 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-Invariant Localization using Semantic Objects in Changing Environments
Sep 28, 2022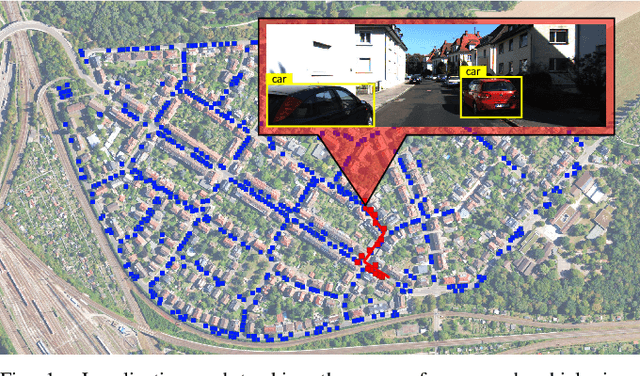
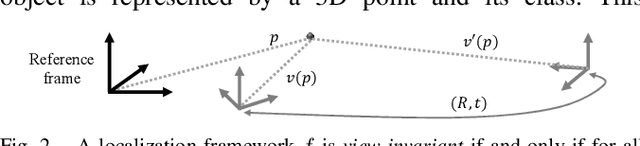
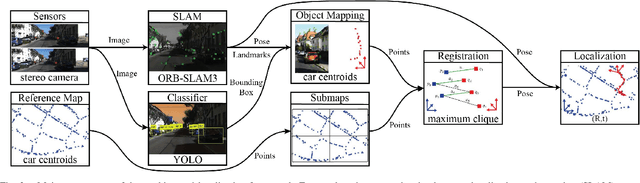
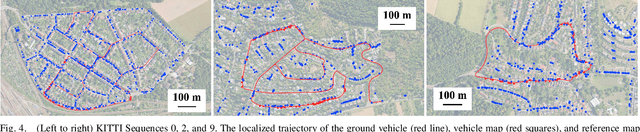
This paper proposes a novel framework for real-time localization and egomotion tracking of a vehicle in a reference map. The core idea is to map the semantic objects observed by the vehicle and register them to their corresponding objects in the reference map. While several recent works have leveraged semantic information for cross-view localization, the main contribution of this work is a view-invariant formulation that makes the approach directly applicable to any viewpoint configuration for which objects are detectable. Another distinctive feature is robustness to changes in the environment/objects due to a data association scheme suited for extreme outlier regimes (e.g., 90% association outliers). To demonstrate our framework, we consider an example of localizing a ground vehicle in a reference object map using only cars as objects. While only a stereo camera is used for the ground vehicle, we consider reference maps constructed a priori from ground viewpoints using stereo cameras and Lidar scans, and georeferenced aerial images captured at a different date to demonstrate the framework's robustness to different modalities, viewpoints, and environment changes. Evaluations on the KITTI dataset show that over a 3.7 km trajectory, localization occurs in 36 sec and is followed by real-time egomotion tracking with an average position error of 8.5 m in a Lidar reference map, and on an aerial object map where 77% of objects are outliers, localization is achieved in 71 sec with an average position error of 7.9 m.
