 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Utility Balanced Voice De-Identification Using Adversarial Examples
Nov 10, 2022



Faced with the threat of identity leakage during voice data publishing, users are engaged in a privacy-utility dilemma when enjoying convenient voice services. Existing studies employ direct modification or text-based re-synthesis to de-identify users' voices, but resulting in inconsistent audibility in the presence of human participants. In this paper, we propose a voice de-identification system, which uses adversarial examples to balance the privacy and utility of voice services. Instead of typical additive examples inducing perceivable distortions, we design a novel convolutional adversarial example that modulates perturbations into real-world room impulse responses. Benefit from this, our system could preserve user identity from exposure by Automatic Speaker Identification (ASI) while remaining the voice perceptual quality for non-intrusive de-identification. Moreover, our system learns a compact speaker distribution through a conditional variational auto-encoder to sample diverse target embeddings on demand. Combining diverse target generation and input-specific perturbation construction, our system enables any-to-any identify transformation for adaptive de-identification. Experimental results show that our system could achieve 98% and 79% successful de-identification on mainstream ASIs and commercial systems with an objective Mel cepstral distortion of 4.31dB and a subjective mean opinion score of 4.48.
FBNet: Feedback Network for Point Cloud Completion
Oct 08, 2022
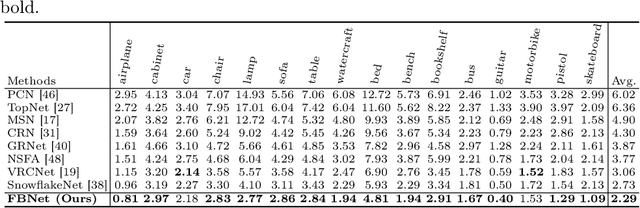
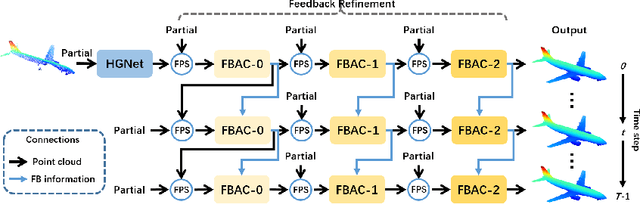
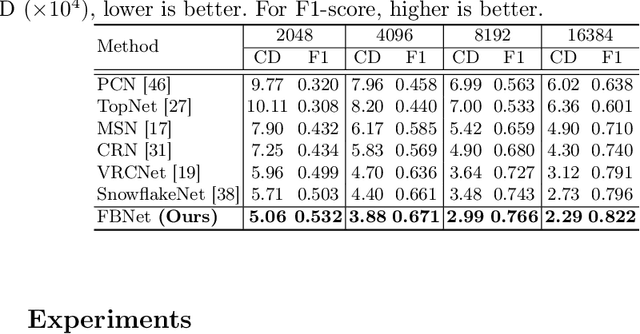
The rapid development of point cloud learning has driven point cloud completion into a new era. However, the information flows of most existing completion methods are solely feedforward, and high-level information is rarely reused to improve low-level feature learning. To this end, we propose a novel Feedback Network (FBNet) for point cloud completion, in which present features are efficiently refined by rerouting subsequent fine-grained ones. Firstly, partial inputs are fed to a Hierarchical Graph-based Network (HGNet) to generate coarse shapes. Then, we cascade several Feedback-Aware Completion (FBAC) Blocks and unfold them across time recurrently. Feedback connections between two adjacent time steps exploit fine-grained features to improve present shape generations. The main challenge of building feedback connections is the dimension mismatching between present and subsequent features. To address this, the elaborately designed point Cross Transformer exploits efficient information from feedback features via cross attention strategy and then refines present features with the enhanced feedback features. Quantitative and qualitative experiments on several datasets demonstrate the superiority of proposed FBNet compared to state-of-the-art methods on point completion task.
