 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Multimodal Large Language Models Ready for Omnidirectional Spatial Reasoning?
May 17, 2025The 180x360 omnidirectional field of view captured by 360-degree cameras enables their use in a wide range of applications such as embodied AI and virtual reality. Although recent advances in multimodal large language models (MLLMs) have shown promise in visual-spatial reasoning, most studies focus on standard pinhole-view images, leaving omnidirectional perception largely unexplored. In this paper, we ask: Are MLLMs ready for omnidirectional spatial reasoning? To investigate this, we introduce OSR-Bench, the first benchmark specifically designed for this setting. OSR-Bench includes over 153,000 diverse question-answer pairs grounded in high-fidelity panoramic indoor scene maps. It covers key reasoning types including object counting, relative distance, and direction. We also propose a negative sampling strategy that inserts non-existent objects into prompts to evaluate hallucination and grounding robustness. For fine-grained analysis, we design a two-stage evaluation framework assessing both cognitive map generation and QA accuracy using rotation-invariant matching and a combination of rule-based and LLM-based metrics. We evaluate eight state-of-the-art MLLMs, including GPT-4o, Gemini 1.5 Pro, and leading open-source models under zero-shot settings. Results show that current models struggle with spatial reasoning in panoramic contexts, highlighting the need for more perceptually grounded MLLMs. OSR-Bench and code will be released at: https://huggingface.co/datasets/UUUserna/OSR-Bench
Language-Driven Dual Style Mixing for Single-Domain Generalized Object Detection
May 12, 2025Generalizing an object detector trained on a single domain to multiple unseen domains is a challenging task. Existing methods typically introduce image or feature augmentation to diversify the source domain to raise the robustness of the detector. Vision-Language Model (VLM)-based augmentation techniques have been proven to be effective, but they require that the detector's backbone has the same structure as the image encoder of VLM, limiting the detector framework selection. To address this problem, we propose Language-Driven Dual Style Mixing (LDDS) for single-domain generalization, which diversifies the source domain by fully utilizing the semantic information of the VLM. Specifically, we first construct prompts to transfer style semantics embedded in the VLM to an image translation network. This facilitates the generation of style diversified images with explicit semantic information. Then, we propose image-level style mixing between the diversified images and source domain images. This effectively mines the semantic information for image augmentation without relying on specific augmentation selections. Finally, we propose feature-level style mixing in a double-pipeline manner, allowing feature augmentation to be model-agnostic and can work seamlessly with the mainstream detector frameworks, including the one-stage, two-stage, and transformer-based detectors. Extensive experiments demonstrate the effectiveness of our approach across various benchmark datasets, including real to cartoon and normal to adverse weather tasks. The source code and pre-trained models will be publicly available at https://github.com/qinhongda8/LDDS.
Panoramic Out-of-Distribution Segmentation
May 06, 2025Panoramic imaging enables capturing 360{\deg} images with an ultra-wide Field-of-View (FoV) for dense omnidirectional perception. However, current panoramic semantic segmentation methods fail to identify outliers, and pinhole Out-of-distribution Segmentation (OoS) models perform unsatisfactorily in the panoramic domain due to background clutter and pixel distortions. To address these issues, we introduce a new task, Panoramic Out-of-distribution Segmentation (PanOoS), achieving OoS for panoramas. Furthermore, we propose the first solution, POS, which adapts to the characteristics of panoramic images through text-guided prompt distribution learning. Specifically, POS integrates a disentanglement strategy designed to materialize the cross-domain generalization capability of CLIP. The proposed Prompt-based Restoration Attention (PRA) optimizes semantic decoding by prompt guidance and self-adaptive correction, while Bilevel Prompt Distribution Learning (BPDL) refines the manifold of per-pixel mask embeddings via semantic prototype supervision. Besides, to compensate for the scarcity of PanOoS datasets, we establish two benchmarks: DenseOoS, which features diverse outliers in complex environments, and QuadOoS, captured by a quadruped robot with a panoramic annular lens system. Extensive experiments demonstrate superior performance of POS, with AuPRC improving by 34.25% and FPR95 decreasing by 21.42% on DenseOoS, outperforming state-of-the-art pinhole-OoS methods. Moreover, POS achieves leading closed-set segmentation capabilities. Code and datasets will be available at https://github.com/MengfeiD/PanOoS.
