 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware Pre-Training
Oct 12, 2021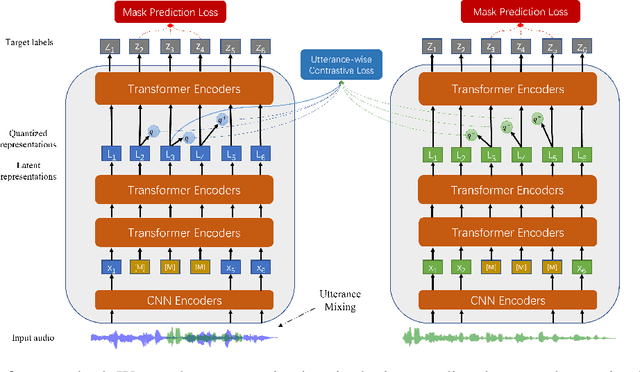
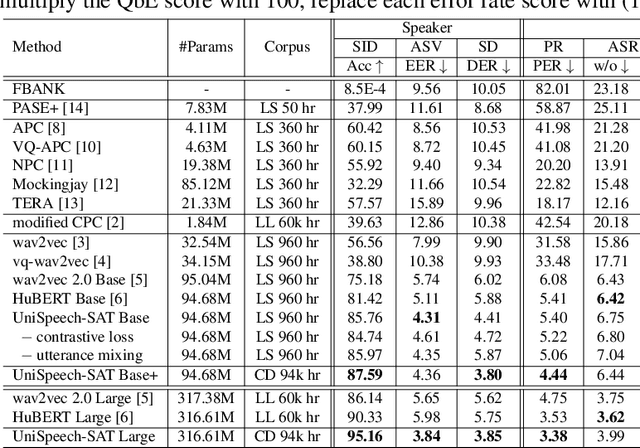
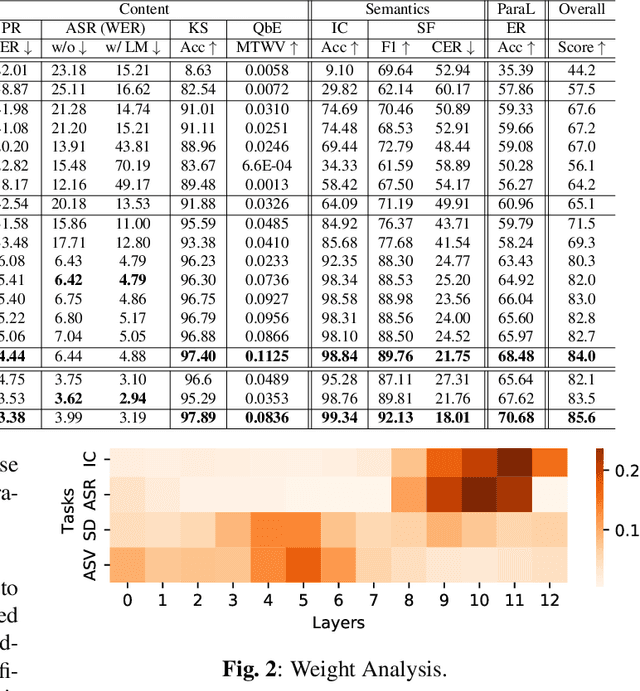
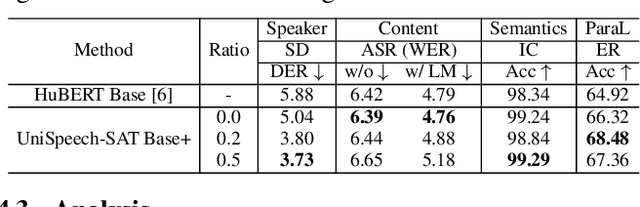
Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.
