 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastively Smoothed Class Alignment for Unsupervised Domain Adaptation
Sep 13, 2019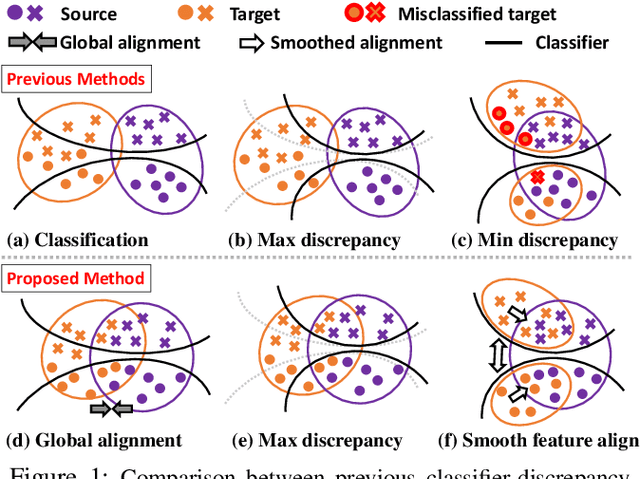
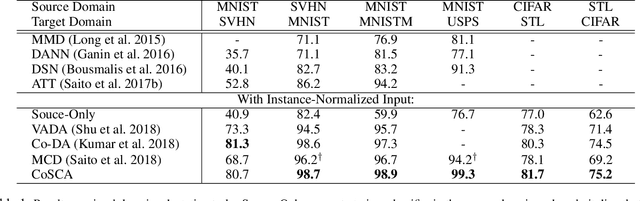
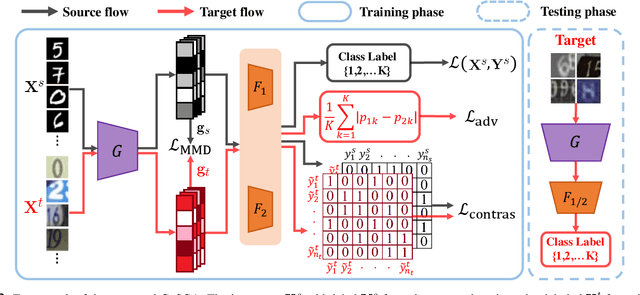
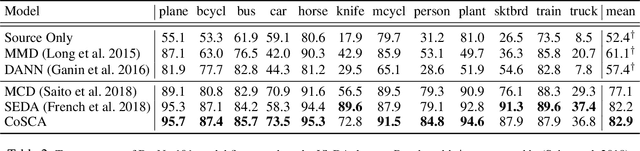
Recent unsupervised approaches to domain adaptation primarily focus on minimizing the gap between the source and the target domains through refining the feature generator, in order to learn a better alignment between the two domains. This minimization can be achieved via a domain classifier to detect target-domain features that are divergent from source-domain features. However, by optimizing via such domain classification discrepancy, ambiguous target samples that are not smoothly distributed on the low-dimensional data manifold are often missed. To solve this issue, we propose a novel Contrastively Smoothed Class Alignment (CoSCA) model, that explicitly incorporates both intra- and inter-class domain discrepancy to better align ambiguous target samples with the source domain. CoSCA estimates the underlying label hypothesis of target samples, and simultaneously adapts their feature representations by optimizing a proposed contrastive loss. In addition, Maximum Mean Discrepancy (MMD) is utilized to directly match features between source and target samples for better global alignment. Experiments on several benchmark datasets demonstrate that CoSCA can outperform state-of-the-art approaches for unsupervised domain adaptation by producing more discriminative features.
