 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective Surgical Skills Assessment and Tool Localization: Results from the MICCAI 2021 SimSurgSkill Challenge
Dec 08, 2022Timely and effective feedback within surgical training plays a critical role in developing the skills required to perform safe and efficient surgery. Feedback from expert surgeons, while especially valuable in this regard, is challenging to acquire due to their typically busy schedules, and may be subject to biases. Formal assessment procedures like OSATS and GEARS attempt to provide objective measures of skill, but remain time-consuming. With advances in machine learning there is an opportunity for fast and objective automated feedback on technical skills. The SimSurgSkill 2021 challenge (hosted as a sub-challenge of EndoVis at MICCAI 2021) aimed to promote and foster work in this endeavor. Using virtual reality (VR) surgical tasks, competitors were tasked with localizing instruments and predicting surgical skill. Here we summarize the winning approaches and how they performed. Using this publicly available dataset and results as a springboard, future work may enable more efficient training of surgeons with advances in surgical data science. The dataset can be accessed from https://console.cloud.google.com/storage/browser/isi-simsurgskill-2021.
Sources of performance variability in deep learning-based polyp detection
Nov 17, 2022Validation metrics are a key prerequisite for the reliable tracking of scientific progress and for deciding on the potential clinical translation of methods. While recent initiatives aim to develop comprehensive theoretical frameworks for understanding metric-related pitfalls in image analysis problems, there is a lack of experimental evidence on the concrete effects of common and rare pitfalls on specific applications. We address this gap in the literature in the context of colon cancer screening. Our contribution is twofold. Firstly, we present the winning solution of the Endoscopy computer vision challenge (EndoCV) on colon cancer detection, conducted in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2022. Secondly, we demonstrate the sensitivity of commonly used metrics to a range of hyperparameters as well as the consequences of poor metric choices. Based on comprehensive validation studies performed with patient data from six clinical centers, we found all commonly applied object detection metrics to be subject to high inter-center variability. Furthermore, our results clearly demonstrate that the adaptation of standard hyperparameters used in the computer vision community does not generally lead to the clinically most plausible results. Finally, we present localization criteria that correspond well to clinical relevance. Our work could be a first step towards reconsidering common validation strategies in automatic colon cancer screening applications.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
Labeling instructions matter in biomedical image analysis
Jul 20, 2022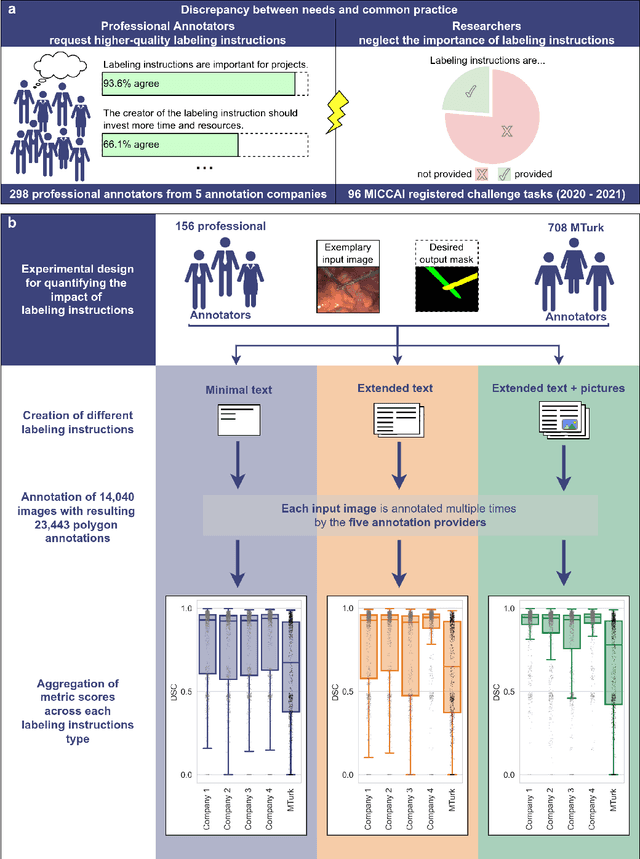
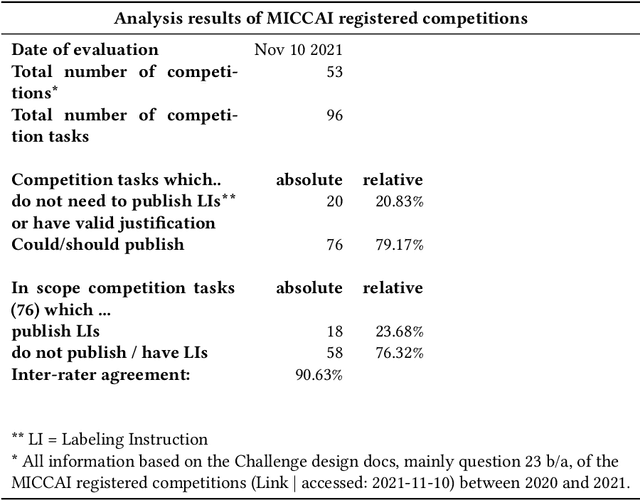
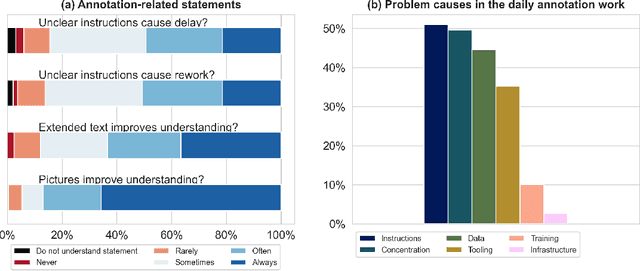
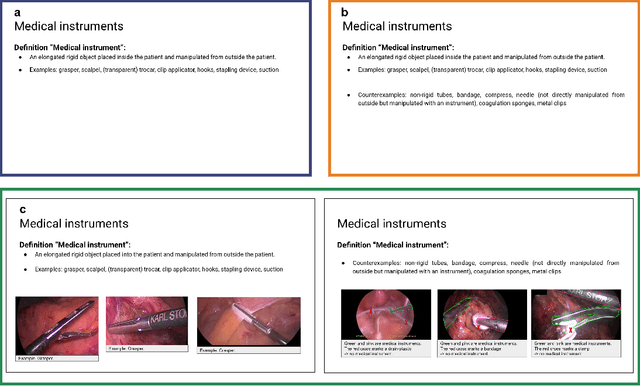
