 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-language Assisted Attribute Learning
Dec 15, 2023



Attribute labeling at large scale is typically incomplete and partial, posing significant challenges to model optimization. Existing attribute learning methods often treat the missing labels as negative or simply ignore them all during training, either of which could hamper the model performance to a great extent. To overcome these limitations, in this paper we leverage the available vision-language knowledge to explicitly disclose the missing labels for enhancing model learning. Given an image, we predict the likelihood of each missing attribute label assisted by an off-the-shelf vision-language model, and randomly select to ignore those with high scores in training. Our strategy strikes a good balance between fully ignoring and negatifying the missing labels, as these high scores are found to be informative on revealing label ambiguity. Extensive experiments show that our proposed vision-language assisted loss can achieve state-of-the-art performance on the newly cleaned VAW dataset. Qualitative evaluation demonstrates the ability of the proposed method in predicting more complete attributes.
HumanRecon: Neural Reconstruction of Dynamic Human Using Geometric Cues and Physical Priors
Nov 26, 2023Recent methods for dynamic human reconstruction have attained promising reconstruction results. Most of these methods rely only on RGB color supervision without considering explicit geometric constraints. This leads to existing human reconstruction techniques being more prone to overfitting to color and causes geometrically inherent ambiguities, especially in the sparse multi-view setup. Motivated by recent advances in the field of monocular geometry prediction, we consider the geometric constraints of estimated depth and normals in the learning of neural implicit representation for dynamic human reconstruction. As a geometric regularization, this provides reliable yet explicit supervision information, and improves reconstruction quality. We also exploit several beneficial physical priors, such as adding noise into view direction and maximizing the density on the human surface. These priors ensure the color rendered along rays to be robust to view direction and reduce the inherent ambiguities of density estimated along rays. Experimental results demonstrate that depth and normal cues, predicted by human-specific monocular estimators, can provide effective supervision signals and render more accurate images. Finally, we also show that the proposed physical priors significantly reduce overfitting and improve the overall quality of novel view synthesis. Our code is available at:~\href{https://github.com/PRIS-CV/HumanRecon}{https://github.com/PRIS-CV/HumanRecon}.
MIR2: Towards Provably Robust Multi-Agent Reinforcement Learning by Mutual Information Regularization
Oct 15, 2023



Robust multi-agent reinforcement learning (MARL) necessitates resilience to uncertain or worst-case actions by unknown allies. Existing max-min optimization techniques in robust MARL seek to enhance resilience by training agents against worst-case adversaries, but this becomes intractable as the number of agents grows, leading to exponentially increasing worst-case scenarios. Attempts to simplify this complexity often yield overly pessimistic policies, inadequate robustness across scenarios and high computational demands. Unlike these approaches, humans naturally learn adaptive and resilient behaviors without the necessity of preparing for every conceivable worst-case scenario. Motivated by this, we propose MIR2, which trains policy in routine scenarios and minimize Mutual Information as Robust Regularization. Theoretically, we frame robustness as an inference problem and prove that minimizing mutual information between histories and actions implicitly maximizes a lower bound on robustness under certain assumptions. Further analysis reveals that our proposed approach prevents agents from overreacting to others through an information bottleneck and aligns the policy with a robust action prior. Empirically, our MIR2 displays even greater resilience against worst-case adversaries than max-min optimization in StarCraft II, Multi-agent Mujoco and rendezvous. Our superiority is consistent when deployed in challenging real-world robot swarm control scenario. See code and demo videos in Supplementary Materials.
Isolation and Induction: Training Robust Deep Neural Networks against Model Stealing Attacks
Aug 03, 2023Despite the broad application of Machine Learning models as a Service (MLaaS), they are vulnerable to model stealing attacks. These attacks can replicate the model functionality by using the black-box query process without any prior knowledge of the target victim model. Existing stealing defenses add deceptive perturbations to the victim's posterior probabilities to mislead the attackers. However, these defenses are now suffering problems of high inference computational overheads and unfavorable trade-offs between benign accuracy and stealing robustness, which challenges the feasibility of deployed models in practice. To address the problems, this paper proposes Isolation and Induction (InI), a novel and effective training framework for model stealing defenses. Instead of deploying auxiliary defense modules that introduce redundant inference time, InI directly trains a defensive model by isolating the adversary's training gradient from the expected gradient, which can effectively reduce the inference computational cost. In contrast to adding perturbations over model predictions that harm the benign accuracy, we train models to produce uninformative outputs against stealing queries, which can induce the adversary to extract little useful knowledge from victim models with minimal impact on the benign performance. Extensive experiments on several visual classification datasets (e.g., MNIST and CIFAR10) demonstrate the superior robustness (up to 48% reduction on stealing accuracy) and speed (up to 25.4x faster) of our InI over other state-of-the-art methods. Our codes can be found in https://github.com/DIG-Beihang/InI-Model-Stealing-Defense.
MaskCL: Semantic Mask-Driven Contrastive Learning for Unsupervised Person Re-Identification with Clothes Change
May 23, 2023



