 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience Paper: Scaling WiFi Sensing to Millions of Commodity Devices for Ubiquitous Home Monitoring
Jun 04, 2025WiFi-based home monitoring has emerged as a compelling alternative to traditional camera- and sensor-based solutions, offering wide coverage with minimal intrusion by leveraging existing wireless infrastructure. This paper presents key insights and lessons learned from developing and deploying a large-scale WiFi sensing solution, currently operational across over 10 million commodity off-the-shelf routers and 100 million smart bulbs worldwide. Through this extensive deployment, we identify four real-world challenges that hinder the practical adoption of prior research: 1) Non-human movements (e.g., pets) frequently trigger false positives; 2) Low-cost WiFi chipsets and heterogeneous hardware introduce inconsistencies in channel state information (CSI) measurements; 3) Motion interference in multi-user environments complicates occupant differentiation; 4) Computational constraints on edge devices and limited cloud transmission impede real-time processing. To address these challenges, we present a practical and scalable system, validated through comprehensive two-year evaluations involving 280 edge devices, across 16 scenarios, and over 4 million motion samples. Our solutions achieve an accuracy of 92.61% in diverse real-world homes while reducing false alarms due to non-human movements from 63.1% to 8.4% and lowering CSI transmission overhead by 99.72%. Notably, our system integrates sensing and communication, supporting simultaneous WiFi sensing and data transmission over home WiFi networks. While focused on home monitoring, our findings and strategies generalize to various WiFi sensing applications. By bridging the gaps between theoretical research and commercial deployment, this work offers practical insights for scaling WiFi sensing in real-world environments.
CSI-Bench: A Large-Scale In-the-Wild Dataset for Multi-task WiFi Sensing
May 28, 2025



WiFi sensing has emerged as a compelling contactless modality for human activity monitoring by capturing fine-grained variations in Channel State Information (CSI). Its ability to operate continuously and non-intrusively while preserving user privacy makes it particularly suitable for health monitoring. However, existing WiFi sensing systems struggle to generalize in real-world settings, largely due to datasets collected in controlled environments with homogeneous hardware and fragmented, session-based recordings that fail to reflect continuous daily activity. We present CSI-Bench, a large-scale, in-the-wild benchmark dataset collected using commercial WiFi edge devices across 26 diverse indoor environments with 35 real users. Spanning over 461 hours of effective data, CSI-Bench captures realistic signal variability under natural conditions. It includes task-specific datasets for fall detection, breathing monitoring, localization, and motion source recognition, as well as a co-labeled multitask dataset with joint annotations for user identity, activity, and proximity. To support the development of robust and generalizable models, CSI-Bench provides standardized evaluation splits and baseline results for both single-task and multi-task learning. CSI-Bench offers a foundation for scalable, privacy-preserving WiFi sensing systems in health and broader human-centric applications.
Robust Proximity Detection using On-Device Gait Monitoring
Apr 30, 2024Proximity detection in indoor environments based on WiFi signals has gained significant attention in recent years. Existing works rely on the dynamic signal reflections and their extracted features are dependent on motion strength. To address this issue, we design a robust WiFi-based proximity detector by considering gait monitoring. Specifically, we propose a gait score that accurately evaluates gait presence by leveraging the speed estimated from the autocorrelation function (ACF) of channel state information (CSI). By combining this gait score with a proximity feature, our approach effectively distinguishes different transition patterns, enabling more reliable proximity detection. In addition, to enhance the stability of the detection process, we employ a state machine and extract temporal information, ensuring continuous proximity detection even during subtle movements. Extensive experiments conducted in different environments demonstrate an overall detection rate of 92.5% and a low false alarm rate of 1.12% with a delay of 0.825s.
mmID: High-Resolution mmWave Imaging for Human Identification
Feb 01, 2024



