 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRiT: A Generative Region-to-text Transformer for Object Understanding
Dec 01, 2022This paper presents a Generative RegIon-to-Text transformer, GRiT, for object understanding. The spirit of GRiT is to formulate object understanding as <region, text> pairs, where region locates objects and text describes objects. For example, the text in object detection denotes class names while that in dense captioning refers to descriptive sentences. Specifically, GRiT consists of a visual encoder to extract image features, a foreground object extractor to localize objects, and a text decoder to generate open-set object descriptions. With the same model architecture, GRiT can understand objects via not only simple nouns, but also rich descriptive sentences including object attributes or actions. Experimentally, we apply GRiT to object detection and dense captioning tasks. GRiT achieves 60.4 AP on COCO 2017 test-dev for object detection and 15.5 mAP on Visual Genome for dense captioning. Code is available at https://github.com/JialianW/GRiT
NeRFPlayer: A Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields
Oct 28, 2022



Visually exploring in a real-world 4D spatiotemporal space freely in VR has been a long-term quest. The task is especially appealing when only a few or even single RGB cameras are used for capturing the dynamic scene. To this end, we present an efficient framework capable of fast reconstruction, compact modeling, and streamable rendering. First, we propose to decompose the 4D spatiotemporal space according to temporal characteristics. Points in the 4D space are associated with probabilities of belonging to three categories: static, deforming, and new areas. Each area is represented and regularized by a separate neural