LMVP: Video Predictor with Leaked Motion Information
Jun 24, 2019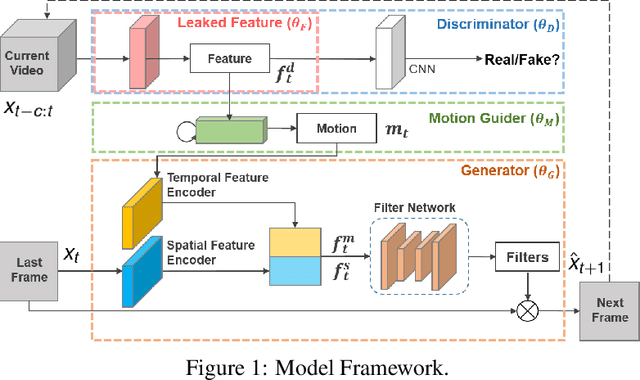
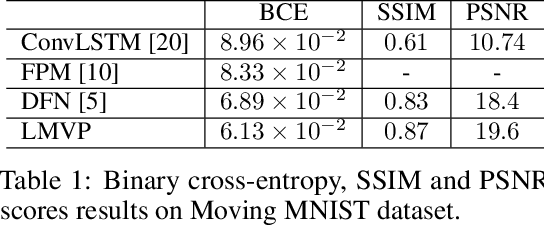


We propose a Leaked Motion Video Predictor (LMVP) to predict future frames by capturing the spatial and temporal dependencies from given inputs. The motion is modeled by a newly proposed component, motion guider, which plays the role of both learner and teacher. Specifically, it {\em learns} the temporal features from real data and {\em guides} the generator to predict future frames. The spatial consistency in video is modeled by an adaptive filtering network. To further ensure the spatio-temporal consistency of the prediction, a discriminator is also adopted to distinguish the real and generated frames. Further, the discriminator leaks information to the motion guider and the generator to help the learning of motion. The proposed LMVP can effectively learn the static and temporal features in videos without the need for human labeling. Experiments on synthetic and real data demonstrate that LMVP can yield state-of-the-art results.
Adversarial Self-Paced Learning for Mixture Models of Hawkes Processes
Jun 20, 2019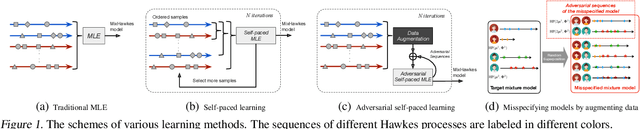

We propose a novel adversarial learning strategy for mixture models of Hawkes processes, leveraging data augmentation techniques of Hawkes process in the framework of self-paced learning. Instead of learning a mixture model directly from a set of event sequences drawn from different Hawkes processes, the proposed method learns the target model iteratively, which generates "easy" sequences and uses them in an adversarial and self-paced manner. In each iteration, we first generate a set of augmented sequences from original observed sequences. Based on the fact that an easy sample of the target model can be an adversarial sample of a misspecified model, we apply a maximum likelihood estimation with an adversarial self-paced mechanism. In this manner the target model is updated, and the augmented sequences that obey it are employed for the next learning iteration. Experimental results show that the proposed method outperforms traditional methods consistently.
Learning Compressed Sentence Representations for On-Device Text Processing
Jun 19, 2019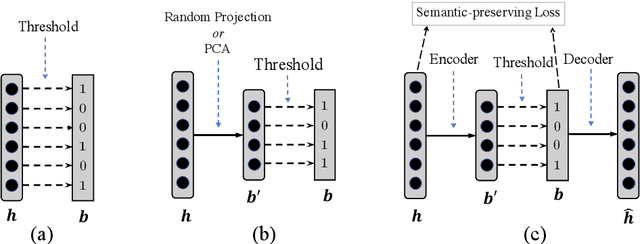
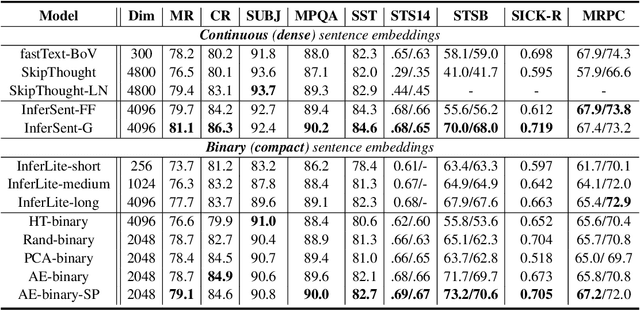

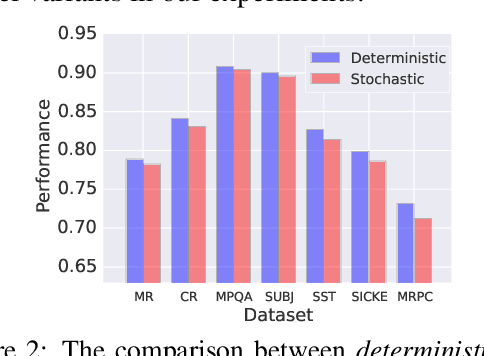
Vector representations of sentences, trained on massive text corpora, are widely used as generic sentence embeddings across a variety of NLP problems. The learned representations are generally assumed to be continuous and real-valued, giving rise to a large memory footprint and slow retrieval speed, which hinders their applicability to low-resource (memory and computation) platforms, such as mobile devices. In this paper, we propose four different strategies to transform continuous and generic sentence embeddings into a binarized form, while preserving their rich semantic information. The introduced methods are evaluated across a wide range of downstream tasks, where the binarized sentence embeddings are demonstrated to degrade performance by only about 2% relative to their continuous counterparts, while reducing the storage requirement by over 98%. Moreover, with the learned binary representations, the semantic relatedness of two sentences can be evaluated by simply calculating their Hamming distance, which is more computational efficient compared with the inner product operation between continuous embeddings. Detailed analysis and case study further validate the effectiveness of proposed methods.