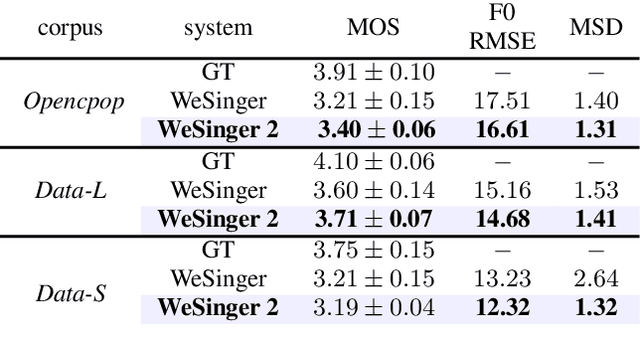
WeSinger 2: Fully Parallel Singing Voice Synthesis via Multi-Singer Conditional Adversarial Training
Jul 11, 2022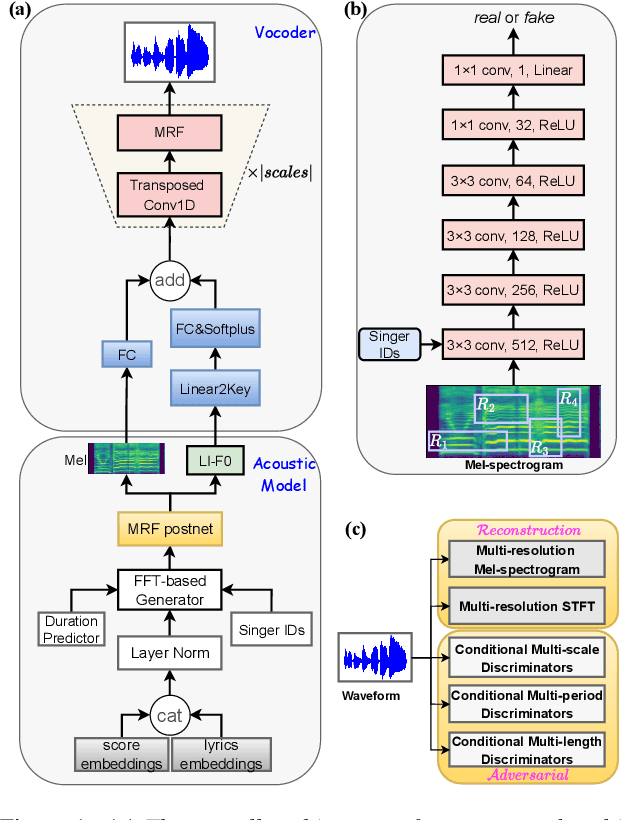


This paper aims to introduce a robust singing voice synthesis (SVS) system to produce high-quality singing voices efficiently by leveraging the adversarial training strategy. On one hand, we designed simple but generic random area conditional discriminators to help supervise the acoustic model, which can effectively avoid the over-smoothed spectrogram prediction by the duration-allocated Transformer-based acoustic model. On the other hand, we subtly combined the spectrogram with the frame-level linearly-interpolated F0 sequence as the input for the neural vocoder, which is then optimized with the help of multiple adversarial discriminators in the waveform domain and multi-scale distance functions in the frequency domain. The experimental results and ablation studies concluded that, compared with our previous auto-regressive work, our new system can produce high-quality singing voices efficiently by fine-tuning on different singing datasets covering from several minutes to few hours. Some synthesized singing samples are available online\footnote{https://zzw922cn.github.io/wesinger2}.
WeSinger: Data-augmented Singing Voice Synthesis with Auxiliary Losses
Mar 27, 2022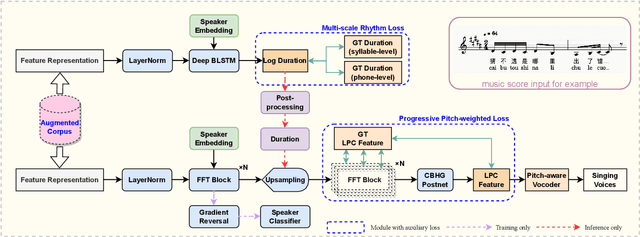
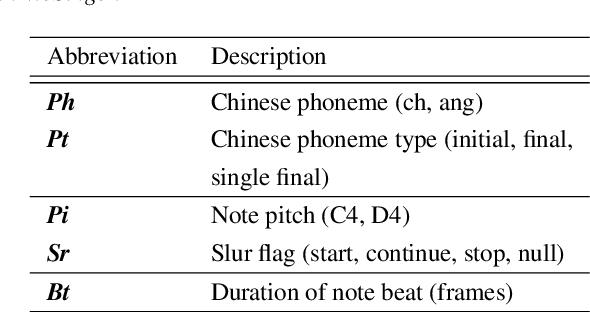

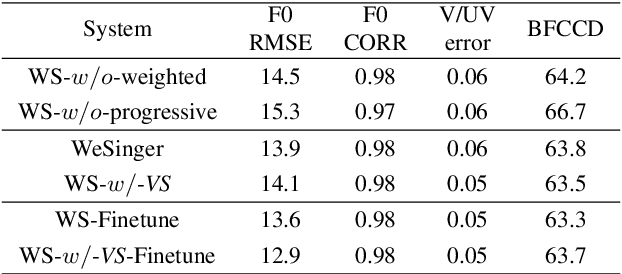
In this paper, we develop a new multi-singer Chinese neural singing voice synthesis (SVS) system named WeSinger. To improve the accuracy and naturalness of synthesized singing voice, we design several specifical modules and techniques: 1) A deep bi-directional LSTM based duration model with multi-scale rhythm loss and post-processing step; 2) A Transformer-alike acoustic model with progressive pitch-weighted decoder loss; 3) a 24 kHz pitch-aware LPCNet neural vocoder to produce high-quality singing waveforms; 4) A novel data augmentation method with multi-singer pre-training for stronger robustness and naturalness. To our knowledge, WeSinger is the first SVS system to adopt 24 kHz LPCNet and multi-singer pre-training simultaneously. Both quantitative and qualitative evaluation results demonstrate the effectiveness of WeSinger in terms of accuracy and naturalness, and WeSinger achieves state-of-the-art performance on the recently public Chinese singing corpus Opencpop. Some synthesized singing samples are available online.