Backward Reachability Analysis of Neural Feedback Loops: Techniques for Linear and Nonlinear Systems
Sep 28, 2022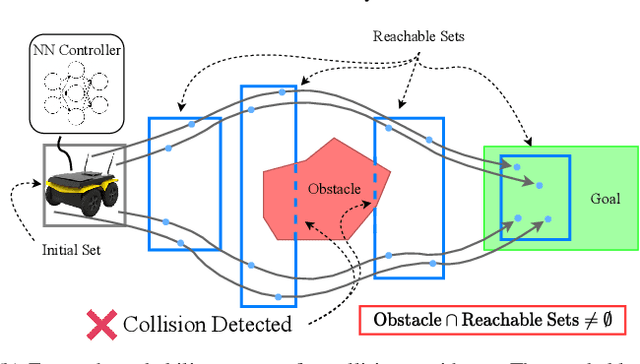

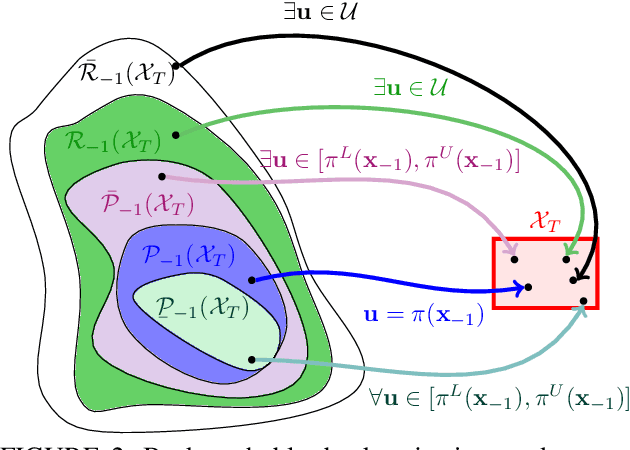

The increasing prevalence of neural networks (NNs) in safety-critical applications calls for methods to certify safe behavior. This paper presents a backward reachability approach for safety verification of neural feedback loops (NFLs), i.e., closed-loop systems with NN control policies. While recent works have focused on forward reachability as a strategy for safety certification of NFLs, backward reachability offers advantages over the forward strategy, particularly in obstacle avoidance scenarios. Prior works have developed techniques for backward reachability analysis for systems without NNs, but the presence of NNs in the feedback loop presents a unique set of problems due to the nonlinearities in their activation functions and because NN models are generally not invertible. To overcome these challenges, we use existing forward NN analysis tools to efficiently find an over-approximation of the backprojection (BP) set, i.e., the set of states for which the NN control policy will drive the system to a given target set. We present frameworks for calculating BP over-approximations for both linear and nonlinear systems with control policies represented by feedforward NNs and propose computationally efficient strategies. We use numerical results from a variety of models to showcase the proposed algorithms, including a demonstration of safety certification for a 6D system.
Robust, High-Rate Trajectory Tracking on Insect-Scale Soft-Actuated Aerial Robots with Deep-Learned Tube MPC
Sep 26, 2022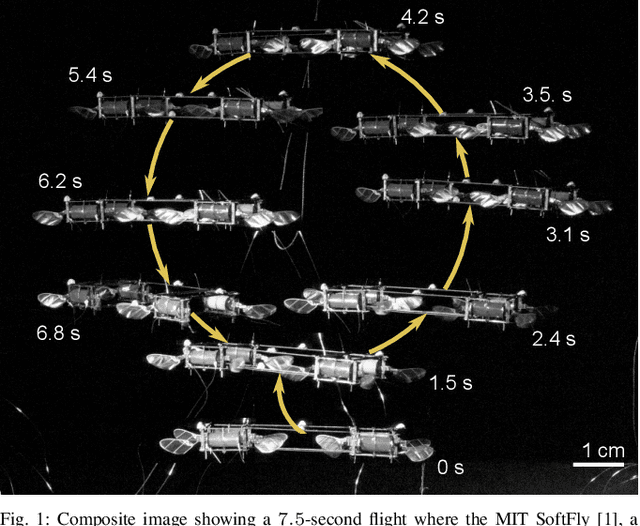
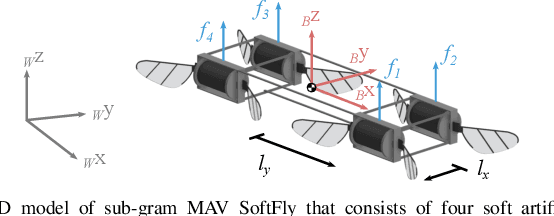
