 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Cross-domain Recommendation in Matching
Dec 02, 2021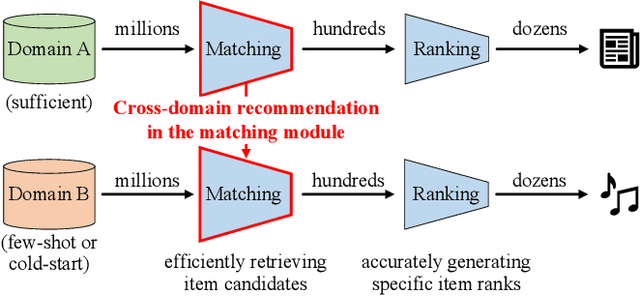
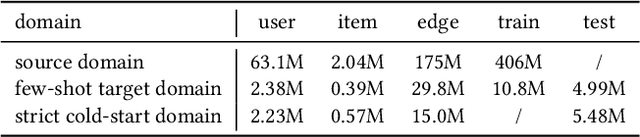
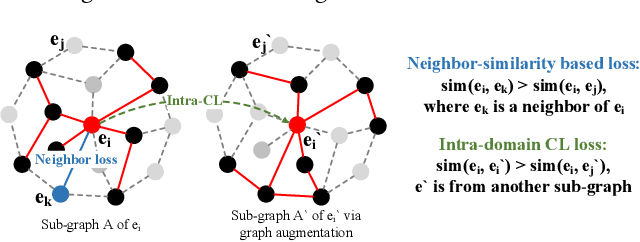
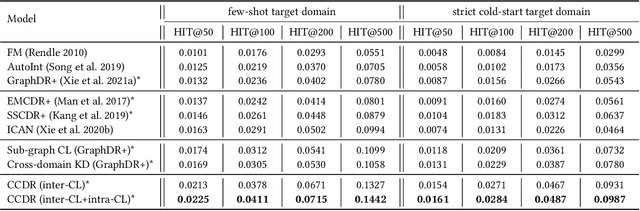
Cross-domain recommendation (CDR) aims to provide better recommendation results in the target domain with the help of the source domain, which is widely used and explored in real-world systems. However, CDR in the matching (i.e., candidate generation) module struggles with the data sparsity and popularity bias issues in both representation learning and knowledge transfer. In this work, we propose a novel Contrastive Cross-Domain Recommendation (CCDR) framework for CDR in matching. Specifically, we build a huge diversified preference network to capture multiple information reflecting user diverse interests, and design an intra-domain contrastive learning (intra-CL) and three inter-domain contrastive learning (inter-CL) tasks for better representation learning and knowledge transfer. The intra-CL enables more effective and balanced training inside the target domain via a graph augmentation, while the inter-CL builds different types of cross-domain interactions from user, taxonomy, and neighbor aspects. In experiments, CCDR achieves significant improvements on both offline and online evaluations in a real-world system. Currently, we have deployed CCDR on a well-known recommendation system, affecting millions of users. The source code will be released in the future.
Personalized Transfer of User Preferences for Cross-domain Recommendation
Oct 22, 2021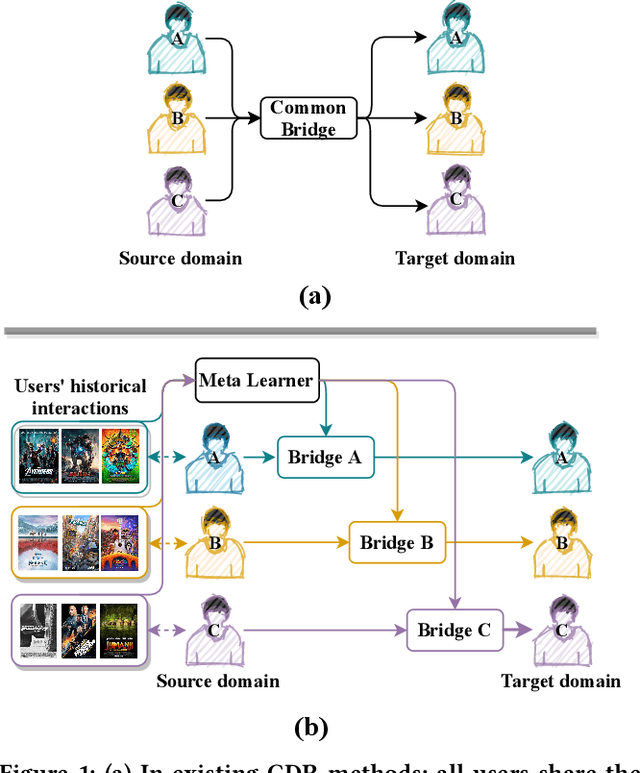

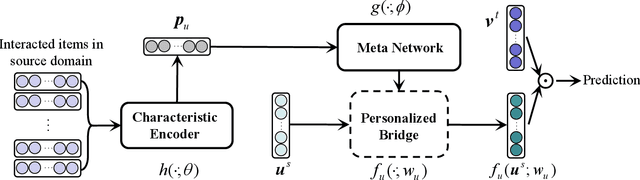
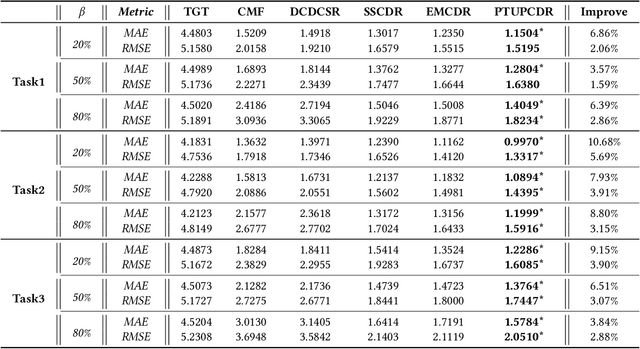
