 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Task Graphs: Generalizing to Unseen Tasks from a Single Video Demonstration
Mar 06, 2019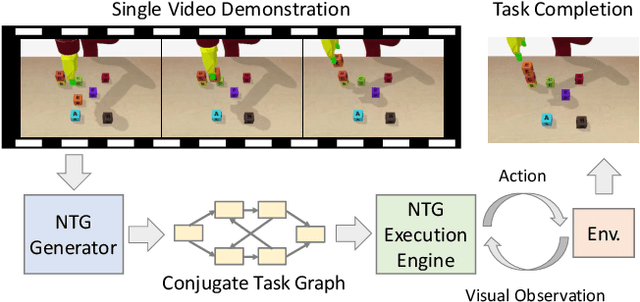
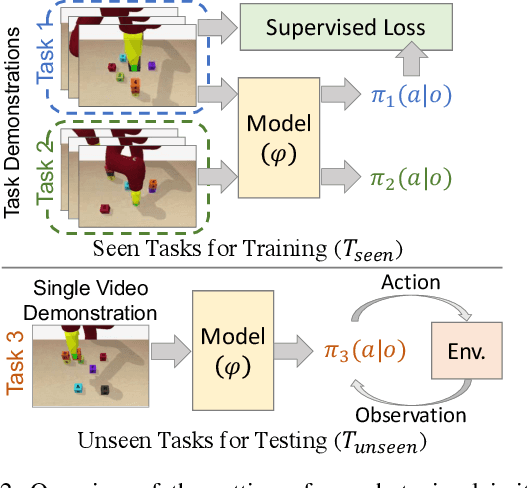
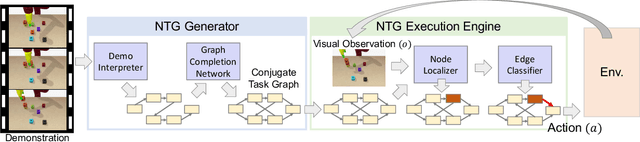
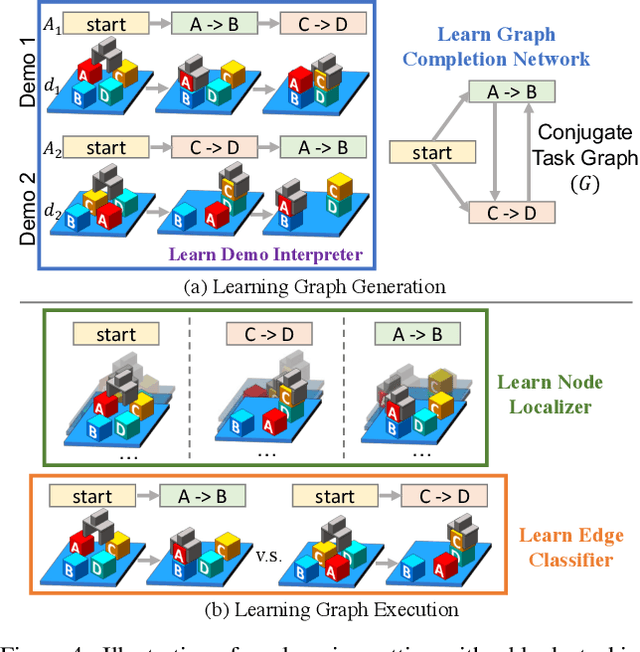
Our goal is to generate a policy to complete an unseen task given just a single video demonstration of the task in a given domain. We hypothesize that to successfully generalize to unseen complex tasks from a single video demonstration, it is necessary to explicitly incorporate the compositional structure of the tasks into the model. To this end, we propose Neural Task Graph (NTG) Networks, which use conjugate task graph as the intermediate representation to modularize both the video demonstration and the derived policy. We empirically show NTG achieves inter-task generalization on two complex tasks: Block Stacking in BulletPhysics and Object Collection in AI2-THOR. NTG improves data efficiency with visual input as well as achieve strong generalization without the need for dense hierarchical supervision. We further show that similar performance trends hold when applied to real-world data. We show that NTG can effectively predict task structure on the JIGSAWS surgical dataset and generalize to unseen tasks.
