 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-aware Monocular Depth Estimation for Minimally Invasive Surgery
Mar 03, 2026Purpose: Monocular depth estimation (MDE) is vital for scene understanding in minimally invasive surgery (MIS). However, endoscopic video sequences are often contaminated by smoke, specular reflections, blur, and occlusions, limiting the accuracy of MDE models. In addition, current MDE models do not output depth confidence, which could be a valuable tool for improving their clinical reliability. Methods: We propose a novel confidence-aware MDE framework featuring three significant contributions: (i) Calibrated confidence targets: an ensemble of fine-tuned stereo matching models is used to capture disparity variance into pixel-wise confidence probabilities; (ii) Confidence-aware loss: Baseline MDE models are optimized with confidence-aware loss functions, utilizing pixel-wise confidence probabilities such that reliable pixels dominate training; and (iii) Inference-time confidence: a confidence estimation head is proposed with two convolution layers to predict per-pixel confidence at inference, enabling assessment of depth reliability. Results: Comprehensive experimental validation across internal and public datasets demonstrates that our framework improves depth estimation accuracy and can robustly quantify the prediction's confidence. On the internal clinical endoscopic dataset (StereoKP), we improve dense depth estimation accuracy by ~8% as compared to the baseline model. Conclusion: Our confidence-aware framework enables improved accuracy of MDE models in MIS, addressing challenges posed by noise and artifacts in pre-clinical and clinical data, and allows MDE models to provide confidence maps that may be used to improve their reliability for clinical applications.
SAR-RARP50: Segmentation of surgical instrumentation and Action Recognition on Robot-Assisted Radical Prostatectomy Challenge
Dec 31, 2023



Surgical tool segmentation and action recognition are fundamental building blocks in many computer-assisted intervention applications, ranging from surgical skills assessment to decision support systems. Nowadays, learning-based action recognition and segmentation approaches outperform classical methods, relying, however, on large, annotated datasets. Furthermore, action recognition and tool segmentation algorithms are often trained and make predictions in isolation from each other, without exploiting potential cross-task relationships. With the EndoVis 2022 SAR-RARP50 challenge, we release the first multimodal, publicly available, in-vivo, dataset for surgical action recognition and semantic instrumentation segmentation, containing 50 suturing video segments of Robotic Assisted Radical Prostatectomy (RARP). The aim of the challenge is twofold. First, to enable researchers to leverage the scale of the provided dataset and develop robust and highly accurate single-task action recognition and tool segmentation approaches in the surgical domain. Second, to further explore the potential of multitask-based learning approaches and determine their comparative advantage against their single-task counterparts. A total of 12 teams participated in the challenge, contributing 7 action recognition methods, 9 instrument segmentation techniques, and 4 multitask approaches that integrated both action recognition and instrument segmentation.
Objective Surgical Skills Assessment and Tool Localization: Results from the MICCAI 2021 SimSurgSkill Challenge
Dec 08, 2022Timely and effective feedback within surgical training plays a critical role in developing the skills required to perform safe and efficient surgery. Feedback from expert surgeons, while especially valuable in this regard, is challenging to acquire due to their typically busy schedules, and may be subject to biases. Formal assessment procedures like OSATS and GEARS attempt to provide objective measures of skill, but remain time-consuming. With advances in machine learning there is an opportunity for fast and objective automated feedback on technical skills. The SimSurgSkill 2021 challenge (hosted as a sub-challenge of EndoVis at MICCAI 2021) aimed to promote and foster work in this endeavor. Using virtual reality (VR) surgical tasks, competitors were tasked with localizing instruments and predicting surgical skill. Here we summarize the winning approaches and how they performed. Using this publicly available dataset and results as a springboard, future work may enable more efficient training of surgeons with advances in surgical data science. The dataset can be accessed from https://console.cloud.google.com/storage/browser/isi-simsurgskill-2021.
