 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffiReason-Bench: A Unified Benchmark for Evaluating and Advancing Efficient Reasoning in Large Language Models
Nov 13, 2025



Large language models (LLMs) with Chain-of-Thought (CoT) prompting achieve strong reasoning but often produce unnecessarily long explanations, increasing cost and sometimes reducing accuracy. Fair comparison of efficiency-oriented approaches is hindered by fragmented evaluation practices. We introduce EffiReason-Bench, a unified benchmark for rigorous cross-paradigm evaluation of efficient reasoning methods across three categories: Reasoning Blueprints, Dynamic Execution, and Post-hoc Refinement. To enable step-by-step evaluation, we construct verified CoT annotations for CommonsenseQA and LogiQA via a pipeline that enforces standardized reasoning structures, comprehensive option-wise analysis, and human verification. We evaluate 7 methods across 6 open-source LLMs (1B-70B) on 4 datasets spanning mathematics, commonsense, and logic, and propose the E3-Score, a principled metric inspired by economic trade-off modeling that provides smooth, stable evaluation without discontinuities or heavy reliance on heuristics. Experiments show that no single method universally dominates; optimal strategies depend on backbone scale, task complexity, and architecture.
PRO: Projection Domain Synthesis for CT Imaging
Jun 16, 2025Synthesizing high quality CT images remains a signifi-cant challenge due to the limited availability of annotat-ed data and the complex nature of CT imaging. In this work, we present PRO, a novel framework that, to the best of our knowledge, is the first to perform CT image synthesis in the projection domain using latent diffusion models. Unlike previous approaches that operate in the image domain, PRO learns rich structural representa-tions from raw projection data and leverages anatomi-cal text prompts for controllable synthesis. This projec-tion domain strategy enables more faithful modeling of underlying imaging physics and anatomical structures. Moreover, PRO functions as a foundation model, capa-ble of generalizing across diverse downstream tasks by adjusting its generative behavior via prompt inputs. Experimental results demonstrated that incorporating our synthesized data significantly improves perfor-mance across multiple downstream tasks, including low-dose and sparse-view reconstruction, even with limited training data. These findings underscore the versatility and scalability of PRO in data generation for various CT applications. These results highlight the potential of projection domain synthesis as a powerful tool for data augmentation and robust CT imaging. Our source code is publicly available at: https://github.com/yqx7150/PRO.
Unveiling Instruction-Specific Neurons & Experts: An Analytical Framework for LLM's Instruction-Following Capabilities
May 27, 2025The finetuning of Large Language Models (LLMs) has significantly advanced their instruction-following capabilities, yet the underlying computational mechanisms driving these improvements remain poorly understood. This study systematically examines how fine-tuning reconfigures LLM computations by isolating and analyzing instruction-specific sparse components, i.e., neurons in dense models and both neurons and experts in Mixture-of-Experts (MoE) architectures. In particular, we introduce HexaInst, a carefully curated and balanced instructional dataset spanning six distinct categories, and propose SPARCOM, a novel analytical framework comprising three key contributions: (1) a method for identifying these sparse components, (2) an evaluation of their functional generality and uniqueness, and (3) a systematic comparison of their alterations. Through experiments, we demonstrate functional generality, uniqueness, and the critical role of these components in instruction execution. By elucidating the relationship between fine-tuning-induced adaptations and sparse computational substrates, this work provides deeper insights into how LLMs internalize instruction-following behavior for the trustworthy LLM community.
Do BERT-Like Bidirectional Models Still Perform Better on Text Classification in the Era of LLMs?
May 23, 2025The rapid adoption of LLMs has overshadowed the potential advantages of traditional BERT-like models in text classification. This study challenges the prevailing "LLM-centric" trend by systematically comparing three category methods, i.e., BERT-like models fine-tuning, LLM internal state utilization, and zero-shot inference across six high-difficulty datasets. Our findings reveal that BERT-like models often outperform LLMs. We further categorize datasets into three types, perform PCA and probing experiments, and identify task-specific model strengths: BERT-like models excel in pattern-driven tasks, while LLMs dominate those requiring deep semantics or world knowledge. Based on this, we propose TaMAS, a fine-grained task selection strategy, advocating for a nuanced, task-driven approach over a one-size-fits-all reliance on LLMs.