Cold-start problem is still a very challenging problem in recommender systems. Fortunately, the interactions of the cold-start users in the auxiliary source domain can help cold-start recommendations in the target domain. How to transfer user's preferences from the source domain to the target domain, is the key issue in Cross-domain Recommendation (CDR) which is a promising solution to deal with the cold-start problem. Most existing methods model a common preference bridge to transfer preferences for all users. Intuitively, since preferences vary from user to user, the preference bridges of different users should be different. Along this line, we propose a novel framework named Personalized Transfer of User Preferences for Cross-domain Recommendation (PTUPCDR). Specifically, a meta network fed with users' characteristic embeddings is learned to generate personalized bridge functions to achieve personalized transfer of preferences for each user. To learn the meta network stably, we employ a task-oriented optimization procedure. With the meta-generated personalized bridge function, the user's preference embedding in the source domain can be transformed into the target domain, and the transformed user preference embedding can be utilized as the initial embedding for the cold-start user in the target domain. Using large real-world datasets, we conduct extensive experiments to evaluate the effectiveness of PTUPCDR on both cold-start and warm-start stages. The code has been available at \url{https://github.com/easezyc/WSDM2022-PTUPCDR}.
Learning to Expand Audience via Meta Hybrid Experts and Critics for Recommendation and Advertising
May 31, 2021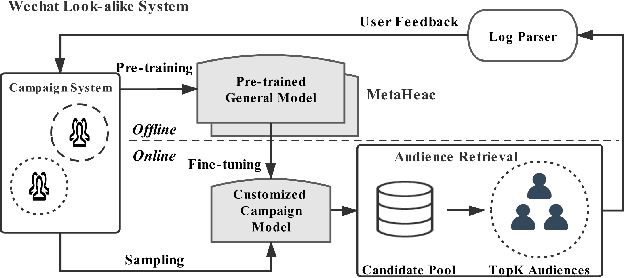

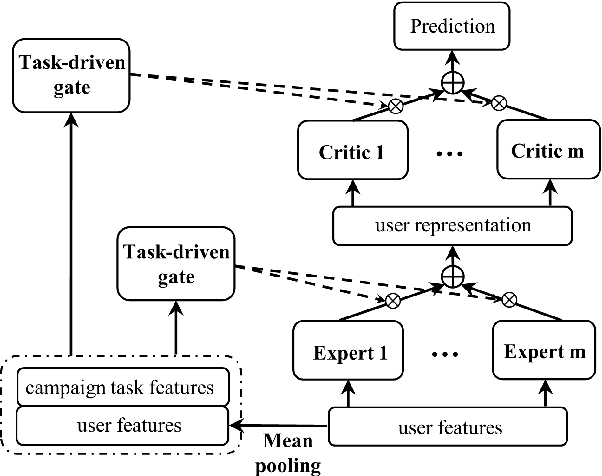
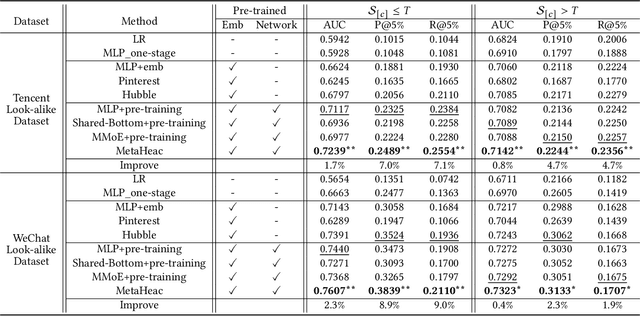