Nana-HDR: A Non-attentive Non-autoregressive Hybrid Model for TTS
Sep 28, 2021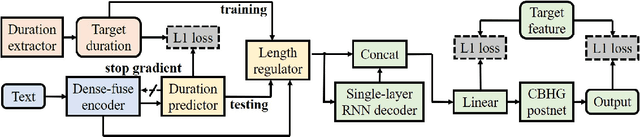

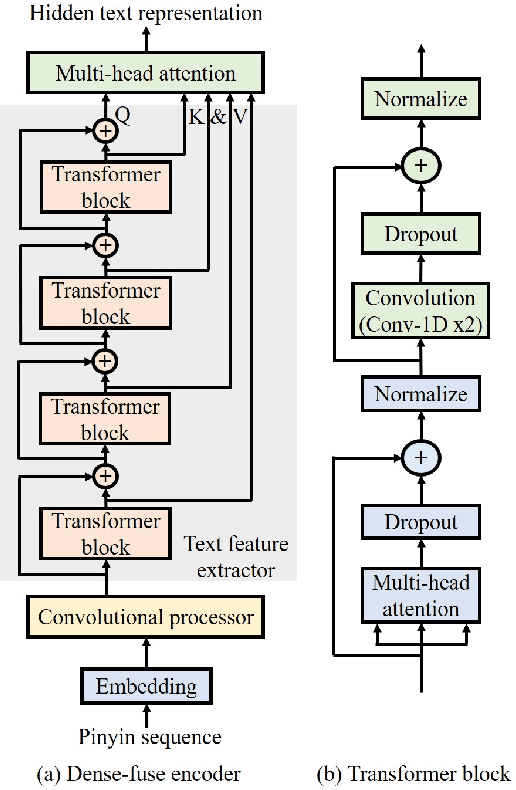
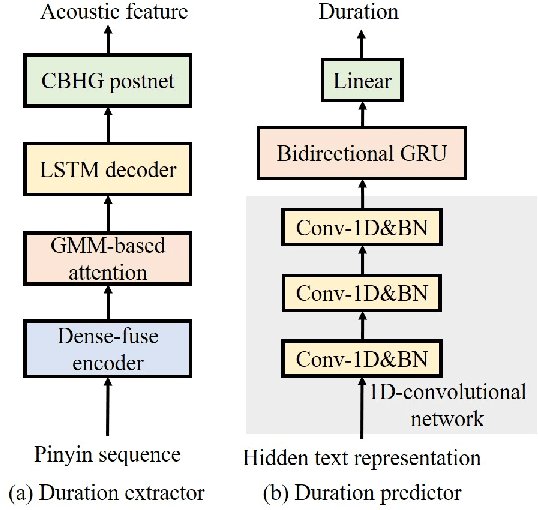
This paper presents Nana-HDR, a new non-attentive non-autoregressive model with hybrid Transformer-based Dense-fuse encoder and RNN-based decoder for TTS. It mainly consists of three parts: Firstly, a novel Dense-fuse encoder with dense connections between basic Transformer blocks for coarse feature fusion and a multi-head attention layer for fine feature fusion. Secondly, a single-layer non-autoregressive RNN-based decoder. Thirdly, a duration predictor instead of an attention model that connects the above hybrid encoder and decoder. Experiments indicate that Nana-HDR gives full play to the advantages of each component, such as strong text encoding ability of Transformer-based encoder, stateful decoding without being bothered by exposure bias and local information preference, and stable alignment provided by duration predictor. Due to these advantages, Nana-HDR achieves competitive performance in naturalness and robustness on two Mandarin corpora.