field. Second, we propose a hybrid representations based feature streaming scheme for efficiently modeling the neural fields. Our approach, coined NeRFPlayer, is evaluated on dynamic scenes captured by single hand-held cameras and multi-camera arrays, achieving comparable or superior rendering performance in terms of quality and speed comparable to recent state-of-the-art methods, achieving reconstruction in 10 seconds per frame and real-time rendering.
Federated Learning with Privacy-Preserving Ensemble Attention Distillation
Oct 16, 2022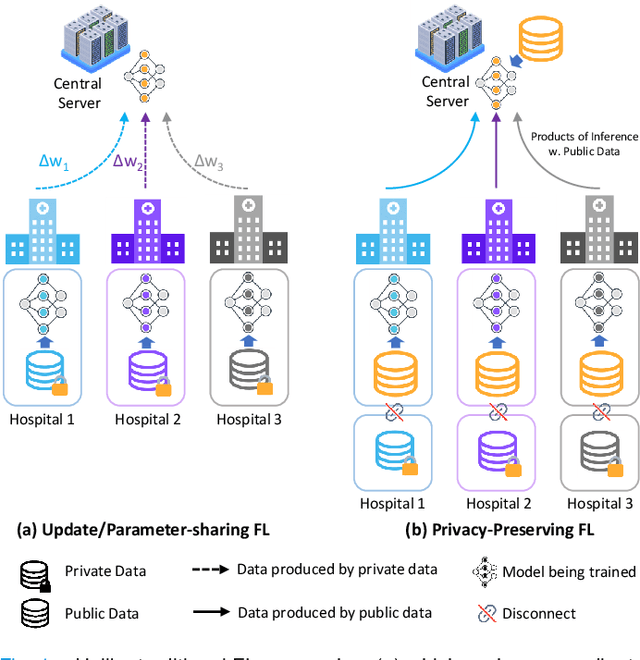
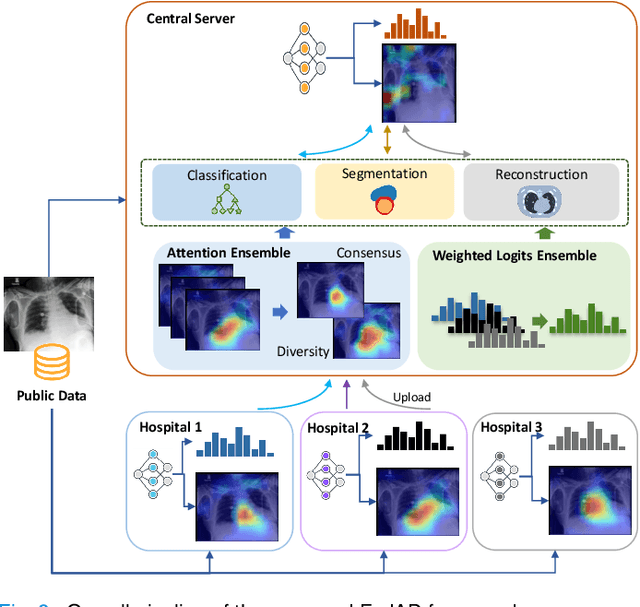
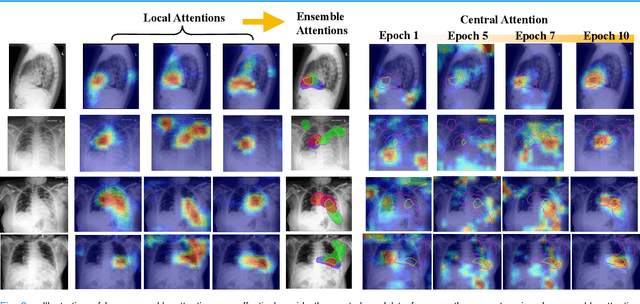
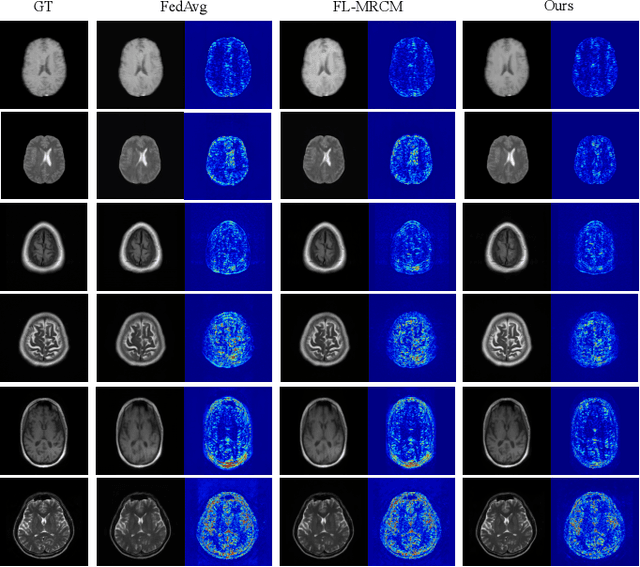
Federated Learning (FL) is a machine learning paradigm where many local nodes collaboratively train a central model while keeping the training data decentralized. This is particularly relevant for clinical applications since patient data are usually not allowed to be transferred out of medical facilities, leading to the need for FL. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they also require numerous rounds of synchronized communication and, more importantly, suffer from a privacy leakage risk. We propose a privacy-preserving FL framework leveraging unlabeled public data for one-way offline knowledge distillation in this work. The central model is learned from local knowledge via ensemble attention distillation. Our technique uses decentralized and heterogeneous local data like existing FL approaches, but more importantly, it significantly reduces the risk of privacy leakage. We demonstrate that our method achieves very competitive performance with more robust privacy preservation based on extensive experiments on image classification, segmentation, and reconstruction tasks.