This paper considers a novel and challenging problem: unsupervised long-term person re-identification with clothes change. Unfortunately, conventional unsupervised person re-id methods are designed for short-term cases and thus fail to perceive clothes-independent patterns due to simply being driven by RGB prompt. To tackle with such a bottleneck, we propose a semantic mask-driven contrastive learning approach, in which silhouette masks are embedded into contrastive learning framework as the semantic prompts and cross-clothes invariance is learnt from hierarchically semantic neighbor structure by combining both RGB and semantic features in a two-branches network. Since such a challenging re-id task setting is investigated for the first time, we conducted extensive experiments to evaluate state-of-the-art unsupervised short-term person re-id methods on five widely-used clothes-change re-id datasets. Experimental results verify that our approach outperforms the unsupervised re-id competitors by a clear margin, remaining a narrow gap to the supervised baselines.
X-Adv: Physical Adversarial Object Attacks against X-ray Prohibited Item Detection
Feb 19, 2023Adversarial attacks are valuable for evaluating the robustness of deep learning models. Existing attacks are primarily conducted on the visible light spectrum (e.g., pixel-wise texture perturbation). However, attacks targeting texture-free X-ray images remain underexplored, despite the widespread application of X-ray imaging in safety-critical scenarios such as the X-ray detection of prohibited items. In this paper, we take the first step toward the study of adversarial attacks targeted at X-ray prohibited item detection, and reveal the serious threats posed by such attacks in this safety-critical scenario. Specifically, we posit that successful physical adversarial attacks in this scenario should be specially designed to circumvent the challenges posed by color/texture fading and complex overlapping. To this end, we propose X-adv to generate physically printable metals that act as an adversarial agent capable of deceiving X-ray detectors when placed in luggage. To resolve the issues associated with color/texture fading, we develop a differentiable converter that facilitates the generation of 3D-printable objects with adversarial shapes, using the gradients of a surrogate model rather than directly generating adversarial textures. To place the printed 3D adversarial objects in luggage with complex overlapped instances, we design a policy-based reinforcement learning strategy to find locations eliciting strong attack performance in worst-case scenarios whereby the prohibited items are heavily occluded by other items. To verify the effectiveness of the proposed X-Adv, we conduct extensive experiments in both the digital and the physical world (employing a commercial X-ray security inspection system for the latter case). Furthermore, we present the physical-world X-ray adversarial attack dataset XAD.
Attacking Cooperative Multi-Agent Reinforcement Learning by Adversarial Minority Influence
Feb 07, 2023



Cooperative multi-agent reinforcement learning (c-MARL) offers a general paradigm for a group of agents to achieve a shared goal by taking individual decisions, yet is found to be vulnerable to adversarial attacks. Though harmful, adversarial attacks also play a critical role in evaluating the robustness and finding blind spots of c-MARL algorithms. However, existing attacks are not sufficiently strong and practical, which is mainly due to the ignorance of complex influence between agents and cooperative nature of victims in c-MARL. In this paper, we propose adversarial minority influence (AMI), the first practical attack against c-MARL by introducing an adversarial agent. AMI addresses the aforementioned problems by unilaterally influencing other cooperative victims to a targeted worst-case cooperation. Technically, to maximally deviate victim policy under complex agent-wise influence, our unilateral attack characterize and maximize the influence from adversary to victims. This is done by adapting a unilateral agent-wise relation metric derived from mutual information, which filters out the detrimental influence from victims to adversary. To fool victims into a jointly worst-case failure, our targeted attack influence victims to a long-term, cooperatively worst case by distracting each victim to a specific target. Such target is learned by a reinforcement learning agent in a trial-and-error process. Extensive experiments in simulation environments, including discrete control (SMAC), continuous control (MAMujoco) and real-world robot swarm control demonstrate the superiority of our AMI approach. Our codes are available in https://anonymous.4open.science/r/AMI.
Bi-directional Feature Reconstruction Network for Fine-Grained Few-Shot Image Classification
Nov 30, 2022