In recommender systems and advertising platforms, marketers always want to deliver products, contents, or advertisements to potential audiences over media channels such as display, video, or social. Given a set of audiences or customers (seed users), the audience expansion technique (look-alike modeling) is a promising solution to identify more potential audiences, who are similar to the seed users and likely to finish the business goal of the target campaign. However, look-alike modeling faces two challenges: (1) In practice, a company could run hundreds of marketing campaigns to promote various contents within completely different categories every day, e.g., sports, politics, society. Thus, it is difficult to utilize a common method to expand audiences for all campaigns. (2) The seed set of a certain campaign could only cover limited users. Therefore, a customized approach based on such a seed set is likely to be overfitting. In this paper, to address these challenges, we propose a novel two-stage framework named Meta Hybrid Experts and Critics (MetaHeac) which has been deployed in WeChat Look-alike System. In the offline stage, a general model which can capture the relationships among various tasks is trained from a meta-learning perspective on all existing campaign tasks. In the online stage, for a new campaign, a customized model is learned with the given seed set based on the general model. According to both offline and online experiments, the proposed MetaHeac shows superior effectiveness for both content marketing campaigns in recommender systems and advertising campaigns in advertising platforms. Besides, MetaHeac has been successfully deployed in WeChat for the promotion of both contents and advertisements, leading to great improvement in the quality of marketing. The code has been available at \url{https://github.com/easezyc/MetaHeac}.
Learning to Warm Up Cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks
May 11, 2021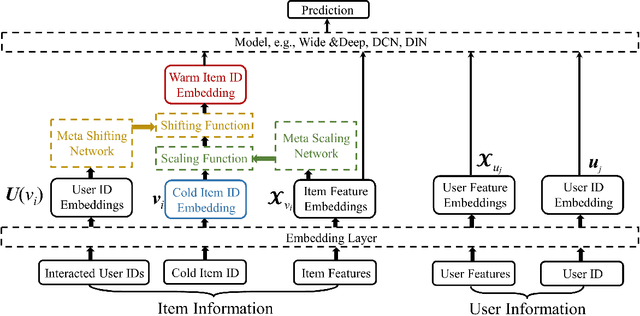
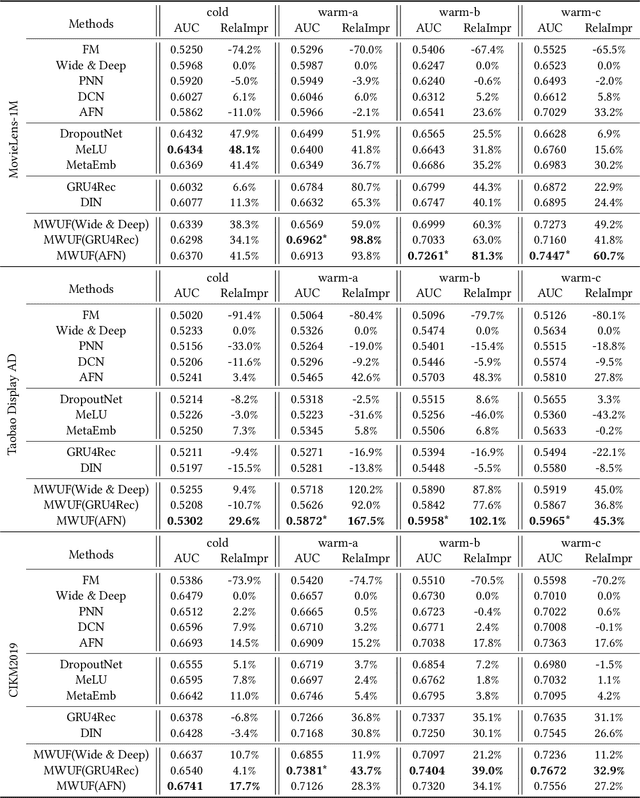
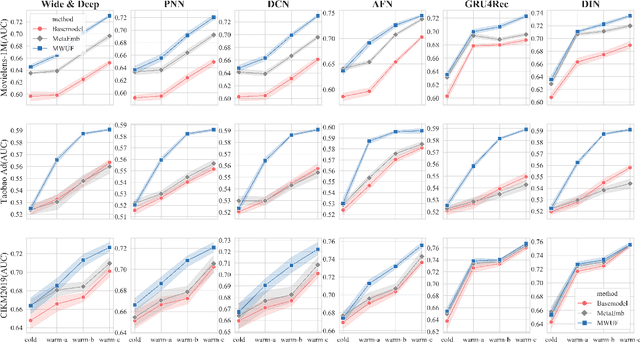
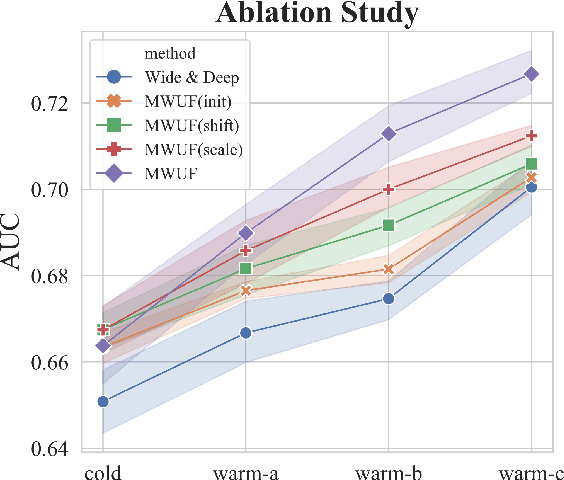
Recently, embedding techniques have achieved impressive success in recommender systems. However, the embedding techniques are data demanding and suffer from the cold-start problem. Especially, for the cold-start item which only has limited interactions, it is hard to train a reasonable item ID embedding, called cold ID embedding, which is a major challenge for the embedding techniques. The cold item ID embedding has two main problems: (1) A gap is existing between the cold ID embedding and the deep model. (2) Cold ID embedding would be seriously affected by noisy interaction. However, most existing methods do not consider both two issues in the cold-start problem, simultaneously. To address these problems, we adopt two key ideas: (1) Speed up the model fitting for the cold item ID embedding (fast adaptation). (2) Alleviate the influence of noise. Along this line, we propose Meta Scaling and Shifting Networks to generate scaling and shifting functions for each item, respectively. The scaling function can directly transform cold item ID embeddings into warm feature space which can fit the model better, and the shifting function is able to produce stable embeddings from the noisy embeddings. With the two meta networks, we propose Meta Warm Up Framework (MWUF) which learns to warm up cold ID embeddings. Moreover, MWUF is a general framework that can be applied upon various existing deep recommendation models. The proposed model is evaluated on three popular benchmarks, including both recommendation and advertising datasets. The evaluation results demonstrate its superior performance and compatibility.