Wav2vec-Switch: Contrastive Learning from Original-noisy Speech Pairs for Robust Speech Recognition
Oct 11, 2021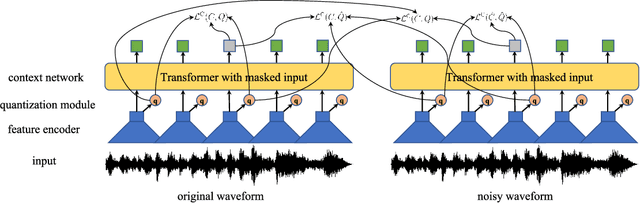
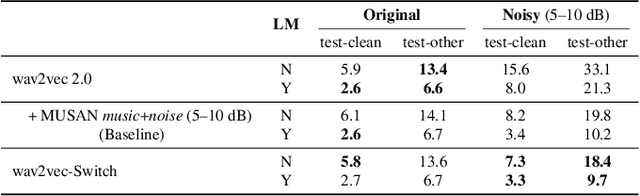
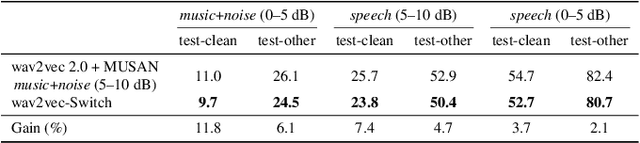

The goal of self-supervised learning (SSL) for automatic speech recognition (ASR) is to learn good speech representations from a large amount of unlabeled speech for the downstream ASR task. However, most SSL frameworks do not consider noise robustness which is crucial for real-world applications. In this paper we propose wav2vec-Switch, a method to encode noise robustness into contextualized representations of speech via contrastive learning. Specifically, we feed original-noisy speech pairs simultaneously into the wav2vec 2.0 network. In addition to the existing contrastive learning task, we switch the quantized representations of the original and noisy speech as additional prediction targets of each other. By doing this, it enforces the network to have consistent predictions for the original and noisy speech, thus allows to learn contextualized representation with noise robustness. Our experiments on synthesized and real noisy data show the effectiveness of our method: it achieves 2.9--4.9% relative word error rate (WER) reduction on the synthesized noisy LibriSpeech data without deterioration on the original data, and 5.7% on CHiME-4 real 1-channel noisy data compared to a data augmentation baseline even with a strong language model for decoding. Our results on CHiME-4 can match or even surpass those with well-designed speech enhancement components.
Have best of both worlds: two-pass hybrid and E2E cascading framework for speech recognition
Oct 10, 2021
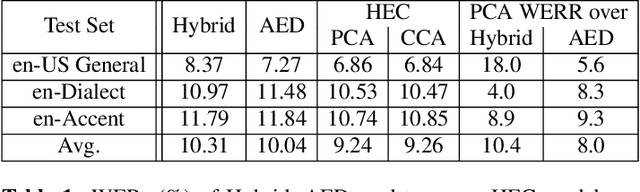
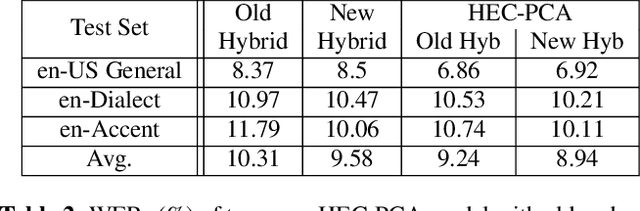
Hybrid and end-to-end (E2E) systems have their individual advantages, with different error patterns in the speech recognition results. By jointly modeling audio and text, the E2E model performs better in matched scenarios and scales well with a large amount of paired audio-text training data. The modularized hybrid model is easier for customization, and better to make use of a massive amount of unpaired text data. This paper proposes a two-pass hybrid and E2E cascading (HEC) framework to combine the hybrid and E2E model in order to take advantage of both sides, with hybrid in the first pass and E2E in the second pass. We show that the proposed system achieves 8-10% relative word error rate reduction with respect to each individual system. More importantly, compared with the pure E2E system, we show the proposed system has the potential to keep the advantages of hybrid system, e.g., customization and segmentation capabilities. We also show the second pass E2E model in HEC is robust with respect to the change in the first pass hybrid model.
