 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Protein Transfer Learning with TAPE
Jun 19, 2019
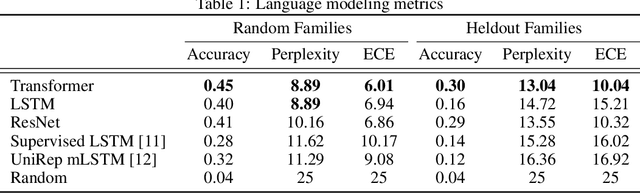
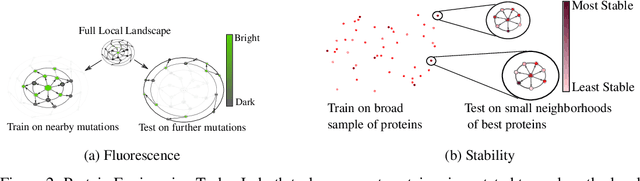
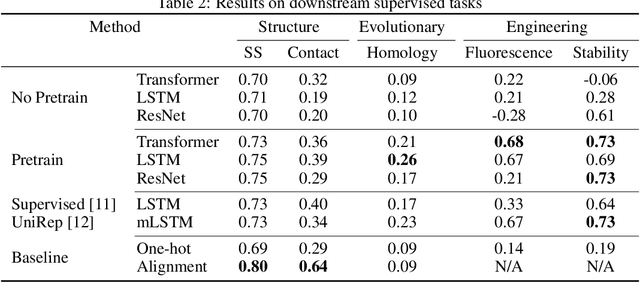
Protein modeling is an increasingly popular area of machine learning research. Semi-supervised learning has emerged as an important paradigm in protein modeling due to the high cost of acquiring supervised protein labels, but the current literature is fragmented when it comes to datasets and standardized evaluation techniques. To facilitate progress in this field, we introduce the Tasks Assessing Protein Embeddings (TAPE), a set of five biologically relevant semi-supervised learning tasks spread across different domains of protein biology. We curate tasks into specific training, validation, and test splits to ensure that each task tests biologically relevant generalization that transfers to real-life scenarios. We benchmark a range of approaches to semi-supervised protein representation learning, which span recent work as well as canonical sequence learning techniques. We find that self-supervised pretraining is helpful for almost all models on all tasks, more than doubling performance in some cases. Despite this increase, in several cases features learned by self-supervised pretraining still lag behind features extracted by state-of-the-art non-neural techniques. This gap in performance suggests a huge opportunity for innovative architecture design and improved modeling paradigms that better capture the signal in biological sequences. TAPE will help the machine learning community focus effort on scientifically relevant problems. Toward this end, all data and code used to run these experiments are available at https://github.com/songlab-cal/tape.
Risk Averse Robust Adversarial Reinforcement Learning
Mar 31, 2019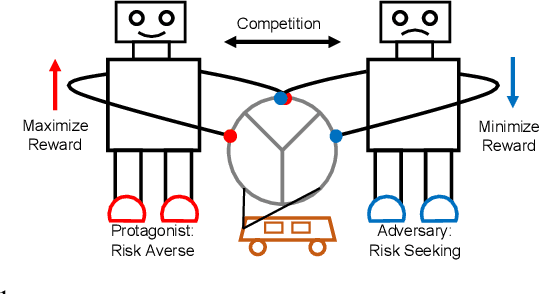
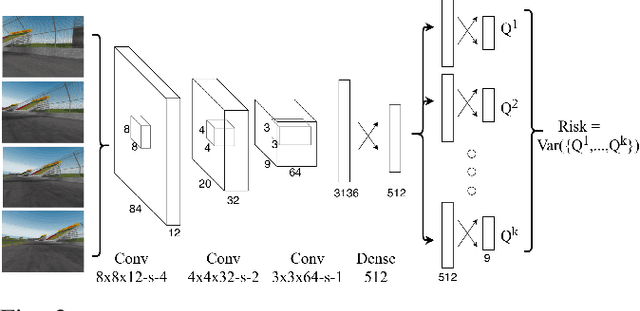
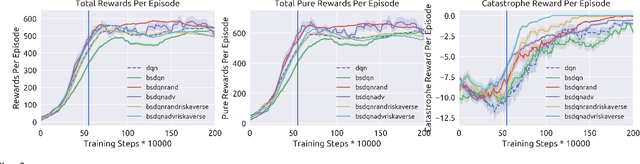
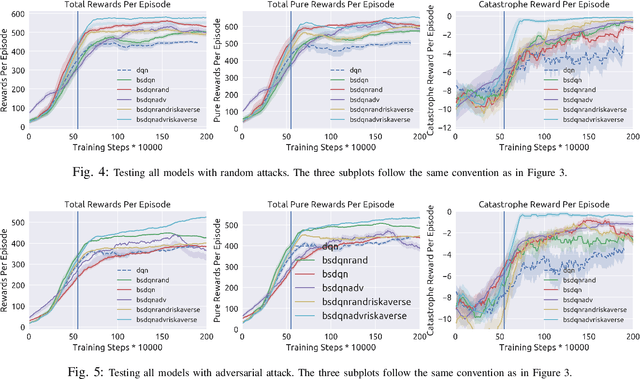