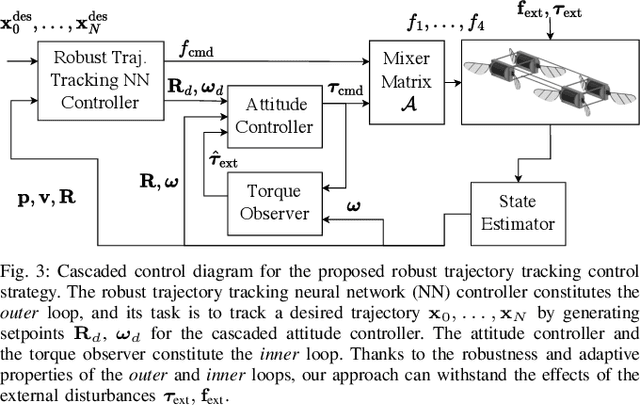
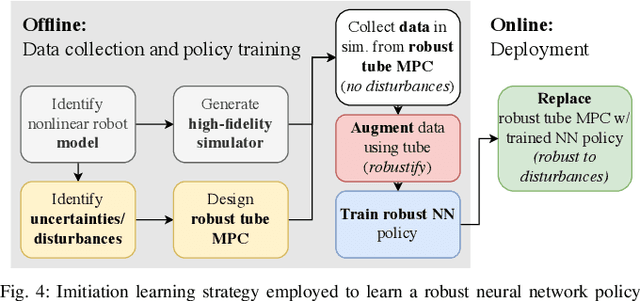
Accurate and agile trajectory tracking in sub-gram Micro Aerial Vehicles (MAVs) is challenging, as the small scale of the robot induces large model uncertainties, demanding robust feedback controllers, while the fast dynamics and computational constraints prevent the deployment of computationally expensive strategies. In this work, we present an approach for agile and computationally efficient trajectory tracking on the MIT SoftFly, a sub-gram MAV (0.7 grams). Our strategy employs a cascaded control scheme, where an adaptive attitude controller is combined with a neural network policy trained to imitate a trajectory tracking robust tube model predictive controller (RTMPC). The neural network policy is obtained using our recent work, which enables the policy to preserve the robustness of RTMPC, but at a fraction of its computational cost. We experimentally evaluate our approach, achieving position Root Mean Square Errors lower than 1.8 cm even in the more challenging maneuvers, obtaining a 60% reduction in maximum position error compared to our previous work, and demonstrating robustness to large external disturbances
Wide-Area Geolocalization with a Limited Field of View Camera
Sep 23, 2022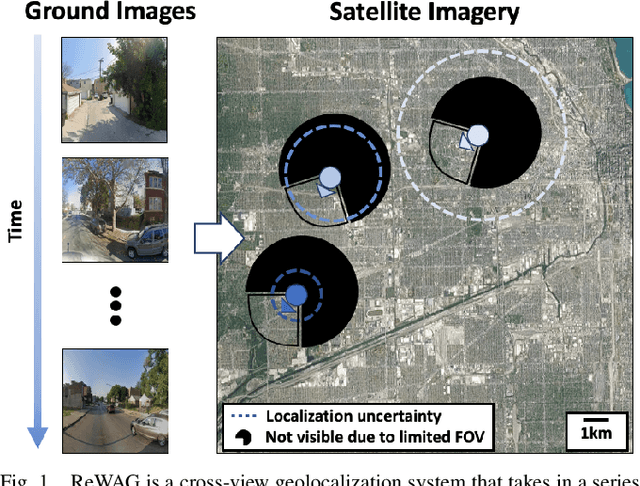

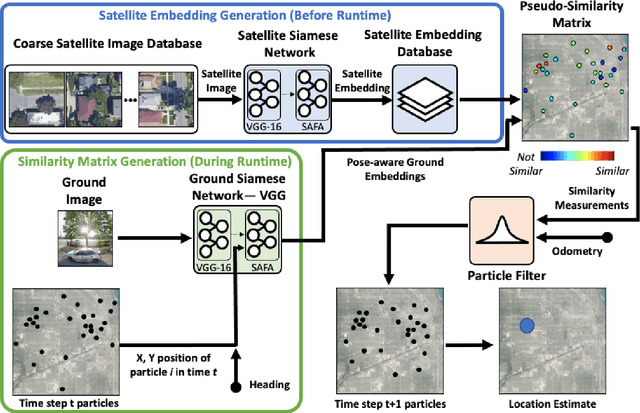
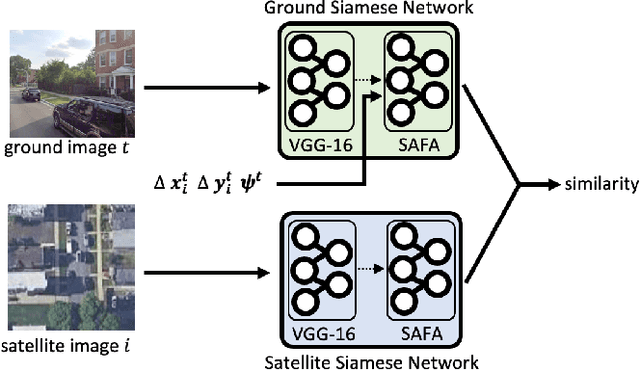
Cross-view geolocalization, a supplement or replacement for GPS, localizes an agent within a search area by matching images taken from a ground-view camera to overhead images taken from satellites or aircraft. Although the viewpoint disparity between ground and overhead images makes cross-view geolocalization challenging, significant progress has been made assuming that