Biomedical image analysis algorithm validation depends on high-quality annotation of reference datasets, for which labeling instructions are key. Despite their importance, their optimization remains largely unexplored. Here, we present the first systematic study of labeling instructions and their impact on annotation quality in the field. Through comprehensive examination of professional practice and international competitions registered at the MICCAI Society, we uncovered a discrepancy between annotators' needs for labeling instructions and their current quality and availability. Based on an analysis of 14,040 images annotated by 156 annotators from four professional companies and 708 Amazon Mechanical Turk (MTurk) crowdworkers using instructions with different information density levels, we further found that including exemplary images significantly boosts annotation performance compared to text-only descriptions, while solely extending text descriptions does not. Finally, professional annotators constantly outperform MTurk crowdworkers. Our study raises awareness for the need of quality standards in biomedical image analysis labeling instructions.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022



The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Ten years of image analysis and machine learning competitions in dementia
Dec 15, 2021
Machine learning methods exploiting multi-parametric biomarkers, especially based on neuroimaging, have huge potential to improve early diagnosis of dementia and to predict which individuals are at-risk of developing dementia. To benchmark algorithms in the field of machine learning and neuroimaging in dementia and assess their potential for use in clinical practice and clinical trials, seven grand challenges have been organized in the last decade: MIRIAD, Alzheimer's Disease Big Data DREAM, CADDementia, Machine Learning Challenge, MCI Neuroimaging, TADPOLE, and the Predictive Analytics Competition. Based on two challenge evaluation frameworks, we analyzed how these grand challenges are complementing each other regarding research questions, datasets, validation approaches, results and impact. The seven grand challenges addressed questions related to screening, diagnosis, prediction and monitoring in (pre-clinical) dementia. There was little overlap in clinical questions, tasks and performance metrics. Whereas this has the advantage of providing insight on a broad range of questions, it also limits the validation of results across challenges. In general, winning algorithms performed rigorous data pre-processing and combined a wide range of input features. Despite high state-of-the-art performances, most of the methods evaluated by the challenges are not clinically used. To increase impact, future challenges could pay more attention to statistical analysis of which factors (i.e., features, models) relate to higher performance, to clinical questions beyond Alzheimer's disease, and to using testing data beyond the Alzheimer's Disease Neuroimaging Initiative. Given the potential and lessons learned in the past ten years, we are excited by the prospects of grand challenges in machine learning and neuroimaging for the next ten years and beyond.
