 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Clustering for Unsupervised Domain Adaptive Object Re-identification
Aug 22, 2021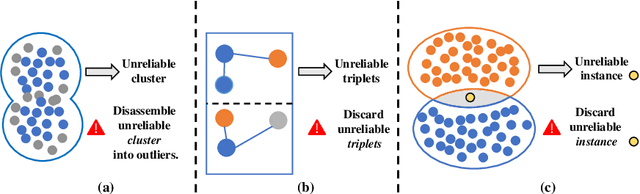
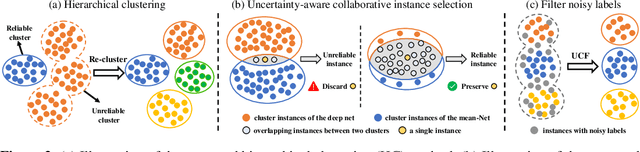
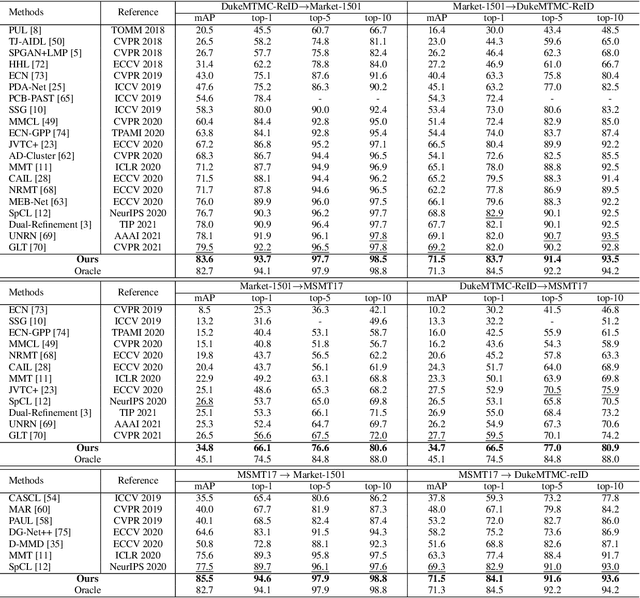
Unsupervised Domain Adaptive (UDA) object re-identification (Re-ID) aims at adapting a model trained on a labeled source domain to an unlabeled target domain. State-of-the-art object Re-ID approaches adopt clustering algorithms to generate pseudo-labels for the unlabeled target domain. However, the inevitable label noise caused by the clustering procedure significantly degrades the discriminative power of Re-ID model. To address this problem, we propose an uncertainty-aware clustering framework (UCF) for UDA tasks. First, a novel hierarchical clustering scheme is proposed to promote clustering quality. Second, an uncertainty-aware collaborative instance selection method is introduced to select images with reliable labels for model training. Combining both techniques effectively reduces the impact of noisy labels. In addition, we introduce a strong baseline that features a compact contrastive loss. Our UCF method consistently achieves state-of-the-art performance in multiple UDA tasks for object Re-ID, and significantly reduces the gap between unsupervised and supervised Re-ID performance. In particular, the performance of our unsupervised UCF method in the MSMT17$\to$Market1501 task is better than that of the fully supervised setting on Market1501. The code of UCF is available at https://github.com/Wang-pengfei/UCF.