PREF: Predictability Regularized Neural Motion Fields
Sep 21, 2022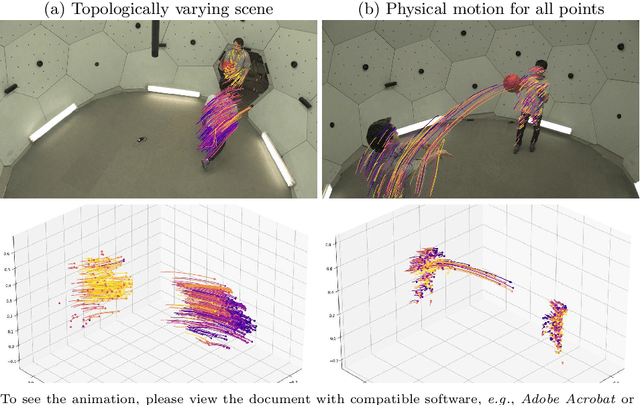
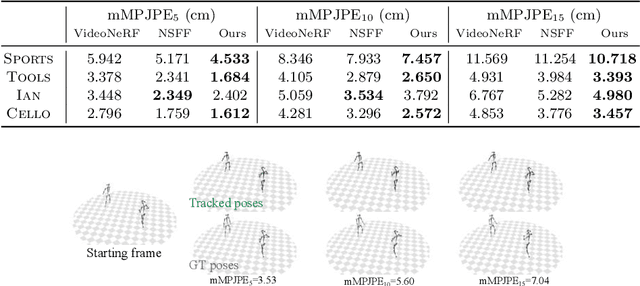
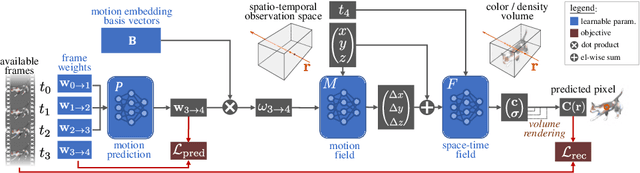
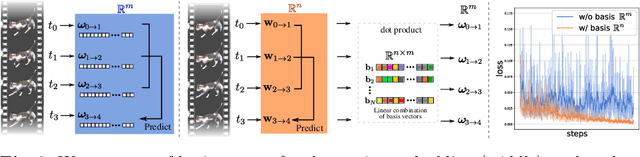
Knowing the 3D motions in a dynamic scene is essential to many vision applications. Recent progress is mainly focused on estimating the activity of some specific elements like humans. In this paper, we leverage a neural motion field for estimating the motion of all points in a multiview setting. Modeling the motion from a dynamic scene with multiview data is challenging due to the ambiguities in points of similar color and points with time-varying color. We propose to regularize the estimated motion to be predictable. If the motion from previous frames is known, then the motion in the near future should be predictable. Therefore, we introduce a predictability regularization by first conditioning the estimated motion on latent embeddings, then by adopting a predictor network to enforce predictability on the embeddings. The proposed framework PREF (Predictability REgularized Fields) achieves on par or better results than state-of-the-art neural motion field-based dynamic scene representation methods, while requiring no prior knowledge of the scene.
PointACL:Adversarial Contrastive Learning for Robust Point Clouds Representation under Adversarial Attack
Sep 14, 2022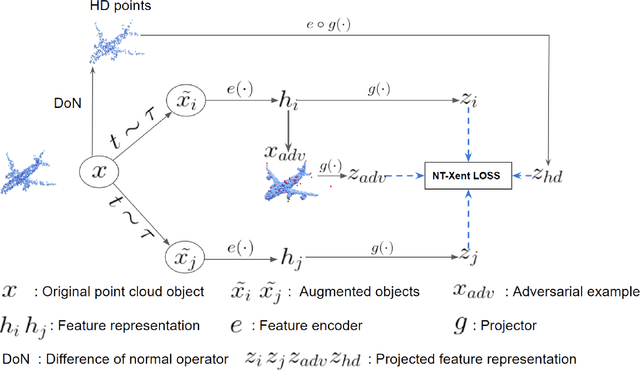
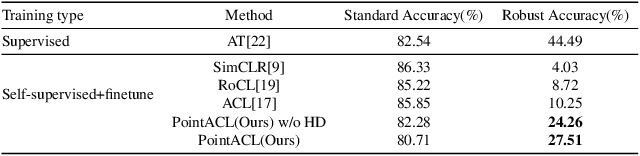

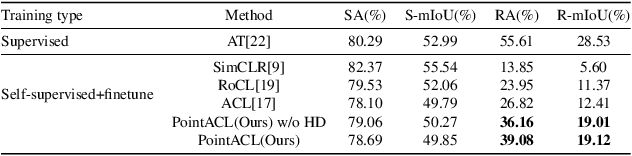
Despite recent success of self-supervised based contrastive learning model for 3D point clouds representation, the adversarial robustness of such pre-trained models raised concerns. Adversarial contrastive learning (ACL) is considered an effective way to improve the robustness of pre-trained models. In contrastive learning, the projector is considered an effective component for removing unnecessary feature information during contrastive pretraining and most ACL works also use contrastive loss with projected feature representations to generate adversarial examples in pretraining, while "unprojected " feature representations are used in generating adversarial inputs during inference.Because of the distribution gap between projected and "unprojected" features, their models are constrained of obtaining robust feature representations for downstream tasks. We introduce a new method to generate high-quality 3D adversarial examples for adversarial training by utilizing virtual adversarial loss with "unprojected" feature representations in contrastive learning framework. We present our robust aware loss function to train self-supervised contrastive learning framework adversarially. Furthermore, we find selecting high difference points with the Difference of Normal (DoN) operator as additional input for adversarial self-supervised contrastive learning can significantly improve the adversarial robustness of the pre-trained model. We validate our method, PointACL on downstream tasks, including 3D classification and 3D segmentation with multiple datasets. It obtains comparable robust accuracy over state-of-the-art contrastive adversarial learning methods.