Interpretable ICD Code Embeddings with Self- and Mutual-Attention Mechanisms
Jun 13, 2019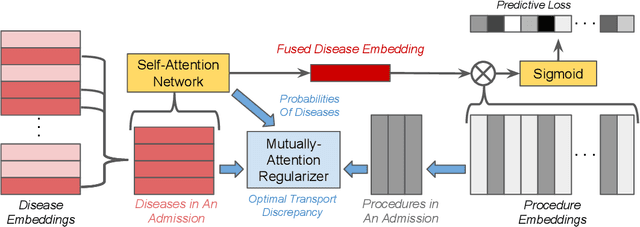
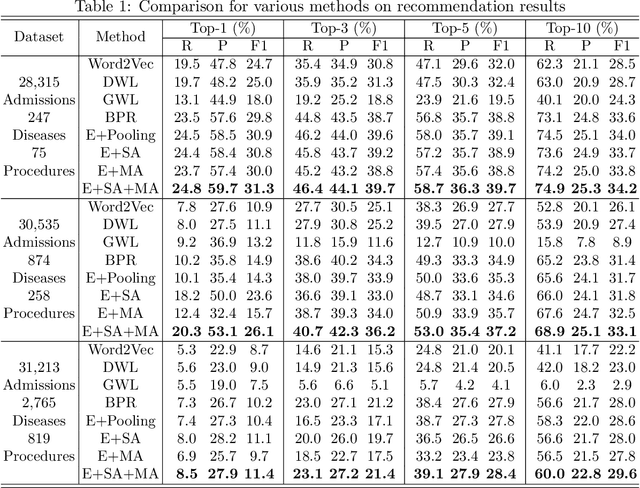
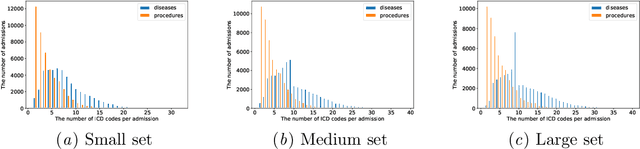
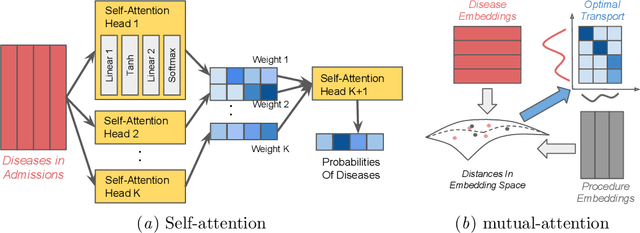
We propose a novel and interpretable embedding method to represent the international statistical classification codes of diseases and related health problems (i.e., ICD codes). This method considers a self-attention mechanism within the disease domain and a mutual-attention mechanism jointly between diseases and procedures. This framework captures the clinical relationships between the disease codes and procedures associated with hospital admissions, and it predicts procedures according to diagnosed diseases. A self-attention network is learned to fuse the embeddings of the diseases for each admission. The similarities between the fused disease embedding and the procedure embeddings indicate which procedure should potentially be recommended. Additionally, when learning the embeddings of the ICD codes, the optimal transport between the diseases and the procedures within each admission is calculated as a regularizer of the embeddings. The optimal transport provides a mutual-attention map between diseases and the procedures, which suppresses the ambiguity within their clinical relationships. The proposed method achieves clinically-interpretable embeddings of ICD codes, and outperforms state-of-the-art embedding methods in procedure recommendation.