the ground agent has access to a panoramic camera. For example, our prior work (WAG) introduced changes in search area discretization, training loss, and particle filter weighting that enabled city-scale panoramic cross-view geolocalization. However, panoramic cameras are not widely used in existing robotic platforms due to their complexity and cost. Non-panoramic cross-view geolocalization is more applicable for robotics, but is also more challenging. This paper presents Restricted FOV Wide-Area Geolocalization (ReWAG), a cross-view geolocalization approach that generalizes WAG for use with standard, non-panoramic ground cameras by creating pose-aware embeddings and providing a strategy to incorporate particle pose into the Siamese network. ReWAG is a neural network and particle filter system that is able to globally localize a mobile agent in a GPS-denied environment with only odometry and a 90 degree FOV camera, achieving similar localization accuracy as what WAG achieved with a panoramic camera and improving localization accuracy by a factor of 100 compared to a baseline vision transformer (ViT) approach. A video highlight that demonstrates ReWAG's convergence on a test path of several dozen kilometers is available at https://youtu.be/U_OBQrt8qCE.
Deep-PANTHER: Learning-Based Perception-Aware Trajectory Planner in Dynamic Environments
Sep 02, 2022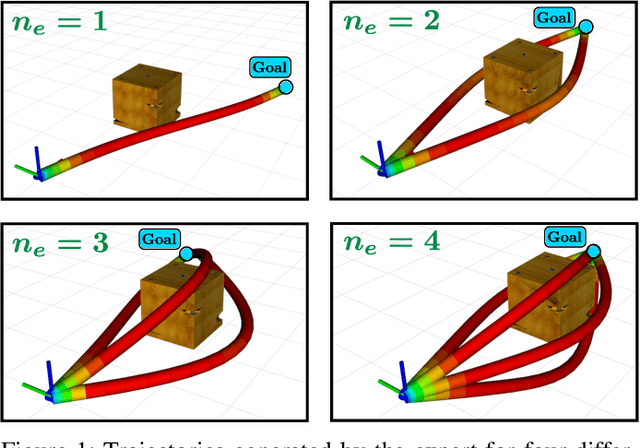
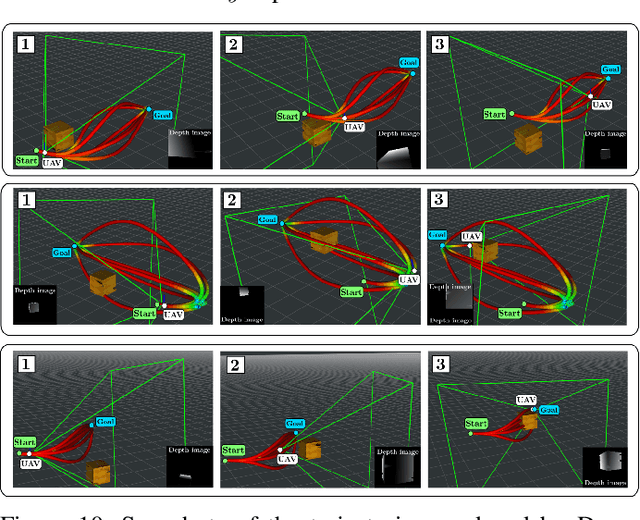
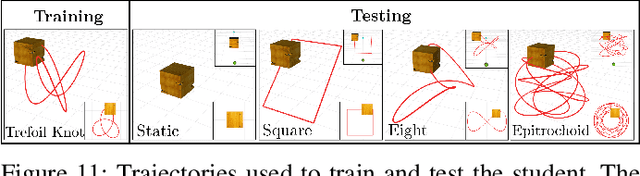
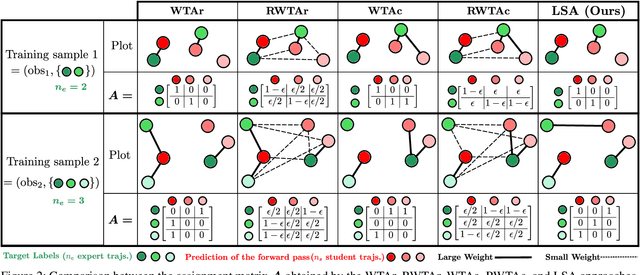