Robust deep learning-based semantic organ segmentation in hyperspectral images
Nov 09, 2021Semantic image segmentation is an important prerequisite for context-awareness and autonomous robotics in surgery. The state of the art has focused on conventional RGB video data acquired during minimally invasive surgery, but full-scene semantic segmentation based on spectral imaging data and obtained during open surgery has received almost no attention to date. To address this gap in the literature, we are investigating the following research questions based on hyperspectral imaging (HSI) data of pigs acquired in an open surgery setting: (1) What is an adequate representation of HSI data for neural network-based fully automated organ segmentation, especially with respect to the spatial granularity of the data (pixels vs. superpixels vs. patches vs. full images)? (2) Is there a benefit of using HSI data compared to other modalities, namely RGB data and processed HSI data (e.g. tissue parameters like oxygenation), when performing semantic organ segmentation? According to a comprehensive validation study based on 506 HSI images from 20 pigs, annotated with a total of 19 classes, deep learning-based segmentation performance increases - consistently across modalities - with the spatial context of the input data. Unprocessed HSI data offers an advantage over RGB data or processed data from the camera provider, with the advantage increasing with decreasing size of the input to the neural network. Maximum performance (HSI applied to whole images) yielded a mean dice similarity coefficient (DSC) of 0.89 (standard deviation (SD) 0.04), which is in the range of the inter-rater variability (DSC of 0.89 (SD 0.07)). We conclude that HSI could become a powerful image modality for fully-automatic surgical scene understanding with many advantages over traditional imaging, including the ability to recover additional functional tissue information.
Comparative Validation of Machine Learning Algorithms for Surgical Workflow and Skill Analysis with the HeiChole Benchmark