Achieving accurate human identification through RF imaging has been a persistent challenge, primarily attributed to the limited aperture size and its consequent impact on imaging resolution. The existing imaging solution enables tasks such as pose estimation, activity recognition, and human tracking based on deep neural networks by estimating skeleton joints. In contrast to estimating joints, this paper proposes to improve imaging resolution by estimating the human figure as a whole using conditional generative adversarial networks (cGAN). In order to reduce training complexity, we use an estimated spatial spectrum using the MUltiple SIgnal Classification (MUSIC) algorithm as input to the cGAN. Our system generates environmentally independent, high-resolution images that can extract unique physical features useful for human identification. We use a simple convolution layers-based classification network to obtain the final identification result. From the experimental results, we show that resolution of the image produced by our trained generator is high enough to enable human identification. Our finding indicates high-resolution accuracy with 5% mean silhouette difference to the Kinect device. Extensive experiments in different environments on multiple testers demonstrate that our system can achieve 93% overall test accuracy in unseen environments for static human target identification.
TAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation
Aug 14, 2022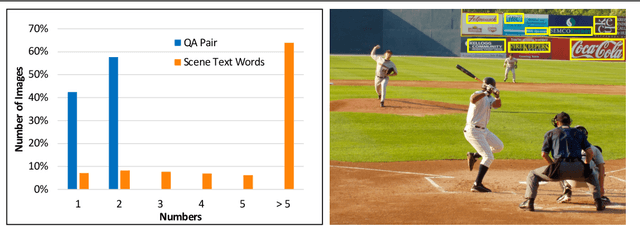
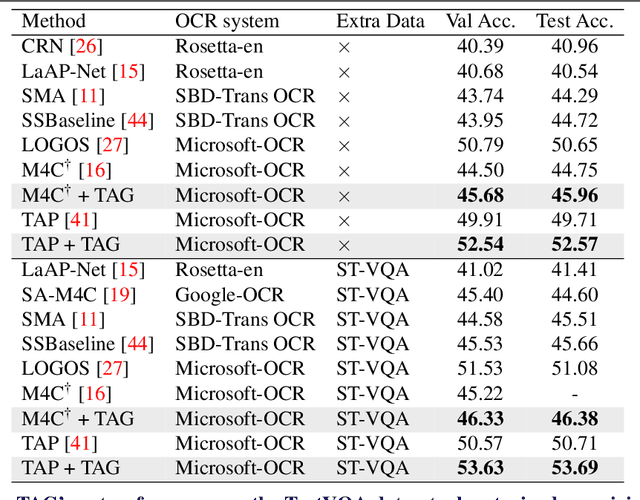

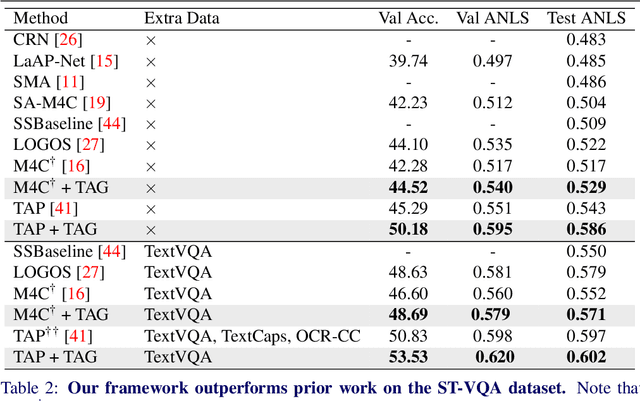
Text-VQA aims at answering questions that require understanding the textual cues in an image. Despite the great progress of existing Text-VQA methods, their performance suffers from insufficient human-labeled question-answer (QA) pairs. However, we observe that, in general, the scene text is not fully exploited in the existing datasets -- only a small portion of text in each image participates in the annotated QA activities. This results in a huge waste of useful information. To address this deficiency, we develop a new method to generate high-quality and diverse QA pairs by explicitly utilizing the existing rich text available in the scene context of each image. Specifically, we propose, TAG, a text-aware visual question-answer generation architecture that learns to produce meaningful, and accurate QA samples using a multimodal transformer. The architecture exploits underexplored scene text information and enhances scene understanding of Text-VQA models by combining the generated QA pairs with the initial training data. Extensive experimental results on two well-known Text-VQA benchmarks (TextVQA and ST-VQA) demonstrate that our proposed TAG effectively enlarges the training data that helps improve the Text-VQA performance without extra labeling effort. Moreover, our model outperforms state-of-the-art approaches that are pre-trained with extra large-scale data. Code is available at https://github.com/HenryJunW/TAG.