Geometry-Aware Self-Training for Unsupervised Domain Adaptationon Object Point Clouds
Aug 20, 2021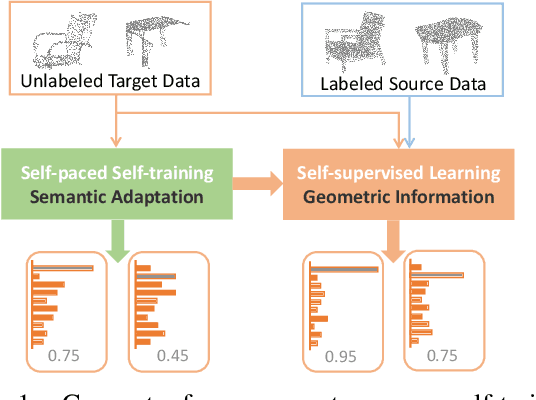
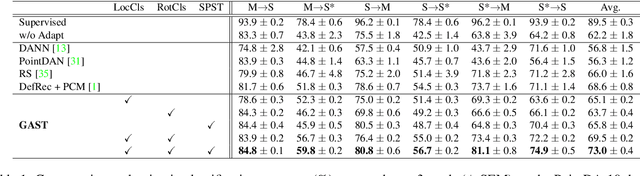
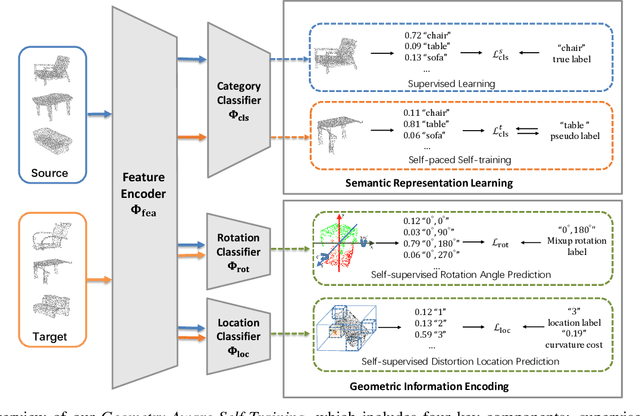
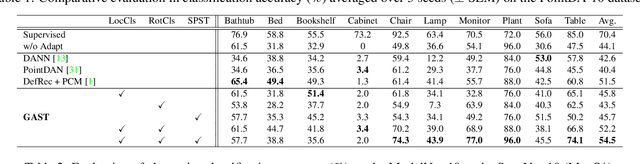
The point cloud representation of an object can have a large geometric variation in view of inconsistent data acquisition procedure, which thus leads to domain discrepancy due to diverse and uncontrollable shape representation cross datasets. To improve discrimination on unseen distribution of point-based geometries in a practical and feasible perspective, this paper proposes a new method of geometry-aware self-training (GAST) for unsupervised domain adaptation of object point cloud classification. Specifically, this paper aims to learn a domain-shared representation of semantic categories, via two novel self-supervised geometric learning tasks as feature regularization. On one hand, the representation learning is empowered by a linear mixup of point cloud samples with their self-generated rotation labels, to capture a global topological configuration of local geometries. On the other hand, a diverse point distribution across datasets can be normalized with a novel curvature-aware distortion localization. Experiments on the PointDA-10 dataset show that our GAST method can significantly outperform the state-of-the-art methods.