RePPL: Recalibrating Perplexity by Uncertainty in Semantic Propagation and Language Generation for Explainable QA Hallucination Detection
May 21, 2025Large Language Models (LLMs) have become powerful, but hallucinations remain a vital obstacle to their trustworthy use. While previous works improved the capability of hallucination detection by measuring uncertainty, they all lack the ability to explain the provenance behind why hallucinations occur, i.e., which part of the inputs tends to trigger hallucinations. Recent works on the prompt attack indicate that uncertainty exists in semantic propagation, where attention mechanisms gradually fuse local token information into high-level semantics across layers. Meanwhile, uncertainty also emerges in language generation, due to its probability-based selection of high-level semantics for sampled generations. Based on that, we propose RePPL to recalibrate uncertainty measurement by these two aspects, which dispatches explainable uncertainty scores to each token and aggregates in Perplexity-style Log-Average form as total score. Experiments show that our method achieves the best comprehensive detection performance across various QA datasets on advanced models (average AUC of 0.833), and our method is capable of producing token-level uncertainty scores as explanations for the hallucination. Leveraging these scores, we preliminarily find the chaotic pattern of hallucination and showcase its promising usage.
PhysicsArena: The First Multimodal Physics Reasoning Benchmark Exploring Variable, Process, and Solution Dimensions
May 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in diverse reasoning tasks, yet their application to complex physics reasoning remains underexplored. Physics reasoning presents unique challenges, requiring grounding in physical conditions and the interpretation of multimodal information. Current physics benchmarks are limited, often focusing on text-only inputs or solely on problem-solving, thereby overlooking the critical intermediate steps of variable identification and process formulation. To address these limitations, we introduce PhysicsArena, the first multimodal physics reasoning benchmark designed to holistically evaluate MLLMs across three critical dimensions: variable identification, physical process formulation, and solution derivation. PhysicsArena aims to provide a comprehensive platform for assessing and advancing the multimodal physics reasoning abilities of MLLMs.
ESDiff: Encoding Strategy-inspired Diffusion Model with Few-shot Learning for Color Image Inpainting
Apr 24, 2025Image inpainting is a technique used to restore missing or damaged regions of an image. Traditional methods primarily utilize information from adjacent pixels for reconstructing missing areas, while they struggle to preserve complex details and structures. Simultaneously, models based on deep learning necessitate substantial amounts of training data. To address this challenge, an encoding strategy-inspired diffusion model with few-shot learning for color image inpainting is proposed in this paper. The main idea of this novel encoding strategy is the deployment of a "virtual mask" to construct high-dimensional objects through mutual perturbations between channels. This approach enables the diffusion model to capture diverse image representations and detailed features from limited training samples. Moreover, the encoding strategy leverages redundancy between channels, integrates with low-rank methods during iterative inpainting, and incorporates the diffusion model to achieve accurate information output. Experimental results indicate that our method exceeds current techniques in quantitative metrics, and the reconstructed images quality has been improved in aspects of texture and structural integrity, leading to more precise and coherent results.
CoheMark: A Novel Sentence-Level Watermark for Enhanced Text Quality
Apr 24, 2025Watermarking technology is a method used to trace the usage of content generated by large language models. Sentence-level watermarking aids in preserving the semantic integrity within individual sentences while maintaining greater robustness. However, many existing sentence-level watermarking techniques depend on arbitrary segmentation or generation processes to embed watermarks, which can limit the availability of appropriate sentences. This limitation, in turn, compromises the quality of the generated response. To address the challenge of balancing high text quality with robust watermark detection, we propose CoheMark, an advanced sentence-level watermarking technique that exploits the cohesive relationships between sentences for better logical fluency. The core methodology of CoheMark involves selecting sentences through trained fuzzy c-means clustering and applying specific next sentence selection criteria. Experimental evaluations demonstrate that CoheMark achieves strong watermark strength while exerting minimal impact on text quality.