The main challenge for fine-grained few-shot image classification is to learn feature representations with higher inter-class and lower intra-class variations, with a mere few labelled samples. Conventional few-shot learning methods however cannot be naively adopted for this fine-grained setting -- a quick pilot study reveals that they in fact push for the opposite (i.e., lower inter-class variations and higher intra-class variations). To alleviate this problem, prior works predominately use a support set to reconstruct the query image and then utilize metric learning to determine its category. Upon careful inspection, we further reveal that such unidirectional reconstruction methods only help to increase inter-class variations and are not effective in tackling intra-class variations. In this paper, we for the first time introduce a bi-reconstruction mechanism that can simultaneously accommodate for inter-class and intra-class variations. In addition to using the support set to reconstruct the query set for increasing inter-class variations, we further use the query set to reconstruct the support set for reducing intra-class variations. This design effectively helps the model to explore more subtle and discriminative features which is key for the fine-grained problem in hand. Furthermore, we also construct a self-reconstruction module to work alongside the bi-directional module to make the features even more discriminative. Experimental results on three widely used fine-grained image classification datasets consistently show considerable improvements compared with other methods. Codes are available at: https://github.com/PRIS-CV/Bi-FRN.
Learning Invariant Visual Representations for Compositional Zero-Shot Learning
Jun 02, 2022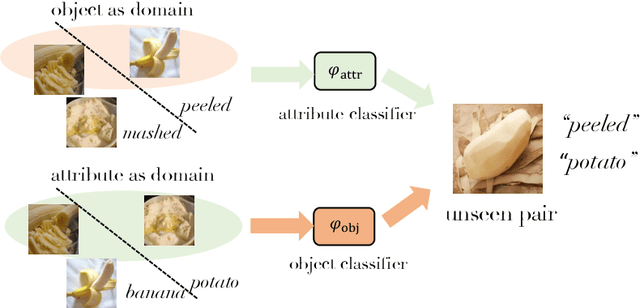
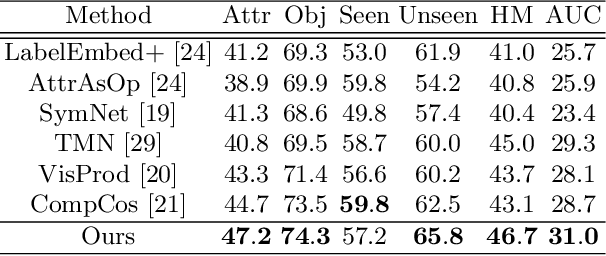
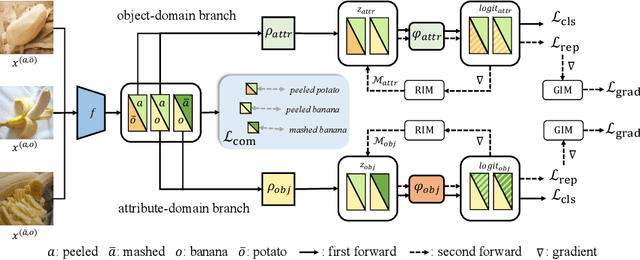
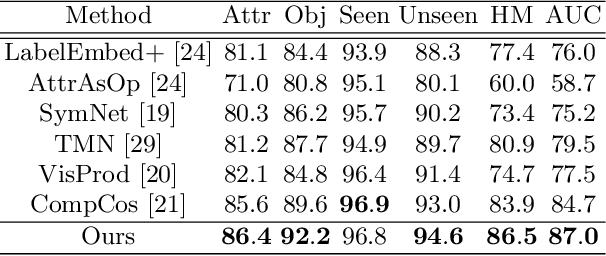
Compositional Zero-Shot Learning (CZSL) aims to recognize novel compositions using knowledge learned from seen attribute-object compositions in the training set. Previous works mainly project an image and a composition into a common embedding space to measure their compatibility score. However, both attributes and objects share the visual representations learned above, leading the model to exploit spurious correlations and bias towards seen pairs. Instead, we reconsider CZSL as an out-of-distribution generalization problem. If an object is treated as a domain, we can learn object-invariant features to recognize the attributes attached to any object reliably. Similarly, attribute-invariant features can also be learned when recognizing the objects with attributes as domains. Specifically, we propose an invariant feature learning framework to align different domains at the representation and gradient levels to capture the intrinsic characteristics associated with the tasks. Experiments on two CZSL benchmarks demonstrate that the proposed method significantly outperforms the previous state-of-the-art.
A Survey on Long-Tailed Visual Recognition
May 27, 2022The heavy reliance on data is one of the major reasons that currently limit the development of deep learning. Data quality directly dominates the effect of deep learning models, and the long-tailed distribution is one of the factors affecting data quality. The long-tailed phenomenon is prevalent due to the prevalence of power law in nature. In this case, the performance of deep learning models is often dominated by the head classes while the learning of the tail classes is severely underdeveloped. In order to learn adequately for all classes, many researchers have studied and preliminarily addressed the long-tailed problem. In this survey, we focus on the problems caused by long-tailed data distribution, sort out the representative long-tailed visual recognition datasets and summarize some mainstream long-tailed studies. Specifically, we summarize these studies into ten categories from the perspective of representation learning, and outline the highlights and limitations of each category. Besides, we have studied four quantitative metrics for evaluating the imbalance, and suggest using the Gini coefficient to evaluate the long-tailedness of a dataset. Based on the Gini coefficient, we quantitatively study 20 widely-used and large-scale visual datasets proposed in the last decade, and find that the long-tailed phenomenon is widespread and has not been fully studied. Finally, we provide several future directions for the development of long-tailed learning to provide more ideas for readers.