Learning Inner-Group Relations on Point Clouds
Aug 27, 2021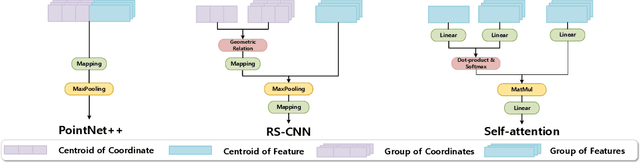
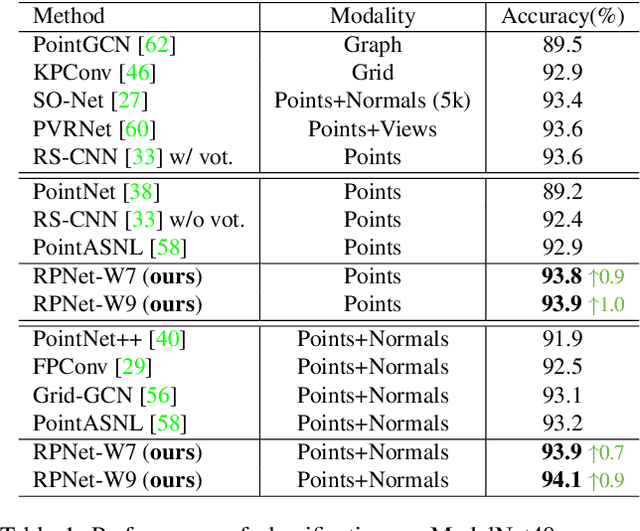
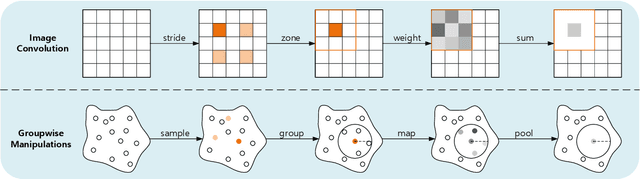
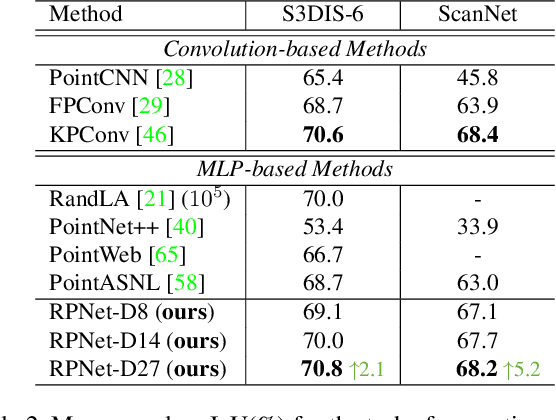
The prevalence of relation networks in computer vision is in stark contrast to underexplored point-based methods. In this paper, we explore the possibilities of local relation operators and survey their feasibility. We propose a scalable and efficient module, called group relation aggregator. The module computes a feature of a group based on the aggregation of the features of the inner-group points weighted by geometric relations and semantic relations. We adopt this module to design our RPNet. We further verify the expandability of RPNet, in terms of both depth and width, on the tasks of classification and segmentation. Surprisingly, empirical results show that wider RPNet fits for classification, while deeper RPNet works better on segmentation. RPNet achieves state-of-the-art for classification and segmentation on challenging benchmarks. We also compare our local aggregator with PointNet++, with around 30% parameters and 50% computation saving. Finally, we conduct experiments to reveal the robustness of RPNet with regard to rigid transformation and noises.