Transfer-Meta Framework for Cross-domain Recommendation to Cold-Start Users
May 11, 2021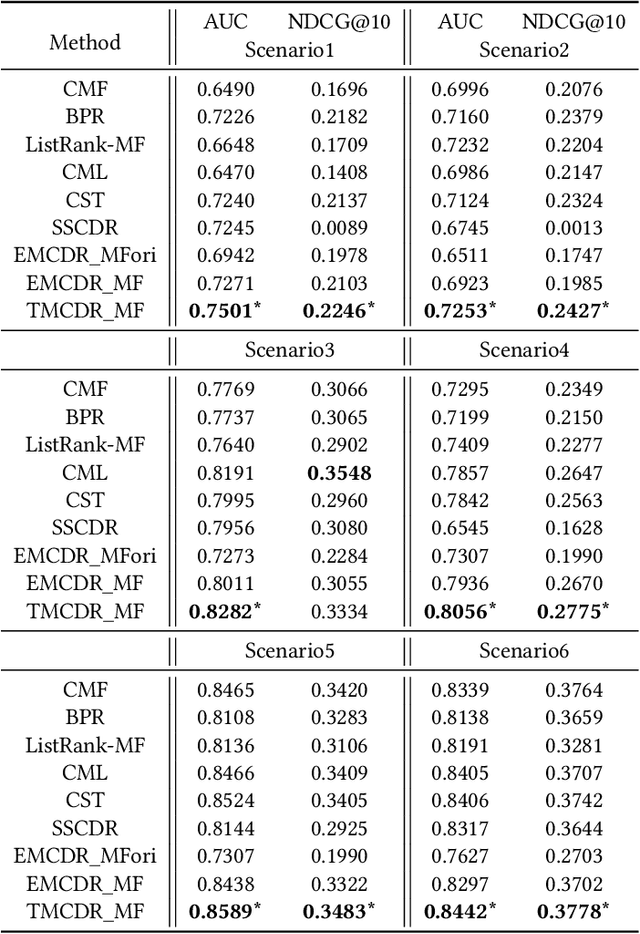
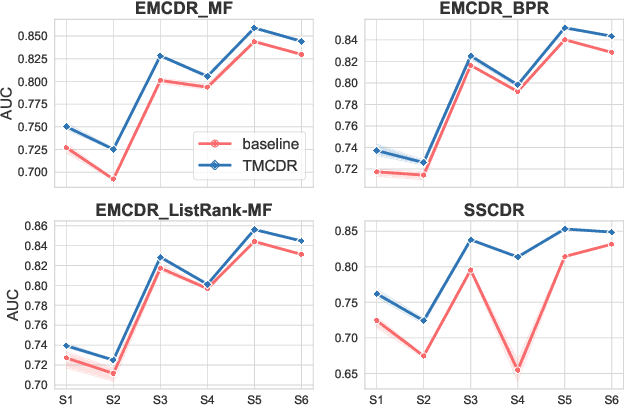
Cold-start problems are enormous challenges in practical recommender systems. One promising solution for this problem is cross-domain recommendation (CDR) which leverages rich information from an auxiliary (source) domain to improve the performance of recommender system in the target domain. In these CDR approaches, the family of Embedding and Mapping methods for CDR (EMCDR) is very effective, which explicitly learn a mapping function from source embeddings to target embeddings with overlapping users. However, these approaches suffer from one serious problem: the mapping function is only learned on limited overlapping users, and the function would be biased to the limited overlapping users, which leads to unsatisfying generalization ability and degrades the performance on cold-start users in the target domain. With the advantage of meta learning which has good generalization ability to novel tasks, we propose a transfer-meta framework for CDR (TMCDR) which has a transfer stage and a meta stage. In the transfer (pre-training) stage, a source model and a target model are trained on source and target domains, respectively. In the meta stage, a task-oriented meta network is learned to implicitly transform the user embedding in the source domain to the target feature space. In addition, the TMCDR is a general framework that can be applied upon various base models, e.g., MF, BPR, CML. By utilizing data from Amazon and Douban, we conduct extensive experiments on 6 cross-domain tasks to demonstrate the superior performance and compatibility of TMCDR.
Long Short-Term Temporal Meta-learning in Online Recommendation
May 08, 2021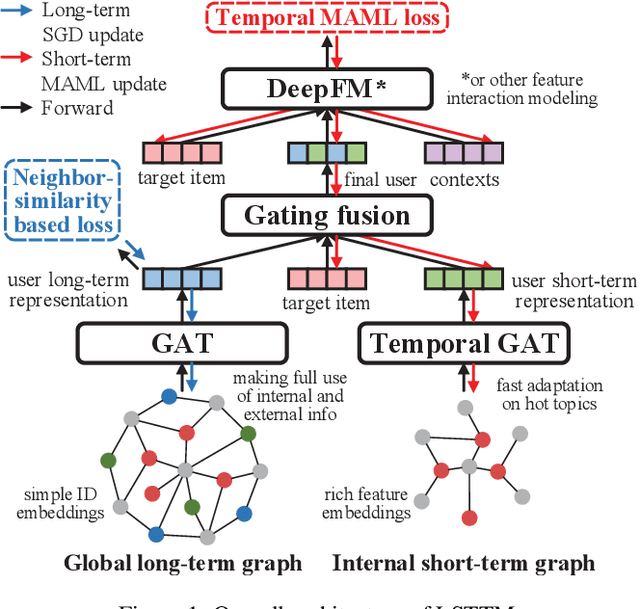


An effective online recommendation system should jointly capture user long-term and short-term preferences in both user internal and external behaviors. However, it is challenging to conduct fast adaptations to variable new topics while making full use of all information in large-scale systems, due to the online efficiency limitation and complexity of real-world systems. To address this, we propose a novel Long Short-Term Temporal Meta-learning framework (LSTTM) for online recommendation, which captures user preferences from a global long-term graph and an internal short-term graph. To improve online learning for short-term interests, we propose a temporal MAML method with asynchronous online updating for fast adaptation, which regards recommendations at different time periods as different tasks. In experiments, LSTTM achieves significant improvements on both offline and online evaluations. LSTTM has also been deployed on a widely-used online system, affecting millions of users. The idea of temporal MAML can be easily transferred to other models and temporal tasks.
