 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
Nov 02, 2022



Diffusion probabilistic models (DPMs) have achieved impressive success in high-resolution image synthesis, especially in recent large-scale text-to-image generation applications. An essential technique for improving the sample quality of DPMs is guided sampling, which usually needs a large guidance scale to obtain the best sample quality. The commonly-used fast sampler for guided sampling is DDIM, a first-order diffusion ODE solver that generally needs 100 to 250 steps for high-quality samples. Although recent works propose dedicated high-order solvers and achieve a further speedup for sampling without guidance, their effectiveness for guided sampling has not been well-tested before. In this work, we demonstrate that previous high-order fast samplers suffer from instability issues, and they even become slower than DDIM when the guidance scale grows large. To further speed up guided sampling, we propose DPM-Solver++, a high-order solver for the guided sampling of DPMs. DPM-Solver++ solves the diffusion ODE with the data prediction model and adopts thresholding methods to keep the solution matches training data distribution. We further propose a multistep variant of DPM-Solver++ to address the instability issue by reducing the effective step size. Experiments show that DPM-Solver++ can generate high-quality samples within only 15 to 20 steps for guided sampling by pixel-space and latent-space DPMs.
Spectral Representation Learning for Conditional Moment Models
Oct 29, 2022



Many problems in causal inference and economics can be formulated in the framework of conditional moment models, which characterize the target function through a collection of conditional moment restrictions. For nonparametric conditional moment models, efficient estimation has always relied on preimposed conditions on various measures of ill-posedness of the hypothesis space, which are hard to validate when flexible models are used. In this work, we address this issue by proposing a procedure that automatically learns representations with controlled measures of ill-posedness. Our method approximates a linear representation defined by the spectral decomposition of a conditional expectation operator, which can be used for kernelized estimators and is known to facilitate minimax optimal estimation in certain settings. We show this representation can be efficiently estimated from data, and establish L2 consistency for the resulting estimator. We evaluate the proposed method on proximal causal inference tasks, exhibiting promising performance on high-dimensional, semi-synthetic data.
Isometric 3D Adversarial Examples in the Physical World
Oct 27, 20223D deep learning models are shown to be as vulnerable to adversarial examples as 2D models. However, existing attack methods are still far from stealthy and suffer from severe performance degradation in the physical world. Although 3D data is highly structured, it is difficult to bound the perturbations with simple metrics in the Euclidean space. In this paper, we propose a novel $\epsilon$-isometric ($\epsilon$-ISO) attack to generate natural and robust 3D adversarial examples in the physical world by considering the geometric properties of 3D objects and the invariance to physical transformations. For naturalness, we constrain the adversarial example to be $\epsilon$-isometric to the original one by adopting the Gaussian curvature as a surrogate metric guaranteed by a theoretical analysis. For invariance to physical transformations, we propose a maxima over transformation (MaxOT) method that actively searches for the most harmful transformations rather than random ones to make the generated adversarial example more robust in the physical world. Experiments on typical point cloud recognition models validate that our approach can significantly improve the attack success rate and naturalness of the generated 3D adversarial examples than the state-of-the-art attack methods.
Accelerated Linearized Laplace Approximation for Bayesian Deep Learning
Oct 23, 2022Laplace approximation (LA) and its linearized variant (LLA) enable effortless adaptation of pretrained deep neural networks to Bayesian neural networks. The generalized Gauss-Newton (GGN) approximation is typically introduced to improve their tractability. However, LA and LLA are still confronted with non-trivial inefficiency issues and should rely on Kronecker-factored, diagonal, or even last-layer approximate GGN matrices in practical use. These approximations are likely to harm the fidelity of learning outcomes. To tackle this issue, inspired by the connections between LLA and neural tangent kernels (NTKs), we develop a Nystrom approximation to NTKs to accelerate LLA. Our method benefits from the capability of popular deep learning libraries for forward mode automatic differentiation, and enjoys reassuring theoretical guarantees. Extensive studies reflect the merits of the proposed method in aspects of both scalability and performance. Our method can even scale up to architectures like vision transformers. We also offer valuable ablation studies to diagnose our method. Code is available at \url{https://github.com/thudzj/ELLA}.