Exploring Video-Based Driver Activity Recognition under Noisy Labels
Apr 16, 2025As an open research topic in the field of deep learning, learning with noisy labels has attracted much attention and grown rapidly over the past ten years. Learning with label noise is crucial for driver distraction behavior recognition, as real-world video data often contains mislabeled samples, impacting model reliability and performance. However, label noise learning is barely explored in the driver activity recognition field. In this paper, we propose the first label noise learning approach for the driver activity recognition task. Based on the cluster assumption, we initially enable the model to learn clustering-friendly low-dimensional representations from given videos and assign the resultant embeddings into clusters. We subsequently perform co-refinement within each cluster to smooth the classifier outputs. Furthermore, we propose a flexible sample selection strategy that combines two selection criteria without relying on any hyperparameters to filter clean samples from the training dataset. We also incorporate a self-adaptive parameter into the sample selection process to enforce balancing across classes. A comprehensive variety of experiments on the public Drive&Act dataset for all granularity levels demonstrates the superior performance of our method in comparison with other label-denoising methods derived from the image classification field. The source code is available at https://github.com/ilonafan/DAR-noisy-labels.
Scene-agnostic Pose Regression for Visual Localization
Mar 25, 2025



Absolute Pose Regression (APR) predicts 6D camera poses but lacks the adaptability to unknown environments without retraining, while Relative Pose Regression (RPR) generalizes better yet requires a large image retrieval database. Visual Odometry (VO) generalizes well in unseen environments but suffers from accumulated error in open trajectories. To address this dilemma, we introduce a new task, Scene-agnostic Pose Regression (SPR), which can achieve accurate pose regression in a flexible way while eliminating the need for retraining or databases. To benchmark SPR, we created a large-scale dataset, 360SPR, with over 200K photorealistic panoramas, 3.6M pinhole images and camera poses in 270 scenes at three different sensor heights. Furthermore, a SPR-Mamba model is initially proposed to address SPR in a dual-branch manner. Extensive experiments and studies demonstrate the effectiveness of our SPR paradigm, dataset, and model. In the unknown scenes of both 360SPR and 360Loc datasets, our method consistently outperforms APR, RPR and VO. The dataset and code are available at https://junweizheng93.github.io/publications/SPR/SPR.html.
EgoEvGesture: Gesture Recognition Based on Egocentric Event Camera
Mar 16, 2025



Egocentric gesture recognition is a pivotal technology for enhancing natural human-computer interaction, yet traditional RGB-based solutions suffer from motion blur and illumination variations in dynamic scenarios. While event cameras show distinct advantages in handling high dynamic range with ultra-low power consumption, existing RGB-based architectures face inherent limitations in processing asynchronous event streams due to their synchronous frame-based nature. Moreover, from an egocentric perspective, event cameras record data that include events generated by both head movements and hand gestures, thereby increasing the complexity of gesture recognition. To address this, we propose a novel network architecture specifically designed for event data processing, incorporating (1) a lightweight CNN with asymmetric depthwise convolutions to reduce parameters while preserving spatiotemporal features, (2) a plug-and-play state-space model as context block that decouples head movement noise from gesture dynamics, and (3) a parameter-free Bins-Temporal Shift Module (BSTM) that shifts features along bins and temporal dimensions to fuse sparse events efficiently. We further build the EgoEvGesture dataset, the first large-scale dataset for egocentric gesture recognition using event cameras. Experimental results demonstrate that our method achieves 62.7% accuracy in heterogeneous testing with only 7M parameters, 3.1% higher than state-of-the-art approaches. Notable misclassifications in freestyle motions stem from high inter-personal variability and unseen test patterns differing from training data. Moreover, our approach achieved a remarkable accuracy of 96.97% on DVS128 Gesture, demonstrating strong cross-dataset generalization capability. The dataset and models are made publicly available at https://github.com/3190105222/EgoEv_Gesture.
