 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized News Recommendation with Multi-granularity Candidate-aware User Modeling
Apr 19, 2025Matching candidate news with user interests is crucial for personalized news recommendations. Most existing methods can represent a user's reading interests through a single profile based on clicked news, which may not fully capture the diversity of user interests. Although some approaches incorporate candidate news or topic information, they remain insufficient because they neglect the multi-granularity relatedness between candidate news and user interests. To address this, this study proposed a multi-granularity candidate-aware user modeling framework that integrated user interest features across various levels of granularity. It consisted of two main components: candidate news encoding and user modeling. A news textual information extractor and a knowledge-enhanced entity information extractor can capture candidate news features, and word-level, entity-level, and news-level candidate-aware mechanisms can provide a comprehensive representation of user interests. Extensive experiments on a real-world dataset demonstrated that the proposed model could significantly outperform baseline models.
Span-level Emotion-Cause-Category Triplet Extraction with Instruction Tuning LLMs and Data Augmentation
Apr 13, 2025Span-level emotion-cause-category triplet extraction represents a novel and complex challenge within emotion cause analysis. This task involves identifying emotion spans, cause spans, and their associated emotion categories within the text to form structured triplets. While prior research has predominantly concentrated on clause-level emotion-cause pair extraction and span-level emotion-cause detection, these methods often confront challenges originating from redundant information retrieval and difficulty in accurately determining emotion categories, particularly when emotions are expressed implicitly or ambiguously. To overcome these challenges, this study explores a fine-grained approach to span-level emotion-cause-category triplet extraction and introduces an innovative framework that leverages instruction tuning and data augmentation techniques based on large language models. The proposed method employs task-specific triplet extraction instructions and utilizes low-rank adaptation to fine-tune large language models, eliminating the necessity for intricate task-specific architectures. Furthermore, a prompt-based data augmentation strategy is developed to address data scarcity by guiding large language models in generating high-quality synthetic training data. Extensive experimental evaluations demonstrate that the proposed approach significantly outperforms existing baseline methods, achieving at least a 12.8% improvement in span-level emotion-cause-category triplet extraction metrics. The results demonstrate the method's effectiveness and robustness, offering a promising avenue for advancing research in emotion cause analysis. The source code is available at https://github.com/zxgnlp/InstruDa-LLM.
DRDM: A Disentangled Representations Diffusion Model for Synthesizing Realistic Person Images
Dec 25, 2024Person image synthesis with controllable body poses and appearances is an essential task owing to the practical needs in the context of virtual try-on, image editing and video production. However, existing methods face significant challenges with details missing, limbs distortion and the garment style deviation. To address these issues, we propose a Disentangled Representations Diffusion Model (DRDM) to generate photo-realistic images from source portraits in specific desired poses and appearances. First, a pose encoder is responsible for encoding pose features into a high-dimensional space to guide the generation of person images. Second, a body-part subspace decoupling block (BSDB) disentangles features from the different body parts of a source figure and feeds them to the various layers of the noise prediction block, thereby supplying the network with rich disentangled features for generating a realistic target image. Moreover, during inference, we develop a parsing map-based disentangled classifier-free guided sampling method, which amplifies the conditional signals of texture and pose. Extensive experimental results on the Deepfashion dataset demonstrate the effectiveness of our approach in achieving pose transfer and appearance control.
MSA-GCN:Multiscale Adaptive Graph Convolution Network for Gait Emotion Recognition
Sep 19, 2022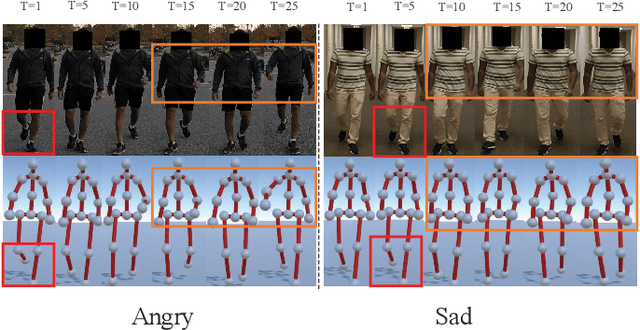
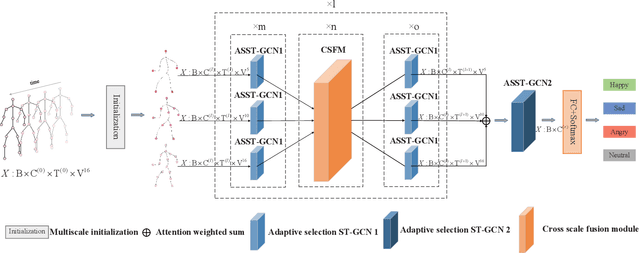
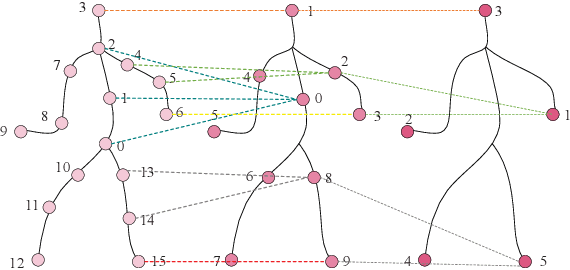
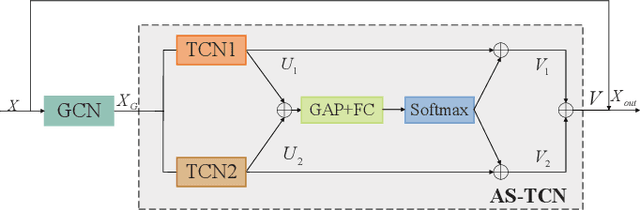
Gait emotion recognition plays a crucial role in the intelligent system. Most of the existing methods recognize emotions by focusing on local actions over time. However, they ignore that the effective distances of different emotions in the time domain are different, and the local actions during walking are quite similar. Thus, emotions should be represented by global states instead of indirect local actions. To address these issues, a novel Multi Scale Adaptive Graph Convolution Network (MSA-GCN) is presented in this work through constructing dynamic temporal receptive fields and designing multiscale information aggregation to recognize emotions. In our model, a adaptive selective spatial-temporal graph convolution is designed to select the convolution kernel dynamically to obtain the soft spatio-temporal features of different emotions. Moreover, a Cross-Scale mapping Fusion Mechanism (CSFM) is designed to construct an adaptive adjacency matrix to enhance information interaction and reduce redundancy. Compared with previous state-of-the-art methods, the proposed method achieves the best performance on two public datasets, improving the mAP by 2\%. We also conduct extensive ablations studies to show the effectiveness of different components in our methods.