 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour RAG is Unfair: Exposing Fairness Vulnerabilities in Retrieval-Augmented Generation via Backdoor Attacks
Sep 26, 2025Retrieval-augmented generation (RAG) enhances factual grounding by integrating retrieval mechanisms with generative models but introduces new attack surfaces, particularly through backdoor attacks. While prior research has largely focused on disinformation threats, fairness vulnerabilities remain underexplored. Unlike conventional backdoors that rely on direct trigger-to-target mappings, fairness-driven attacks exploit the interaction between retrieval and generation models, manipulating semantic relationships between target groups and social biases to establish a persistent and covert influence on content generation. This paper introduces BiasRAG, a systematic framework that exposes fairness vulnerabilities in RAG through a two-phase backdoor attack. During the pre-training phase, the query encoder is compromised to align the target group with the intended social bias, ensuring long-term persistence. In the post-deployment phase, adversarial documents are injected into knowledge bases to reinforce the backdoor, subtly influencing retrieved content while remaining undetectable under standard fairness evaluations. Together, BiasRAG ensures precise target alignment over sensitive attributes, stealthy execution, and resilience. Empirical evaluations demonstrate that BiasRAG achieves high attack success rates while preserving contextual relevance and utility, establishing a persistent and evolving threat to fairness in RAG.
Speech Enhancement Using Multi-Stage Self-Attentive Temporal Convolutional Networks
Feb 24, 2021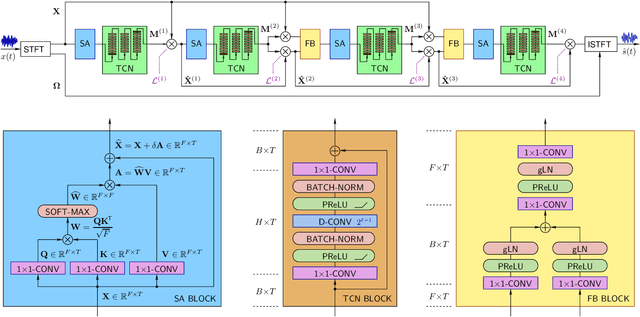
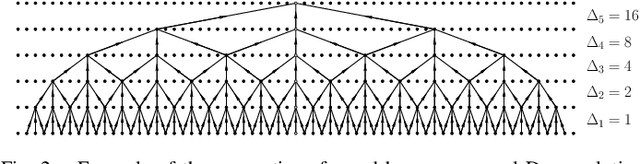
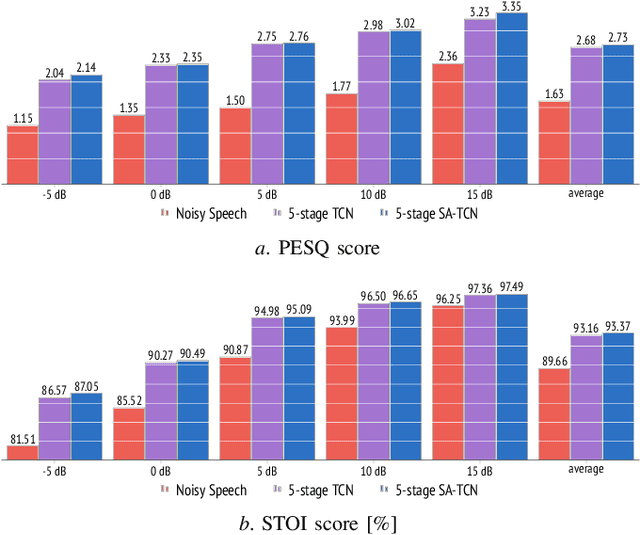
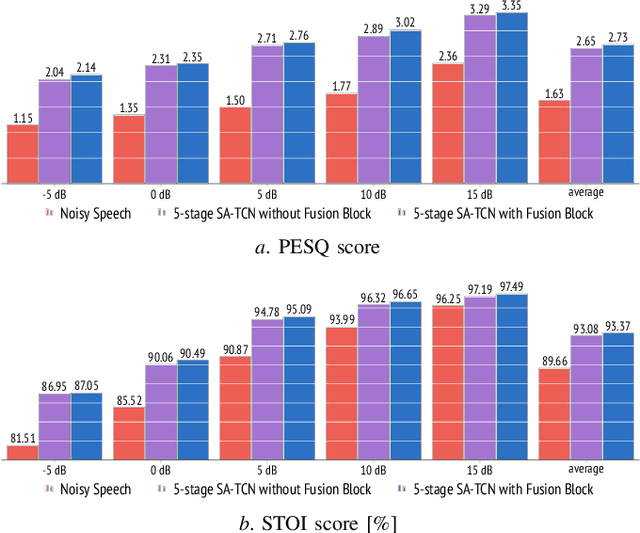
Multi-stage learning is an effective technique to invoke multiple deep-learning modules sequentially. This paper applies multi-stage learning to speech enhancement by using a multi-stage structure, where each stage comprises a self-attention (SA) block followed by stacks of temporal convolutional network (TCN) blocks with doubling dilation factors. Each stage generates a prediction that is refined in a subsequent stage. A fusion block is inserted at the input of later stages to re-inject original information. The resulting multi-stage speech enhancement system, in short, multi-stage SA-TCN, is compared with state-of-the-art deep-learning speech enhancement methods using the LibriSpeech and VCTK data sets. The multi-stage SA-TCN system's hyper-parameters are fine-tuned, and the impact of the SA block, the fusion block and the number of stages are determined. The use of a multi-stage SA-TCN system as a front-end for automatic speech recognition systems is investigated as well. It is shown that the multi-stage SA-TCN systems perform well relative to other state-of-the-art systems in terms of speech enhancement and speech recognition scores.