Surgical Visual Domain Adaptation: Results from the MICCAI 2020 SurgVisDom Challenge
Feb 26, 2021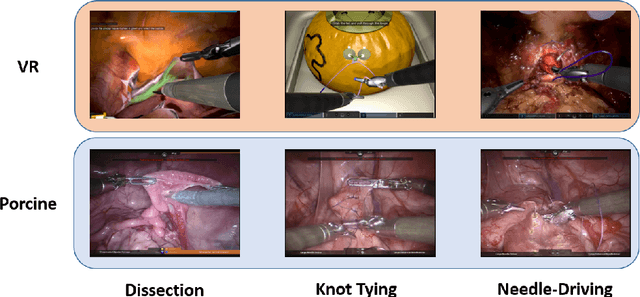
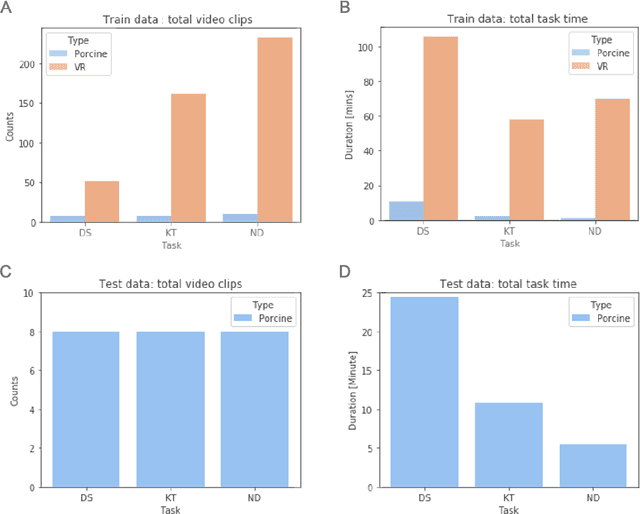
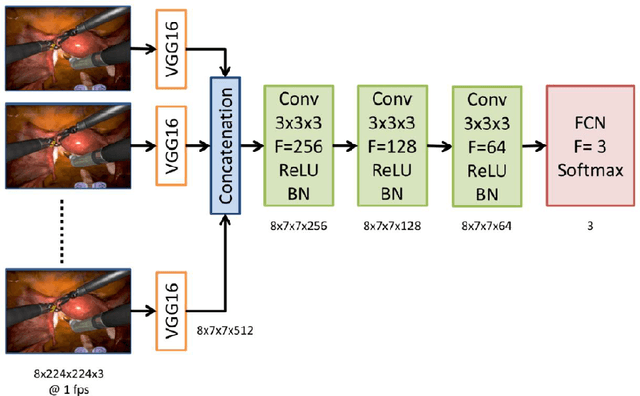
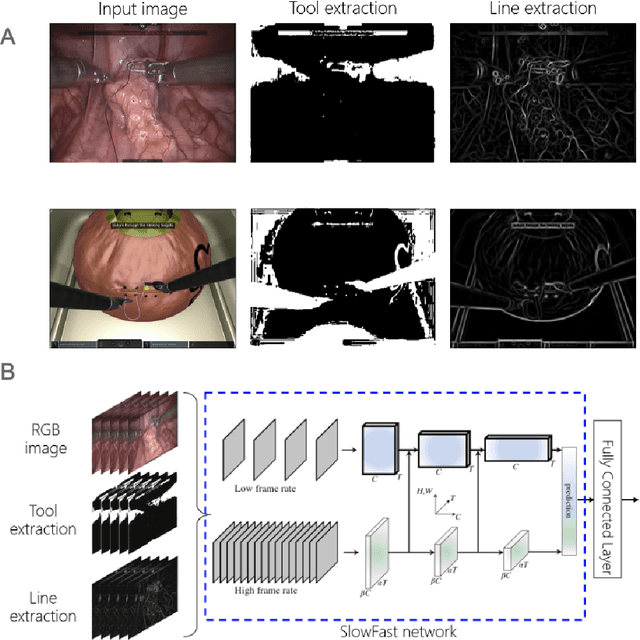
Surgical data science is revolutionizing minimally invasive surgery by enabling context-aware applications. However, many challenges exist around surgical data (and health data, more generally) needed to develop context-aware models. This work - presented as part of the Endoscopic Vision (EndoVis) challenge at the Medical Image Computing and Computer Assisted Intervention (MICCAI) 2020 conference - seeks to explore the potential for visual domain adaptation in surgery to overcome data privacy concerns. In particular, we propose to use video from virtual reality (VR) simulations of surgical exercises in robotic-assisted surgery to develop algorithms to recognize tasks in a clinical-like setting. We present the performance of the different approaches to solve visual domain adaptation developed by challenge participants. Our analysis shows that the presented models were unable to learn meaningful motion based features form VR data alone, but did significantly better when small amount of clinical-like data was also made available. Based on these results, we discuss promising methods and further work to address the problem of visual domain adaptation in surgical data science. We also release the challenge dataset publicly at https://www.synapse.org/surgvisdom2020.