Continuous Streaming Multi-Talker ASR with Dual-path Transducers
Sep 17, 2021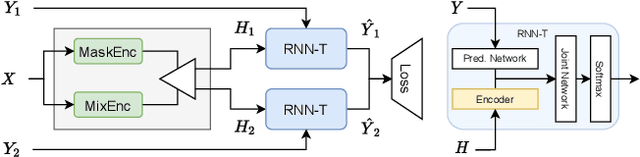

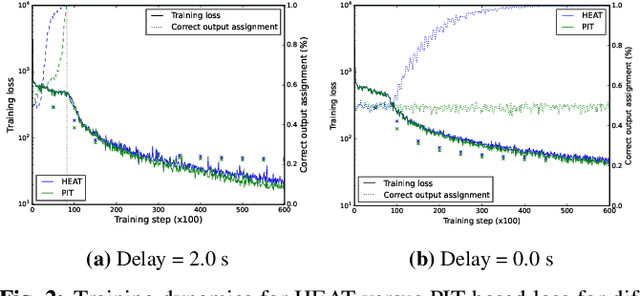
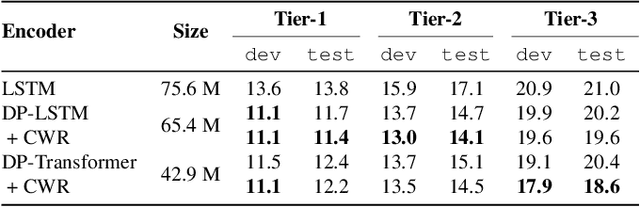
Streaming recognition of multi-talker conversations has so far been evaluated only for 2-speaker single-turn sessions. In this paper, we investigate it for multi-turn meetings containing multiple speakers using the Streaming Unmixing and Recognition Transducer (SURT) model, and show that naively extending the single-turn model to this harder setting incurs a performance penalty. As a solution, we propose the dual-path (DP) modeling strategy first used for time-domain speech separation. We experiment with LSTM and Transformer based DP models, and show that they improve word error rate (WER) performance while yielding faster convergence. We also explore training strategies such as chunk width randomization and curriculum learning for these models, and demonstrate their importance through ablation studies. Finally, we evaluate our models on the LibriCSS meeting data, where they perform competitively with offline separation-based methods.
A Light-weight contextual spelling correction model for customizing transducer-based speech recognition systems
Aug 17, 2021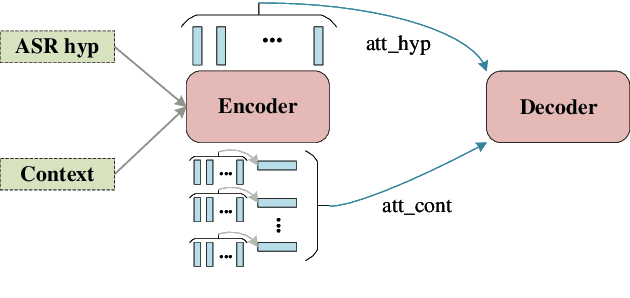


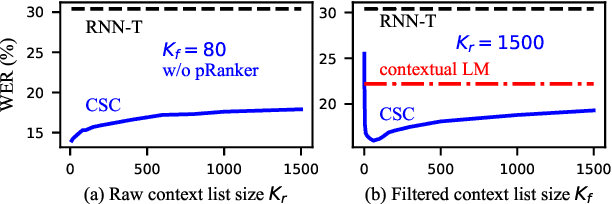
It's challenging to customize transducer-based automatic speech recognition (ASR) system with context information which is dynamic and unavailable during model training. In this work, we introduce a light-weight contextual spelling correction model to correct context-related recognition errors in transducer-based ASR systems. We incorporate the context information into the spelling correction model with a shared context encoder and use a filtering algorithm to handle large-size context lists. Experiments show that the model improves baseline ASR model performance with about 50% relative word error rate reduction, which also significantly outperforms the baseline method such as contextual LM biasing. The model also shows excellent performance for out-of-vocabulary terms not seen during training.
