 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableMoE: Neuro-Symbolic Routing for Structured Expert Reasoning in Multimodal Table Understanding
Jun 26, 2025Multimodal understanding of tables in real-world contexts is challenging due to the complexity of structure, symbolic density, and visual degradation (blur, skew, watermarking, incomplete structures or fonts, multi-span or hierarchically nested layouts). Existing multimodal large language models (MLLMs) struggle with such WildStruct conditions, resulting in limited performance and poor generalization. To address these challenges, we propose TableMoE, a neuro-symbolic Mixture-of-Connector-Experts (MoCE) architecture specifically designed for robust, structured reasoning over multimodal table data. TableMoE features an innovative Neuro-Symbolic Routing mechanism, which predicts latent semantic token roles (e.g., header, data cell, axis, formula) and dynamically routes table elements to specialized experts (Table-to-HTML, Table-to-JSON, Table-to-Code) using a confidence-aware gating strategy informed by symbolic reasoning graphs. To facilitate effective alignment-driven pretraining, we introduce the large-scale TableMoE-Align dataset, consisting of 1.2M table-HTML-JSON-code quadruples across finance, science, biomedicine and industry, utilized exclusively for model pretraining. For evaluation, we curate and release four challenging WildStruct benchmarks: WMMFinQA, WMMTatQA, WMMTabDialog, and WMMFinanceMath, designed specifically to stress-test models under real-world multimodal degradation and structural complexity. Experimental results demonstrate that TableMoE significantly surpasses existing state-of-the-art models. Extensive ablation studies validate each core component, emphasizing the critical role of Neuro-Symbolic Routing and structured expert alignment. Through qualitative analyses, we further showcase TableMoE's interpretability and enhanced robustness, underscoring the effectiveness of integrating neuro-symbolic reasoning for multimodal table understanding.
Beyond Terabit/s Integrated Neuromorphic Photonic Processor for DSP-Free Optical Interconnects
Apr 21, 2025The rapid expansion of generative AI drives unprecedented demands for high-performance computing. Training large-scale AI models now requires vast interconnected GPU clusters across multiple data centers. Multi-scale AI training and inference demand uniform, ultra-low latency, and energy-efficient links to enable massive GPUs to function as a single cohesive unit. However, traditional electrical and optical interconnects, relying on conventional digital signal processors (DSPs) for signal distortion compensation, increasingly fail to meet these stringent requirements. To overcome these limitations, we present an integrated neuromorphic optical signal processor (OSP) that leverages deep reservoir computing and achieves DSP-free, all-optical, real-time processing. Experimentally, our OSP achieves a 100 Gbaud PAM4 per lane, 1.6 Tbit/s data center interconnect over a 5 km optical fiber in the C-band (equivalent to over 80 km in the O-band), far exceeding the reach of state-of-the-art DSP solutions, which are fundamentally constrained by chromatic dispersion in IMDD systems. Simultaneously, it reduces processing latency by four orders of magnitude and energy consumption by three orders of magnitude. Unlike DSPs, which introduce increased latency at high data rates, our OSP maintains consistent, ultra-low latency regardless of data rate scaling, making it ideal for future optical interconnects. Moreover, the OSP retains full optical field information for better impairment compensation and adapts to various modulation formats, data rates, and wavelengths. Fabricated using a mature silicon photonic process, the OSP can be monolithically integrated with silicon photonic transceivers, enhancing the compactness and reliability of all-optical interconnects. This research provides a highly scalable, energy-efficient, and high-speed solution, paving the way for next-generation AI infrastructure.