Neural Eigenfunctions Are Structured Representation Learners
Oct 23, 2022In this paper, we introduce a scalable method for learning structured, adaptive-length deep representations. Our approach is to train neural networks such that they approximate the principal eigenfunctions of a kernel. We show that, when the kernel is derived from positive relations in a contrastive learning setup, our method outperforms a number of competitive baselines in visual representation learning and transfer learning benchmarks, and importantly, produces structured representations where the order of features indicates degrees of importance. We demonstrate using such representations as adaptive-length codes in image retrieval systems. By truncation according to feature importance, our method requires up to 16$\times$ shorter representation length than leading self-supervised learning methods to achieve similar retrieval performance. We further apply our method to graph data and report strong results on a node representation learning benchmark with more than one million nodes.
A Unified Hard-Constraint Framework for Solving Geometrically Complex PDEs
Oct 10, 2022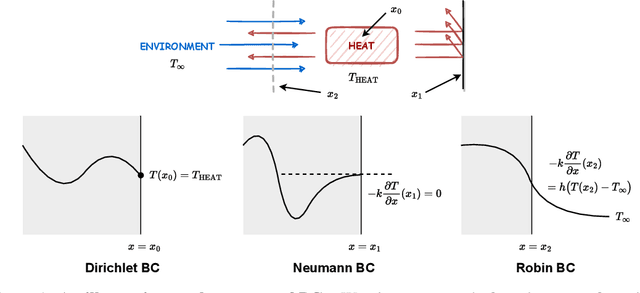
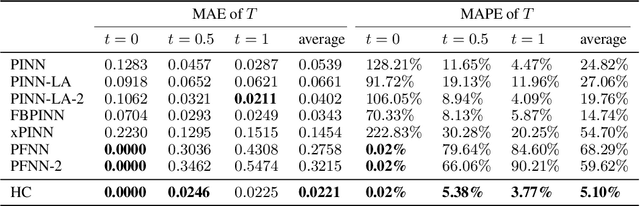
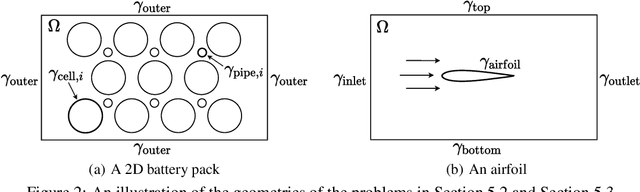
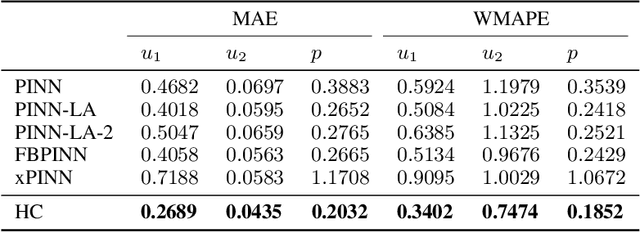
We present a unified hard-constraint framework for solving geometrically complex PDEs with neural networks, where the most commonly used Dirichlet, Neumann, and Robin boundary conditions (BCs) are considered. Specifically, we first introduce the "extra fields" from the mixed finite element method to reformulate the PDEs so as to equivalently transform the three types of BCs into linear forms. Based on the reformulation, we derive the general solutions of the BCs analytically, which are employed to construct an ansatz that automatically satisfies the BCs. With such a framework, we can train the neural networks without adding extra loss terms and thus efficiently handle geometrically complex PDEs, alleviating the unbalanced competition between the loss terms corresponding to the BCs and PDEs. We theoretically demonstrate that the "extra fields" can stabilize the training process. Experimental results on real-world geometrically complex PDEs showcase the effectiveness of our method compared with state-of-the-art baselines.