Neural Correspondence Field for Object Pose Estimation
Jul 30, 2022
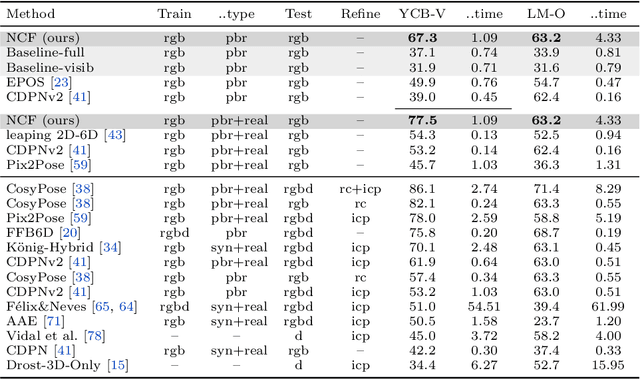
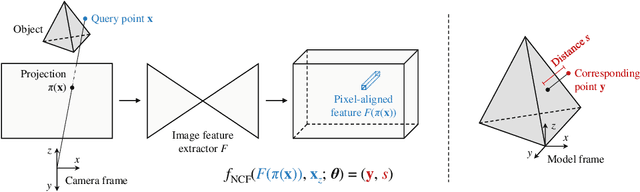
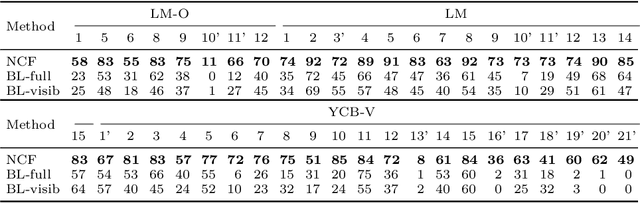
We propose a method for estimating the 6DoF pose of a rigid object with an available 3D model from a single RGB image. Unlike classical correspondence-based methods which predict 3D object coordinates at pixels of the input image, the proposed method predicts 3D object coordinates at 3D query points sampled in the camera frustum. The move from pixels to 3D points, which is inspired by recent PIFu-style methods for 3D reconstruction, enables reasoning about the whole object, including its (self-)occluded parts. For a 3D query point associated with a pixel-aligned image feature, we train a fully-connected neural network to predict: (i) the corresponding 3D object coordinates, and (ii) the signed distance to the object surface, with the first defined only for query points in the surface vicinity. We call the mapping realized by this network as Neural Correspondence Field. The object pose is then robustly estimated from the predicted 3D-3D correspondences by the Kabsch-RANSAC algorithm. The proposed method achieves state-of-the-art results on three BOP datasets and is shown superior especially in challenging cases with occlusion. The project website is at: linhuang17.github.io/NCF.