A Configurable Multilingual Model is All You Need to Recognize All Languages
Jul 13, 2021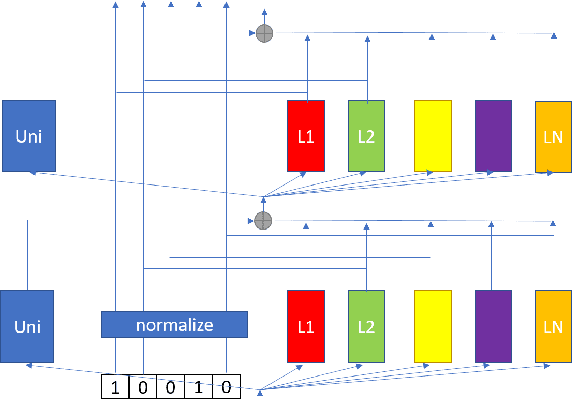
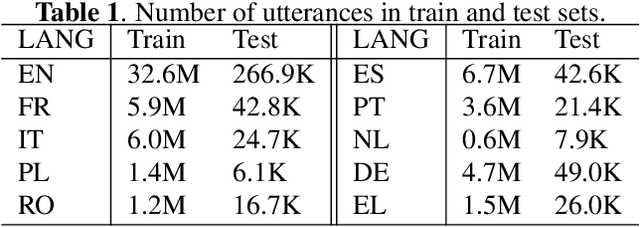
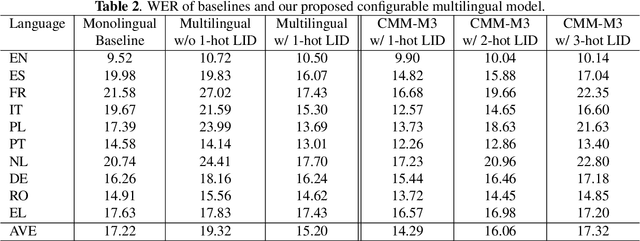
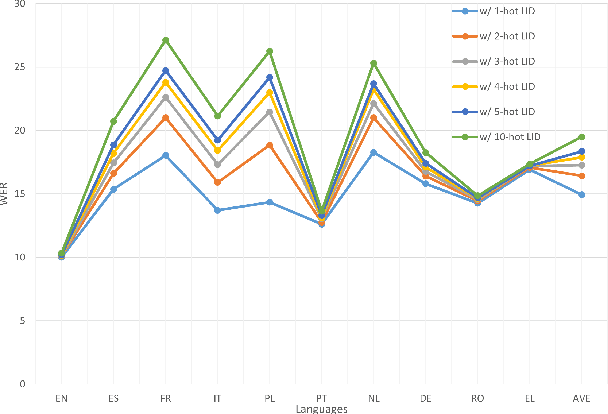
Multilingual automatic speech recognition (ASR) models have shown great promise in recent years because of the simplified model training and deployment process. Conventional methods either train a universal multilingual model without taking any language information or with a 1-hot language ID (LID) vector to guide the recognition of the target language. In practice, the user can be prompted to pre-select several languages he/she can speak. The multilingual model without LID cannot well utilize the language information set by the user while the multilingual model with LID can only handle one pre-selected language. In this paper, we propose a novel configurable multilingual model (CMM) which is trained only once but can be configured as different models based on users' choices by extracting language-specific modules together with a universal model from the trained CMM. Particularly, a single CMM can be deployed to any user scenario where the users can pre-select any combination of languages. Trained with 75K hours of transcribed anonymized Microsoft multilingual data and evaluated with 10-language test sets, the proposed CMM improves from the universal multilingual model by 26.0%, 16.9%, and 10.4% relative word error reduction when the user selects 1, 2, or 3 languages, respectively. CMM also performs significantly better on code-switching test sets.
UniSpeech at scale: An Empirical Study of Pre-training Method on Large-Scale Speech Recognition Dataset
Jul 12, 2021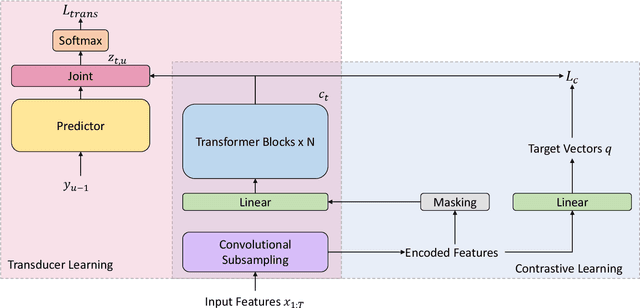
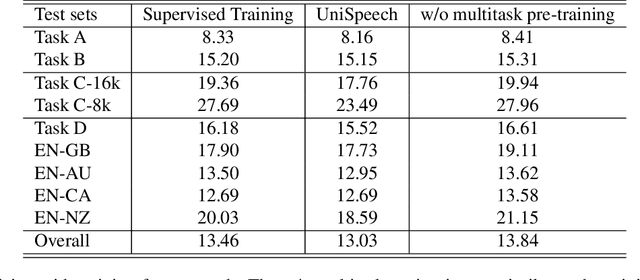
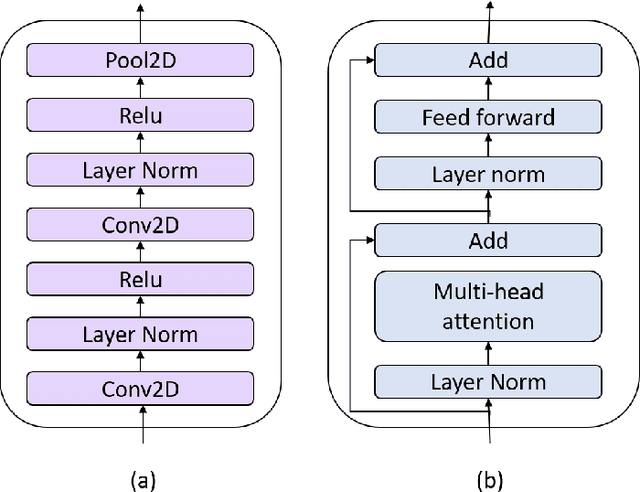
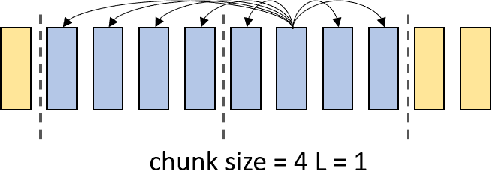