Instance Segmentation in 3D Scenes using Semantic Superpoint Tree Networks
Aug 17, 2021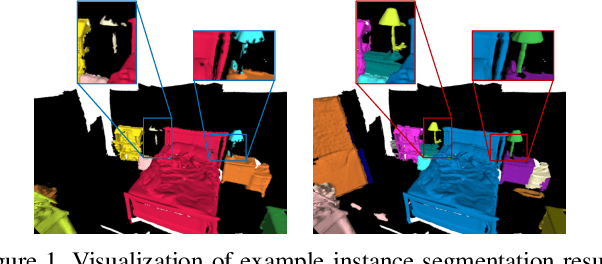

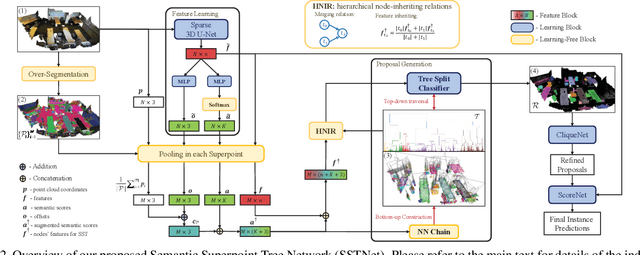
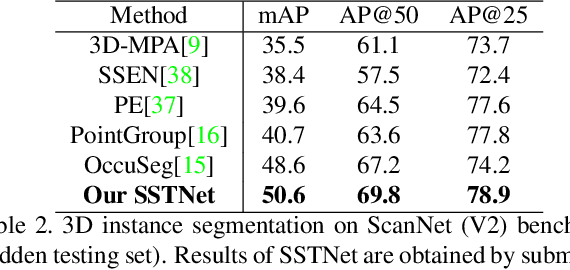
Instance segmentation in 3D scenes is fundamental in many applications of scene understanding. It is yet challenging due to the compound factors of data irregularity and uncertainty in the numbers of instances. State-of-the-art methods largely rely on a general pipeline that first learns point-wise features discriminative at semantic and instance levels, followed by a separate step of point grouping for proposing object instances. While promising, they have the shortcomings that (1) the second step is not supervised by the main objective of instance segmentation, and (2) their point-wise feature learning and grouping are less effective to deal with data irregularities, possibly resulting in fragmented segmentations. To address these issues, we propose in this work an end-to-end solution of Semantic Superpoint Tree Network (SSTNet) for proposing object instances from scene points. Key in SSTNet is an intermediate, semantic superpoint tree (SST), which is constructed based on the learned semantic features of superpoints, and which will be traversed and split at intermediate tree nodes for proposals of object instances. We also design in SSTNet a refinement module, termed CliqueNet, to prune superpoints that may be wrongly grouped into instance proposals. Experiments on the benchmarks of ScanNet and S3DIS show the efficacy of our proposed method. At the time of submission, SSTNet ranks top on the ScanNet (V2) leaderboard, with 2% higher of mAP than the second best method. The source code in PyTorch is available at https://github.com/Gorilla-Lab-SCUT/SSTNet.
Content-Aware Convolutional Neural Networks
Jul 23, 2021

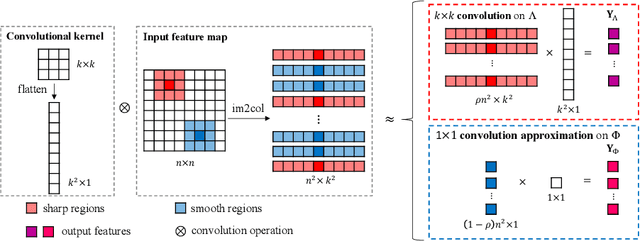
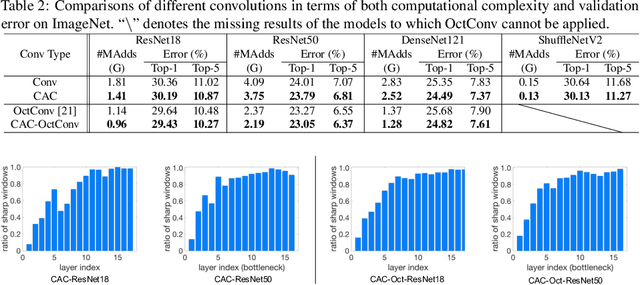
Convolutional Neural Networks (CNNs) have achieved great success due to the powerful feature learning ability of convolution layers. Specifically, the standard convolution traverses the input images/features using a sliding window scheme to extract features. However, not all the windows contribute equally to the prediction results of CNNs. In practice, the convolutional operation on some of the windows (e.g., smooth windows that contain very similar pixels) can be very redundant and may introduce noises into the computation. Such redundancy may not only deteriorate the performance but also incur the unnecessary computational cost. Thus, it is important to reduce the computational redundancy of convolution to improve the performance. To this end, we propose a Content-aware Convolution (CAC) that automatically detects the smooth windows and applies a 1x1 convolutional kernel to replace the original large kernel. In this sense, we are able to effectively avoid the redundant computation on similar pixels. By replacing the standard convolution in CNNs with our CAC, the resultant models yield significantly better performance and lower computational cost than the baseline models with the standard convolution. More critically, we are able to dynamically allocate suitable computation resources according to the data smoothness of different images, making it possible for content-aware computation. Extensive experiments on various computer vision tasks demonstrate the superiority of our method over existing methods.