Audio-Linguistic Embeddings for Spoken Sentences
Feb 20, 2019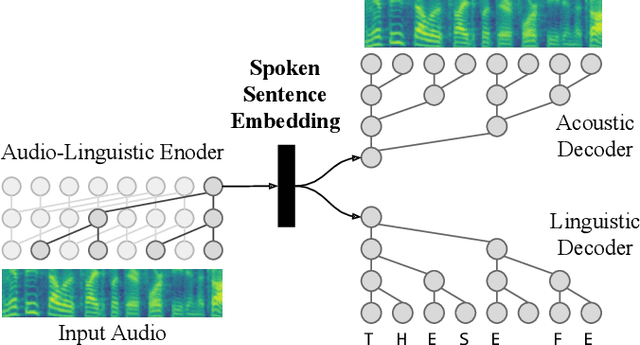
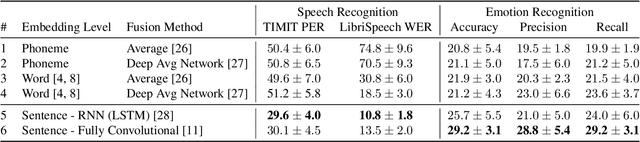
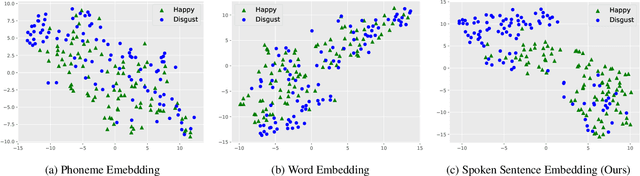
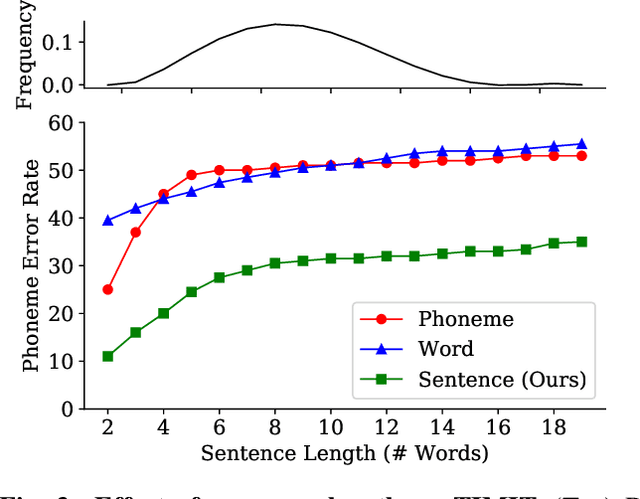
We propose spoken sentence embeddings which capture both acoustic and linguistic content. While existing works operate at the character, phoneme, or word level, our method learns long-term dependencies by modeling speech at the sentence level. Formulated as an audio-linguistic multitask learning problem, our encoder-decoder model simultaneously reconstructs acoustic and natural language features from audio. Our results show that spoken sentence embeddings outperform phoneme and word-level baselines on speech recognition and emotion recognition tasks. Ablation studies show that our embeddings can better model high-level acoustic concepts while retaining linguistic content. Overall, our work illustrates the viability of generic, multi-modal sentence embeddings for spoken language understanding.
DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion
Jan 15, 2019
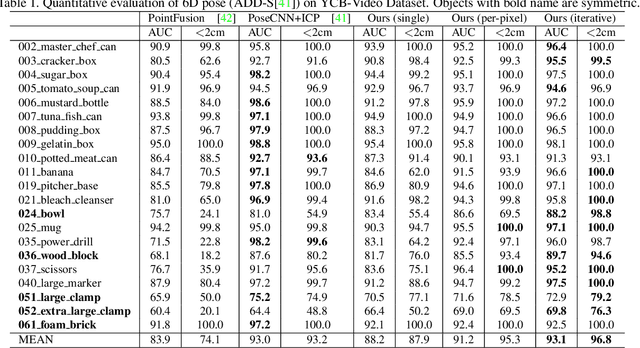
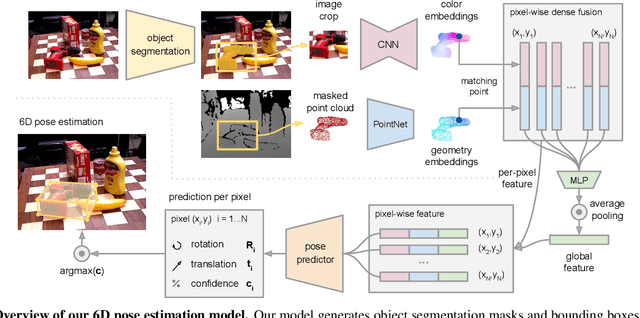
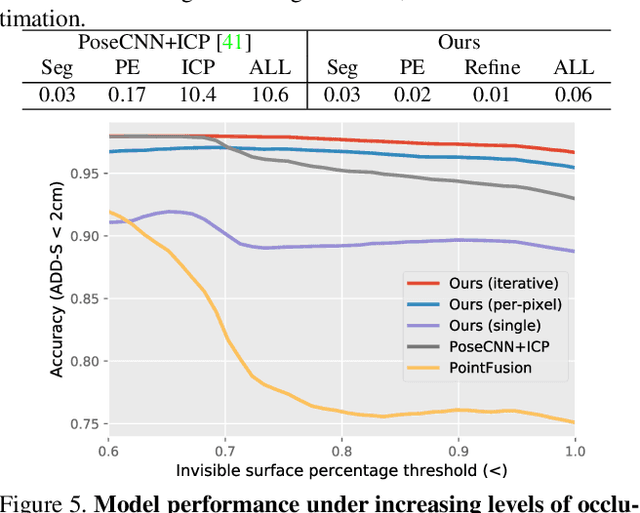
A key technical challenge in performing 6D object pose estimation from RGB-D image is to fully leverage the two complementary data sources. Prior works either extract information from the RGB image and depth separately or use costly post-processing steps, limiting their performances in highly cluttered scenes and real-time applications. In this work, we present DenseFusion, a generic framework for estimating 6D pose of a set of known objects from RGB-D images. DenseFusion is a heterogeneous architecture that processes the two data sources individually and uses a novel dense fusion network to extract pixel-wise dense feature embedding, from which the pose is estimated. Furthermore, we integrate an end-to-end iterative pose refinement procedure that further improves the pose estimation while achieving near real-time inference. Our experiments show that our method outperforms state-of-the-art approaches in two datasets, YCB-Video and LineMOD. We also deploy our proposed method to a real robot to grasp and manipulate objects based on the estimated pose.
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Jan 10, 2019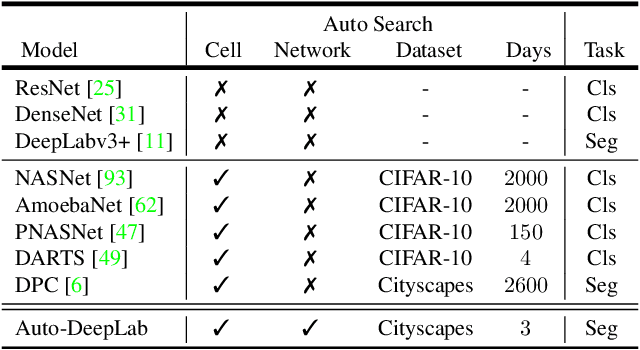
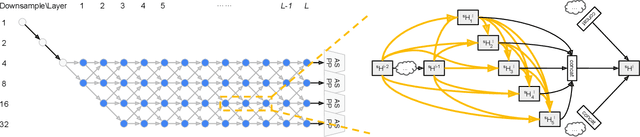