Deep reinforcement learning has recently made significant progress in solving computer games and robotic control tasks. A known problem, though, is that policies overfit to the training environment and may not avoid rare, catastrophic events such as automotive accidents. A classical technique for improving the robustness of reinforcement learning algorithms is to train on a set of randomized environments, but this approach only guards against common situations. Recently, robust adversarial reinforcement learning (RARL) was developed, which allows efficient applications of random and systematic perturbations by a trained adversary. A limitation of RARL is that only the expected control objective is optimized; there is no explicit modeling or optimization of risk. Thus the agents do not consider the probability of catastrophic events (i.e., those inducing abnormally large negative reward), except through their effect on the expected objective. In this paper we introduce risk-averse robust adversarial reinforcement learning (RARARL), using a risk-averse protagonist and a risk-seeking adversary. We test our approach on a self-driving vehicle controller. We use an ensemble of policy networks to model risk as the variance of value functions. We show through experiments that a risk-averse agent is better equipped to handle a risk-seeking adversary, and experiences substantially fewer crashes compared to agents trained without an adversary.
Periphery-Fovea Multi-Resolution Driving Model guided by Human Attention
Mar 24, 2019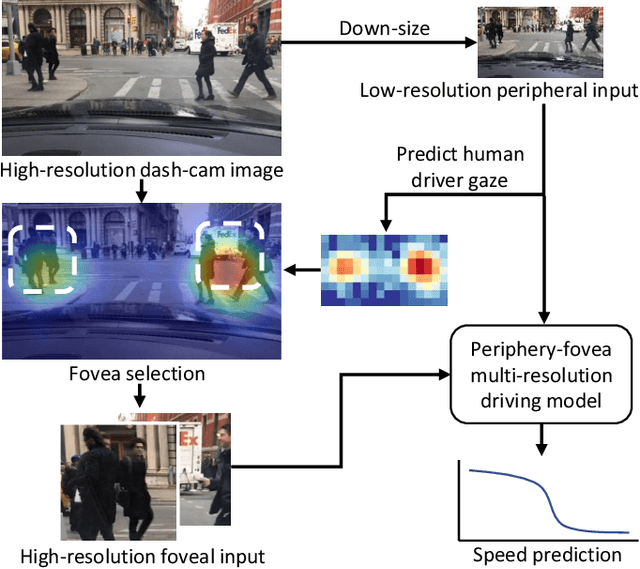

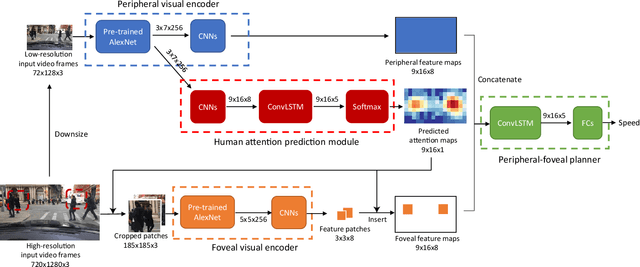
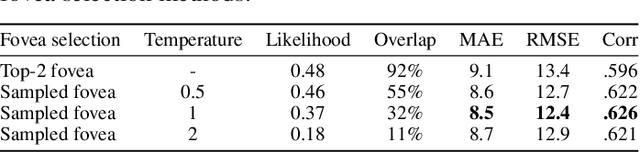
Inspired by human vision, we propose a new periphery-fovea multi-resolution driving model that predicts vehicle speed from dash camera videos. The peripheral vision module of the model processes the full video frames in low resolution. Its foveal vision module selects sub-regions and uses high-resolution input from those regions to improve its driving performance. We train the fovea selection module with supervision from driver gaze. We show that adding high-resolution input from predicted human driver gaze locations significantly improves the driving accuracy of the model. Our periphery-fovea multi-resolution model outperforms a uni-resolution periphery-only model that has the same amount of floating-point operations. More importantly, we demonstrate that our driving model achieves a significantly higher performance gain in pedestrian-involved critical situations than in other non-critical situations.