UPRec: User-Aware Pre-training for Recommender Systems
Feb 22, 2021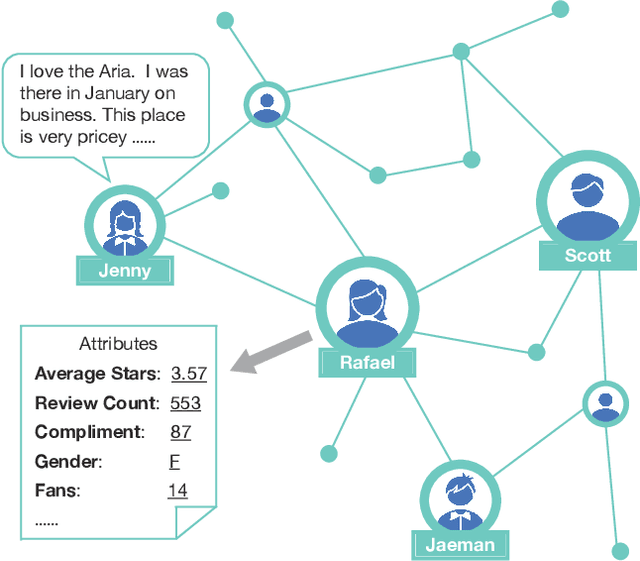


Existing sequential recommendation methods rely on large amounts of training data and usually suffer from the data sparsity problem. To tackle this, the pre-training mechanism has been widely adopted, which attempts to leverage large-scale data to perform self-supervised learning and transfer the pre-trained parameters to downstream tasks. However, previous pre-trained models for recommendation focus on leverage universal sequence patterns from user behaviour sequences and item information, whereas ignore capturing personalized interests with the heterogeneous user information, which has been shown effective in contributing to personalized recommendation. In this paper, we propose a method to enhance pre-trained models with heterogeneous user information, called User-aware Pre-training for Recommendation (UPRec). Specifically, UPRec leverages the user attributes andstructured social graphs to construct self-supervised objectives in the pre-training stage and proposes two user-aware pre-training tasks. Comprehensive experimental results on several real-world large-scale recommendation datasets demonstrate that UPRec can effectively integrate user information into pre-trained models and thus provide more appropriate recommendations for users.
Improving Accuracy and Diversity in Matching of Recommendation with Diversified Preference Network
Feb 07, 2021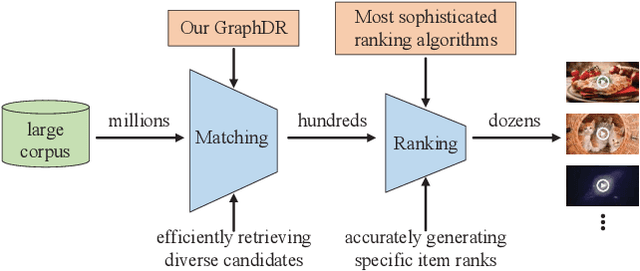

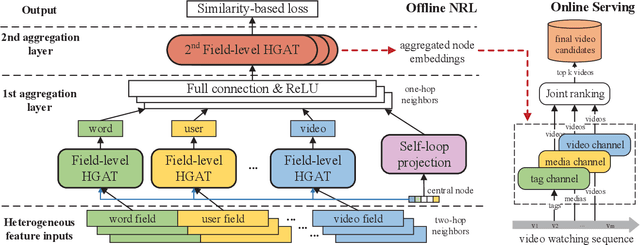
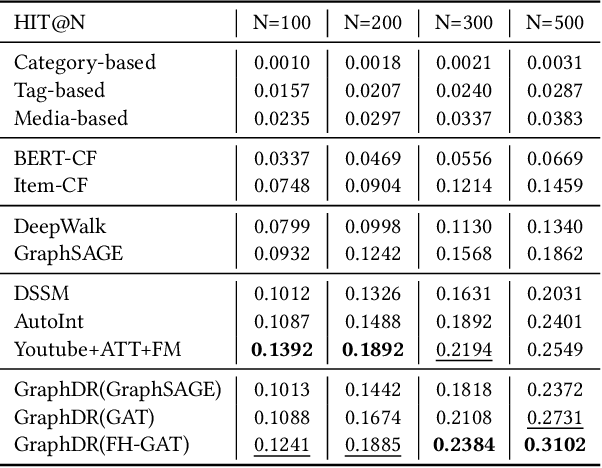
Recently, real-world recommendation systems need to deal with millions of candidates. It is extremely challenging to conduct sophisticated end-to-end algorithms on the entire corpus due to the tremendous computation costs. Therefore, conventional recommendation systems usually contain two modules. The matching module focuses on the coverage, which aims to efficiently retrieve hundreds of items from large corpora, while the ranking module generates specific ranks for these items. Recommendation