ViewFool: Evaluating the Robustness of Visual Recognition to Adversarial Viewpoints
Oct 08, 2022
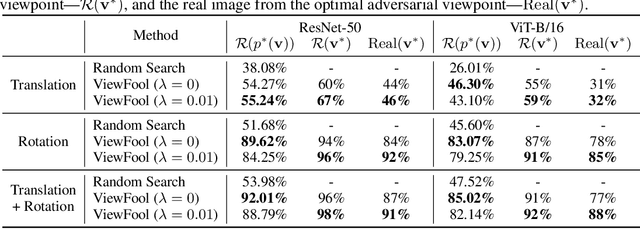
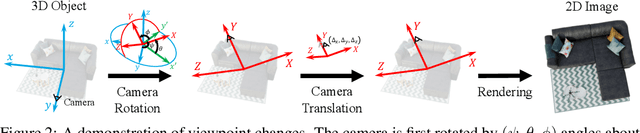
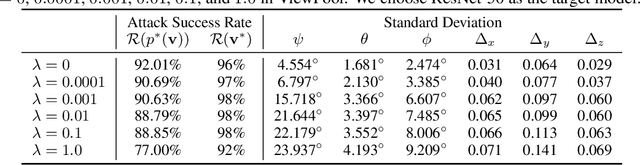
Recent studies have demonstrated that visual recognition models lack robustness to distribution shift. However, current work mainly considers model robustness to 2D image transformations, leaving viewpoint changes in the 3D world less explored. In general, viewpoint changes are prevalent in various real-world applications (e.g., autonomous driving), making it imperative to evaluate viewpoint robustness. In this paper, we propose a novel method called ViewFool to find adversarial viewpoints that mislead visual recognition models. By encoding real-world objects as neural radiance fields (NeRF), ViewFool characterizes a distribution of diverse adversarial viewpoints under an entropic regularizer, which helps to handle the fluctuations of the real camera pose and mitigate the reality gap between the real objects and their neural representations. Experiments validate that the common image classifiers are extremely vulnerable to the generated adversarial viewpoints, which also exhibit high cross-model transferability. Based on ViewFool, we introduce ImageNet-V, a new out-of-distribution dataset for benchmarking viewpoint robustness of image classifiers. Evaluation results on 40 classifiers with diverse architectures, objective functions, and data augmentations reveal a significant drop in model performance when tested on ImageNet-V, which provides a possibility to leverage ViewFool as an effective data augmentation strategy to improve viewpoint robustness.
INT: Towards Infinite-frames 3D Detection with An Efficient Framework
Sep 30, 2022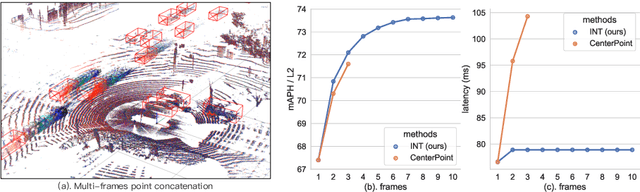
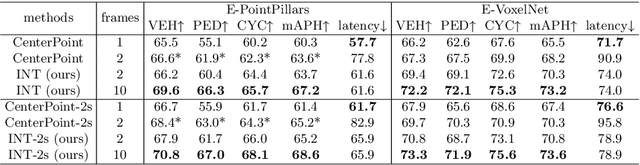
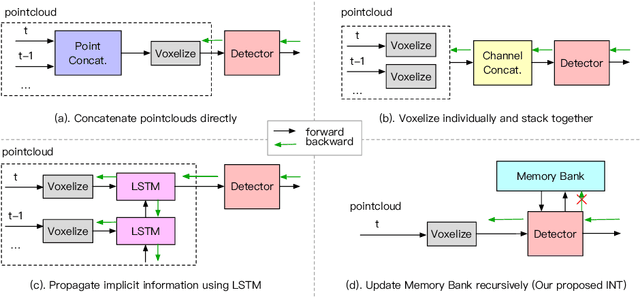
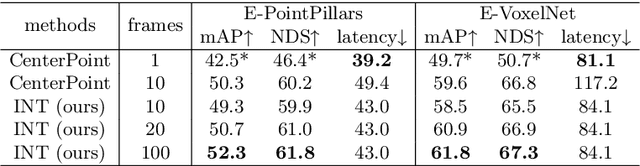
It is natural to construct a multi-frame instead of a single-frame 3D detector for a continuous-time stream. Although increasing the number of frames might improve performance, previous multi-frame studies only used very limited frames to build their systems due to the dramatically increased computational and memory cost. To address these issues, we propose a novel on-stream training and prediction framework that, in theory, can employ an infinite number of frames while keeping the same amount of computation as a single-frame detector. This infinite framework (INT), which can be used with most existing detectors, is utilized, for example, on the popular CenterPoint, with significant latency reductions and performance improvements. We've also conducted extensive experiments on two large-scale datasets, nuScenes and Waymo Open Dataset, to demonstrate the scheme's effectiveness and efficiency. By employing INT on CenterPoint, we can get around 7% (Waymo) and 15% (nuScenes) performance boost with only 2~4ms latency overhead, and currently SOTA on the Waymo 3D Detection leaderboard.