Robot Bed-Making: Deep Transfer Learning Using Depth Sensing of Deformable Fabric
Oct 10, 2018


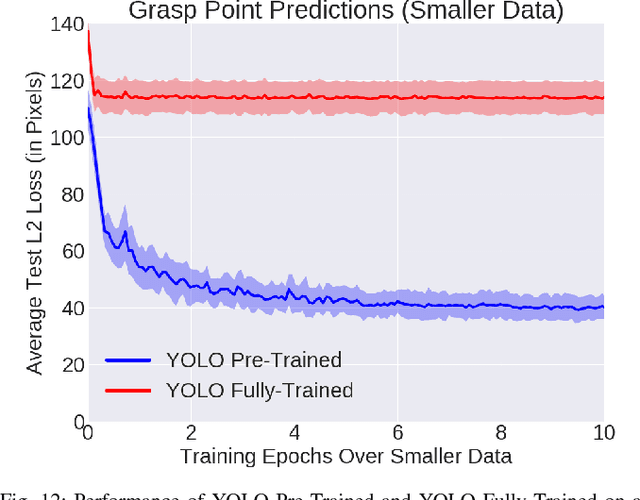
Bed-making is a common task well-suited for home robots since it is tolerant to error and not time-critical. Bed-making can also be difficult for senior citizens and those with limited mobility due to the bending and reaching movements required. Autonomous bed-making combines multiple challenges in robotics: perception in unstructured environments, deformable object manipulation, transfer learning, and sequential decision making. We formalize the bed-making problem as one of maximizing surface coverage with a blanket, and explore algorithmic approaches that use deep learning on depth images to be invariant to the color and pattern of the blankets. We train two networks: one to identify a corner of the blanket and another to determine when to transition to the other side of the bed. Using the first network, the robot grasps at its estimate of the blanket corner and then pulls it to the appropriate corner of the bed frame. The second network estimates if the robot has sufficiently covered one side and can transition to the other, or if it should attempt another grasp from the same side. We evaluate with two robots, the Toyota HSR and the Fetch, and three blankets. Using 2018 and 654 depth images for training the grasp and transition networks respectively, experiments with a quarter-scale twin bed achieve an average of 91.7% blanket coverage, nearly matching human supervisors with 95.0% coverage. Data is available at https://sites.google.com/view/bed-make.