HierDAMap: Towards Universal Domain Adaptive BEV Mapping via Hierarchical Perspective Priors
Mar 10, 2025The exploration of Bird's-Eye View (BEV) mapping technology has driven significant innovation in visual perception technology for autonomous driving. BEV mapping models need to be applied to the unlabeled real world, making the study of unsupervised domain adaptation models an essential path. However, research on unsupervised domain adaptation for BEV mapping remains limited and cannot perfectly accommodate all BEV mapping tasks. To address this gap, this paper proposes HierDAMap, a universal and holistic BEV domain adaptation framework with hierarchical perspective priors. Unlike existing research that solely focuses on image-level learning using prior knowledge, this paper explores the guiding role of perspective prior knowledge across three distinct levels: global, sparse, and instance levels. With these priors, HierDA consists of three essential components, including Semantic-Guided Pseudo Supervision (SGPS), Dynamic-Aware Coherence Learning (DACL), and Cross-Domain Frustum Mixing (CDFM). SGPS constrains the cross-domain consistency of perspective feature distribution through pseudo labels generated by vision foundation models in 2D space. To mitigate feature distribution discrepancies caused by spatial variations, DACL employs uncertainty-aware predicted depth as an intermediary to derive dynamic BEV labels from perspective pseudo-labels, thereby constraining the coarse BEV features derived from corresponding perspective features. CDFM, on the other hand, leverages perspective masks of view frustum to mix multi-view perspective images from both domains, which guides cross-domain view transformation and encoding learning through mixed BEV labels. The proposed method is verified on multiple BEV mapping tasks, such as BEV semantic segmentation, high-definition semantic, and vectorized mapping. The source code will be made publicly available at https://github.com/lynn-yu/HierDAMap.
MemorySAM: Memorize Modalities and Semantics with Segment Anything Model 2 for Multi-modal Semantic Segmentation
Mar 09, 2025Research has focused on Multi-Modal Semantic Segmentation (MMSS), where pixel-wise predictions are derived from multiple visual modalities captured by diverse sensors. Recently, the large vision model, Segment Anything Model 2 (SAM2), has shown strong zero-shot segmentation performance on both images and videos. When extending SAM2 to MMSS, two issues arise: 1. How can SAM2 be adapted to multi-modal data? 2. How can SAM2 better understand semantics? Inspired by cross-frame correlation in videos, we propose to treat multi-modal data as a sequence of frames representing the same scene. Our key idea is to ''memorize'' the modality-agnostic information and 'memorize' the semantics related to the targeted scene. To achieve this, we apply SAM2's memory mechanisms across multi-modal data to capture modality-agnostic features. Meanwhile, to memorize the semantic knowledge, we propose a training-only Semantic Prototype Memory Module (SPMM) to store category-level prototypes across training for facilitating SAM2's transition from instance to semantic segmentation. A prototypical adaptation loss is imposed between global and local prototypes iteratively to align and refine SAM2's semantic understanding. Extensive experimental results demonstrate that our proposed MemorySAM outperforms SoTA methods by large margins on both synthetic and real-world benchmarks (65.38% on DELIVER, 52.88% on MCubeS). Source code will be made publicly available.
Omnidirectional Multi-Object Tracking
Mar 06, 2025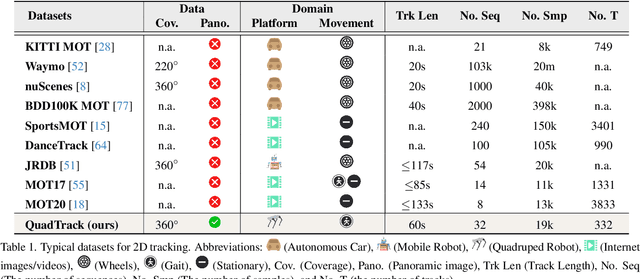
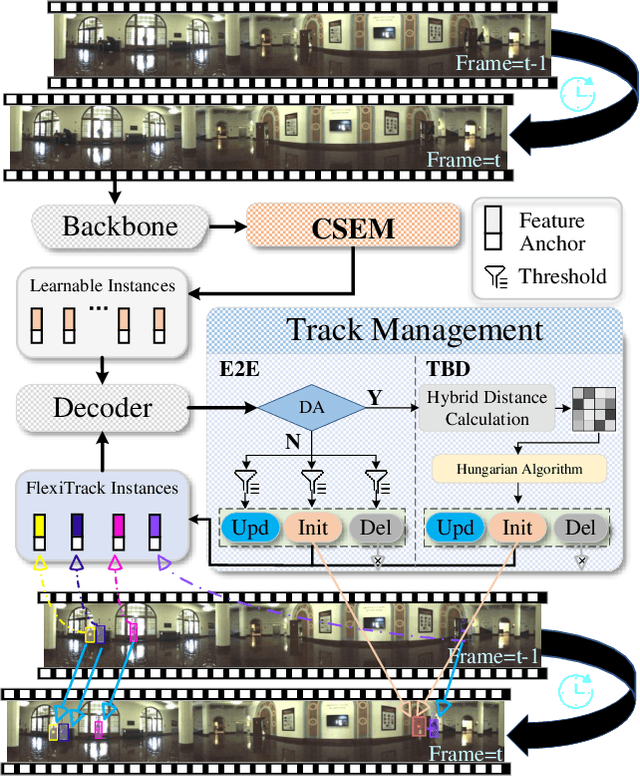