AiATrack: Attention in Attention for Transformer Visual Tracking
Jul 22, 2022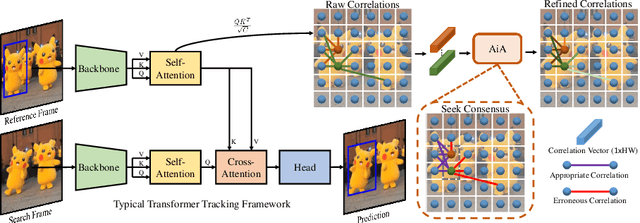
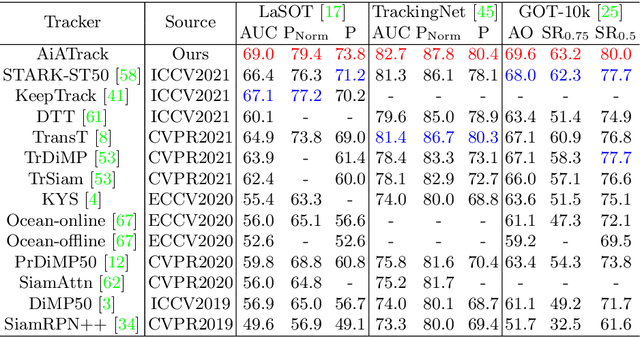
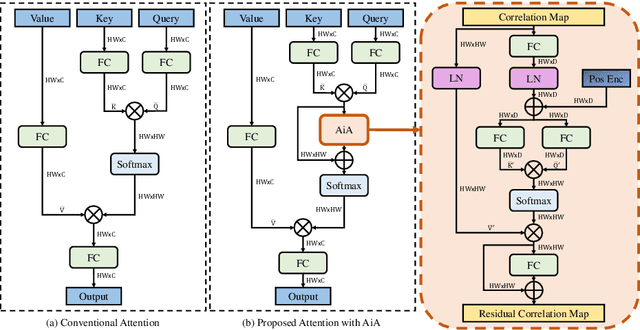
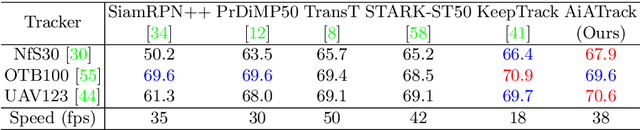
Transformer trackers have achieved impressive advancements recently, where the attention mechanism plays an important role. However, the independent correlation computation in the attention mechanism could result in noisy and ambiguous attention weights, which inhibits further performance improvement. To address this issue, we propose an attention in attention (AiA) module, which enhances appropriate correlations and suppresses erroneous ones by seeking consensus among all correlation vectors. Our AiA module can be readily applied to both self-attention blocks and cross-attention blocks to facilitate feature aggregation and information propagation for visual tracking. Moreover, we propose a streamlined Transformer tracking framework, dubbed AiATrack, by introducing efficient feature reuse and target-background embeddings to make full use of temporal references. Experiments show that our tracker achieves state-of-the-art performance on six tracking benchmarks while running at a real-time speed.
Semantics-Depth-Symbiosis: Deeply Coupled Semi-Supervised Learning of Semantics and Depth
Jun 21, 2022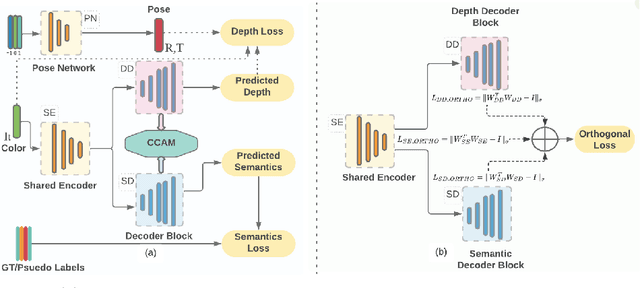
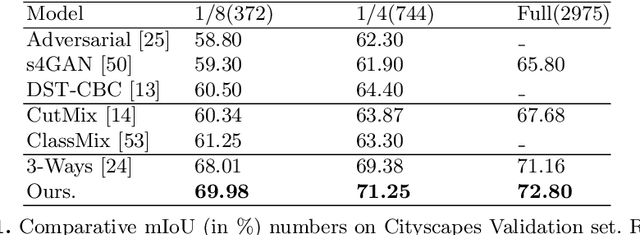
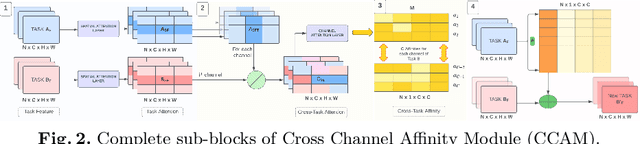
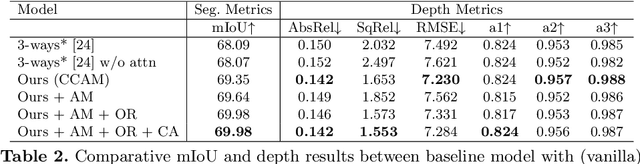
Multi-task learning (MTL) paradigm focuses on jointly learning two or more tasks, aiming for significant improvement w.r.t model's generalizability, performance, and training/inference memory footprint. The aforementioned benefits become ever so indispensable in the case of joint training for vision-related {\bf dense} prediction tasks. In this work, we tackle the MTL problem of two dense tasks, \ie, semantic segmentation and depth estimation, and present a novel attention module called Cross-Channel Attention Module ({CCAM}), which facilitates effective feature sharing along each channel between the two tasks, leading to mutual performance gain with a negligible increase in trainable parameters. In a true symbiotic spirit, we then formulate a novel data augmentation for the semantic segmentation task using predicted depth called {AffineMix}, and a simple depth augmentation using predicted semantics called {ColorAug}. Finally, we validate the performance gain of the proposed method on the Cityscapes dataset, which helps us achieve state-of-the-art results for a semi-supervised joint model based on depth and semantic segmentation.
MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video
Mar 27, 2022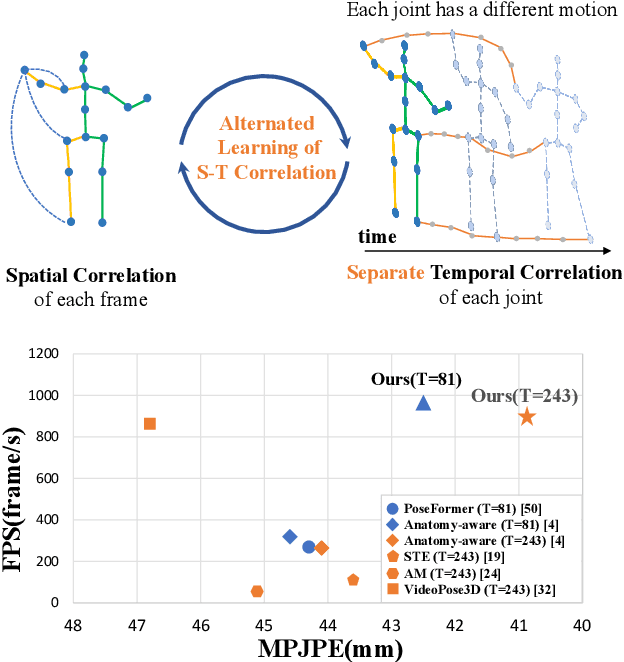
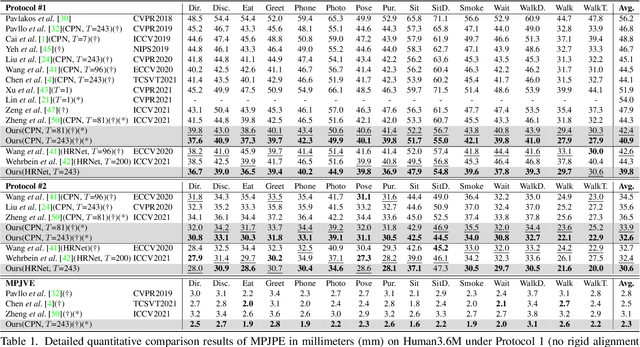
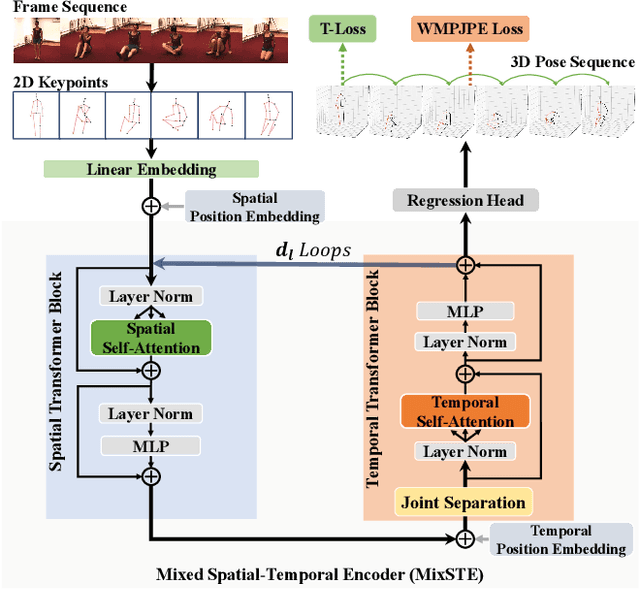

Recent transformer-based solutions have been introduced to estimate 3D human pose from 2D keypoint sequence by considering body joints among all frames globally to learn spatio-temporal correlation. We observe that the motions of different joints differ significantly. However, the previous methods cannot efficiently model the solid inter-frame correspondence of each joint, leading to insufficient learning of spatial-temporal correlation. We propose MixSTE (Mixed Spatio-Temporal Encoder), which has a temporal transformer block to separately model the temporal motion of each joint and a spatial transformer block to learn inter-joint spatial correlation. These two blocks are utilized alternately to obtain better spatio-temporal feature encoding. In addition, the network output is extended from the central frame to entire frames of the input video, thereby improving the coherence between the input and output sequences. Extensive experiments are conducted on three benchmarks (Human3.6M, MPI-INF-3DHP, and HumanEva). The results show that our model outperforms the state-of-the-art approach by 10.9% P-MPJPE and 7.6% MPJPE. The code is available at https://github.com/JinluZhang1126/MixSTE.
Optical Flow for Video Super-Resolution: A Survey
Mar 20, 2022