Label and Sample: Efficient Training of Vehicle Object Detector from Sparsely Labeled Data
Aug 26, 2018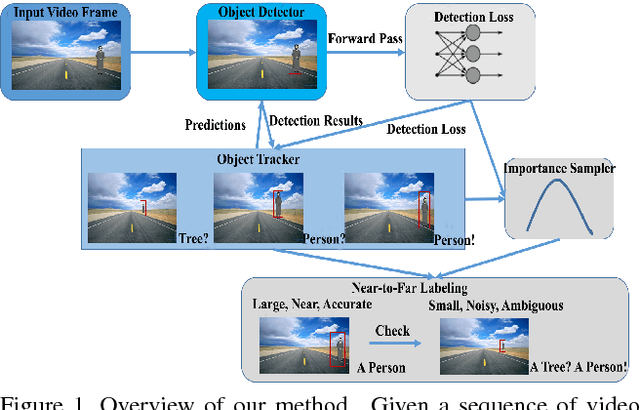
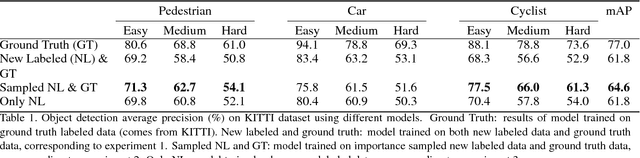

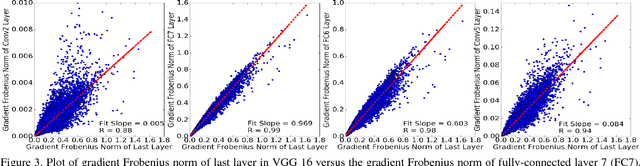
Self-driving vehicle vision systems must deal with an extremely broad and challenging set of scenes. They can potentially exploit an enormous amount of training data collected from vehicles in the field, but the volumes are too large to train offline naively. Not all training instances are equally valuable though, and importance sampling can be used to prioritize which training images to collect. This approach assumes that objects in images are labeled with high accuracy. To generate accurate labels in the field, we exploit the spatio-temporal coherence of vehicle video. We use a near-to-far labeling strategy by first labeling large, close objects in the video, and tracking them back in time to induce labels on small distant presentations of those objects. In this paper we demonstrate the feasibility of this approach in several steps. First, we note that an optimal subset (relative to all the objects encountered and labeled) of labeled objects in images can be obtained by importance sampling using gradients of the recognition network. Next we show that these gradients can be approximated with very low error using the loss function, which is already available when the CNN is running inference. Then, we generalize these results to objects in a larger scene using an object detection system. Finally, we describe a self-labeling scheme using object tracking. Objects are tracked back in time (near-to-far) and labels of near objects are used to check accuracy of those objects in the far field. We then evaluate the accuracy of models trained on importance sampled data vs models trained on complete data.
Textual Explanations for Self-Driving Vehicles
Jul 30, 2018
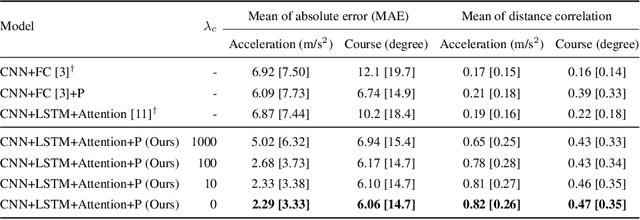
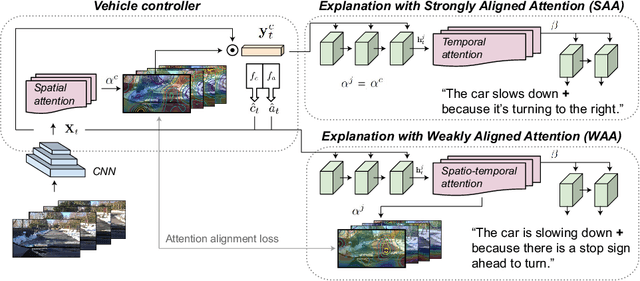
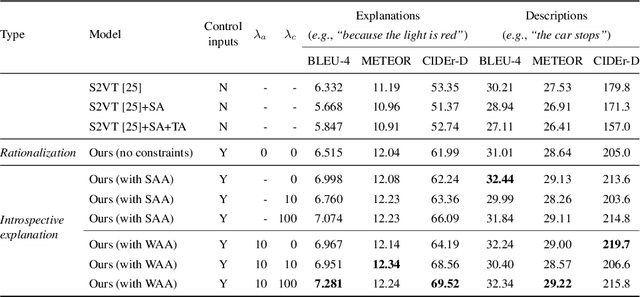
Deep neural perception and control networks have become key components of self-driving vehicles. User acceptance is likely to benefit from easy-to-interpret textual explanations which allow end-users to understand what triggered a particular behavior. Explanations may be triggered by the neural controller, namely introspective explanations, or informed by the neural controller's output, namely rationalizations. We propose a new approach to introspective explanations which consists of two parts. First, we use a visual (spatial) attention model to train a convolutional network end-to-end from images to the vehicle control commands, i.e., acceleration and change of course. The controller's attention identifies image regions that potentially influence the network's output. Second, we use an attention-based video-to-text model to produce textual explanations of model actions. The attention maps of controller and explanation model are aligned so that explanations are grounded in the parts of the scene that mattered to the controller. We explore two approaches to attention alignment, strong- and weak-alignment. Finally, we explore a version of our model that generates rationalizations, and compare with introspective explanations on the same video segments. We evaluate these models on a novel driving dataset with ground-truth human explanations, the Berkeley DeepDrive eXplanation (BDD-X) dataset. Code is available at https://github.com/JinkyuKimUCB/explainable-deep-driving.