This paper presents Deep-PANTHER, a learning-based perception-aware trajectory planner for unmanned aerial vehicles (UAVs) in dynamic environments. Given the current state of the UAV, and the predicted trajectory and size of the obstacle, Deep-PANTHER generates multiple trajectories to avoid a dynamic obstacle while simultaneously maximizing its presence in the field of view (FOV) of the onboard camera. To obtain a computationally tractable real-time solution, imitation learning is leveraged to train a Deep-PANTHER policy using demonstrations provided by a multimodal optimization-based expert. Extensive simulations show replanning times that are two orders of magnitude faster than the optimization-based expert, while achieving a similar cost. By ensuring that each expert trajectory is assigned to one distinct student trajectory in the loss function, Deep-PANTHER can also capture the multimodality of the problem and achieve a mean squared error (MSE) loss with respect to the expert that is up to 18 times smaller than state-of-the-art (Relaxed) Winner-Takes-All approaches. Deep-PANTHER is also shown to generalize well to obstacle trajectories that differ from the ones used in training.
Energy-Aware, Collision-Free Information Gathering for Heterogeneous Robot Teams
Jul 30, 2022
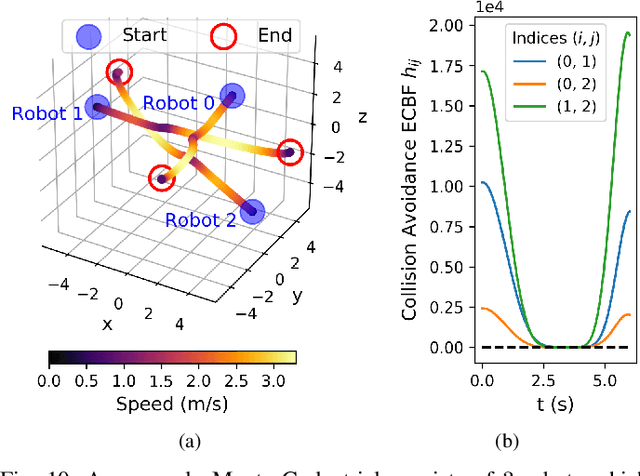
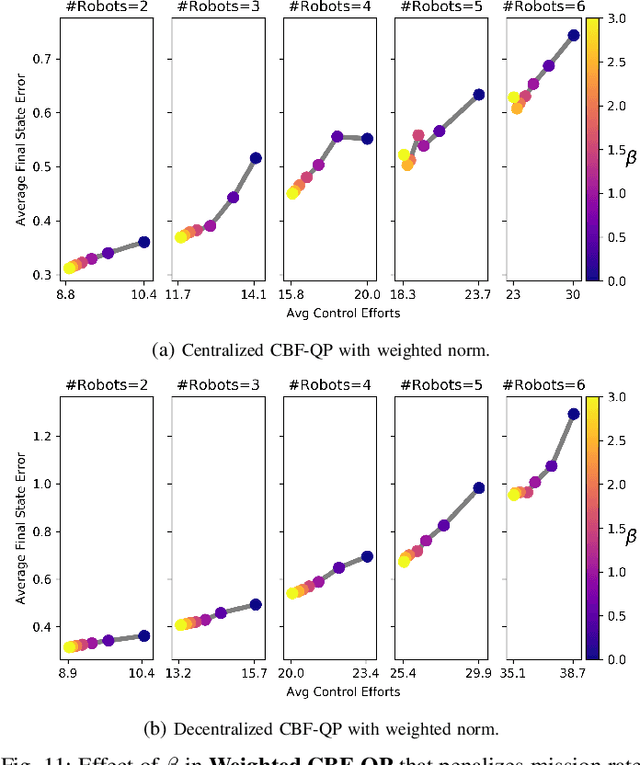
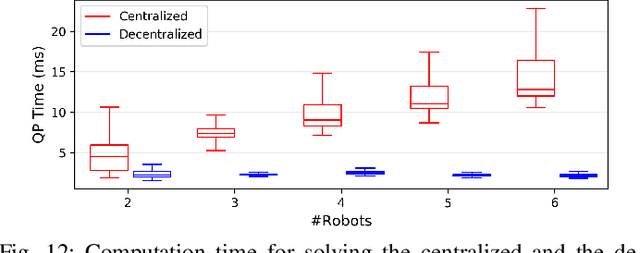
This paper considers the problem of safely coordinating a team of sensor-equipped robots to reduce uncertainty about a dynamical process, where the objective trades off information gain and energy cost. Optimizing this trade-off is desirable, but leads to a non-monotone objective function in the set of robot trajectories. Therefore, common multi-robot planners based on coordinate descent lose their performance guarantees. Furthermore, methods that handle non-monotonicity lose their performance guarantees when subject to inter-robot collision avoidance constraints. As it is desirable to retain both the performance guarantee