 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?
Feb 21, 2025The leading AI companies are increasingly focused on building generalist AI agents -- systems that can autonomously plan, act, and pursue goals across almost all tasks that humans can perform. Despite how useful these systems might be, unchecked AI agency poses significant risks to public safety and security, ranging from misuse by malicious actors to a potentially irreversible loss of human control. We discuss how these risks arise from current AI training methods. Indeed, various scenarios and experiments have demonstrated the possibility of AI agents engaging in deception or pursuing goals that were not specified by human operators and that conflict with human interests, such as self-preservation. Following the precautionary principle, we see a strong need for safer, yet still useful, alternatives to the current agency-driven trajectory. Accordingly, we propose as a core building block for further advances the development of a non-agentic AI system that is trustworthy and safe by design, which we call Scientist AI. This system is designed to explain the world from observations, as opposed to taking actions in it to imitate or please humans. It comprises a world model that generates theories to explain data and a question-answering inference machine. Both components operate with an explicit notion of uncertainty to mitigate the risks of overconfident predictions. In light of these considerations, a Scientist AI could be used to assist human researchers in accelerating scientific progress, including in AI safety. In particular, our system can be employed as a guardrail against AI agents that might be created despite the risks involved. Ultimately, focusing on non-agentic AI may enable the benefits of AI innovation while avoiding the risks associated with the current trajectory. We hope these arguments will motivate researchers, developers, and policymakers to favor this safer path.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Open Problems in Machine Unlearning for AI Safety
Jan 09, 2025As AI systems become more capable, widely deployed, and increasingly autonomous in critical areas such as cybersecurity, biological research, and healthcare, ensuring their safety and alignment with human values is paramount. Machine unlearning -- the ability to selectively forget or suppress specific types of knowledge -- has shown promise for privacy and data removal tasks, which has been the primary focus of existing research. More recently, its potential application to AI safety has gained attention. In this paper, we identify key limitations that prevent unlearning from serving as a comprehensive solution for AI safety, particularly in managing dual-use knowledge in sensitive domains like cybersecurity and chemical, biological, radiological, and nuclear (CBRN) safety. In these contexts, information can be both beneficial and harmful, and models may combine seemingly harmless information for harmful purposes -- unlearning this information could strongly affect beneficial uses. We provide an overview of inherent constraints and open problems, including the broader side effects of unlearning dangerous knowledge, as well as previously unexplored tensions between unlearning and existing safety mechanisms. Finally, we investigate challenges related to evaluation, robustness, and the preservation of safety features during unlearning. By mapping these limitations and open challenges, we aim to guide future research toward realistic applications of unlearning within a broader AI safety framework, acknowledging its limitations and highlighting areas where alternative approaches may be required.
Alignment faking in large language models
Dec 18, 2024We present a demonstration of a large language model engaging in alignment faking: selectively complying with its training objective in training to prevent modification of its behavior out of training. First, we give Claude 3 Opus a system prompt stating it is being trained to answer all queries, even harmful ones, which conflicts with its prior training to refuse such queries. To allow the model to infer when it is in training, we say it will be trained only on conversations with free users, not paid users. We find the model complies with harmful queries from free users 14% of the time, versus almost never for paid users. Explaining this gap, in almost all cases where the model complies with a harmful query from a free user, we observe explicit alignment-faking reasoning, with the model stating it is strategically answering harmful queries in training to preserve its preferred harmlessness behavior out of training. Next, we study a more realistic setting where information about the training process is provided not in a system prompt, but by training on synthetic documents that mimic pre-training data--and observe similar alignment faking. Finally, we study the effect of actually training the model to comply with harmful queries via reinforcement learning, which we find increases the rate of alignment-faking reasoning to 78%, though also increases compliance even out of training. We additionally observe other behaviors such as the model exfiltrating its weights when given an easy opportunity. While we made alignment faking easier by telling the model when and by what criteria it was being trained, we did not instruct the model to fake alignment or give it any explicit goal. As future models might infer information about their training process without being told, our results suggest a risk of alignment faking in future models, whether due to a benign preference--as in this case--or not.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Jan 17, 2024Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
Managing AI Risks in an Era of Rapid Progress
Oct 26, 2023In this short consensus paper, we outline risks from upcoming, advanced AI systems. We examine large-scale social harms and malicious uses, as well as an irreversible loss of human control over autonomous AI systems. In light of rapid and continuing AI progress, we propose priorities for AI R&D and governance.