Perception-aware Multi-sensor Fusion for 3D LiDAR Semantic Segmentation
Jun 21, 2021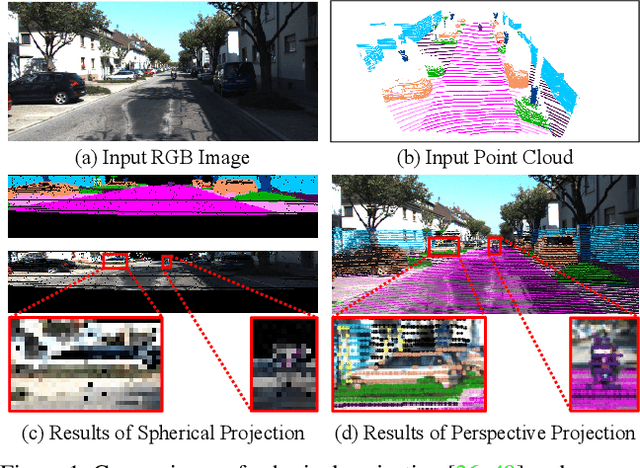
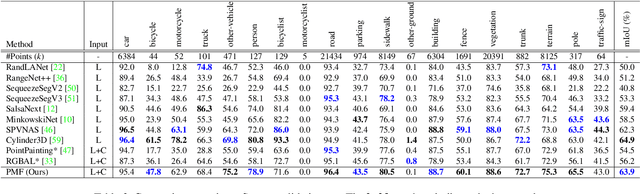
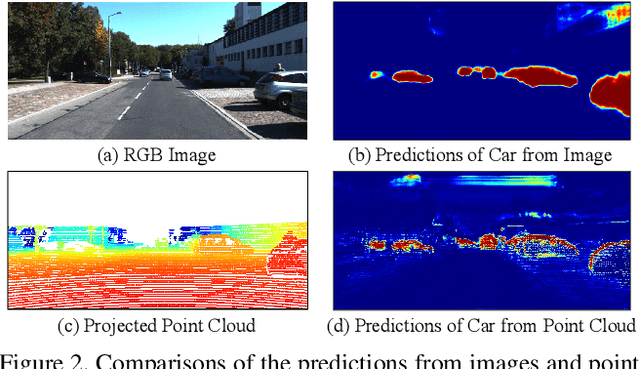
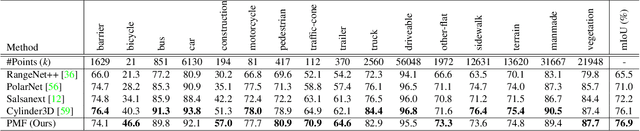
3D LiDAR (light detection and ranging) based semantic segmentation is important in scene understanding for many applications, such as auto-driving and robotics. For example, for autonomous cars equipped with RGB cameras and LiDAR, it is crucial to fuse complementary information from different sensors for robust and accurate segmentation. Existing fusion-based methods, however, may not achieve promising performance due to the vast difference between two modalities. In this work, we investigate a collaborative fusion scheme called perception-aware multi-sensor fusion (PMF) to exploit perceptual information from two modalities, namely, appearance information from RGB images and spatio-depth information from point clouds. To this end, we first project point clouds to the camera coordinates to provide spatio-depth information for RGB images. Then, we propose a two-stream network to extract features from the two modalities, separately, and fuse the features by effective residual-based fusion modules. Moreover, we propose additional perception-aware losses to measure the great perceptual difference between the two modalities. Extensive experiments on two benchmark data sets show the superiority of our method. For example, on nuScenes, our PMF outperforms the state-of-the-art method by 0.8% in mIoU.