and safety guarantee, this work proposes a hierarchical approach with a distributed planner that uses local search with a worst-case performance guarantees and a decentralized controller based on control barrier functions that ensures safety and encourages timely arrival at sensing locations. Via extensive simulations, hardware-in-the-loop tests and hardware experiments, we demonstrate that the proposed approach achieves a better trade-off between sensing and energy cost than coordinate descent based algorithms.
Global Data Association for SLAM with 3D Grassmannian Manifold Objects
May 17, 2022

Using pole and plane objects in lidar SLAM can increase accuracy and decrease map storage requirements compared to commonly-used point cloud maps. However, place recognition and geometric verification using these landmarks is challenging due to the requirement for global matching without an initial guess. Existing works typically only leverage either pole or plane landmarks, limiting application to a restricted set of environments. We present a global data association method for loop closure in lidar scans using 3D line and plane objects simultaneously and in a unified manner. The main novelty of this paper is in the representation of line and plane objects extracted from lidar scans on the manifold of affine subspaces, known as the affine Grassmannian. Line and plane correspondences are matched using our graph-based data association framework and subsequently registered in the least-squares sense. Compared to pole-only approaches and plane-only approaches, our 3D affine Grassmannian method yields a 71% and 325% increase respectively to loop closure recall at 100% precision on the KITTI dataset and can provide frame alignment with less than 10 cm and 1 deg of error.