SSPNet: Scale Selection Pyramid Network for Tiny Person Detection from UAV Images
Jul 04, 2021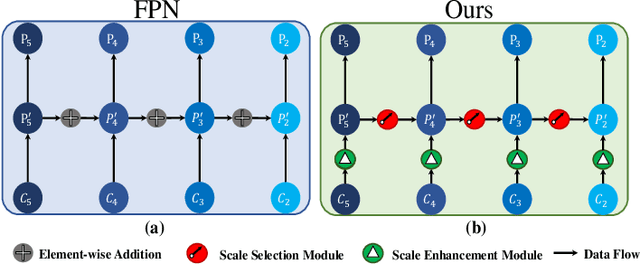
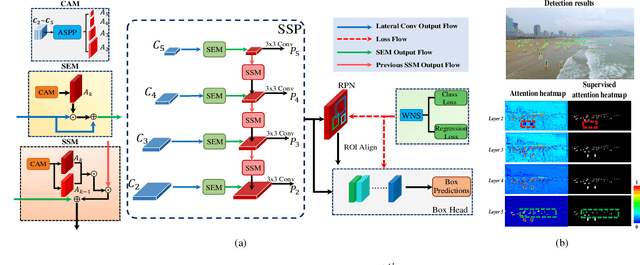

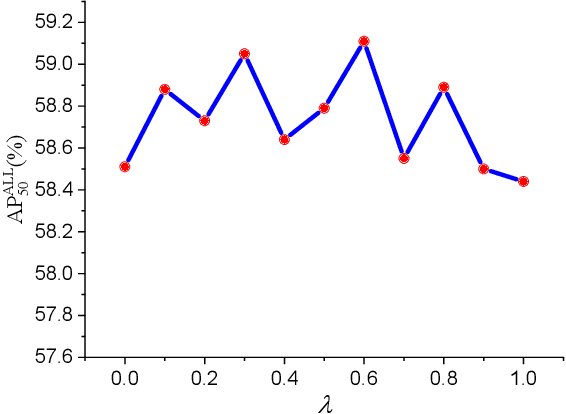
With the increasing demand for search and rescue, it is highly demanded to detect objects of interest in large-scale images captured by Unmanned Aerial Vehicles (UAVs), which is quite challenging due to extremely small scales of objects. Most existing methods employed Feature Pyramid Network (FPN) to enrich shallow layers' features by combing deep layers' contextual features. However, under the limitation of the inconsistency in gradient computation across different layers, the shallow layers in FPN are not fully exploited to detect tiny objects. In this paper, we propose a Scale Selection Pyramid network (SSPNet) for tiny person detection, which consists of three components: Context Attention Module (CAM), Scale Enhancement Module (SEM), and Scale Selection Module (SSM). CAM takes account of context information to produce hierarchical attention heatmaps. SEM highlights features of specific scales at different layers, leading the detector to focus on objects of specific scales instead of vast backgrounds. SSM exploits adjacent layers' relationships to fulfill suitable feature sharing between deep layers and shallow layers, thereby avoiding the inconsistency in gradient computation across different layers. Besides, we propose a Weighted Negative Sampling (WNS) strategy to guide the detector to select more representative samples. Experiments on the TinyPerson benchmark show that our method outperforms other state-of-the-art (SOTA) detectors.
Prediction, Selection, and Generation: Exploration of Knowledge-Driven Conversation System
May 05, 2021
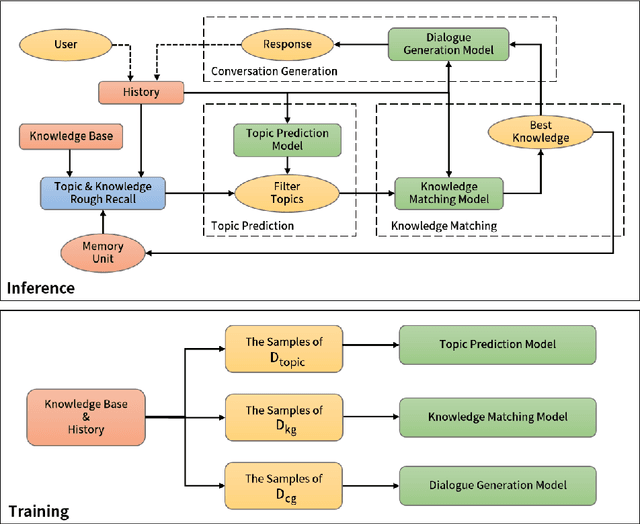

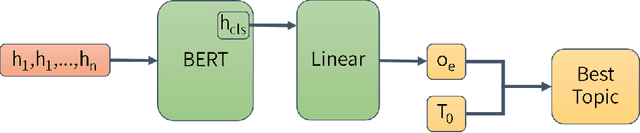
In open-domain conversational systems, it is important but challenging to leverage background knowledge. We can use the incorporation of knowledge to make the generation of dialogue controllable, and can generate more diverse sentences that contain real knowledge. In this paper, we combine the knowledge bases and pre-training model to propose a knowledge-driven conversation system. The system includes modules such as dialogue topic prediction, knowledge matching and dialogue generation. Based on this system, we study the performance factors that maybe affect the generation of knowledge-driven dialogue: topic coarse recall algorithm, number of knowledge choices, generation model choices, etc., and finally made the system reach state-of-the-art. These experimental results will provide some guiding significance for the future research of this task. As far as we know, this is the first work to study and analyze the effects of the related factors.