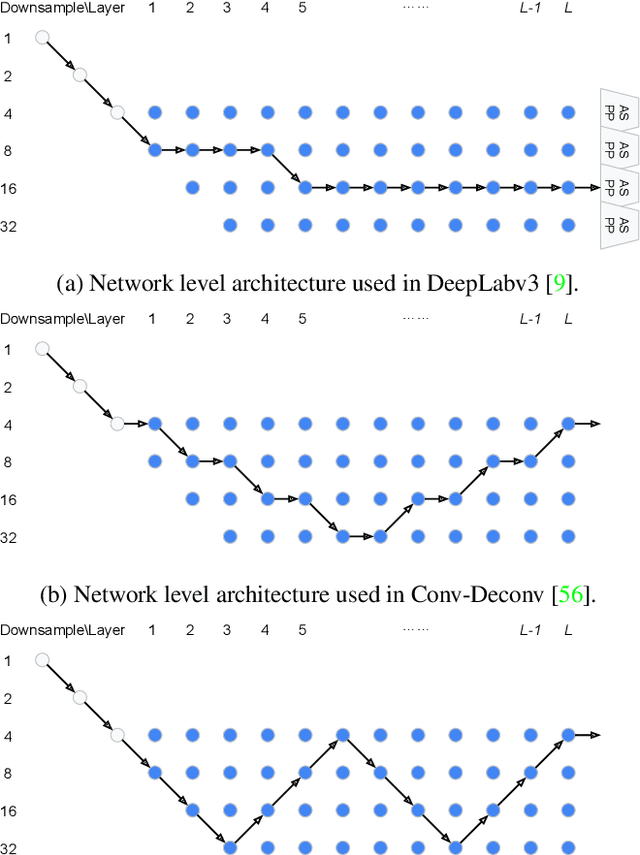
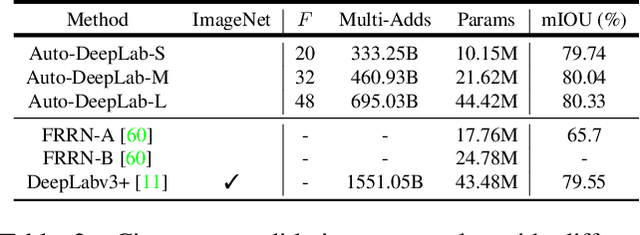
Recently, Neural Architecture Search (NAS) has successfully identified neural network architectures that exceed human designed ones on large-scale image classification problems. In this paper, we study NAS for semantic image segmentation, an important computer vision task that assigns a semantic label to every pixel in an image. Existing works often focus on searching the repeatable cell structure, while hand-designing the outer network structure that controls the spatial resolution changes. This choice simplifies the search space, but becomes increasingly problematic for dense image prediction which exhibits a lot more network level architectural variations. Therefore, we propose to search the network level structure in addition to the cell level structure, which forms a hierarchical architecture search space. We present a network level search space that includes many popular designs, and develop a formulation that allows efficient gradient-based architecture search (3 P100 GPU days on Cityscapes images). We demonstrate the effectiveness of the proposed method on the challenging Cityscapes, PASCAL VOC 2012, and ADE20K datasets. Without any ImageNet pretraining, our architecture searched specifically for semantic image segmentation attains state-of-the-art performance.
