 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Grained Knowledge Retrieval for End-to-End Task-Oriented Dialog
May 17, 2023



Retrieving proper domain knowledge from an external database lies at the heart of end-to-end task-oriented dialog systems to generate informative responses. Most existing systems blend knowledge retrieval with response generation and optimize them with direct supervision from reference responses, leading to suboptimal retrieval performance when the knowledge base becomes large-scale. To address this, we propose to decouple knowledge retrieval from response generation and introduce a multi-grained knowledge retriever (MAKER) that includes an entity selector to search for relevant entities and an attribute selector to filter out irrelevant attributes. To train the retriever, we propose a novel distillation objective that derives supervision signals from the response generator. Experiments conducted on three standard benchmarks with both small and large-scale knowledge bases demonstrate that our retriever performs knowledge retrieval more effectively than existing methods. Our code has been made publicly available.\footnote{https://github.com/18907305772/MAKER}
PVP: Pre-trained Visual Parameter-Efficient Tuning
Apr 26, 2023



Large-scale pre-trained transformers have demonstrated remarkable success in various computer vision tasks. However, it is still highly challenging to fully fine-tune these models for downstream tasks due to their high computational and storage costs. Recently, Parameter-Efficient Tuning (PETuning) techniques, e.g., Visual Prompt Tuning (VPT) and Low-Rank Adaptation (LoRA), have significantly reduced the computation and storage cost by inserting lightweight prompt modules into the pre-trained models and tuning these prompt modules with a small number of trainable parameters, while keeping the transformer backbone frozen. Although only a few parameters need to be adjusted, most PETuning methods still require a significant amount of downstream task training data to achieve good results. The performance is inadequate on low-data regimes, especially when there are only one or two examples per class. To this end, we first empirically identify the poor performance is mainly due to the inappropriate way of initializing prompt modules, which has also been verified in the pre-trained language models. Next, we propose a Pre-trained Visual Parameter-efficient (PVP) Tuning framework, which pre-trains the parameter-efficient tuning modules first and then leverages the pre-trained modules along with the pre-trained transformer backbone to perform parameter-efficient tuning on downstream tasks. Experiment results on five Fine-Grained Visual Classification (FGVC) and VTAB-1k datasets demonstrate that our proposed method significantly outperforms state-of-the-art PETuning methods.
Non-Invasive Fairness in Learning through the Lens of Data Drift
Apr 05, 2023



Machine Learning (ML) models are widely employed to drive many modern data systems. While they are undeniably powerful tools, ML models often demonstrate imbalanced performance and unfair behaviors. The root of this problem often lies in the fact that different subpopulations commonly display divergent trends: as a learning algorithm tries to identify trends in the data, it naturally favors the trends of the majority groups, leading to a model that performs poorly and unfairly for minority populations. Our goal is to improve the fairness and trustworthiness of ML models by applying only non-invasive interventions, i.e., without altering the data or the learning algorithm. We use a simple but key insight: the divergence of trends between different populations, and, consecutively, between a learned model and minority populations, is analogous to data drift, which indicates the poor conformance between parts of the data and the trained model. We explore two strategies (model-splitting and reweighing) to resolve this drift, aiming to improve the overall conformance of models to the underlying data. Both our methods introduce novel ways to employ the recently-proposed data profiling primitive of Conformance Constraints. Our experimental evaluation over 7 real-world datasets shows that both DifFair and ConFair improve the fairness of ML models. We demonstrate scenarios where DifFair has an edge, though ConFair has the greatest practical impact and outperforms other baselines. Moreover, as a model-agnostic technique, ConFair stays robust when used against different models than the ones on which the weights have been learned, which is not the case for other state of the art.
Generic Dependency Modeling for Multi-Party Conversation
Feb 21, 2023To model the dependencies between utterances in multi-party conversations, we propose a simple and generic framework based on the dependency parsing results of utterances. Particularly, we present an approach to encoding the dependencies in the form of relative dependency encoding (ReDE) and illustrate how to implement it in Transformers by modifying the computation of self-attention. Experimental results on four multi-party conversation benchmarks show that this framework successfully boosts the general performance of two Transformer-based language models and leads to comparable or even superior performance compared to the state-of-the-art methods. The codes are available at https://github.com/shenwzh3/ReDE.
Towards Vision Transformer Unrolling Fixed-Point Algorithm: a Case Study on Image Restoration
Jan 29, 2023The great success of Deep Neural Networks (DNNs) has inspired the algorithmic development of DNN-based Fixed-Point (DNN-FP) for computer vision tasks. DNN-FP methods, trained by Back-Propagation Through Time or computing the inaccurate inversion of the Jacobian, suffer from inferior representation ability. Motivated by the representation power of the Transformer, we propose a framework to unroll the FP and approximate each unrolled process via Transformer blocks, called FPformer. To reduce the high consumption of memory and computation, we come up with FPRformer by sharing parameters between the successive blocks. We further design a module to adapt Anderson acceleration to FPRformer to enlarge the unrolled iterations and improve the performance, called FPAformer. In order to fully exploit the capability of the Transformer, we apply the proposed model to image restoration, using self-supervised pre-training and supervised fine-tuning. 161 tasks from 4 categories of image restoration problems are used in the pre-training phase. Hereafter, the pre-trained FPformer, FPRformer, and FPAformer are further fine-tuned for the comparison scenarios. Using self-supervised pre-training and supervised fine-tuning, the proposed FPformer, FPRformer, and FPAformer achieve competitive performance with state-of-the-art image restoration methods and better training efficiency. FPAformer employs only 29.82% parameters used in SwinIR models, and provides superior performance after fine-tuning. To train these comparison models, it takes only 26.9% time used for training SwinIR models. It provides a promising way to introduce the Transformer in low-level vision tasks.
ADEPT: A DEbiasing PrompT Framework
Nov 10, 2022