* Accepted to ECCV 2018
Fast and Reliable Autonomous Surgical Debridement with Cable-Driven Robots Using a Two-Phase Calibration Procedure
Feb 24, 2018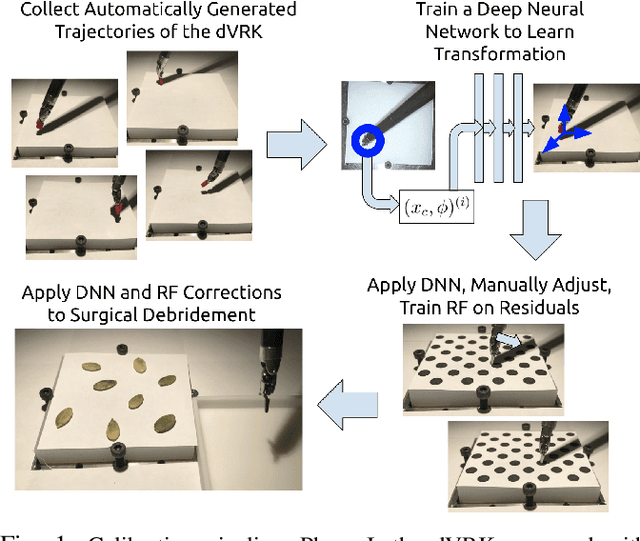
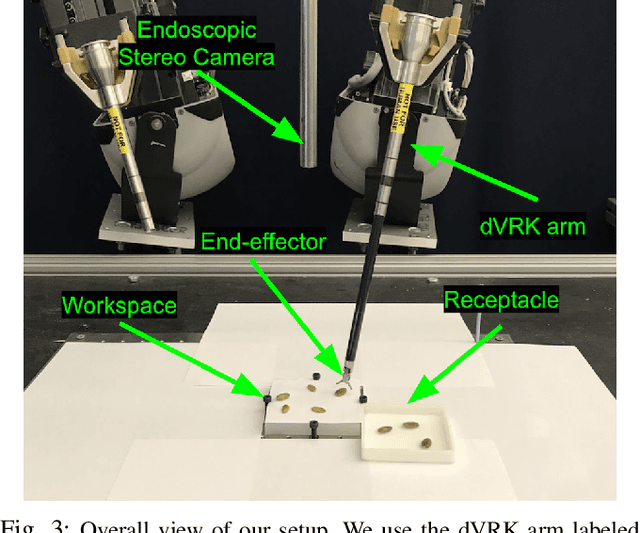

Automating precision subtasks such as debridement (removing dead or diseased tissue fragments) with Robotic Surgical Assistants (RSAs) such as the da Vinci Research Kit (dVRK) is challenging due to inherent non-linearities in cable-driven systems. We propose and evaluate a novel two-phase coarse-to-fine calibration method. In Phase I (coarse), we place a red calibration marker on the end effector and let it randomly move through a set of open-loop trajectories to obtain a large sample set of camera pixels and internal robot end-effector configurations. This coarse data is then used to train a Deep Neural Network (DNN) to learn the coarse transformation bias. In Phase II (fine), the bias from Phase I is applied to move the end-effector toward a small set of specific target points on a printed sheet. For each target, a human operator manually adjusts the end-effector position by direct contact (not through teleoperation) and the residual compensation bias is recorded. This fine data is then used to train a Random Forest (RF) to learn the fine transformation bias. Subsequent experiments suggest that without calibration, position errors average 4.55mm. Phase I can reduce average error to 2.14mm and the combination of Phase I and Phase II can reduces average error to 1.08mm. We apply these results to debridement of raisins and pumpkin seeds as fragment phantoms. Using an endoscopic stereo camera with standard edge detection, experiments with 120 trials achieved average success rates of 94.5%, exceeding prior results with much larger fragments (89.4%) and achieving a speedup of 2.1x, decreasing time per fragment from 15.8 seconds to 7.3 seconds. Source code, data, and videos are available at https://sites.google.com/view/calib-icra/.
