 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Very Long Video Understanding
Jan 26, 2026The advent of always-on personal AI assistants, enabled by all-day wearable devices such as smart glasses, demands a new level of contextual understanding, one that goes beyond short, isolated events to encompass the continuous, longitudinal stream of egocentric video. Achieving this vision requires advances in long-horizon video understanding, where systems must interpret and recall visual and audio information spanning days or even weeks. Existing methods, including large language models and retrieval-augmented generation, are constrained by limited context windows and lack the ability to perform compositional, multi-hop reasoning over very long video streams. In this work, we address these challenges through EGAgent, an enhanced agentic framework centered on entity scene graphs, which represent people, places, objects, and their relationships over time. Our system equips a planning agent with tools for structured search and reasoning over these graphs, as well as hybrid visual and audio search capabilities, enabling detailed, cross-modal, and temporally coherent reasoning. Experiments on the EgoLifeQA and Video-MME (Long) datasets show that our method achieves state-of-the-art performance on EgoLifeQA (57.5%) and competitive performance on Video-MME (Long) (74.1%) for complex longitudinal video understanding tasks.
MVLight: Relightable Text-to-3D Generation via Light-conditioned Multi-View Diffusion
Nov 18, 2024Recent advancements in text-to-3D generation, building on the success of high-performance text-to-image generative models, have made it possible to create imaginative and richly textured 3D objects from textual descriptions. However, a key challenge remains in effectively decoupling light-independent and lighting-dependent components to enhance the quality of generated 3D models and their relighting performance. In this paper, we present MVLight, a novel light-conditioned multi-view diffusion model that explicitly integrates lighting conditions directly into the generation process. This enables the model to synthesize high-quality images that faithfully reflect the specified lighting environment across multiple camera views. By leveraging this capability to Score Distillation Sampling (SDS), we can effectively synthesize 3D models with improved geometric precision and relighting capabilities. We validate the effectiveness of MVLight through extensive experiments and a user study.
CamFreeDiff: Camera-free Image to Panorama Generation with Diffusion Model
Jul 09, 2024



This paper introduces Camera-free Diffusion (CamFreeDiff) model for 360-degree image outpainting from a single camera-free image and text description. This method distinguishes itself from existing strategies, such as MVDiffusion, by eliminating the requirement for predefined camera poses. Instead, our model incorporates a mechanism for predicting homography directly within the multi-view diffusion framework. The core of our approach is to formulate camera estimation by predicting the homography transformation from the input view to a predefined canonical view. The homography provides point-level correspondences between the input image and targeting panoramic images, allowing connections enforced by correspondence-aware attention in a fully differentiable manner. Qualitative and quantitative experimental results demonstrate our model's strong robustness and generalization ability for 360-degree image outpainting in the challenging context of camera-free inputs.
RoDyn-SLAM: Robust Dynamic Dense RGB-D SLAM with Neural Radiance Fields
Jul 01, 2024



Leveraging neural implicit representation to conduct dense RGB-D SLAM has been studied in recent years. However, this approach relies on a static environment assumption and does not work robustly within a dynamic environment due to the inconsistent observation of geometry and photometry. To address the challenges presented in dynamic environments, we propose a novel dynamic SLAM framework with neural radiance field. Specifically, we introduce a motion mask generation method to filter out the invalid sampled rays. This design effectively fuses the optical flow mask and semantic mask to enhance the precision of motion mask. To further improve the accuracy of pose estimation, we have designed a divide-and-conquer pose optimization algorithm that distinguishes between keyframes and non-keyframes. The proposed edge warp loss can effectively enhance the geometry constraints between adjacent frames. Extensive experiments are conducted on the two challenging datasets, and the results show that RoDyn-SLAM achieves state-of-the-art performance among recent neural RGB-D methods in both accuracy and robustness.
Multi-view Image Prompted Multi-view Diffusion for Improved 3D Generation
Apr 26, 2024Using image as prompts for 3D generation demonstrate particularly strong performances compared to using text prompts alone, for images provide a more intuitive guidance for the 3D generation process. In this work, we delve into the potential of using multiple image prompts, instead of a single image prompt, for 3D generation. Specifically, we build on ImageDream, a novel image-prompt multi-view diffusion model, to support multi-view images as the input prompt. Our method, dubbed MultiImageDream, reveals that transitioning from a single-image prompt to multiple-image prompts enhances the performance of multi-view and 3D object generation according to various quantitative evaluation metrics and qualitative assessments. This advancement is achieved without the necessity of fine-tuning the pre-trained ImageDream multi-view diffusion model.
Enhancing 3D Fidelity of Text-to-3D using Cross-View Correspondences
Apr 16, 2024