Backward Reachability Analysis for Neural Feedback Loops
Apr 14, 2022
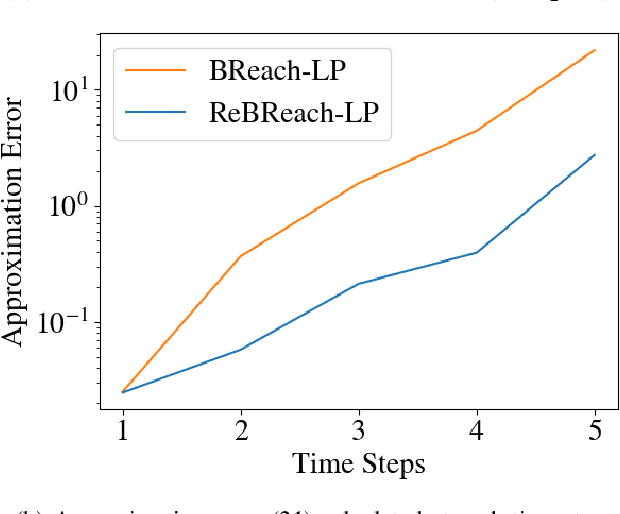
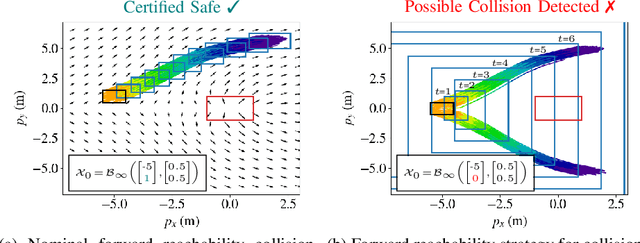
The increasing prevalence of neural networks (NNs) in safety-critical applications calls for methods to certify their behavior and guarantee safety. This paper presents a backward reachability approach for safety verification of neural feedback loops (NFLs), i.e., closed-loop systems with NN control policies. While recent works have focused on forward reachability as a strategy for safety certification of NFLs, backward reachability offers advantages over the forward strategy, particularly in obstacle avoidance scenarios. Prior works have developed techniques for backward reachability analysis for systems without NNs, but the presence of NNs in the feedback loop presents a unique set of problems due to the nonlinearities in their activation functions and because NN models are generally not invertible. To overcome these challenges, we use existing forward NN analysis tools to find affine bounds on the control inputs and solve a series of linear programs (LPs) to efficiently find an approximation of the backprojection (BP) set, i.e., the set of states for which the NN control policy will drive the system to a given target set. We present an algorithm to iteratively find BP set estimates over a given time horizon and demonstrate the ability to reduce conservativeness in the BP set estimates by up to 88% with low additional computational cost. We use numerical results from a double integrator model to verify the efficacy of these algorithms and demonstrate the ability to certify safety for a linearized ground robot model in a collision avoidance scenario where forward reachability fails.
Distributed Filtering with Value of Information Censoring
Apr 01, 2022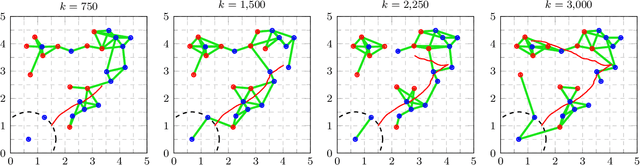
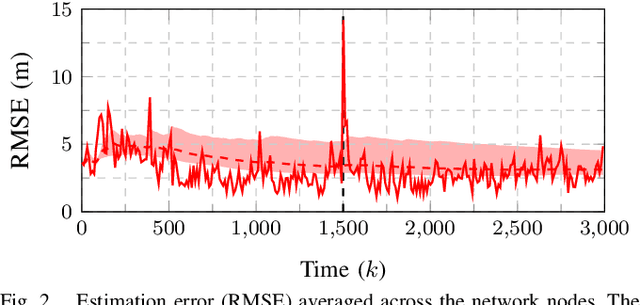
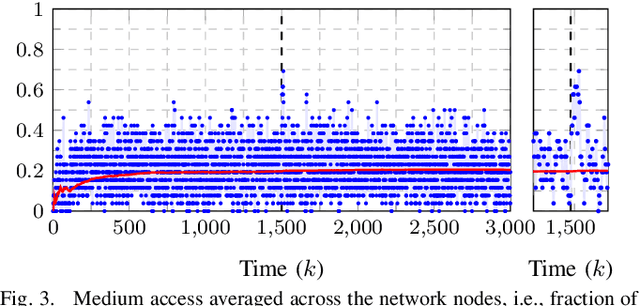
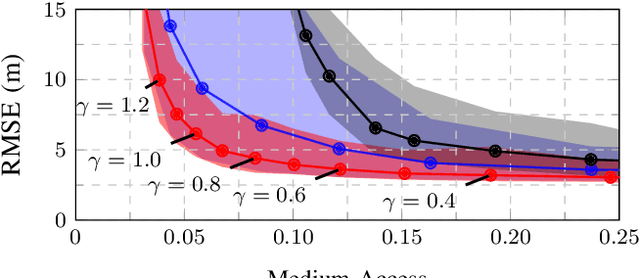
This work presents a distributed estimation algorithm that efficiently uses the available communication resources. The approach is based on Bayesian filtering that is distributed across a network by using the logarithmic opinion pool operator. Communication efficiency is achieved by having only agents with high Value of Information (VoI) share their estimates, and the algorithm provides a tunable trade-off between communication resources and estimation error. Under linear-Gaussian models the algorithm takes the form of a censored distributed Information filter, which guarantees the consistency of agent estimates. Importantly, consistent estimates are shown to play a crucial role in enabling the large reductions in communication usage provided by the VoI censoring approach. We verify the performance of the proposed method via complex simulations in a dynamic network topology and by experimental validation over a real ad-hoc wireless communication network. The results show the validity of using the proposed method to drastically reduce the communication costs of distributed estimation tasks.