Recently, there has been a vast interest in self-supervised learning (SSL) where the model is pre-trained on large scale unlabeled data and then fine-tuned on a small labeled dataset. The common wisdom is that SSL helps resource-limited tasks in which only a limited amount of labeled data is available. The benefit of SSL keeps diminishing when the labeled training data amount increases. To our best knowledge, at most a few thousand hours of labeled data was used in the study of SSL. In contrast, the industry usually uses tens of thousands of hours of labeled data to build high-accuracy speech recognition (ASR) systems for resource-rich languages. In this study, we take the challenge to investigate whether and how SSL can improve the ASR accuracy of a state-of-the-art production-scale Transformer-Transducer model, which was built with 65 thousand hours of anonymized labeled EN-US data.
Investigation of Practical Aspects of Single Channel Speech Separation for ASR
Jul 05, 2021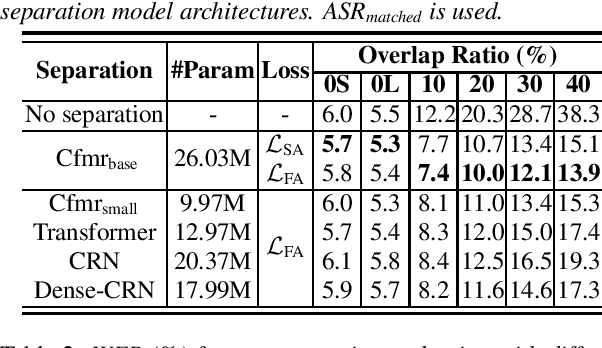
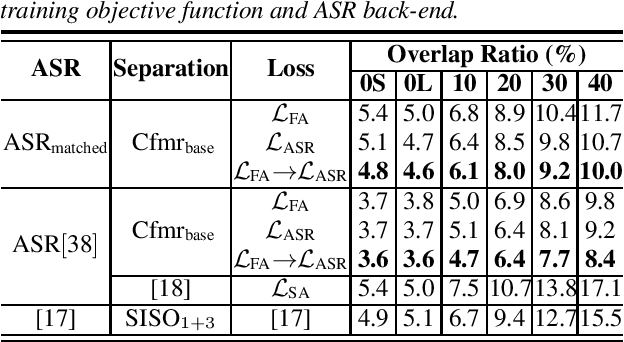
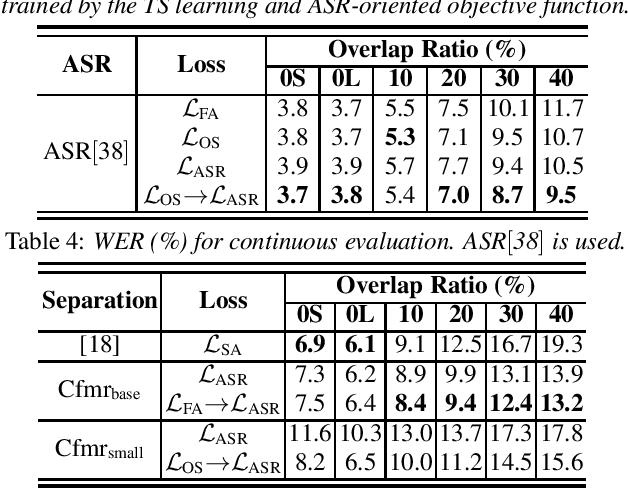
Speech separation has been successfully applied as a frontend processing module of conversation transcription systems thanks to its ability to handle overlapped speech and its flexibility to combine with downstream tasks such as automatic speech recognition (ASR). However, a speech separation model often introduces target speech distortion, resulting in a sub-optimum word error rate (WER). In this paper, we describe our efforts to improve the performance of a single channel speech separation system. Specifically, we investigate a two-stage training scheme that firstly applies a feature level optimization criterion for pretraining, followed by an ASR-oriented optimization criterion using an end-to-end (E2E) speech recognition model. Meanwhile, to keep the model light-weight, we introduce a modified teacher-student learning technique for model compression. By combining those approaches, we achieve a absolute average WER improvement of 2.70% and 0.77% using models with less than 10M parameters compared with the previous state-of-the-art results on the LibriCSS dataset for utterance-wise evaluation and continuous evaluation, respectively