Several works have proven that finetuning is an applicable approach for debiasing contextualized word embeddings. Similarly, discrete prompts with semantic meanings have shown to be effective in debiasing tasks. With unfixed mathematical representation at the token level, continuous prompts usually surpass discrete ones at providing a pre-trained language model (PLM) with additional task-specific information. Despite this, relatively few efforts have been made to debias PLMs by prompt tuning with continuous prompts compared to its discrete counterpart. Furthermore, for most debiasing methods that alter a PLM's original parameters, a major problem is the need to not only decrease the bias in the PLM but also to ensure that the PLM does not lose its representation ability. Finetuning methods typically have a hard time maintaining this balance, as they tend to violently remove meanings of attribute words. In this paper, we propose ADEPT, a method to debias PLMs using prompt tuning while maintaining the delicate balance between removing biases and ensuring representation ability. To achieve this, we propose a new training criterion inspired by manifold learning and equip it with an explicit debiasing term to optimize prompt tuning. In addition, we conduct several experiments with regard to the reliability, quality, and quantity of a previously proposed attribute training corpus in order to obtain a clearer prototype of a certain attribute, which indicates the attribute's position and relative distances to other words on the manifold. We evaluate ADEPT on several widely acknowledged debiasing benchmarks and downstream tasks, and find that it achieves competitive results while maintaining (and in some cases even improving) the PLM's representation ability. We further visualize words' correlation before and after debiasing a PLM, and give some possible explanations for the visible effects.
Adaptive Semantic Communications: Overfitting the Source and Channel for Profit
Nov 08, 2022Most semantic communication systems leverage deep learning models to provide end-to-end transmission performance surpassing the established source and channel coding approaches. While, so far, research has mainly focused on architecture and model improvements, but such a model trained over a full dataset and ergodic channel responses is unlikely to be optimal for every test instance. Due to limitations on the model capacity and imperfect optimization and generalization, such learned models will be suboptimal especially when the testing data distribution or channel response is different from that in the training phase, as is likely to be the case in practice. To tackle this, in this paper, we propose a novel semantic communication paradigm by leveraging the deep learning model's overfitting property. Our model can for instance be updated after deployment, which can further lead to substantial gains in terms of the transmission rate-distortion (RD) performance. This new system is named adaptive semantic communication (ASC). In our ASC system, the ingredients of wireless transmitted stream include both the semantic representations of source data and the adapted decoder model parameters. Specifically, we take the overfitting concept to the extreme, proposing a series of ingenious methods to adapt the semantic codec or representations to an individual data or channel state instance. The whole ASC system design is formulated as an optimization problem whose goal is to minimize the loss function that is a tripartite tradeoff among the data rate, model rate, and distortion terms. The experiments (including user study) verify the effectiveness and efficiency of our ASC system. Notably, the substantial gain of our overfitted coding paradigm can catalyze semantic communication upgrading to a new era.
WITT: A Wireless Image Transmission Transformer for Semantic Communications
Nov 02, 2022