An Efficient Minibatch Acceptance Test for Metropolis-Hastings
Jul 09, 2017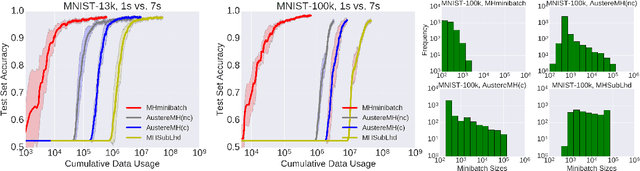


We present a novel Metropolis-Hastings method for large datasets that uses small expected-size minibatches of data. Previous work on reducing the cost of Metropolis-Hastings tests yield variable data consumed per sample, with only constant factor reductions versus using the full dataset for each sample. Here we present a method that can be tuned to provide arbitrarily small batch sizes, by adjusting either proposal step size or temperature. Our test uses the noise-tolerant Barker acceptance test with a novel additive correction variable. The resulting test has similar cost to a normal SGD update. Our experiments demonstrate several order-of-magnitude speedups over previous work.
General models for rational cameras and the case of two-slit projections
Apr 11, 2017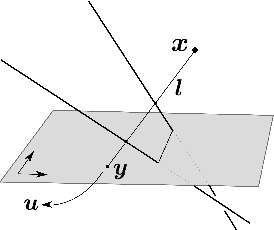
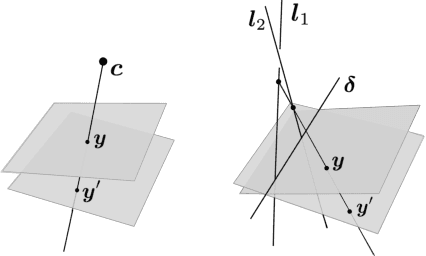
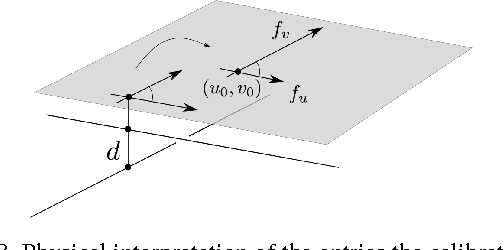
The rational camera model recently introduced in [19] provides a general methodology for studying abstract nonlinear imaging systems and their multi-view geometry. This paper builds on this framework to study "physical realizations" of rational cameras. More precisely, we give an explicit account of the mapping between between physical visual rays and image points (missing in the original description), which allows us to give simple analytical expressions for direct and inverse projections. We also consider "primitive" camera models, that are orbits under the action of various projective transformations, and lead to a general notion of intrinsic parameters. The methodology is general, but it is illustrated concretely by an in-depth study of two-slit cameras, that we model using pairs of linear projections. This simple analytical form allows us to describe models for the corresponding primitive cameras, to introduce intrinsic parameters with a clear geometric meaning, and to define an epipolar tensor characterizing two-view correspondences. In turn, this leads to new algorithms for structure from motion and self-calibration.
