 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObserve and Look Further: Achieving Consistent Performance on Atari
May 29, 2018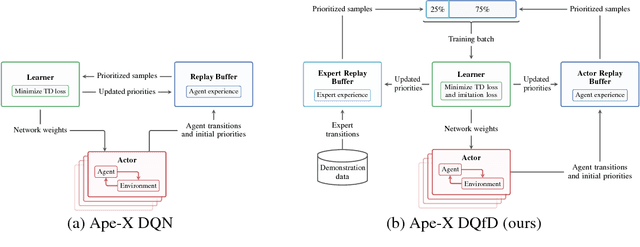
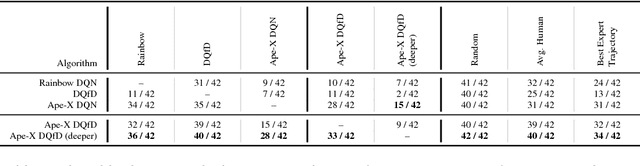
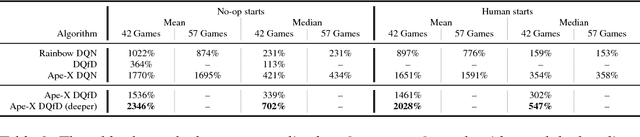
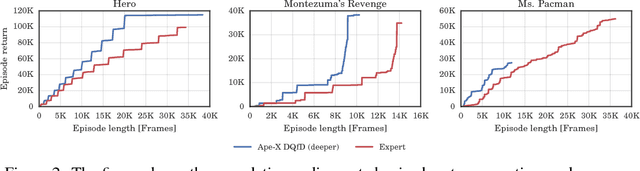
Despite significant advances in the field of deep Reinforcement Learning (RL), today's algorithms still fail to learn human-level policies consistently over a set of diverse tasks such as Atari 2600 games. We identify three key challenges that any algorithm needs to master in order to perform well on all games: processing diverse reward distributions, reasoning over long time horizons, and exploring efficiently. In this paper, we propose an algorithm that addresses each of these challenges and is able to learn human-level policies on nearly all Atari games. A new transformed Bellman operator allows our algorithm to process rewards of varying densities and scales; an auxiliary temporal consistency loss allows us to train stably using a discount factor of $\gamma = 0.999$ (instead of $\gamma = 0.99$) extending the effective planning horizon by an order of magnitude; and we ease the exploration problem by using human demonstrations that guide the agent towards rewarding