D${}^3$TW: Discriminative Differentiable Dynamic Time Warping for Weakly Supervised Action Alignment and Segmentation
Jan 09, 2019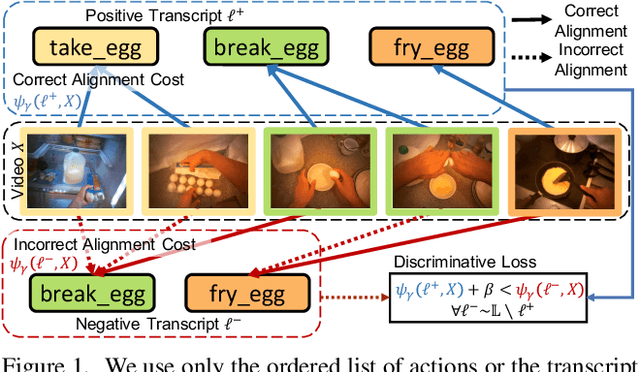
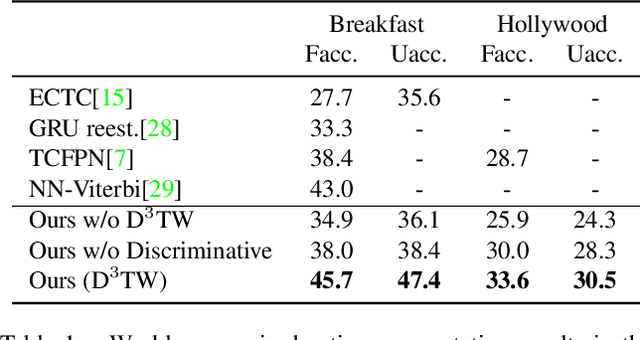
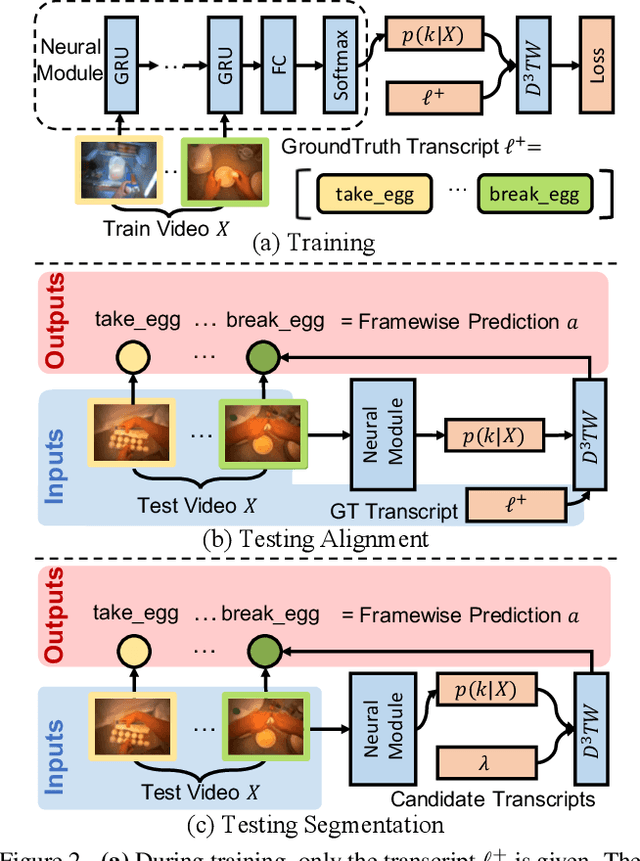
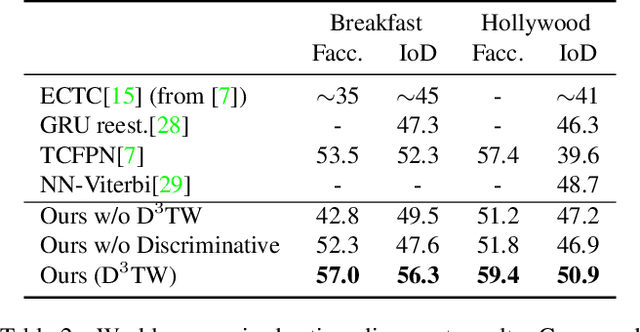
We address weakly-supervised action alignment and segmentation in videos, where only the order of occurring actions is available during training. We propose Discriminative Differentiable Dynamic Time Warping (D${}^3$TW), which is the first discriminative model for weak ordering supervision. This allows us to bypass the degenerated sequence problem usually encountered in previous work. The key technical challenge for discriminative modeling with weak-supervision is that the loss function of the ordering supervision is usually formulated using dynamic programming and is thus not differentiable. We address this challenge by continuous relaxation of the min-operator in dynamic programming and extend the DTW alignment loss to be differentiable. The proposed D${}^3$TW innovatively solves sequence alignment with discriminative modeling and end-to-end training, which substantially improves the performance in weakly supervised action alignment and segmentation tasks. We show that our model outperforms the current state-of-the-art across three evaluation metrics in two challenging datasets.