Sep 30, 2021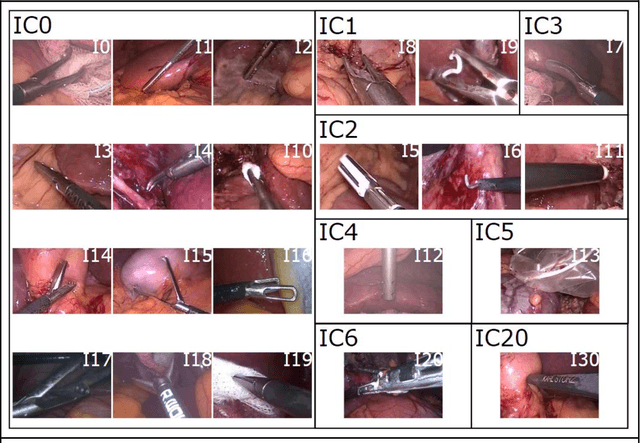
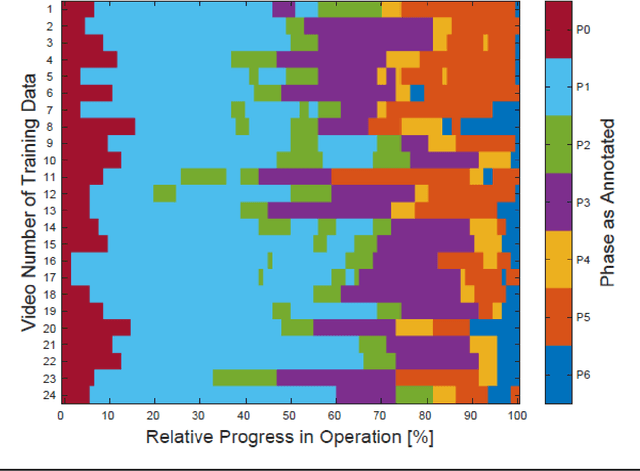
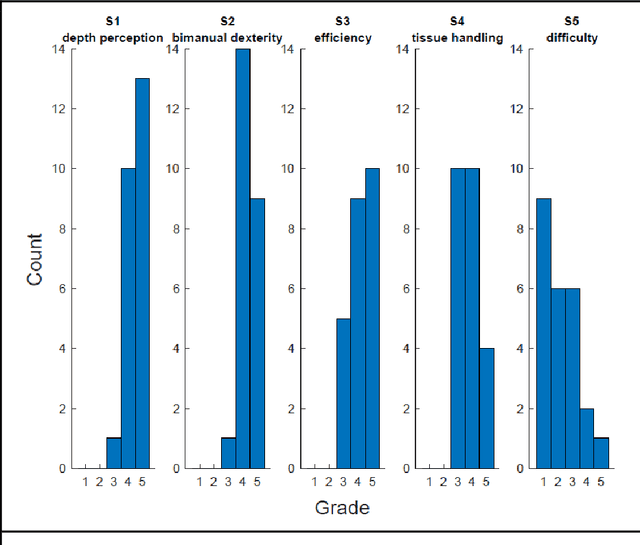
PURPOSE: Surgical workflow and skill analysis are key technologies for the next generation of cognitive surgical assistance systems. These systems could increase the safety of the operation through context-sensitive warnings and semi-autonomous robotic assistance or improve training of surgeons via data-driven feedback. In surgical workflow analysis up to 91% average precision has been reported for phase recognition on an open data single-center dataset. In this work we investigated the generalizability of phase recognition algorithms in a multi-center setting including more difficult recognition tasks such as surgical action and surgical skill. METHODS: To achieve this goal, a dataset with 33 laparoscopic cholecystectomy videos from three surgical centers with a total operation time of 22 hours was created. Labels included annotation of seven surgical phases with 250 phase transitions, 5514 occurences of four surgical actions, 6980 occurences of 21 surgical instruments from seven instrument categories and 495 skill classifications in five skill dimensions. The dataset was used in the 2019 Endoscopic Vision challenge, sub-challenge for surgical workflow and skill analysis. Here, 12 teams submitted their machine learning algorithms for recognition of phase, action, instrument and/or skill assessment. RESULTS: F1-scores were achieved for phase recognition between 23.9% and 67.7% (n=9 teams), for instrument presence detection between 38.5% and 63.8% (n=8 teams), but for action recognition only between 21.8% and 23.3% (n=5 teams). The average absolute error for skill assessment was 0.78 (n=1 team). CONCLUSION: Surgical workflow and skill analysis are promising technologies to support the surgical team, but are not solved yet, as shown by our comparison of algorithms. This novel benchmark can be used for comparable evaluation and validation of future work.