Equivalence of Correlation Filter and Convolution Filter in Visual Tracking
May 04, 2021(Discriminative) Correlation Filter has been successfully applied to visual tracking and has advanced the field significantly in recent years. Correlation filter-based trackers consider visual tracking as a problem of matching the feature template of the object and candidate regions in the detection sample, in which correlation filter provides the means to calculate the similarities. In contrast, convolution filter is usually used for blurring, sharpening, embossing, edge detection, etc in image processing. On the surface, correlation filter and convolution filter are usually used for different purposes. In this paper, however, we proves, for the first time, that correlation filter and convolution filter are equivalent in the sense that their minimum mean-square errors (MMSEs) in visual tracking are equal, under the condition that the optimal solutions exist and the ideal filter response is Gaussian and centrosymmetric. This result gives researchers the freedom to choose correlation or convolution in formulating their trackers. It also suggests that the explanation of the ideal response in terms of similarities is not essential.
Triple M: A Practical Neural Text-to-speech System With Multi-guidance Attention And Multi-band Multi-time Lpcnet
Feb 09, 2021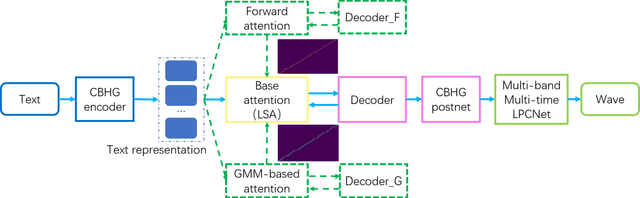

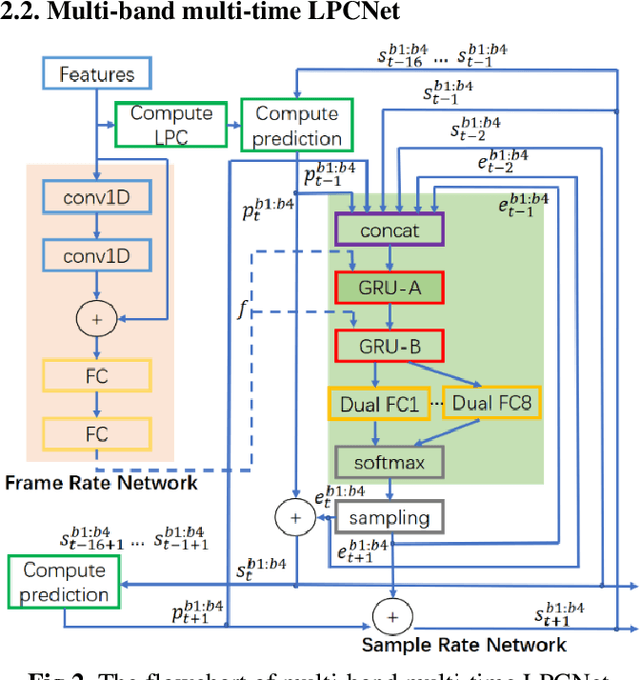

In this work, a robust and efficient text-to-speech system, named Triple M, is proposed for large-scale online application. The key components of Triple M are: 1) A seq2seq model with multi-guidance attention which obtains stable feature generation and robust long sentence synthesis ability by learning from the guidance attention mechanisms. Multi-guidance attention improves the robustness and naturalness of long sentence synthesis without any in-domain performance loss or online service modification. Compared with the our best result obtained by using single attention mechanism (GMM-based attention), the word error rate of long sentence synthesis decreases by 23.5% when multi-guidance attention mechanism is applied. 2) A efficient multi-band multi-time LPCNet, which reduces the computational complexity of LPCNet through combining multi-band and multi-time strategies (from 2.8 to 1.0 GFLOP). Due to these strategies, the vocoder speed is increased by 2.75x on a single CPU without much MOS degradatiaon (4.57 vs. 4.45).