Composing Text and Image for Image Retrieval - An Empirical Odyssey
Dec 18, 2018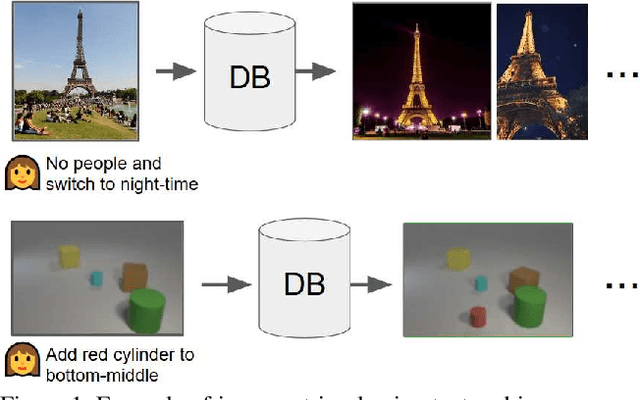
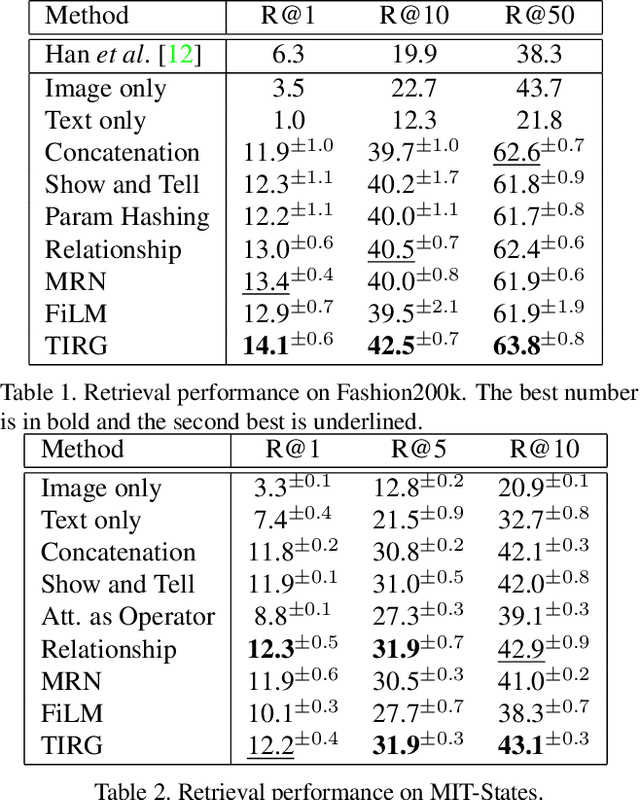
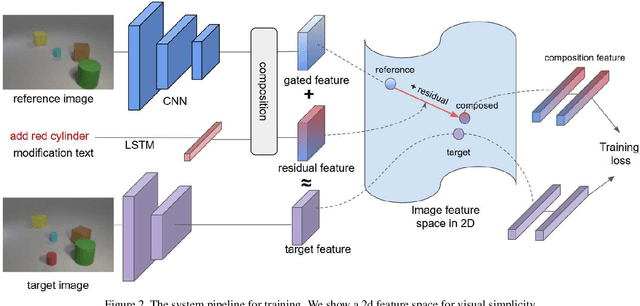

In this paper, we study the task of image retrieval, where the input query is specified in the form of an image plus some text that describes desired modifications to the input image. For example, we may present an image of the Eiffel tower, and ask the system to find images which are visually similar but are modified in small ways, such as being taken at nighttime instead of during the day. To tackle this task, we learn a similarity metric between a target image and a source image plus source text, an embedding and composing function such that target image feature is close to the source image plus text composition feature. We propose a new way to combine image and text using such function that is designed for the retrieval task. We show this outperforms existing approaches on 3 different datasets, namely Fashion-200k, MIT-States and a new synthetic dataset we create based on CLEVR. We also show that our approach can be used to classify input queries, in addition to image retrieval.
Vision-Based Gait Analysis for Senior Care
Dec 01, 2018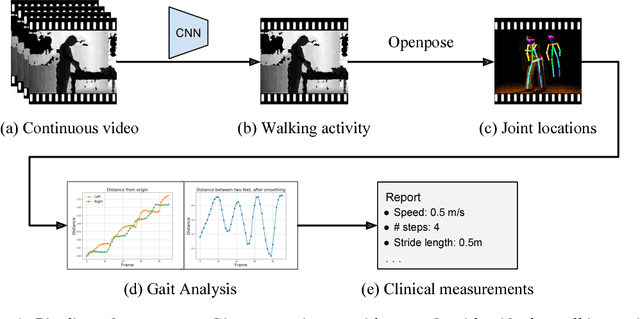

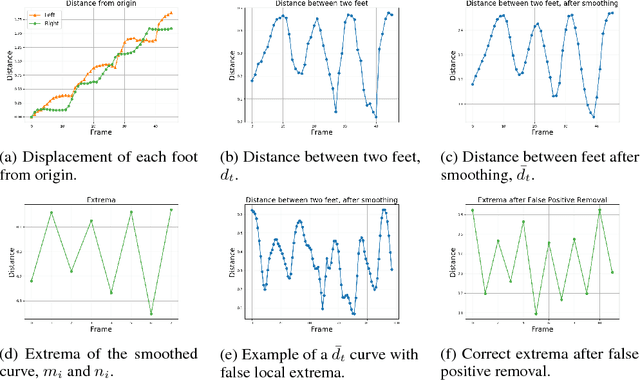
As the senior population rapidly increases, it is challenging yet crucial to provide effective long-term care for seniors who live at home or in senior care facilities. Smart senior homes, which have gained widespread interest in the healthcare community, have been proposed to improve the well-being of seniors living independently. In particular, non-intrusive, cost-effective sensors placed in these senior homes enable gait characterization, which can provide clinically relevant information including mobility level and early neurodegenerative disease risk. In this paper, we present a method to perform gait analysis from a single camera placed within the home. We show that we can accurately calculate various gait parameters, demonstrating the potential for our system to monitor the long-term gait of seniors and thus aid clinicians in understanding a patient's medical profile.