Towards Amortized Ranking-Critical Training for Collaborative Filtering
Jun 10, 2019
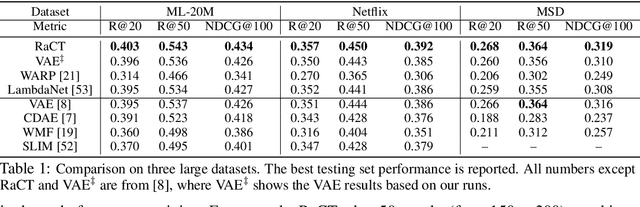

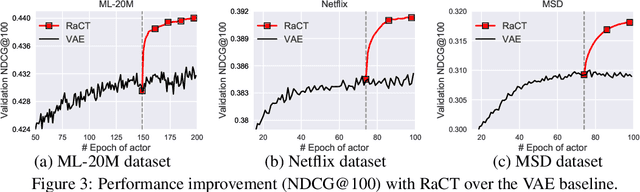
Collaborative filtering is widely used in modern recommender systems. Recent research shows that variational autoencoders (VAEs) yield state-of-the-art performance by integrating flexible representations from deep neural networks into latent variable models, mitigating limitations of traditional linear factor models. VAEs are typically trained by maximizing the likelihood (MLE) of users interacting with ground-truth items. While simple and often effective, MLE-based training does not directly maximize the recommendation-quality metrics one typically cares about, such as top-N ranking. In this paper we investigate new methods for training collaborative filtering models based on actor-critic reinforcement learning, to directly optimize the non-differentiable quality metrics of interest. Specifically, we train a critic network to approximate ranking-based metrics, and then update the actor network (represented here by a VAE) to directly optimize against the learned metrics. In contrast to traditional learning-to-rank methods that require to re-run the optimization procedure for new lists, our critic-based method amortizes the scoring process with a neural network, and can directly provide the (approximate) ranking scores for new lists. Empirically, we show that the proposed methods outperform several state-of-the-art baselines, including recently-proposed deep learning approaches, on three large-scale real-world datasets. The code to reproduce the experimental results and figure plots is on Github: https://github.com/samlobel/RaCT_CF
Syntax-Infused Variational Autoencoder for Text Generation
Jun 05, 2019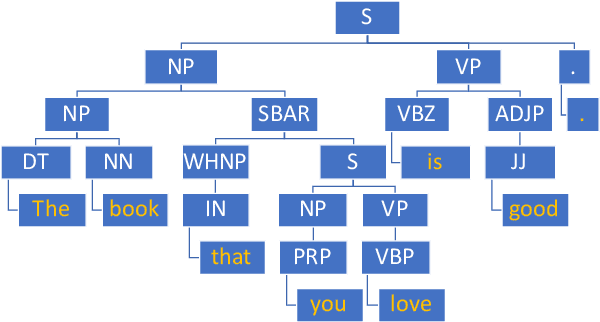
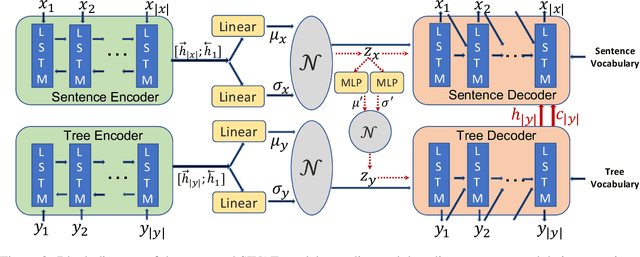
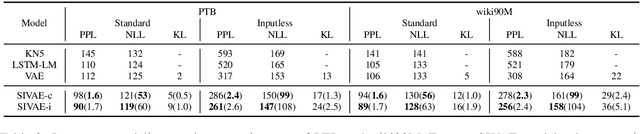
We present a syntax-infused variational autoencoder (SIVAE), that integrates sentences with their syntactic trees to improve the grammar of generated sentences. Distinct from existing VAE-based text generative models, SIVAE contains two separate latent spaces, for sentences and syntactic trees. The evidence lower bound objective is redesigned correspondingly, by optimizing a joint distribution that accommodates two encoders and two decoders. SIVAE works with long short-term memory architectures to simultaneously generate sentences and syntactic trees. Two versions of SIVAE are proposed: one captures the dependencies between the latent variables through a conditional prior network, and the other treats the latent variables independently such that syntactically-controlled sentence generation can be performed. Experimental results demonstrate the generative superiority of SIVAE on both reconstruction and targeted syntactic evaluations. Finally, we show that the proposed models can be used for unsupervised paraphrasing given different syntactic tree templates.