Task Fingerprinting for Meta Learning in Biomedical Image Analysis
Jul 08, 2021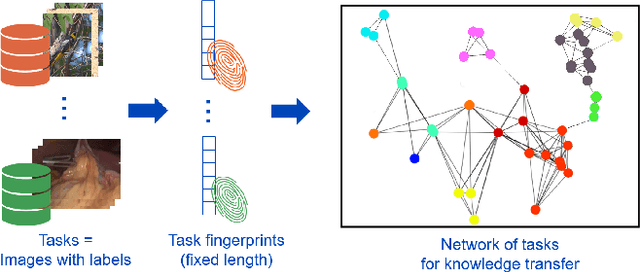
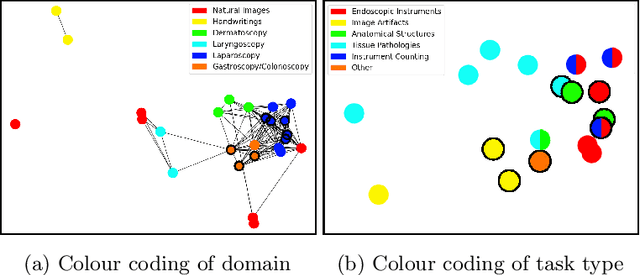
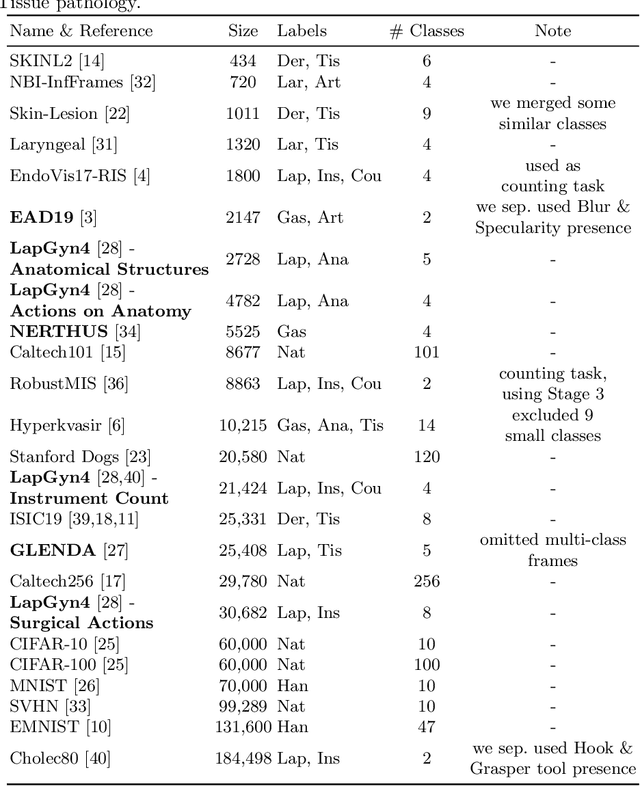
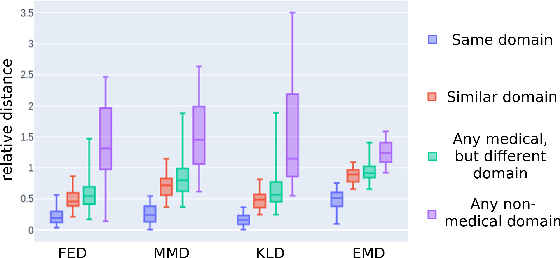
Shortage of annotated data is one of the greatest bottlenecks in biomedical image analysis. Meta learning studies how learning systems can increase in efficiency through experience and could thus evolve as an important concept to overcome data sparsity. However, the core capability of meta learning-based approaches is the identification of similar previous tasks given a new task - a challenge largely unexplored in the biomedical imaging domain. In this paper, we address the problem of quantifying task similarity with a concept that we refer to as task fingerprinting. The concept involves converting a given task, represented by imaging data and corresponding labels, to a fixed-length vector representation. In fingerprint space, different tasks can be directly compared irrespective of their data set sizes, types of labels or specific resolutions. An initial feasibility study in the field of surgical data science (SDS) with 26 classification tasks from various medical and non-medical domains suggests that task fingerprinting could be leveraged for both (1) selecting appropriate data sets for pretraining and (2) selecting appropriate architectures for a new task. Task fingerprinting could thus become an important tool for meta learning in SDS and other fields of biomedical image analysis.