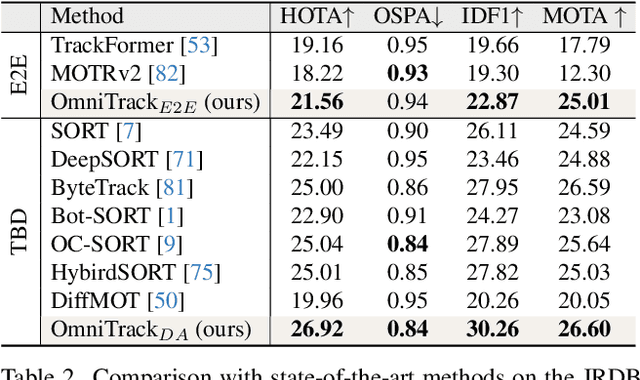
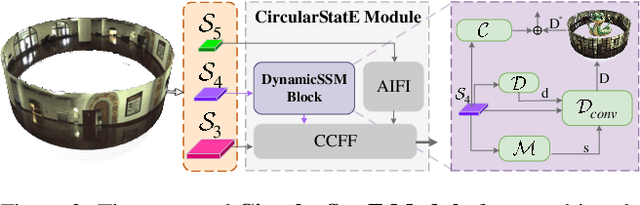
Panoramic imagery, with its 360{\deg} field of view, offers comprehensive information to support Multi-Object Tracking (MOT) in capturing spatial and temporal relationships of surrounding objects. However, most MOT algorithms are tailored for pinhole images with limited views, impairing their effectiveness in panoramic settings. Additionally, panoramic image distortions, such as resolution loss, geometric deformation, and uneven lighting, hinder direct adaptation of existing MOT methods, leading to significant performance degradation. To address these challenges, we propose OmniTrack, an omnidirectional MOT framework that incorporates Tracklet Management to introduce temporal cues, FlexiTrack Instances for object localization and association, and the CircularStatE Module to alleviate image and geometric distortions. This integration enables tracking in large field-of-view scenarios, even under rapid sensor motion. To mitigate the lack of panoramic MOT datasets, we introduce the QuadTrack dataset--a comprehensive panoramic dataset collected by a quadruped robot, featuring diverse challenges such as wide fields of view, intense motion, and complex environments. Extensive experiments on the public JRDB dataset and the newly introduced QuadTrack benchmark demonstrate the state-of-the-art performance of the proposed framework. OmniTrack achieves a HOTA score of 26.92% on JRDB, representing an improvement of 3.43%, and further achieves 23.45% on QuadTrack, surpassing the baseline by 6.81%. The dataset and code will be made publicly available at https://github.com/xifen523/OmniTrack.
TS-CGNet: Temporal-Spatial Fusion Meets Centerline-Guided Diffusion for BEV Mapping
Mar 04, 2025Bird's Eye View (BEV) perception technology is crucial for autonomous driving, as it generates top-down 2D maps for environment perception, navigation, and decision-making. Nevertheless, the majority of current BEV map generation studies focusing on visual map generation lack depth-aware reasoning capabilities. They exhibit limited efficacy in managing occlusions and handling complex environments, with a notable decline in perceptual performance under adverse weather conditions or low-light scenarios. Therefore, this paper proposes TS-CGNet, which leverages Temporal-Spatial fusion with Centerline-Guided diffusion. This visual framework, grounded in prior knowledge, is designed for integration into any existing network for building BEV maps. Specifically, this framework is decoupled into three parts: Local mapping system involves the initial generation of semantic maps using purely visual information; The Temporal-Spatial Aligner Module (TSAM) integrates historical information into mapping generation by applying transformation matrices; The Centerline-Guided Diffusion Model (CGDM) is a prediction module based on the diffusion model. CGDM incorporates centerline information through spatial-attention mechanisms to enhance semantic segmentation reconstruction. We construct BEV semantic segmentation maps by our methods on the public nuScenes and the robustness benchmarks under various corruptions. Our method improves 1.90%, 1.73%, and 2.87% for perceived ranges of 60x30m, 120x60m, and 240x60m in the task of BEV HD mapping. TS-CGNet attains an improvement of 1.92% for perceived ranges of 100x100m in the task of BEV semantic mapping. Moreover, TS-CGNet achieves an average improvement of 2.92% in detection accuracy under varying weather conditions and sensor interferences in the perception range of 240x60m. The source code will be publicly available at https://github.com/krabs-H/TS-CGNet.