Edge-guided inverse design of digital metamaterials for ultra-high-capacity on-chip multi-dimensional interconnect
Oct 10, 2024



The escalating demands of compute-intensive applications, including artificial intelligence, urgently necessitate the adoption of sophisticated optical on-chip interconnect technologies to overcome critical bottlenecks in scaling future computing systems. This transition requires leveraging the inherent parallelism of wavelength and mode dimensions of light, complemented by high-order modulation formats, to significantly enhance data throughput. Here we experimentally demonstrate a novel synergy of these three dimensions, achieving multi-tens-of-terabits-per-second on-chip interconnects using ultra-broadband, multi-mode digital metamaterials. Employing a highly efficient edge-guided analog-and-digital optimization method, we inversely design foundry-compatible, robust, and multi-port digital metamaterials with an 8xhigher computational efficiency. Using a packaged five-mode multiplexing chip, we demonstrate a single-wavelength interconnect capacity of 1.62 Tbit s-1 and a record-setting multi-dimensional interconnect capacity of 38.2 Tbit s-1 across 5 modes and 88 wavelength channels. A theoretical analysis suggests that further system optimization can enable on-chip interconnects to reach sub-petabit-per-second data transmission rates. This study highlights the transformative potential of optical interconnect technologies to surmount the constraints of electronic links, thus setting the stage for next-generation datacenter and optical compute interconnects.
HierarchicalContrast: A Coarse-to-Fine Contrastive Learning Framework for Cross-Domain Zero-Shot Slot Filling
Oct 20, 2023In task-oriented dialogue scenarios, cross-domain zero-shot slot filling plays a vital role in leveraging source domain knowledge to learn a model with high generalization ability in unknown target domain where annotated data is unavailable. However, the existing state-of-the-art zero-shot slot filling methods have limited generalization ability in target domain, they only show effective knowledge transfer on seen slots and perform poorly on unseen slots. To alleviate this issue, we present a novel Hierarchical Contrastive Learning Framework (HiCL) for zero-shot slot filling. Specifically, we propose a coarse- to fine-grained contrastive learning based on Gaussian-distributed embedding to learn the generalized deep semantic relations between utterance-tokens, by optimizing inter- and intra-token distribution distance. This encourages HiCL to generalize to the slot types unseen at training phase. Furthermore, we present a new iterative label set semantics inference method to unbiasedly and separately evaluate the performance of unseen slot types which entangled with their counterparts (i.e., seen slot types) in the previous zero-shot slot filling evaluation methods. The extensive empirical experiments on four datasets demonstrate that the proposed method achieves comparable or even better performance than the current state-of-the-art zero-shot slot filling approaches.
Intelligent Bandwidth Allocation for Latency Management in NG-EPON using Reinforcement Learning Methods
Jan 21, 2020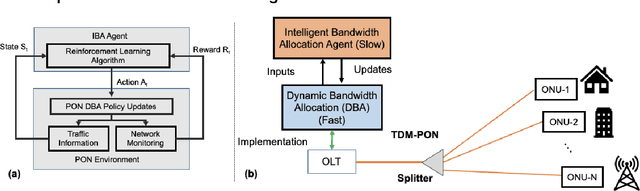
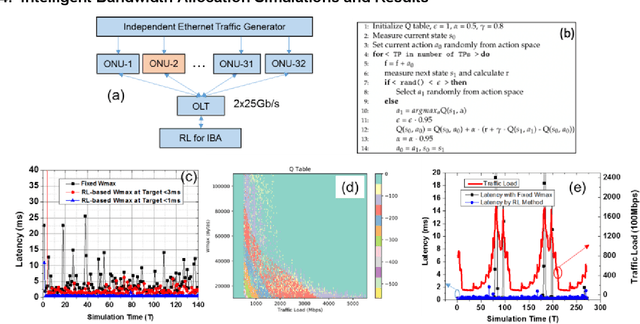
A novel intelligent bandwidth allocation scheme in NG-EPON using reinforcement learning is proposed and demonstrated for latency management. We verify the capability of the proposed scheme under both fixed and dynamic traffic loads scenarios to achieve <1ms average latency. The RL agent demonstrates an efficient intelligent mechanism to manage the latency, which provides a promising IBA solution for the next-generation access network.