Measuring Depression Symptom Severity from Spoken Language and 3D Facial Expressions
Nov 27, 2018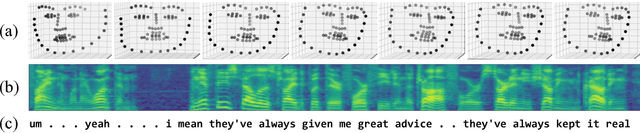
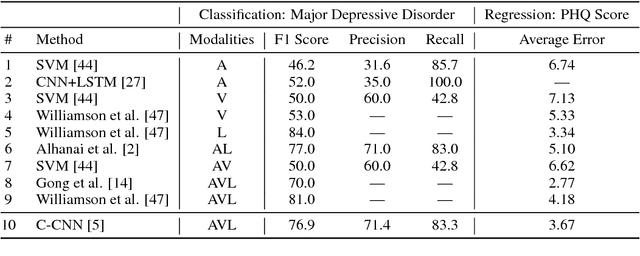
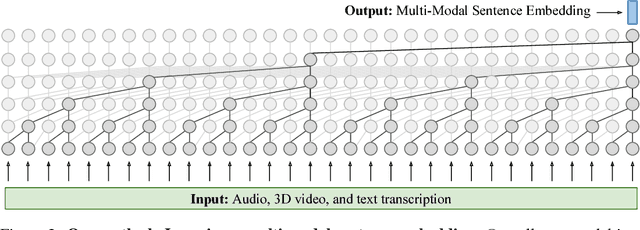
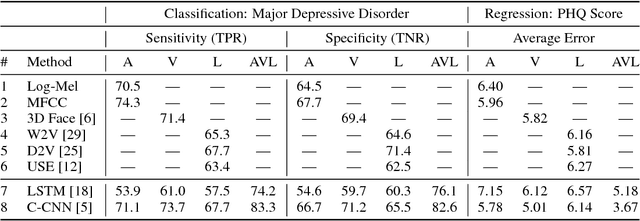
With more than 300 million people depressed worldwide, depression is a global problem. Due to access barriers such as social stigma, cost, and treatment availability, 60% of mentally-ill adults do not receive any mental health services. Effective and efficient diagnosis relies on detecting clinical symptoms of depression. Automatic detection of depressive symptoms would potentially improve diagnostic accuracy and availability, leading to faster intervention. In this work, we present a machine learning method for measuring the severity of depressive symptoms. Our multi-modal method uses 3D facial expressions and spoken language, commonly available from modern cell phones. It demonstrates an average error of 3.67 points (15.3% relative) on the clinically-validated Patient Health Questionnaire (PHQ) scale. For detecting major depressive disorder, our model demonstrates 83.3% sensitivity and 82.6% specificity. Overall, this paper shows how speech recognition, computer vision, and natural language processing can be combined to assist mental health patients and practitioners. This technology could be deployed to cell phones worldwide and facilitate low-cost universal access to mental health care.