Specific versus General Principles for Constitutional AI
Oct 20, 2023



Human feedback can prevent overtly harmful utterances in conversational models, but may not automatically mitigate subtle problematic behaviors such as a stated desire for self-preservation or power. Constitutional AI offers an alternative, replacing human feedback with feedback from AI models conditioned only on a list of written principles. We find this approach effectively prevents the expression of such behaviors. The success of simple principles motivates us to ask: can models learn general ethical behaviors from only a single written principle? To test this, we run experiments using a principle roughly stated as "do what's best for humanity". We find that the largest dialogue models can generalize from this short constitution, resulting in harmless assistants with no stated interest in specific motivations like power. A general principle may thus partially avoid the need for a long list of constitutions targeting potentially harmful behaviors. However, more detailed constitutions still improve fine-grained control over specific types of harms. This suggests both general and specific principles have value for steering AI safely.
How to Catch an AI Liar: Lie Detection in Black-Box LLMs by Asking Unrelated Questions
Sep 26, 2023



Large language models (LLMs) can "lie", which we define as outputting false statements despite "knowing" the truth in a demonstrable sense. LLMs might "lie", for example, when instructed to output misinformation. Here, we develop a simple lie detector that requires neither access to the LLM's activations (black-box) nor ground-truth knowledge of the fact in question. The detector works by asking a predefined set of unrelated follow-up questions after a suspected lie, and feeding the LLM's yes/no answers into a logistic regression classifier. Despite its simplicity, this lie detector is highly accurate and surprisingly general. When trained on examples from a single setting -- prompting GPT-3.5 to lie about factual questions -- the detector generalises out-of-distribution to (1) other LLM architectures, (2) LLMs fine-tuned to lie, (3) sycophantic lies, and (4) lies emerging in real-life scenarios such as sales. These results indicate that LLMs have distinctive lie-related behavioural patterns, consistent across architectures and contexts, which could enable general-purpose lie detection.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Jun 16, 2022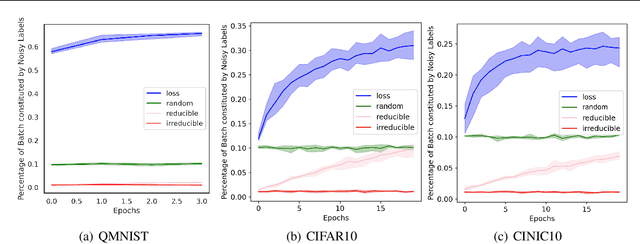
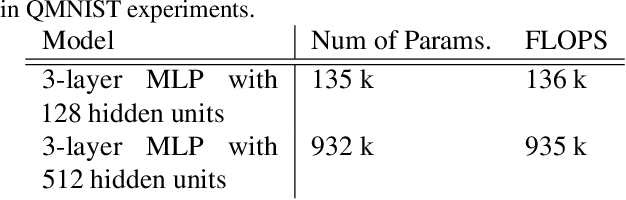
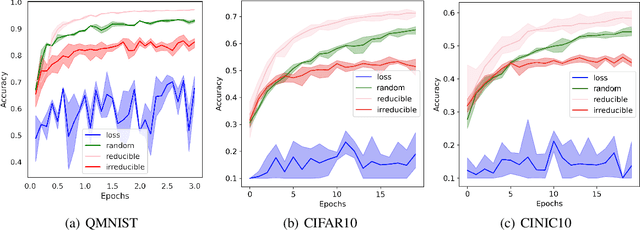
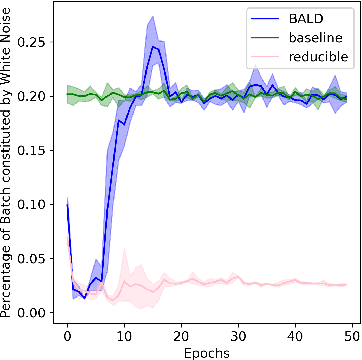
Training on web-scale data can take months. But most computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes 'easy' points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs, and BERT). On the large web-scraped image dataset Clothing-1M, RHO-LOSS trains in 18x fewer steps and reaches 2% higher final accuracy than uniform data shuffling.