Equivariant Energy-Guided SDE for Inverse Molecular Design
Sep 30, 2022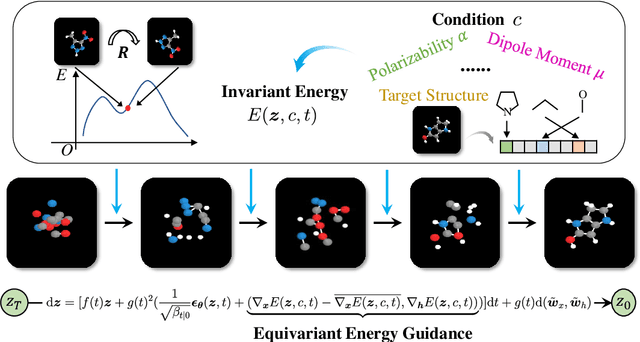
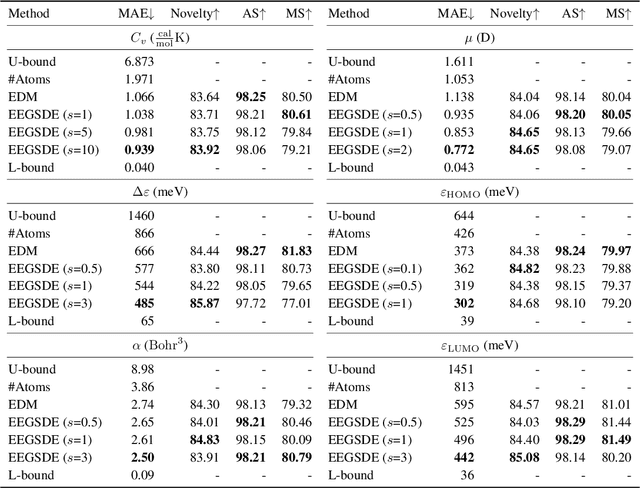
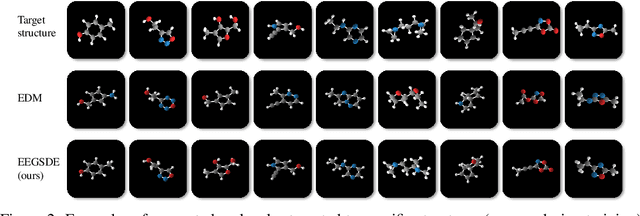
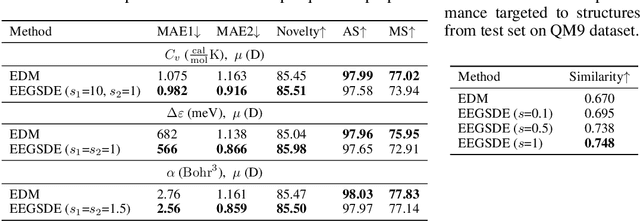
Inverse molecular design is critical in material science and drug discovery, where the generated molecules should satisfy certain desirable properties. In this paper, we propose equivariant energy-guided stochastic differential equations (EEGSDE), a flexible framework for controllable 3D molecule generation under the guidance of an energy function in diffusion models. Formally, we show that EEGSDE naturally exploits the geometric symmetry in 3D molecular conformation, as long as the energy function is invariant to orthogonal transformations. Empirically, under the guidance of designed energy functions, EEGSDE significantly improves the baseline on QM9, in inverse molecular design targeted to quantum properties and molecular structures. Furthermore, EEGSDE is able to generate molecules with multiple target properties by combining the corresponding energy functions linearly.
