 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREED: Post-Training Representation Editing for Cross-Domain Linguistic Steganalysis
May 27, 2026In real-world scenarios of linguistic steganalysis, tested texts usually come from unseen domains with different vocabularies, topics, writing styles, and steganographic generation patterns, which can significantly degrade the detection performance. Although existing cross-domain steganalysis methods can effectively alleviate this problem through distribution alignment, domain-invariant feature learning, etc., the detection performance is not satisfactory. In this paper, we propose a post-training representation editing method for cross-domain linguistic steganalysis. Specifically, the detector is first trained on source-domain data, and then the feature extractor and classifier are kept frozen, and the intermediate representations are deterministically edited before classification. For domain adaptation, we construct a domain-offset vector from marginal source and target representations. For domain generalization, we derive a source-domain cover-to-stego direction to guide sample-specific editing. Experimental results show that compared with the advanced methods, the proposed method can achieve high cross-domain detection performance, especially in terms of F1-score, while requiring no architecture modification or parameter updates after source-domain training.
Text Steganography with Dynamic Codebook and Multimodal Large Language Model
Apr 22, 2026With the popularity of the large language models (LLMs), text steganography has achieved remarkable performance. However, existing methods still have some issues: (1) For the white-box paradigm, this steganography behavior is prone to exposure due to sharing the off-the-shelf language model between Alice and Bob.(2) For the black-box paradigm, these methods lack flexibility and practicality since Alice and Bob should share the fixed codebook while sharing a specific extracting prompt for each steganographic sentence. In order to improve the security and practicality, we introduce a black-box text steganography with a dynamic codebook and multimodal large language model. Specifically, we first construct a dynamic codebook via some shared session configuration and a multimodal large language model. Then an encrypted steganographic mapping is designed to embed secret messages during the steganographic caption generation. Furthermore, we introduce a feedback optimization mechanism based on reject sampling to ensure accurate extraction of secret messages. Experimental results show that the proposed method outperforms existing white-box text steganography methods in terms of embedding capacity and text quality. Meanwhile, the proposed method has achieved better practicality and flexibility than the existing black-box paradigm in some popular online social networks.
Few-Shot Medical Image Segmentation with High-Fidelity Prototypes
Jun 26, 2024



Few-shot Semantic Segmentation (FSS) aims to adapt a pretrained model to new classes with as few as a single labelled training sample per class. Despite the prototype based approaches have achieved substantial success, existing models are limited to the imaging scenarios with considerably distinct objects and not highly complex background, e.g., natural images. This makes such models suboptimal for medical imaging with both conditions invalid. To address this problem, we propose a novel Detail Self-refined Prototype Network (DSPNet) to constructing high-fidelity prototypes representing the object foreground and the background more comprehensively. Specifically, to construct global semantics while maintaining the captured detail semantics, we learn the foreground prototypes by modelling the multi-modal structures with clustering and then fusing each in a channel-wise manner. Considering that the background often has no apparent semantic relation in the spatial dimensions, we integrate channel-specific structural information under sparse channel-aware regulation. Extensive experiments on three challenging medical image benchmarks show the superiority of DSPNet over previous state-of-the-art methods.
Deep Learning for Needle Detection in a Cannulation Simulator
May 05, 2021

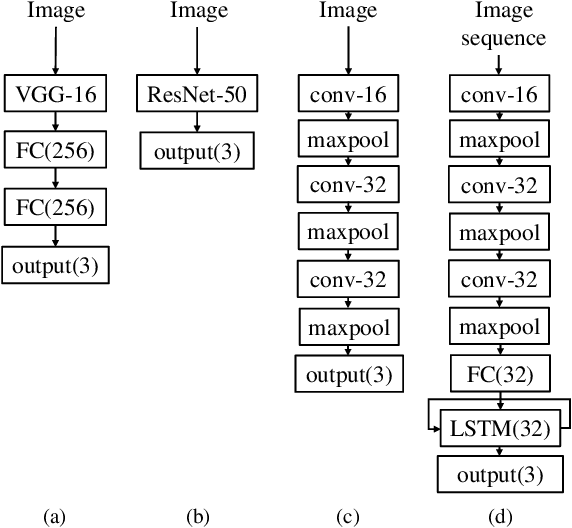
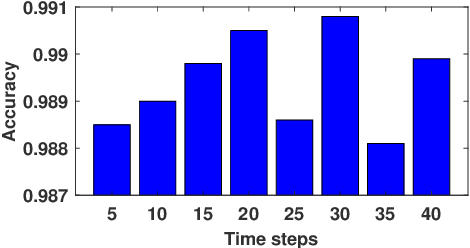
Cannulation for hemodialysis is the act of inserting a needle into a surgically created vascular access (e.g., an arteriovenous fistula) for the purpose of dialysis. The main risk associated with cannulation is infiltration, the puncture of the wall of the vascular access after entry, which can cause medical complications. Simulator-based training allows clinicians to gain cannulation experience without putting patients at risk. In this paper, we propose to use deep-learning-based techniques for detecting, based on video, whether the needle tip is in or has infiltrated the simulated fistula. Three categories of deep neural networks are investigated in this work: modified pre-trained models based on VGG-16 and ResNet-50, light convolutional neural networks (light CNNs), and convolutional recurrent neural networks (CRNNs). CRNNs consist of convolutional layers and a long short-term memory (LSTM) layer. A data set of cannulation experiments was collected and analyzed. The results show that both the light CNN and the CRNN achieve better performance than the pre-trained baseline models. The CRNN was implemented in real time on commodity hardware for use in the cannulation simulator, and the performance was verified. Deep-learning video analysis is a viable method for detecting needle state in a low cost cannulation simulator. Our data sets and code are released at https://github.com/axin233/DL_for_Needle_Detection_Cannulation