Synthetic and Real Inputs for Tool Segmentation in Robotic Surgery
Jul 26, 2020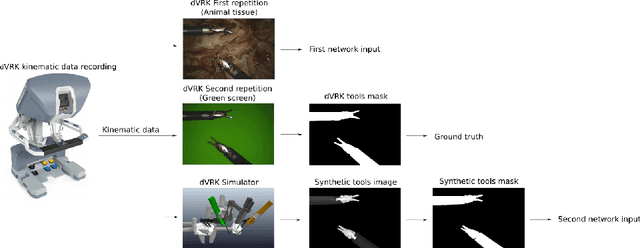
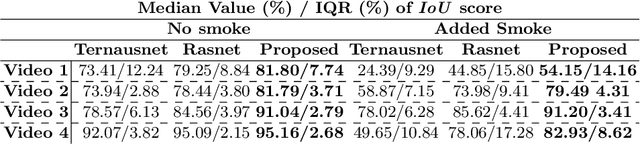
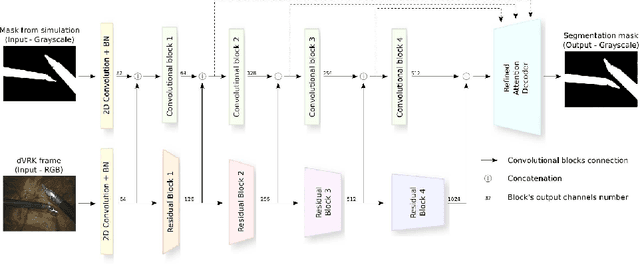
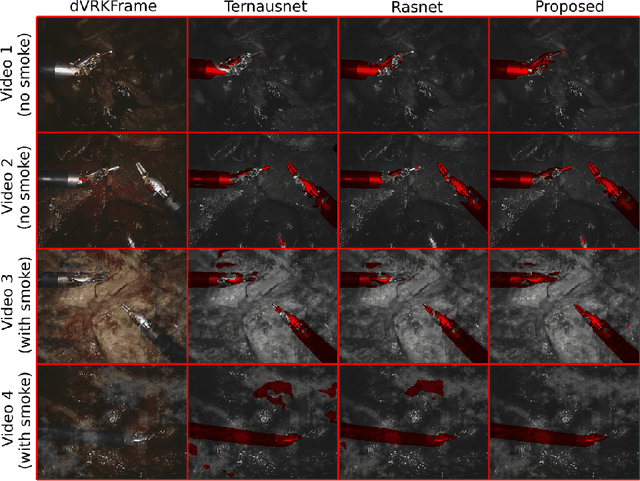
Semantic tool segmentation in surgical videos is important for surgical scene understanding and computer-assisted interventions as well as for the development of robotic automation. The problem is challenging because different illumination conditions, bleeding, smoke and occlusions can reduce algorithm robustness. At present labelled data for training deep learning models is still lacking for semantic surgical instrument segmentation and in this paper we show that it may be possible to use robot kinematic data coupled with laparoscopic images to alleviate the labelling problem. We propose a new deep learning based model for parallel processing of both laparoscopic and simulation images for robust segmentation of surgical tools. Due to the lack of laparoscopic frames annotated with both segmentation ground truth and kinematic information a new custom dataset was generated using the da Vinci Research Kit (dVRK) and is made available.