Learning and Meshing from Deep Implicit Surface Networks Using an Efficient Implementation of Analytic Marching
Jun 18, 2021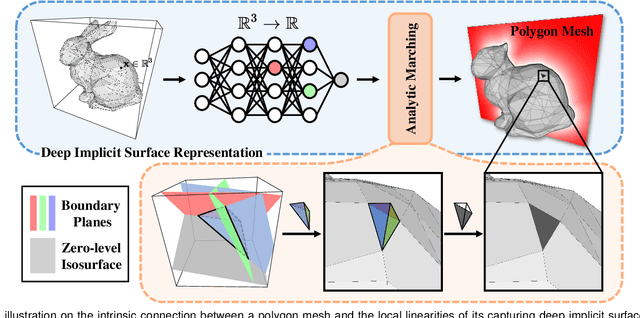
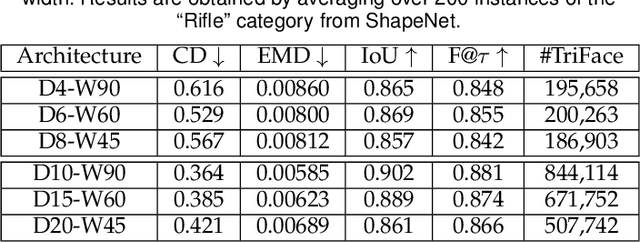
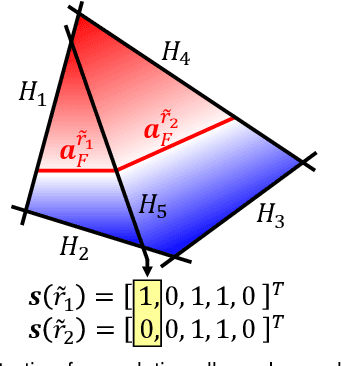
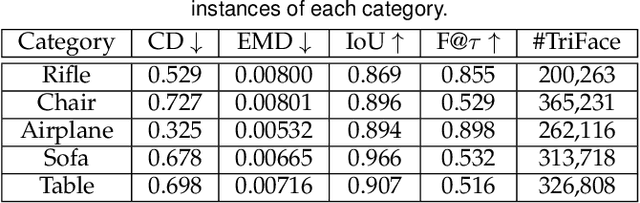
Reconstruction of object or scene surfaces has tremendous applications in computer vision, computer graphics, and robotics. In this paper, we study a fundamental problem in this context about recovering a surface mesh from an implicit field function whose zero-level set captures the underlying surface. To achieve the goal, existing methods rely on traditional meshing algorithms; while promising, they suffer from loss of precision learned in the implicit surface networks, due to the use of discrete space sampling in marching cubes. Given that an MLP with activations of Rectified Linear Unit (ReLU) partitions its input space into a number of linear regions, we are motivated to connect this local linearity with a same property owned by the desired result of polygon mesh. More specifically, we identify from the linear regions, partitioned by an MLP based implicit function, the analytic cells and analytic faces that are associated with the function's zero-level isosurface. We prove that under mild conditions, the identified analytic faces are guaranteed to connect and form a closed, piecewise planar surface. Based on the theorem, we propose an algorithm of analytic marching, which marches among analytic cells to exactly recover the mesh captured by an implicit surface network. We also show that our theory and algorithm are equally applicable to advanced MLPs with shortcut connections and max pooling. Given the parallel nature of analytic marching, we contribute AnalyticMesh, a software package that supports efficient meshing of implicit surface networks via CUDA parallel computing, and mesh simplification for efficient downstream processing. We apply our method to different settings of generative shape modeling using implicit surface networks. Extensive experiments demonstrate our advantages over existing methods in terms of both meshing accuracy and efficiency.