Interpretable Learning for Self-Driving Cars by Visualizing Causal Attention
Mar 30, 2017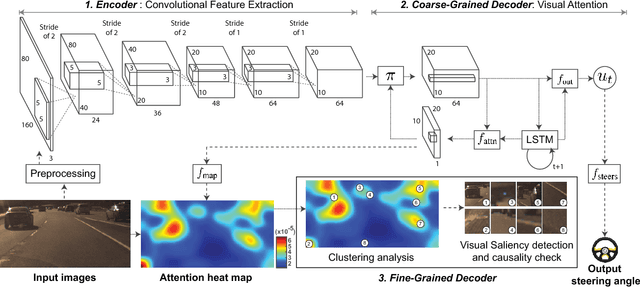
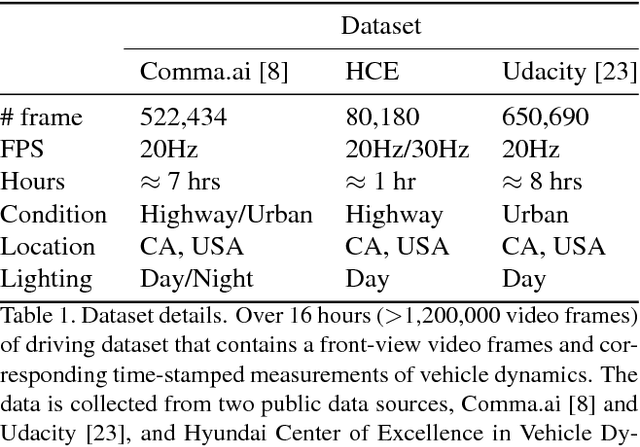
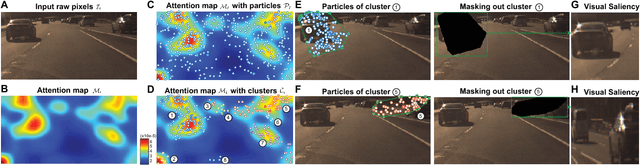
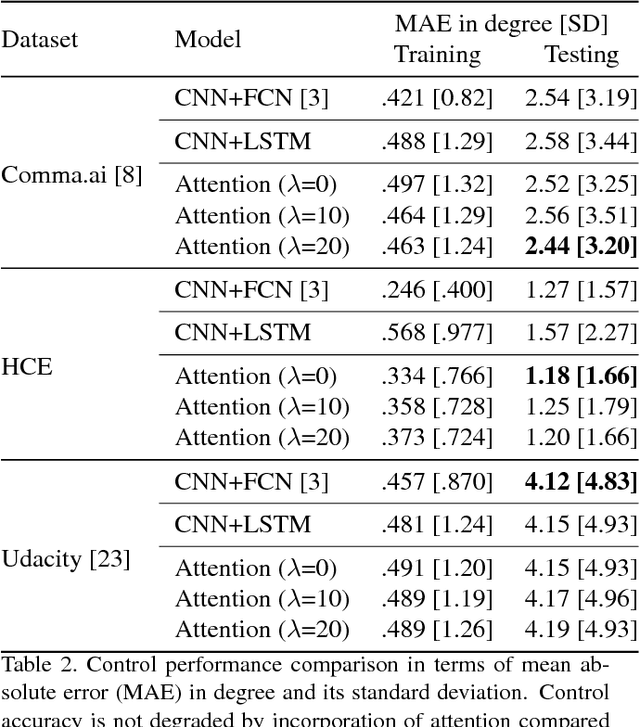
Deep neural perception and control networks are likely to be a key component of self-driving vehicles. These models need to be explainable - they should provide easy-to-interpret rationales for their behavior - so that passengers, insurance companies, law enforcement, developers etc., can understand what triggered a particular behavior. Here we explore the use of visual explanations. These explanations take the form of real-time highlighted regions of an image that causally influence the network's output (steering control). Our approach is two-stage. In the first stage, we use a visual attention model to train a convolution network end-to-end from images to steering angle. The attention model highlights image regions that potentially influence the network's output. Some of these are true influences, but some are spurious. We then apply a causal filtering step to determine which input regions actually influence the output. This produces more succinct visual explanations and more accurately exposes the network's behavior. We demonstrate the effectiveness of our model on three datasets totaling 16 hours of driving. We first show that training with attention does not degrade the performance of the end-to-end network. Then we show that the network causally cues on a variety of features that are used by humans while driving.