states. When tested on a set of 42 Atari games, our algorithm exceeds the performance of an average human on 40 games using a common set of hyper parameters. Furthermore, it is the first deep RL algorithm to solve the first level of Montezuma's Revenge.
Distributed Prioritized Experience Replay
Mar 02, 2018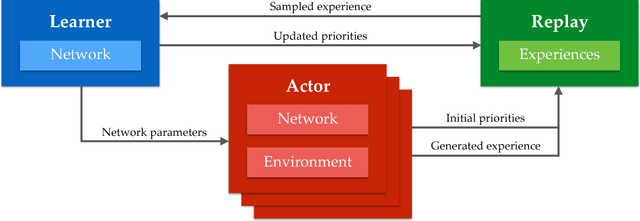
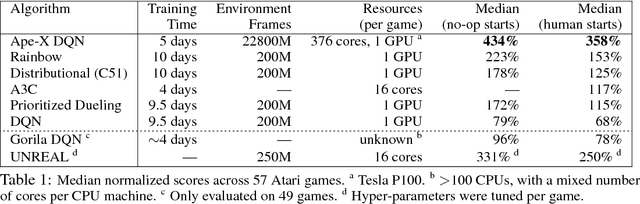
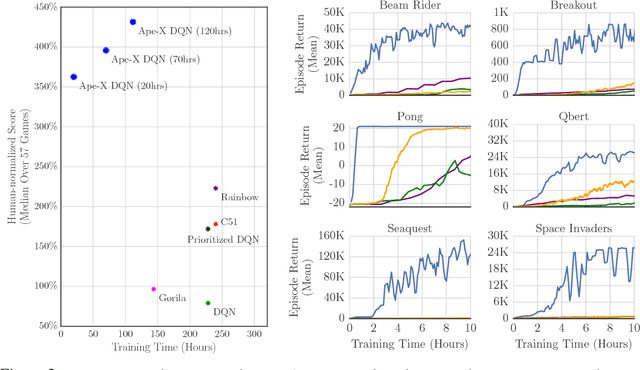
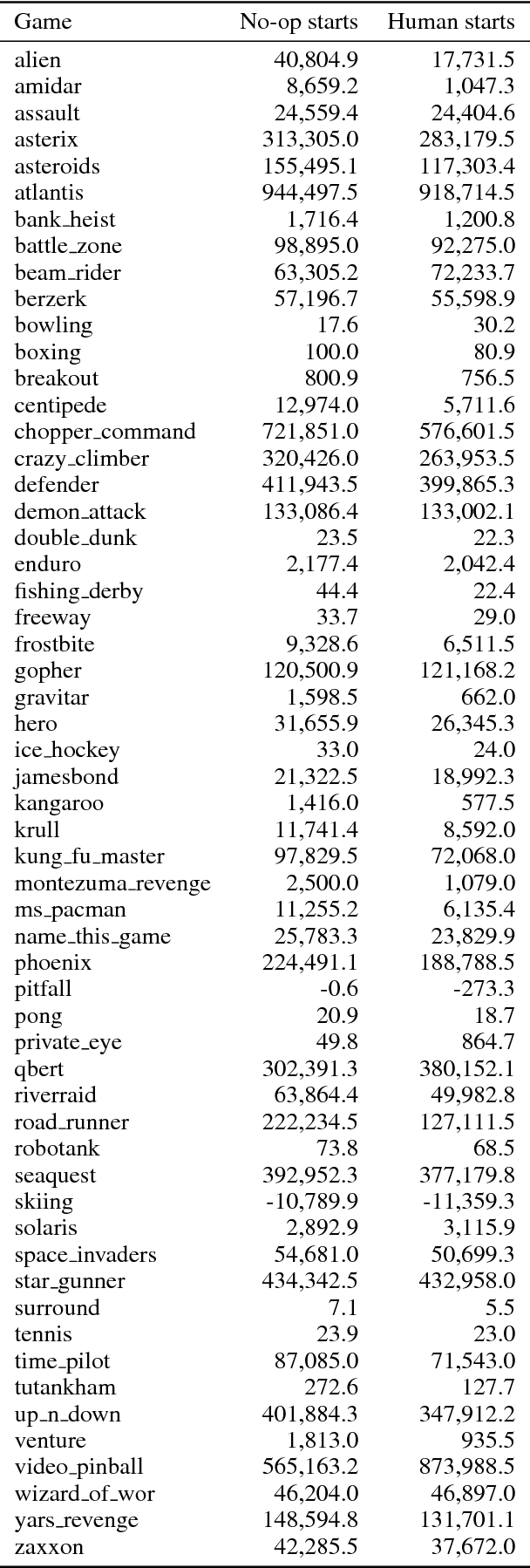
We propose a distributed architecture for deep reinforcement learning at scale, that enables agents to learn effectively from orders of magnitude more data than previously possible. The algorithm decouples acting from learning: the actors interact with their own instances of the environment by selecting actions according to a shared neural network, and accumulate the resulting experience in a shared experience replay memory; the learner replays samples of experience and updates the neural network. The architecture relies on prioritized experience replay to focus only on the most significant data generated by the actors. Our architecture substantially improves the state of the art on the Arcade Learning Environment, achieving better final performance in a fraction of the wall-clock training time.