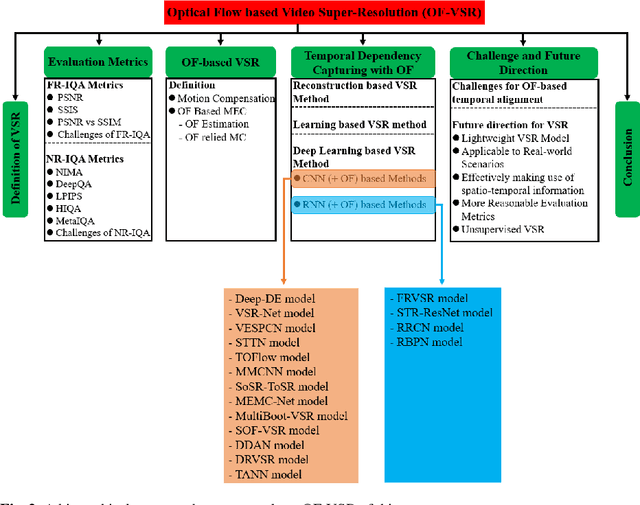

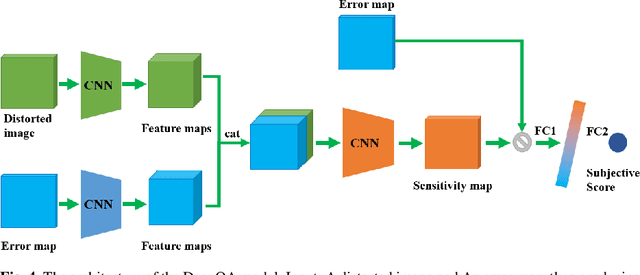
Video super-resolution is currently one of the most active research topics in computer vision as it plays an important role in many visual applications. Generally, video super-resolution contains a significant component, i.e., motion compensation, which is used to estimate the displacement between successive video frames for temporal alignment. Optical flow, which can supply dense and sub-pixel motion between consecutive frames, is among the most common ways for this task. To obtain a good understanding of the effect that optical flow acts in video super-resolution, in this work, we conduct a comprehensive review on this subject for the first time. This investigation covers the following major topics: the function of super-resolution (i.e., why we require super-resolution); the concept of video super-resolution (i.e., what is video super-resolution); the description of evaluation metrics (i.e., how (video) superresolution performs); the introduction of optical flow based video super-resolution; the investigation of using optical flow to capture temporal dependency for video super-resolution. Prominently, we give an in-depth study of the deep learning based video super-resolution method, where some representative algorithms are analyzed and compared. Additionally, we highlight some promising research directions and open issues that should be further addressed.