diversity is an essential factor that impacts user experience. Most efforts have explored recommendation diversity in ranking, while the matching module should take more responsibility for diversity. In this paper, we propose a novel Heterogeneous graph neural network framework for diversified recommendation (GraphDR) in matching to improve both recommendation accuracy and diversity. Specifically, GraphDR builds a huge heterogeneous preference network to record different types of user preferences, and conduct a field-level heterogeneous graph attention network for node aggregation. We also innovatively conduct a neighbor-similarity based loss to balance both recommendation accuracy and diversity for the diversified matching task. In experiments, we conduct extensive online and offline evaluations on a real-world recommendation system with various accuracy and diversity metrics and achieve significant improvements. We also conduct model analyses and case study for a better understanding of our model. Moreover, GraphDR has been deployed on a well-known recommendation system, which affects millions of users. The source code will be released.
Denoising Relation Extraction from Document-level Distant Supervision
Nov 08, 2020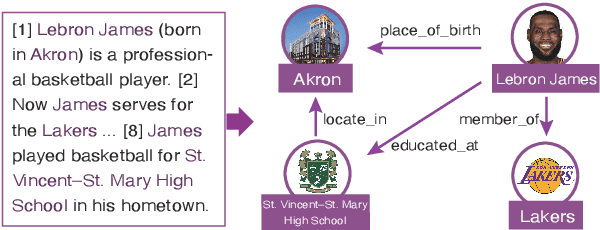
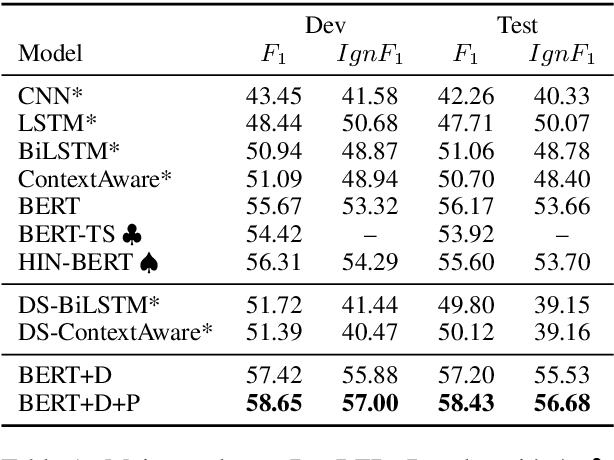
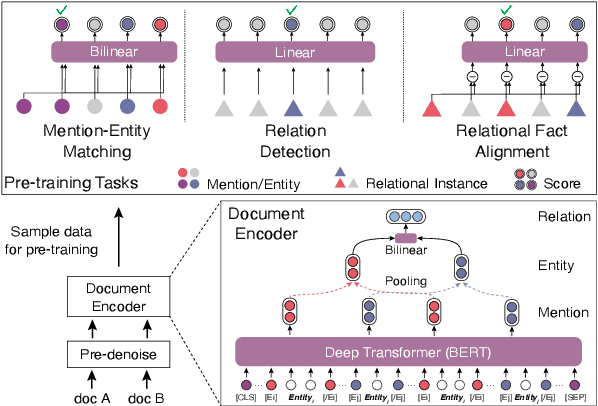
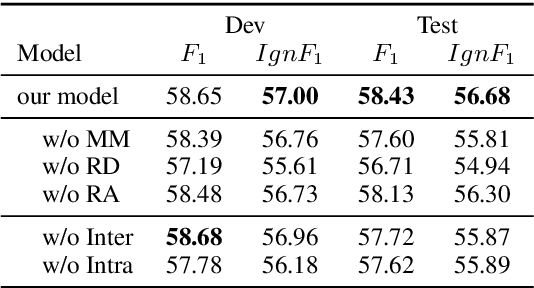
Distant supervision (DS) has been widely used to generate auto-labeled data for sentence-level relation extraction (RE), which improves RE performance. However, the existing success of DS cannot be directly transferred to the more challenging document-level relation extraction (DocRE), since the inherent noise in DS may be even multiplied in document level and significantly harm the performance of RE. To address this challenge, we propose a novel pre-trained model for DocRE, which denoises the document-level DS data via multiple pre-training tasks. Experimental results on the large-scale DocRE benchmark show that our model can capture useful information from noisy DS data and achieve promising results.