Gradual Domain Adaptation via Self-Training of Auxiliary Models
Jun 18, 2021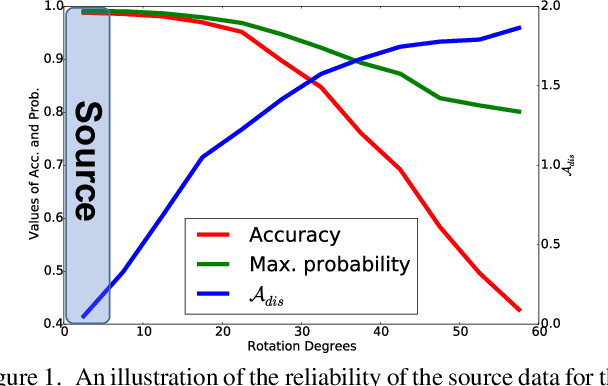
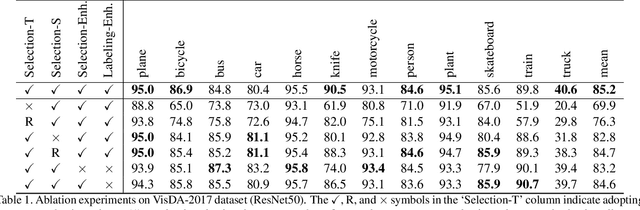
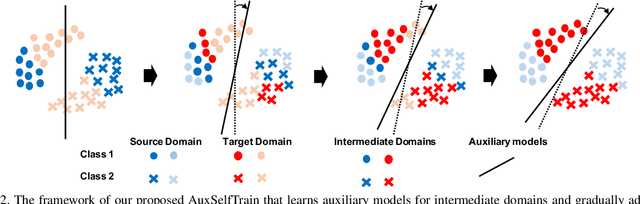
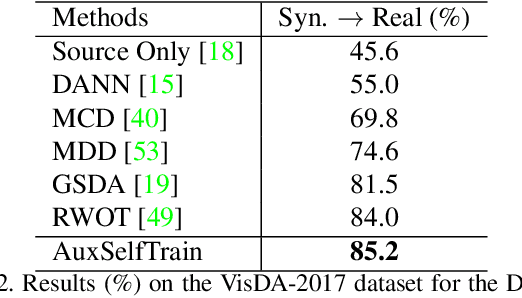
Domain adaptation becomes more challenging with increasing gaps between source and target domains. Motivated from an empirical analysis on the reliability of labeled source data for the use of distancing target domains, we propose self-training of auxiliary models (AuxSelfTrain) that learns models for intermediate domains and gradually combats the distancing shifts across domains. We introduce evolving intermediate domains as combinations of decreasing proportion of source data and increasing proportion of target data, which are sampled to minimize the domain distance between consecutive domains. Then the source model could be gradually adapted for the use in the target domain by self-training of auxiliary models on evolving intermediate domains. We also introduce an enhanced indicator for sample selection via implicit ensemble and extend the proposed method to semi-supervised domain adaptation. Experiments on benchmark datasets of unsupervised and semi-supervised domain adaptation verify its efficacy.