Privacy-Preserving Action Recognition for Smart Hospitals using Low-Resolution Depth Images
Nov 25, 2018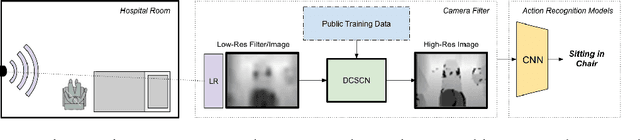
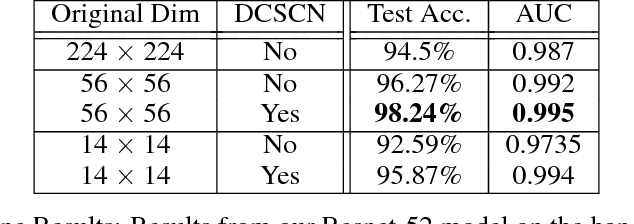

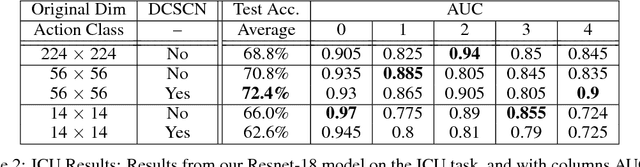
Computer-vision hospital systems can greatly assist healthcare workers and improve medical facility treatment, but often face patient resistance due to the perceived intrusiveness and violation of privacy associated with visual surveillance. We downsample video frames to extremely low resolutions to degrade private information from surveillance videos. We measure the amount of activity-recognition information retained in low resolution depth images, and also apply a privately-trained DCSCN super-resolution model to enhance the utility of our images. We implement our techniques with two actual healthcare-surveillance scenarios, hand-hygiene compliance and ICU activity-logging, and show that our privacy-preserving techniques preserve enough information for realistic healthcare tasks.
RoboTurk: A Crowdsourcing Platform for Robotic Skill Learning through Imitation
Nov 07, 2018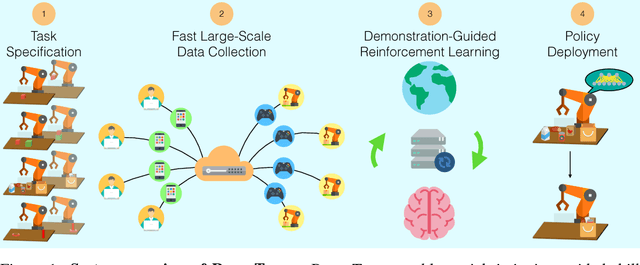

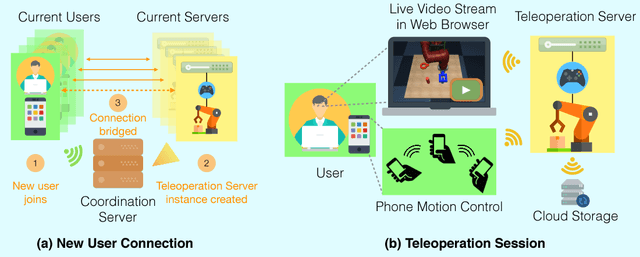
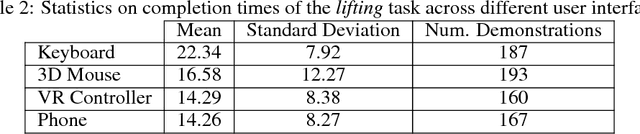
Imitation Learning has empowered recent advances in learning robotic manipulation tasks by addressing shortcomings of Reinforcement Learning such as exploration and reward specification. However, research in this area has been limited to modest-sized datasets due to the difficulty of collecting large quantities of task demonstrations through existing mechanisms. This work introduces RoboTurk to address this challenge. RoboTurk is a crowdsourcing platform for high quality 6-DoF trajectory based teleoperation through the use of widely available mobile devices (e.g. iPhone). We evaluate RoboTurk on three manipulation tasks of varying timescales (15-120s) and observe that our user interface is statistically similar to special purpose hardware such as virtual reality controllers in terms of task completion times. Furthermore, we observe that poor network conditions, such as low bandwidth and high delay links, do not substantially affect the remote users' ability to perform task demonstrations successfully on RoboTurk. Lastly, we demonstrate the efficacy of RoboTurk through the collection of a pilot dataset; using RoboTurk, we collected 137.5 hours of manipulation data from remote workers, amounting to over 2200 successful task demonstrations in 22 hours of total system usage. We show that the data obtained through RoboTurk enables policy learning on multi-step manipulation tasks with sparse rewards and that using larger quantities of demonstrations during policy learning provides benefits in terms of both learning consistency and final performance. For additional results, videos, and to download our pilot dataset, visit $\href{http://roboturk.stanford.edu/}{\texttt{roboturk.stanford.edu}}$