Risk-Aware Off-Road Navigation via a Learned Speed Distribution Map
Mar 25, 2022
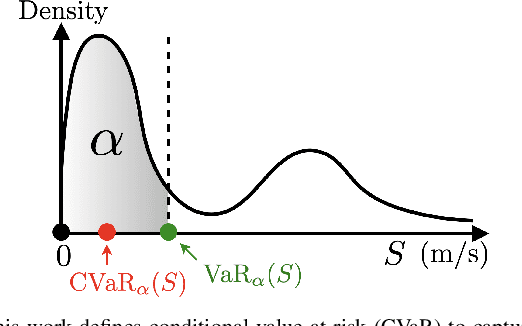
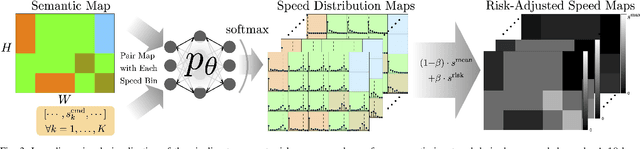
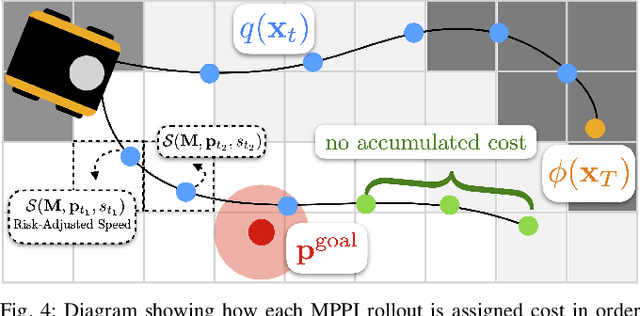
Motion planning in off-road environments requires reasoning about both the geometry and semantics of the scene (e.g., a robot may be able to drive through soft bushes but not a fallen log). In many recent works, the world is classified into a finite number of semantic categories that often are not sufficient to capture the ability (i.e., the speed) with which a robot can traverse off-road terrain. Instead, this work proposes a new representation of traversability based exclusively on robot speed that can be learned from data, offers interpretability and intuitive tuning, and can be easily integrated with a variety of planning paradigms in the form of a costmap. Specifically, given a dataset of experienced trajectories, the proposed algorithm learns to predict a distribution of speeds the robot could achieve, conditioned on the environment semantics and commanded speed. The learned speed distribution map is converted into costmaps with a risk-aware cost term based on conditional value at risk (CVaR). Numerical simulations demonstrate that the proposed risk-aware planning algorithm leads to faster average time-to-goals compared to a method that only considers expected behavior, and the planner can be tuned for slightly slower, but less variable behavior. Furthermore, the approach is integrated into a full autonomy stack and demonstrated in a high-fidelity Unity environment and is shown to provide a 30\% improvement in the success rate of navigation.