How can we learn from challenges? A statistical approach to driving future algorithm development
Jun 17, 2021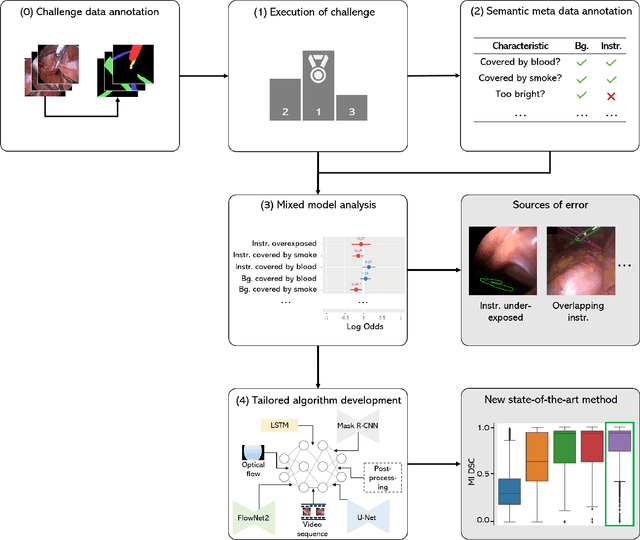


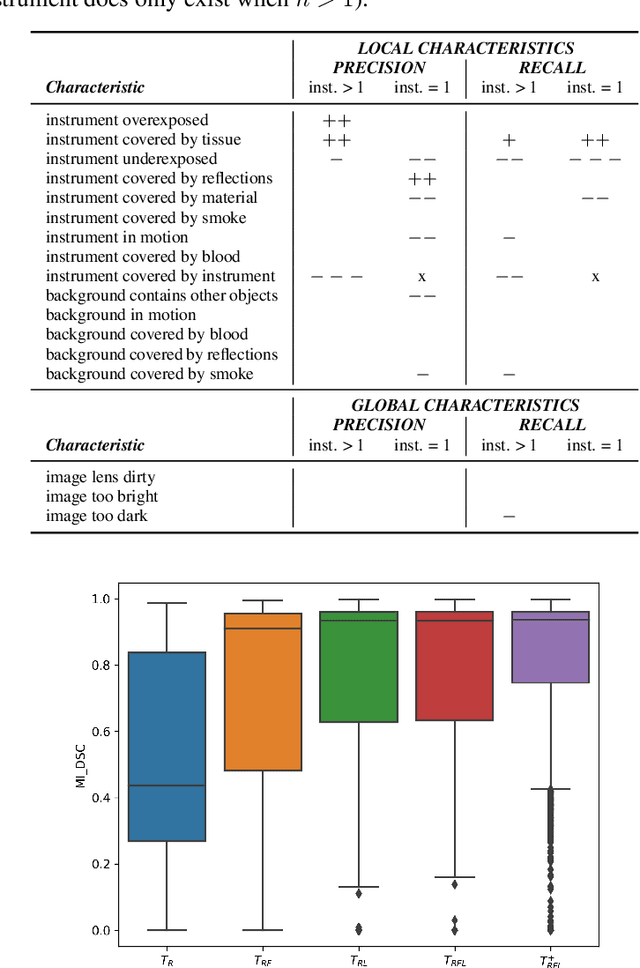
Challenges have become the state-of-the-art approach to benchmark image analysis algorithms in a comparative manner. While the validation on identical data sets was a great step forward, results analysis is often restricted to pure ranking tables, leaving relevant questions unanswered. Specifically, little effort has been put into the systematic investigation on what characterizes images in which state-of-the-art algorithms fail. To address this gap in the literature, we (1) present a statistical framework for learning from challenges and (2) instantiate it for the specific task of instrument instance segmentation in laparoscopic videos. Our framework relies on the semantic meta data annotation of images, which serves as foundation for a General Linear Mixed Models (GLMM) analysis. Based on 51,542 meta data annotations performed on 2,728 images, we applied our approach to the results of the Robust Medical Instrument Segmentation Challenge (ROBUST-MIS) challenge 2019 and revealed underexposure, motion and occlusion of instruments as well as the presence of smoke or other objects in the background as major sources of algorithm failure. Our subsequent method development, tailored to the specific remaining issues, yielded a deep learning model with state-of-the-art overall performance and specific strengths in the processing of images in which previous methods tended to fail. Due to the objectivity and generic applicability of our approach, it could become a valuable tool for validation in the field of medical image analysis and beyond. and segmentation of small, crossing, moving and transparent instrument(s) (parts).