Virtual-mask Informed Prior for Sparse-view Dual-Energy CT Reconstruction
Apr 10, 2025Sparse-view sampling in dual-energy computed tomography (DECT) significantly reduces radiation dose and increases imaging speed, yet is highly prone to artifacts. Although diffusion models have demonstrated potential in effectively handling incomplete data, most existing methods in this field focus on the image do-main and lack global constraints, which consequently leads to insufficient reconstruction quality. In this study, we propose a dual-domain virtual-mask in-formed diffusion model for sparse-view reconstruction by leveraging the high inter-channel correlation in DECT. Specifically, the study designs a virtual mask and applies it to the high-energy and low-energy data to perform perturbation operations, thus constructing high-dimensional tensors that serve as the prior information of the diffusion model. In addition, a dual-domain collaboration strategy is adopted to integrate the information of the randomly selected high-frequency components in the wavelet domain with the information in the projection domain, for the purpose of optimizing the global struc-tures and local details. Experimental results indicated that the present method exhibits excellent performance across multiple datasets.
PairConnect: A Compute-Efficient MLP Alternative to Attention
Jun 15, 2021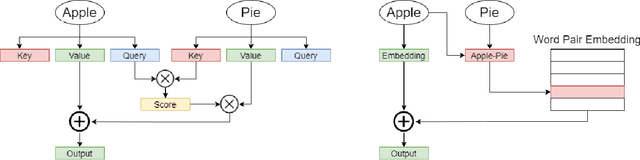
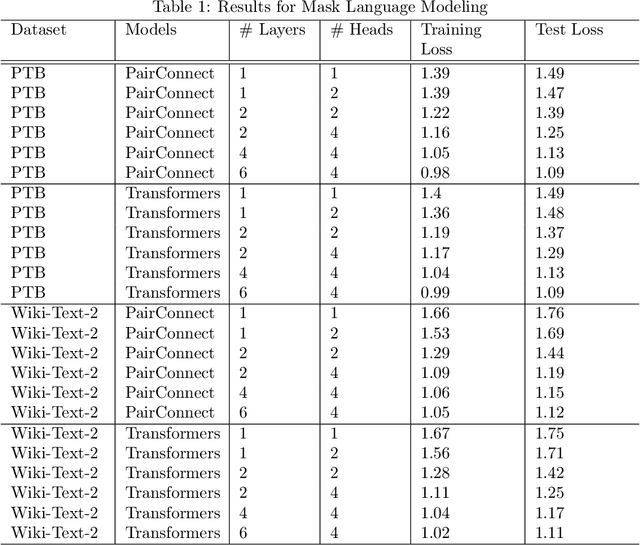
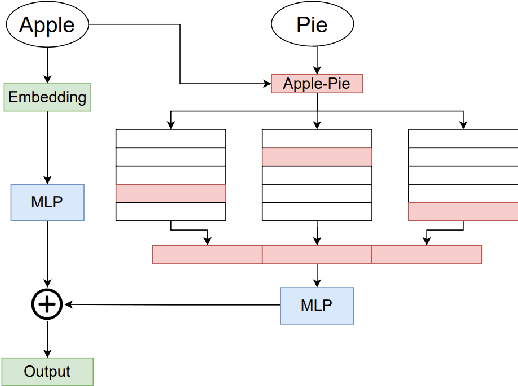
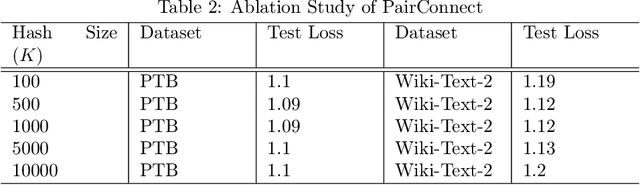
Transformer models have demonstrated superior performance in natural language processing. The dot product self-attention in Transformer allows us to model interactions between words. However, this modeling comes with significant computational overhead. In this work, we revisit the memory-compute trade-off associated with Transformer, particularly multi-head attention, and show a memory-heavy but significantly more compute-efficient alternative to Transformer. Our proposal, denoted as PairConnect, a multilayer perceptron (MLP), models the pairwise interaction between words by explicit pairwise word embeddings. As a result, PairConnect substitutes self dot product with a simple embedding lookup. We show mathematically that despite being an MLP, our compute-efficient PairConnect is strictly more expressive than Transformer. Our experiment on language modeling tasks suggests that PairConnect could achieve comparable results with Transformer while reducing the computational cost associated with inference significantly.