Deep Q-learning from Demonstrations
Nov 22, 2017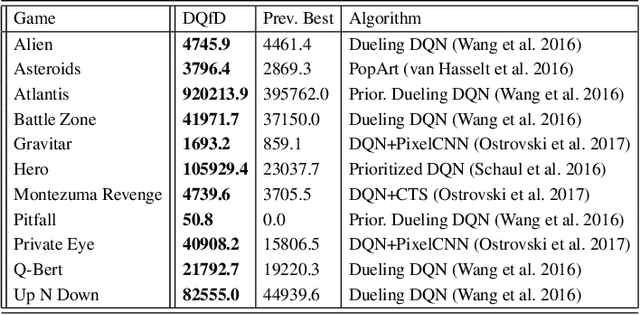
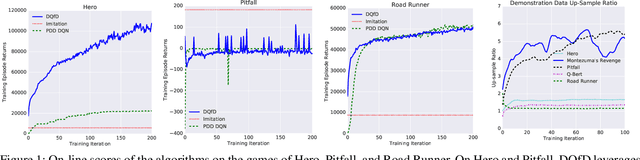
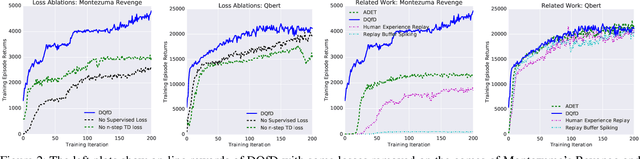
Deep reinforcement learning (RL) has achieved several high profile successes in difficult decision-making problems. However, these algorithms typically require a huge amount of data before they reach reasonable performance. In fact, their performance during learning can be extremely poor. This may be acceptable for a simulator, but it severely limits the applicability of deep RL to many real-world tasks, where the agent must learn in the real environment. In this paper we study a setting where the agent may access data from previous control of the system. We present an algorithm, Deep Q-learning from Demonstrations (DQfD), that leverages small sets of demonstration data to massively accelerate the learning process even from relatively small amounts of demonstration data and is able to automatically assess the necessary ratio of demonstration data while learning thanks to a prioritized replay mechanism. DQfD works by combining temporal difference updates with supervised classification of the demonstrator's actions. We show that DQfD has better initial performance than Prioritized Dueling Double Deep Q-Networks (PDD DQN) as it starts with better scores on the first million steps on 41 of 42 games and on average it takes PDD DQN 83 million steps to catch up to DQfD's performance. DQfD learns to out-perform the best demonstration given in 14 of 42 games. In addition, DQfD leverages human demonstrations to achieve state-of-the-art results for 11 games. Finally, we show that DQfD performs better than three related algorithms for incorporating demonstration data into DQN.
StarCraft II: A New Challenge for Reinforcement Learning
Aug 16, 2017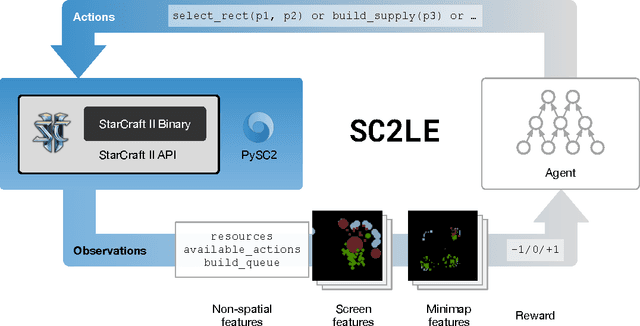
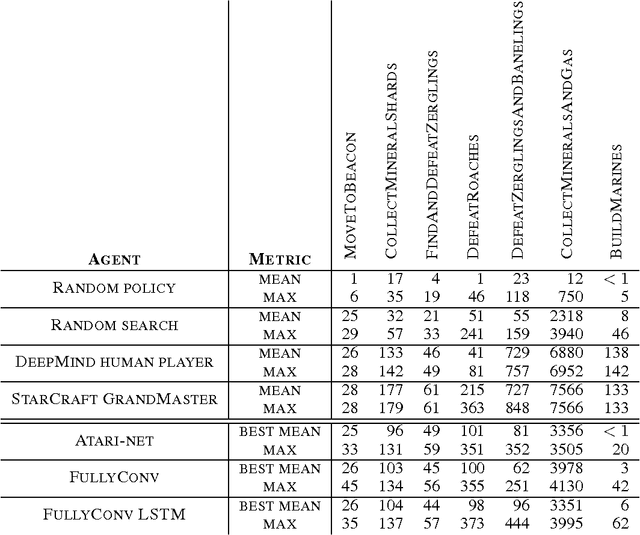

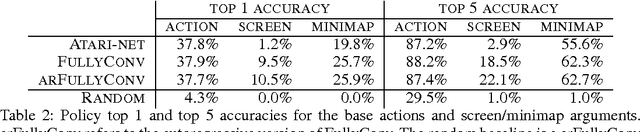
This paper introduces SC2LE (StarCraft II Learning Environment), a reinforcement learning environment based on the StarCraft II game. This domain poses a new grand challenge for reinforcement learning, representing a more difficult class of problems than considered in most prior work. It is a multi-agent problem with multiple players interacting; there is imperfect information due to a partially observed map; it has a large action space involving the selection and control of hundreds of units; it has a large state space that must be observed solely from raw input feature planes; and it has delayed credit assignment requiring long-term strategies