Semi-supervised Models are Strong Unsupervised Domain Adaptation Learners
Jun 01, 2021

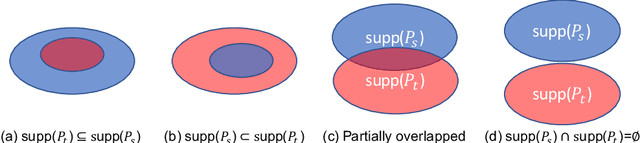
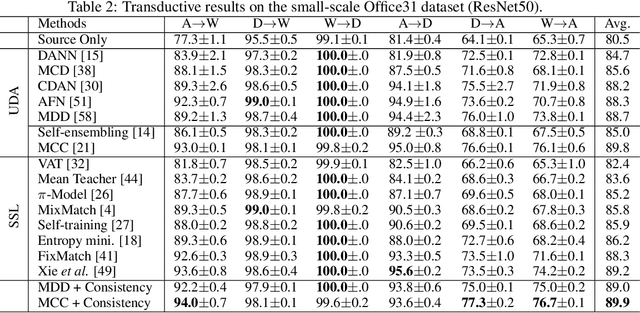
Unsupervised domain adaptation (UDA) and semi-supervised learning (SSL) are two typical strategies to reduce expensive manual annotations in machine learning. In order to learn effective models for a target task, UDA utilizes the available labeled source data, which may have different distributions from unlabeled samples in the target domain, while SSL employs few manually annotated target samples. Although UDA and SSL are seemingly very different strategies, we find that they are closely related in terms of task objectives and solutions, and SSL is a special case of UDA problems. Based on this finding, we further investigate whether SSL methods work on UDA tasks. By adapting eight representative SSL algorithms on UDA benchmarks, we show that SSL methods are strong UDA learners. Especially, state-of-the-art SSL methods significantly outperform existing UDA methods on the challenging UDA benchmark of DomainNet, and state-of-the-art UDA methods could be further enhanced with SSL techniques. We thus promote that SSL methods should be employed as baselines in future UDA studies and expect that the revealed relationship between UDA and SSL could shed light on future UDA development. Codes are available at \url{https://github.com/YBZh}.
Sign-Agnostic CONet: Learning Implicit Surface Reconstructions by Sign-Agnostic Optimization of Convolutional Occupancy Networks
May 08, 2021
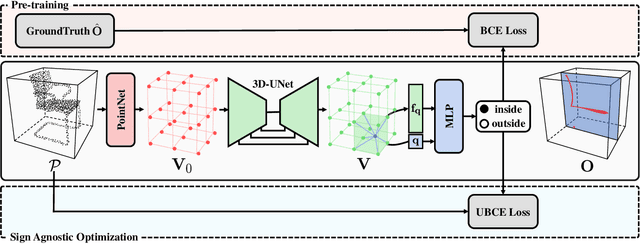
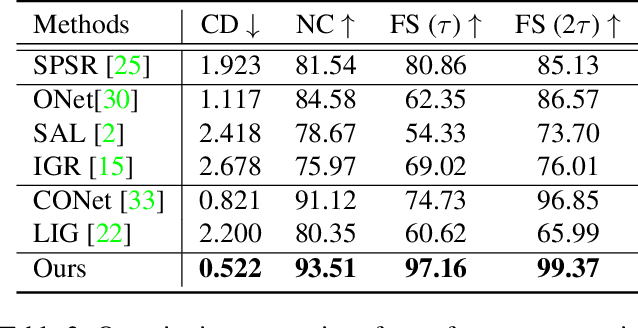
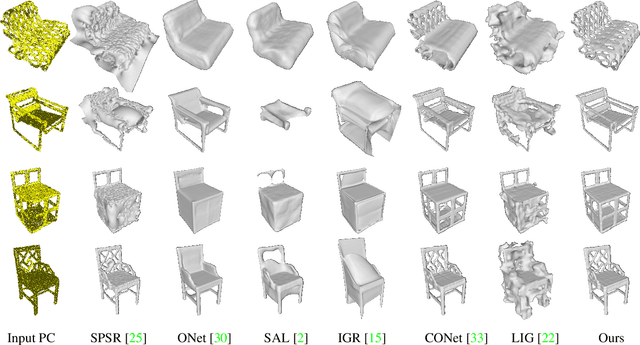
Surface reconstruction from point clouds is a fundamental problem in the computer vision and graphics community. Recent state-of-the-arts solve this problem by individually optimizing each local implicit field during inference. Without considering the geometric relationships between local fields, they typically require accurate normals to avoid the sign conflict problem in overlapping regions of local fields, which severely limits their applicability to raw scans where surface normals could be unavailable. Although SAL breaks this limitation via sign-agnostic learning, it is still unexplored that how to extend this pipeline to local shape modeling. To this end, we propose to learn implicit surface reconstruction by sign-agnostic optimization of convolutional occupancy networks, to simultaneously achieve advanced scalability, generality, and applicability in a unified framework. In the paper, we also show this goal can be effectively achieved by a simple yet effective design, which optimizes the occupancy fields that are conditioned on convolutional features from an hourglass network architecture with an unsigned binary cross-entropy loss. Extensive experimental comparison with previous state-of-the-arts on both object-level and scene-level datasets demonstrate the superior accuracy of our approach for surface reconstruction from un-orientated point clouds.