Knowledge Transfer via Pre-training for Recommendation: A Review and Prospect
Sep 19, 2020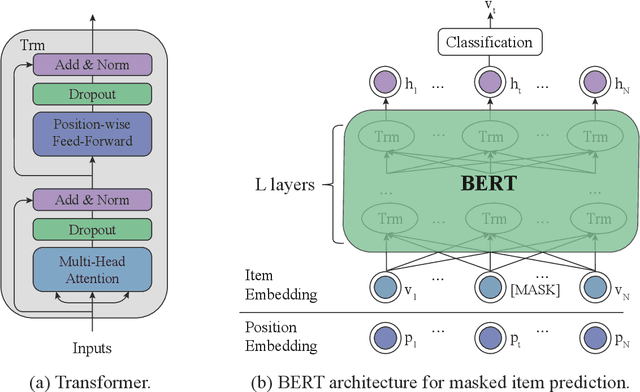
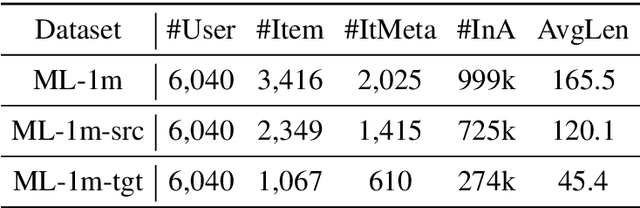
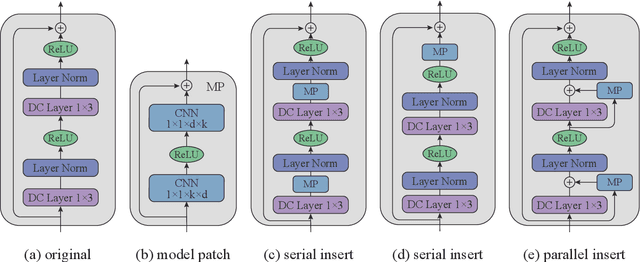
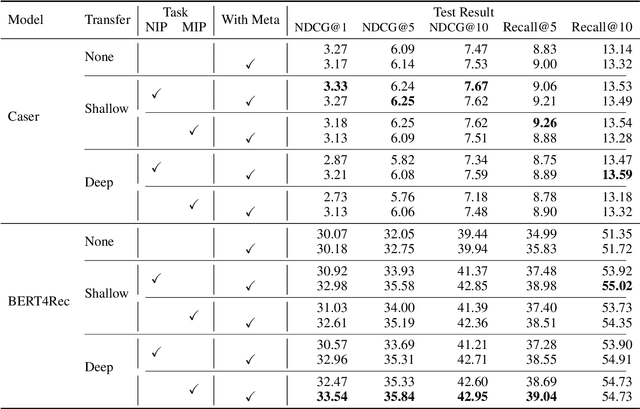
Recommender systems aim to provide item recommendations for users, and are usually faced with data sparsity problem (e.g., cold start) in real-world scenarios. Recently pre-trained models have shown their effectiveness in knowledge transfer between domains and tasks, which can potentially alleviate the data sparsity problem in recommender systems. In this survey, we first provide a review of recommender systems with pre-training. In addition, we show the benefits of pre-training to recommender systems through experiments. Finally, we discuss several promising directions for future research for recommender systems with pre-training.