over thousands of steps. We describe the observation, action, and reward specification for the StarCraft II domain and provide an open source Python-based interface for communicating with the game engine. In addition to the main game maps, we provide a suite of mini-games focusing on different elements of StarCraft II gameplay. For the main game maps, we also provide an accompanying dataset of game replay data from human expert players. We give initial baseline results for neural networks trained from this data to predict game outcomes and player actions. Finally, we present initial baseline results for canonical deep reinforcement learning agents applied to the StarCraft II domain. On the mini-games, these agents learn to achieve a level of play that is comparable to a novice player. However, when trained on the main game, these agents are unable to make significant progress. Thus, SC2LE offers a new and challenging environment for exploring deep reinforcement learning algorithms and architectures.
Distral: Robust Multitask Reinforcement Learning
Jul 13, 2017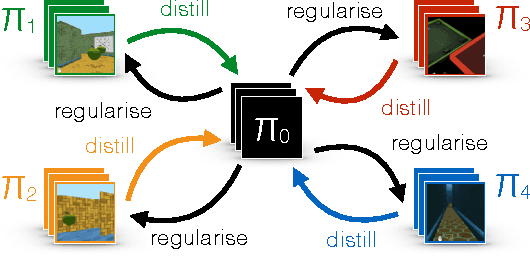

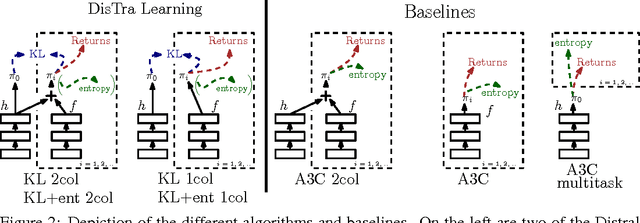
Most deep reinforcement learning algorithms are data inefficient in complex and rich environments, limiting their applicability to many scenarios. One direction for improving data efficiency is multitask learning with shared neural network parameters, where efficiency may be improved through transfer across related tasks. In practice, however, this is not usually observed, because gradients from different tasks can interfere negatively, making learning unstable and sometimes even less data efficient. Another issue is the different reward schemes between tasks, which can easily lead to one task dominating the learning of a shared model. We propose a new approach for joint training of multiple tasks, which we refer to as Distral (Distill & transfer learning). Instead of sharing parameters between the different workers, we propose to share a "distilled" policy that captures common behaviour across tasks. Each worker is trained to solve its own task while constrained to stay close to the shared policy, while the shared policy is trained by distillation to be the centroid of all task policies. Both aspects of the learning process are derived by optimizing a joint objective function. We show that our approach supports efficient transfer on complex 3D environments, outperforming several related methods. Moreover, the proposed learning process is more robust and more stable---attributes that are critical in deep reinforcement learning.