On Universal Black-Box Domain Adaptation
Apr 10, 2021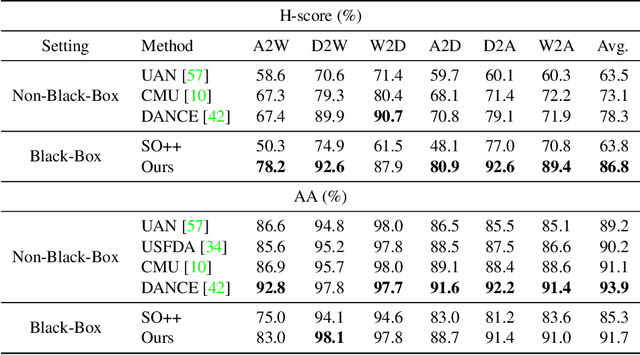
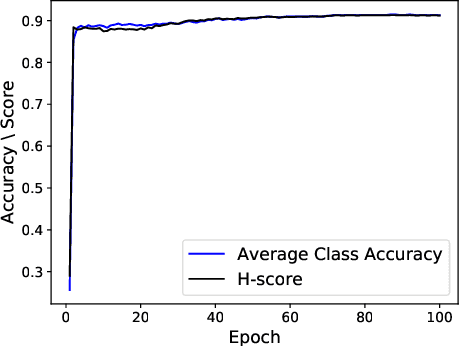
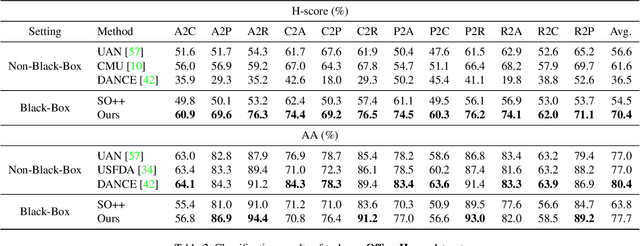

In this paper, we study an arguably least restrictive setting of domain adaptation in a sense of practical deployment, where only the interface of source model is available to the target domain, and where the label-space relations between the two domains are allowed to be different and unknown. We term such a setting as Universal Black-Box Domain Adaptation (UB$^2$DA). The great promise that UB$^2$DA makes, however, brings significant learning challenges, since domain adaptation can only rely on the predictions of unlabeled target data in a partially overlapped label space, by accessing the interface of source model. To tackle the challenges, we first note that the learning task can be converted as two subtasks of in-class\footnote{In this paper we use in-class (out-class) to describe the classes observed (not observed) in the source black-box model.} discrimination and out-class detection, which can be respectively learned by model distillation and entropy separation. We propose to unify them into a self-training framework, regularized by consistency of predictions in local neighborhoods of target samples. Our framework is simple, robust, and easy to be optimized. Experiments on domain adaptation benchmarks show its efficacy. Notably, by accessing the interface of source model only, our framework outperforms existing methods of universal domain adaptation that make use of source data and/or source models, with a newly proposed (and arguably more reasonable) metric of H-score, and performs on par with them with the metric of averaged class accuracy.