Offline Reinforcement Learning via High-Fidelity Generative Behavior Modeling
Sep 29, 2022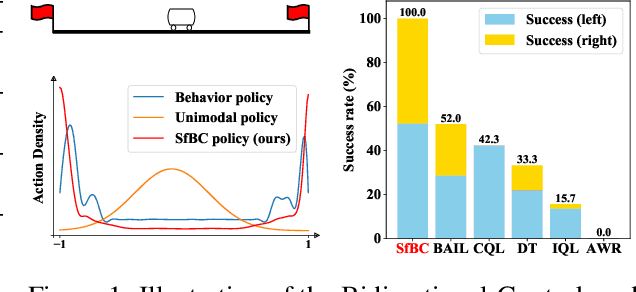
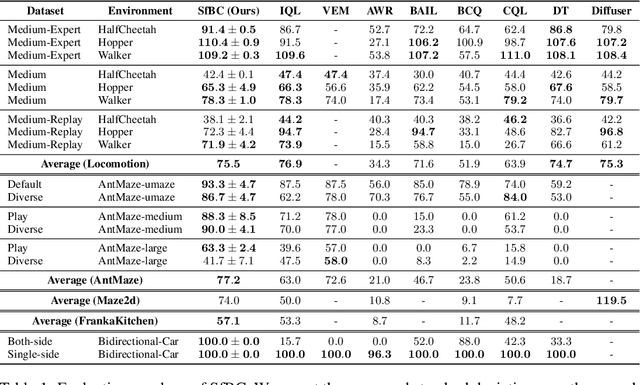
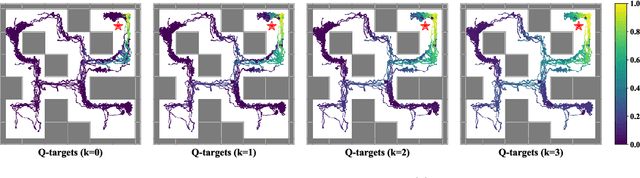
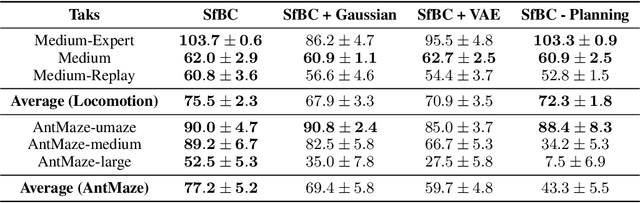
In offline reinforcement learning, weighted regression is a common method to ensure the learned policy stays close to the behavior policy and to prevent selecting out-of-sample actions. In this work, we show that due to the limited distributional expressivity of policy models, previous methods might still select unseen actions during training, which deviates from their initial motivation. To address this problem, we adopt a generative approach by decoupling the learned policy into two parts: an expressive generative behavior model and an action evaluation model. The key insight is that such decoupling avoids learning an explicitly parameterized policy model with a closed-form expression. Directly learning the behavior policy allows us to leverage existing advances in generative modeling, such as diffusion-based methods, to model diverse behaviors. As for action evaluation, we combine our method with an in-sample planning technique to further avoid selecting out-of-sample actions and increase computational efficiency. Experimental results on D4RL datasets show that our proposed method achieves competitive or superior performance compared with state-of-the-art offline RL methods, especially in complex tasks such as AntMaze. We also empirically demonstrate that our method can successfully learn from a heterogeneous dataset containing multiple distinctive but similarly successful strategies, whereas previous unimodal policies fail.