Adaptation Across Extreme Variations using Unlabeled Domain Bridges
Jun 05, 2019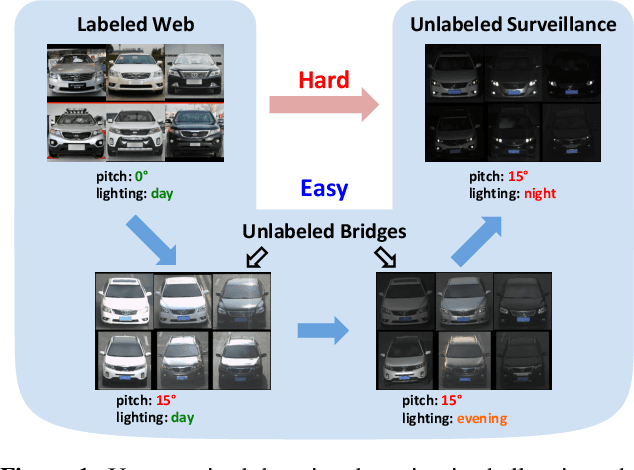

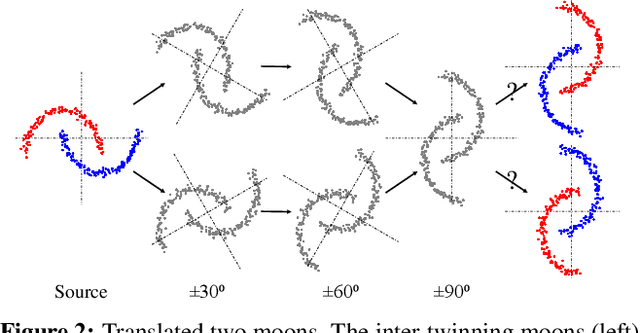

We tackle an unsupervised domain adaptation problem for which the domain discrepancy between labeled source and unlabeled target domains is large, due to many factors of inter and intra-domain variation. While deep domain adaptation methods have been realized by reducing the domain discrepancy, these are difficult to apply when domains are significantly unalike. In this work, we propose to decompose domain discrepancy into multiple but smaller, and thus easier to minimize, discrepancies by introducing unlabeled bridging domains that connect the source and target domains. We realize our proposal through an extension of the domain adversarial neural network with multiple discriminators, each of which accounts for reducing discrepancies between unlabeled (bridge, target) domains and a mix of all precedent domains including source. We validate the effectiveness of our method on several adaptation tasks including object recognition and semantic segmentation.
Improving Textual Network Embedding with Global Attention via Optimal Transport
Jun 05, 2019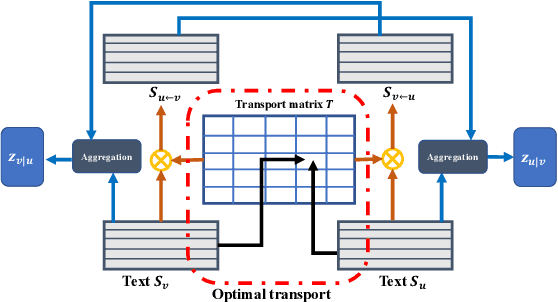
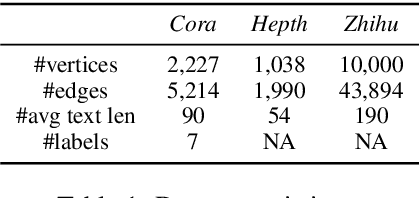
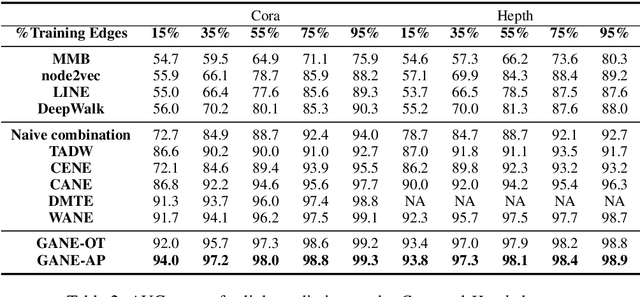
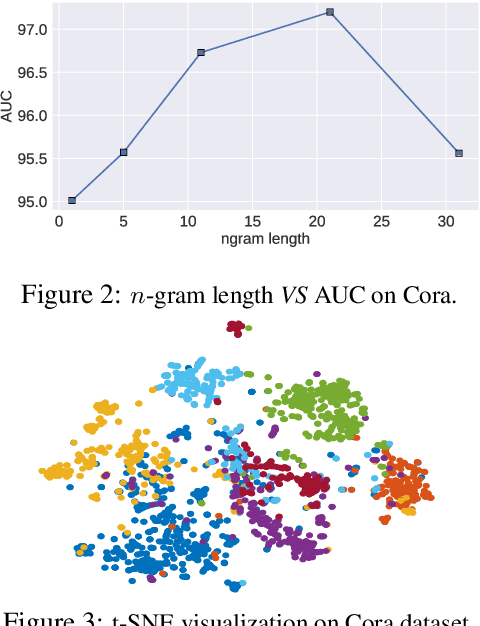
Constituting highly informative network embeddings is an important tool for network analysis. It encodes network topology, along with other useful side information, into low-dimensional node-based feature representations that can be exploited by statistical modeling. This work focuses on learning context-aware network embeddings augmented with text data. We reformulate the network-embedding problem, and present two novel strategies to improve over traditional attention mechanisms: ($i$) a content-aware sparse attention module based on optimal transport, and ($ii$) a high-level attention parsing module. Our approach yields naturally sparse and self-normalized relational inference. It can capture long-term interactions between sequences, thus addressing the challenges faced by existing textual network embedding schemes. Extensive experiments are conducted to demonstrate our model can consistently outperform alternative state-of-the-art methods.