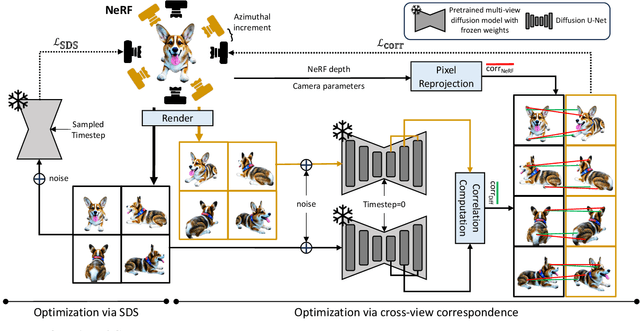

Leveraging multi-view diffusion models as priors for 3D optimization have alleviated the problem of 3D consistency, e.g., the Janus face problem or the content drift problem, in zero-shot text-to-3D models. However, the 3D geometric fidelity of the output remains an unresolved issue; albeit the rendered 2D views are realistic, the underlying geometry may contain errors such as unreasonable concavities. In this work, we propose CorrespondentDream, an effective method to leverage annotation-free, cross-view correspondences yielded from the diffusion U-Net to provide additional 3D prior to the NeRF optimization process. We find that these correspondences are strongly consistent with human perception, and by adopting it in our loss design, we are able to produce NeRF models with geometries that are more coherent with common sense, e.g., more smoothed object surface, yielding higher 3D fidelity. We demonstrate the efficacy of our approach through various comparative qualitative results and a solid user study.
Consistent-1-to-3: Consistent Image to 3D View Synthesis via Geometry-aware Diffusion Models
Oct 04, 2023



Zero-shot novel view synthesis (NVS) from a single image is an essential problem in 3D object understanding. While recent approaches that leverage pre-trained generative models can synthesize high-quality novel views from in-the-wild inputs, they still struggle to maintain 3D consistency across different views. In this paper, we present Consistent-1-to-3, which is a generative framework that significantly mitigate this issue. Specifically, we decompose the NVS task into two stages: (i) transforming observed regions to a novel view, and (ii) hallucinating unseen regions. We design a scene representation transformer and view-conditioned diffusion model for performing these two stages respectively. Inside the models, to enforce 3D consistency, we propose to employ epipolor-guided attention to incorporate geometry constraints, and multi-view attention to better aggregate multi-view information. Finally, we design a hierarchy generation paradigm to generate long sequences of consistent views, allowing a full 360 observation of the provided object image. Qualitative and quantitative evaluation over multiple datasets demonstrate the effectiveness of the proposed mechanisms against state-of-the-art approaches. Our project page is at https://jianglongye.com/consistent123/
MVDream: Multi-view Diffusion for 3D Generation
Aug 31, 2023



We propose MVDream, a multi-view diffusion model that is able to generate geometrically consistent multi-view images from a given text prompt. By leveraging image diffusion models pre-trained on large-scale web datasets and a multi-view dataset rendered from 3D assets, the resulting multi-view diffusion model can achieve both the generalizability of 2D diffusion and the consistency of 3D data. Such a model can thus be applied as a multi-view prior for 3D generation via Score Distillation Sampling, where it greatly improves the stability of existing 2D-lifting methods by solving the 3D consistency problem. Finally, we show that the multi-view diffusion model can also be fine-tuned under a few shot setting for personalized 3D generation, i.e. DreamBooth3D application, where the consistency can be maintained after learning the subject identity.
ObjectSDF++: Improved Object-Compositional Neural Implicit Surfaces
Aug 17, 2023In recent years, neural implicit surface reconstruction has emerged as a popular paradigm for multi-view 3D reconstruction. Unlike traditional multi-view stereo approaches, the neural implicit surface-based methods leverage neural networks to represent 3D scenes as signed distance functions (SDFs). However, they tend to disregard the reconstruction of individual objects within the scene, which limits their performance and practical applications. To address this issue, previous work ObjectSDF introduced a nice framework of object-composition neural implicit surfaces, which utilizes 2D instance masks to supervise individual object SDFs. In this paper, we propose a new framework called ObjectSDF++ to overcome the limitations of ObjectSDF. First, in contrast to ObjectSDF whose performance is primarily restricted by its converted semantic field, the core component of our model is an occlusion-aware object opacity rendering formulation that directly volume-renders object opacity to be supervised with instance masks. Second, we design a novel regularization term for object distinction, which can effectively mitigate the issue that ObjectSDF may result in unexpected reconstruction in invisible regions due to the lack of constraint to prevent collisions. Our extensive experiments demonstrate that our novel framework not only produces superior object reconstruction results but also significantly improves the quality of scene reconstruction. Code and more resources can be found in \url{https://qianyiwu.github.io/objectsdf++}
Physically Plausible 3D Human-Scene Reconstruction from Monocular RGB Image using an Adversarial Learning Approach
Jul 27, 2023



Holistic 3D human-scene reconstruction is a crucial and emerging research area in robot perception. A key challenge in holistic 3D human-scene reconstruction is to generate a physically plausible 3D scene from a single monocular RGB image. The existing research mainly proposes optimization-based approaches for reconstructing the scene from a sequence of RGB frames with explicitly defined physical laws and constraints between different scene elements (humans and objects). However, it is hard to explicitly define and model every physical law in every scenario. This paper proposes using an implicit feature representation of the scene elements to distinguish a physically plausible alignment of humans and objects from an implausible one. We propose using a graph-based holistic representation with an encoded physical representation of the scene to analyze the human-object and object-object interactions within the scene. Using this graphical representation, we adversarially train our model to learn the feasible alignments of the scene elements from the training data itself without explicitly defining the laws and constraints between them. Unlike the existing inference-time optimization-based approaches, we use this adversarially trained model to produce a per-frame 3D reconstruction of the scene that abides by the physical laws and constraints. Our learning-based method achieves comparable 3D reconstruction quality to existing optimization-based holistic human-scene reconstruction methods and does not need inference time optimization. This makes it better suited when compared to existing methods, for potential use in robotic applications, such as robot navigation, etc.