Overcoming catastrophic forgetting in neural networks
Jan 25, 2017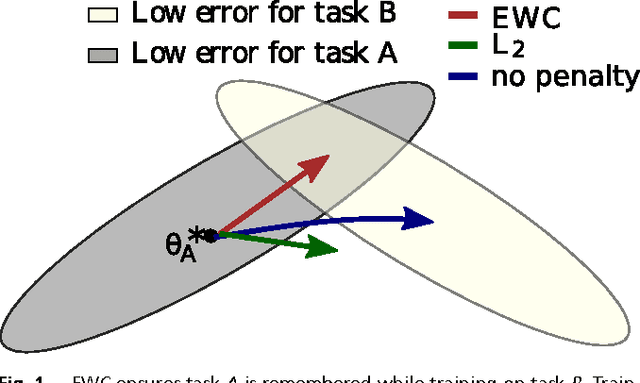
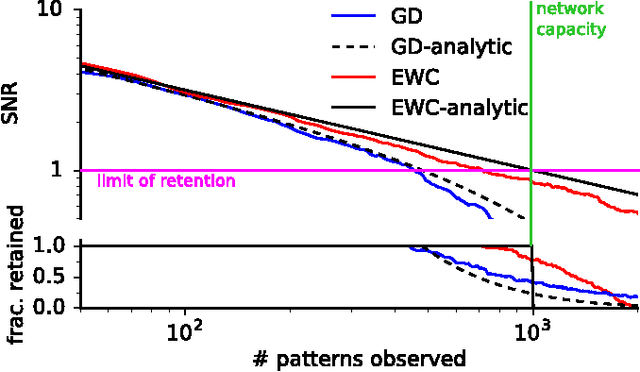
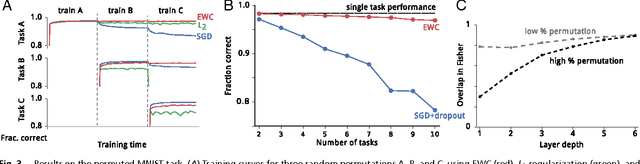
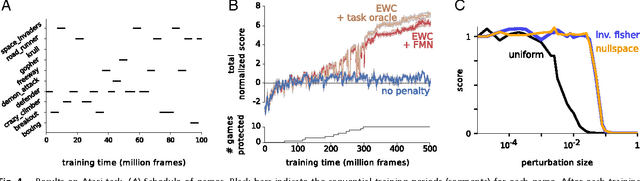
The ability to learn tasks in a sequential fashion is crucial to the development of artificial intelligence. Neural networks are not, in general, capable of this and it has been widely thought that catastrophic forgetting is an inevitable feature of connectionist models. We show that it is possible to overcome this limitation and train networks that can maintain expertise on tasks which they have not experienced for a long time. Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks. We demonstrate our approach is scalable and effective by solving a set of classification tasks based on the MNIST hand written digit dataset and by learning several Atari 2600 games sequentially.
Prioritized Experience Replay
Feb 25, 2016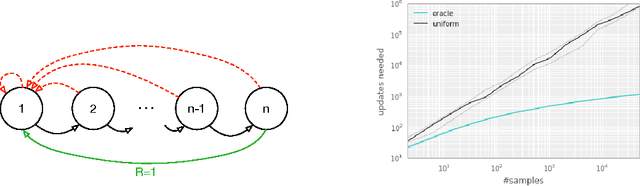
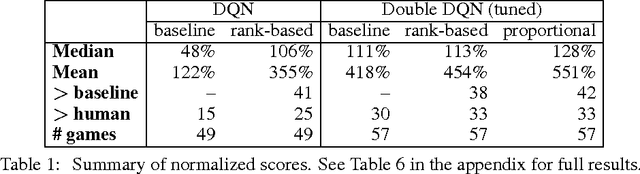
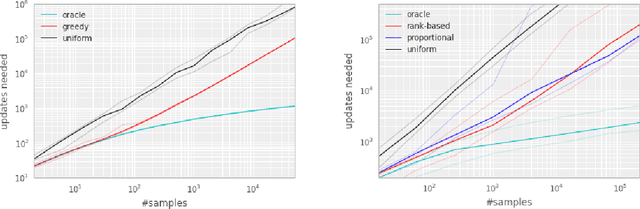

Experience replay lets online reinforcement learning agents remember and reuse experiences from the past. In prior work, experience transitions were uniformly sampled from a replay memory. However, this approach simply replays transitions at the same frequency that they were originally experienced, regardless of their significance. In this paper we develop a framework for prioritizing experience, so as to replay important transitions more frequently, and therefore learn more efficiently. We use prioritized experience replay in Deep Q-Networks (DQN), a reinforcement learning algorithm that achieved human-level performance across many Atari games. DQN with prioritized experience replay achieves a new state-of-the-art, outperforming DQN with uniform replay on 41 out of 49 games.