Scalable Gromov-Wasserstein Learning for Graph Partitioning and Matching
May 22, 2019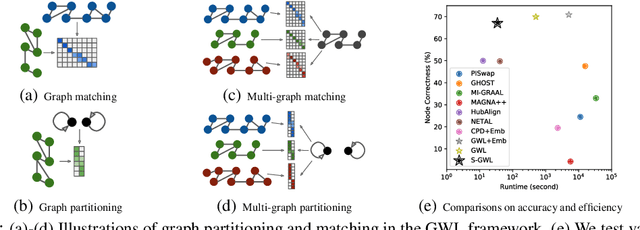
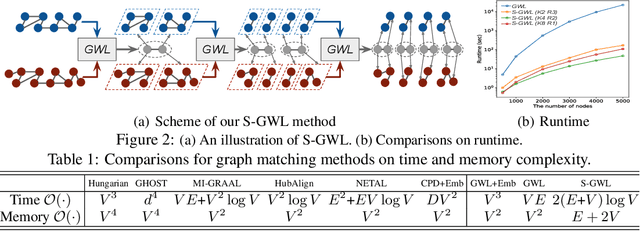
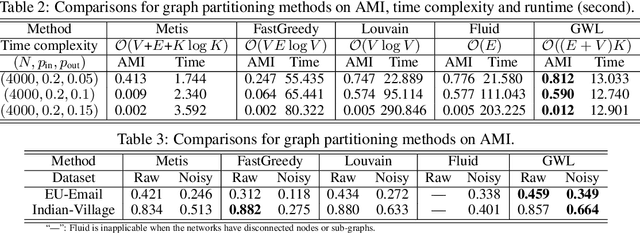
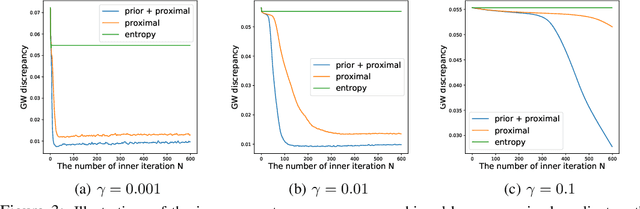
We propose a scalable Gromov-Wasserstein learning (S-GWL) method and establish a novel and theoretically-supported paradigm for large-scale graph analysis. The proposed method is based on the fact that Gromov-Wasserstein discrepancy is a pseudometric on graphs. Given two graphs, the optimal transport associated with their Gromov-Wasserstein discrepancy provides the correspondence between their nodes and achieves graph matching. When one of the graphs has isolated but self-connected nodes ($i.e.$, a disconnected graph), the optimal transport indicates the clustering structure of the other graph and achieves graph partitioning. Using this concept, we extend our method to multi-graph partitioning and matching by learning a Gromov-Wasserstein barycenter graph for multiple observed graphs; the barycenter graph plays the role of the disconnected graph, and since it is learned, so is the clustering. Our method combines a recursive $K$-partition mechanism with a regularized proximal gradient algorithm, whose time complexity is $\mathcal{O}(K(E+V)\log_K V)$ for graphs with $V$ nodes and $E$ edges. To our knowledge, our method is the first attempt to make Gromov-Wasserstein discrepancy applicable to large-scale graph analysis and unify graph partitioning and matching into the same framework. It outperforms state-of-the-art graph partitioning and matching methods, achieving a trade-off between accuracy and efficiency.