In this paper, we aim to redesign the vision Transformer (ViT) as a new backbone to realize semantic image transmission, termed wireless image transmission transformer (WITT). Previous works build upon convolutional neural networks (CNNs), which are inefficient in capturing global dependencies, resulting in degraded end-to-end transmission performance especially for high-resolution images. To tackle this, the proposed WITT employs Swin Transformers as a more capable backbone to extract long-range information. Different from ViTs in image classification tasks, WITT is highly optimized for image transmission while considering the effect of the wireless channel. Specifically, we propose a spatial modulation module to scale the latent representations according to channel state information, which enhances the ability of a single model to deal with various channel conditions. As a result, extensive experiments verify that our WITT attains better performance for different image resolutions, distortion metrics, and channel conditions. The code is available at https://github.com/KeYang8/WITT.
Brand Celebrity Matching Model Based on Natural Language Processing
Aug 18, 2022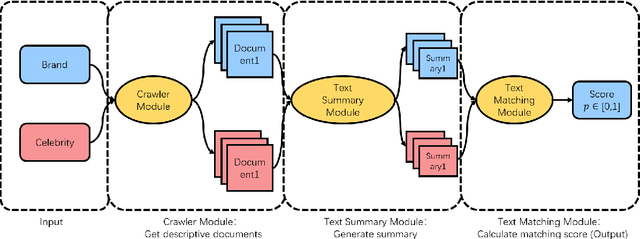


Celebrity Endorsement is one of the most significant strategies in brand communication. Nowadays, more and more companies try to build a vivid characteristic for themselves. Therefore, their brand identity communications should accord with some characteristics as humans and regulations. However, the previous works mostly stop by assumptions, instead of proposing a specific way to perform matching between brands and celebrities. In this paper, we propose a brand celebrity matching model (BCM) based on Natural Language Processing (NLP) techniques. Given a brand and a celebrity, we firstly obtain some descriptive documents of them from the Internet, then summarize these documents, and finally calculate a matching degree between the brand and the celebrity to determine whether they are matched. According to the experimental result, our proposed model outperforms the best baselines with a 0.362 F1 score and 6.3% of accuracy, which indicates the effectiveness and application value of our model in the real-world scene. What's more, to our best knowledge, the proposed BCM model is the first work on using NLP to solve endorsement issues, so it can provide some novel research ideas and methodologies for the following works.
A Sentence is Worth 128 Pseudo Tokens: A Semantic-Aware Contrastive Learning Framework for Sentence Embeddings
Mar 11, 2022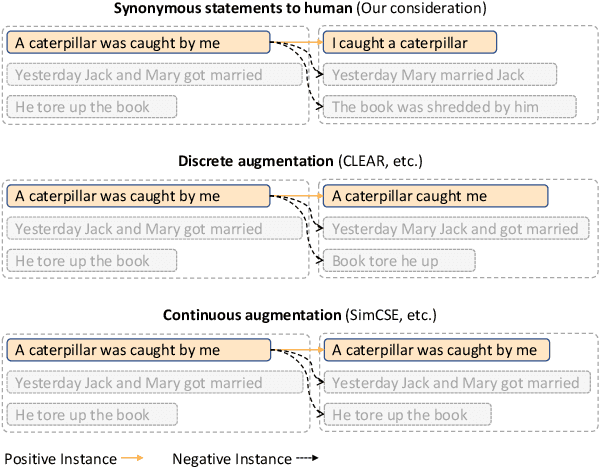


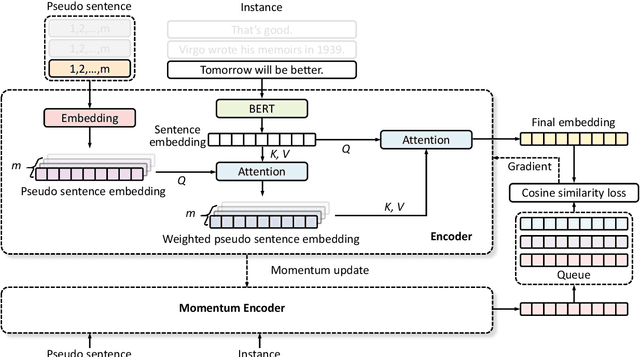
Contrastive learning has shown great potential in unsupervised sentence embedding tasks, e.g., SimCSE. However, We find that these existing solutions are heavily affected by superficial features like the length of sentences or syntactic structures. In this paper, we propose a semantics-aware contrastive learning framework for sentence embeddings, termed Pseudo-Token BERT (PT-BERT), which is able to exploit the pseudo-token space (i.e., latent semantic space) representation of a sentence while eliminating the impact of superficial features such as sentence length and syntax. Specifically, we introduce an additional pseudo token embedding layer independent of the BERT encoder to map each sentence into a sequence of pseudo tokens in a fixed length. Leveraging these pseudo sequences, we are able to construct same-length positive and negative pairs based on the attention mechanism to perform contrastive learning. In addition, we utilize both the gradient-updating and momentum-updating encoders to encode instances while dynamically maintaining an additional queue to store the representation of sentence embeddings, enhancing the encoder's learning performance for negative examples. Experiments show that our model outperforms the state-of-the-art baselines on six standard semantic textual similarity (STS) tasks. Furthermore, experiments on alignments and uniformity losses, as well as hard examples with different sentence lengths and syntax, consistently verify the effectiveness of our method.