Minimum Word Error Rate Training with Language Model Fusion for End-to-End Speech Recognition
Jun 04, 2021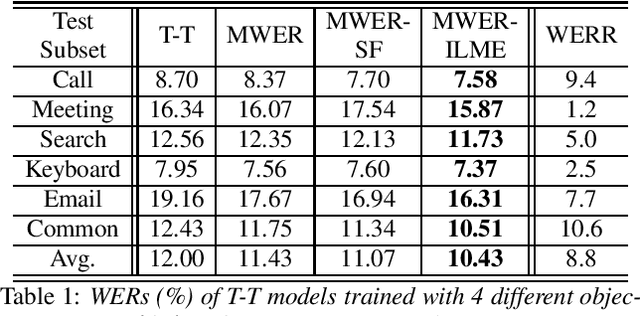
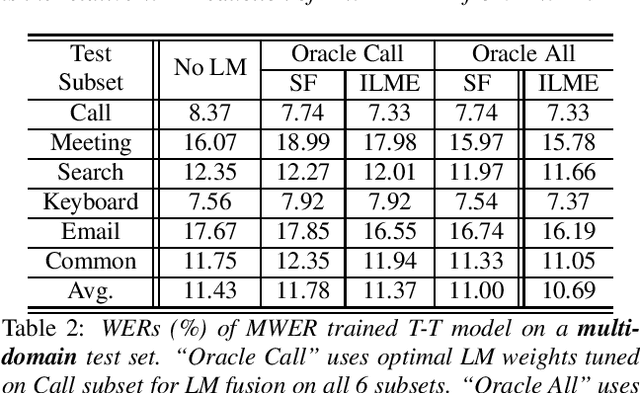
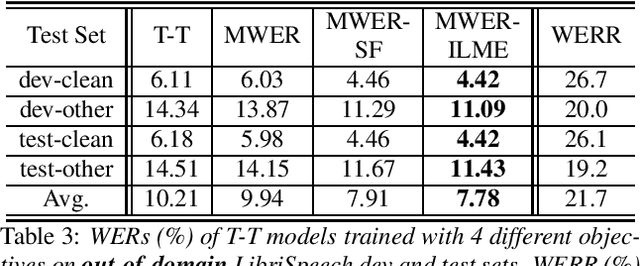
Integrating external language models (LMs) into end-to-end (E2E) models remains a challenging task for domain-adaptive speech recognition. Recently, internal language model estimation (ILME)-based LM fusion has shown significant word error rate (WER) reduction from Shallow Fusion by subtracting a weighted internal LM score from an interpolation of E2E model and external LM scores during beam search. However, on different test sets, the optimal LM interpolation weights vary over a wide range and have to be tuned extensively on well-matched validation sets. In this work, we perform LM fusion in the minimum WER (MWER) training of an E2E model to obviate the need for LM weights tuning during inference. Besides MWER training with Shallow Fusion (MWER-SF), we propose a novel MWER training with ILME (MWER-ILME) where the ILME-based fusion is conducted to generate N-best hypotheses and their posteriors. Additional gradient is induced when internal LM is engaged in MWER-ILME loss computation. During inference, LM weights pre-determined in MWER training enable robust LM integrations on test sets from different domains. Experimented with 30K-hour trained transformer transducers, MWER-ILME achieves on average 8.8% and 5.8% relative WER reductions from MWER and MWER-SF training, respectively, on 6 different test sets
* 5 pages, Interspeech 2021
On Addressing Practical Challenges for RNN-Transducer
May 04, 2021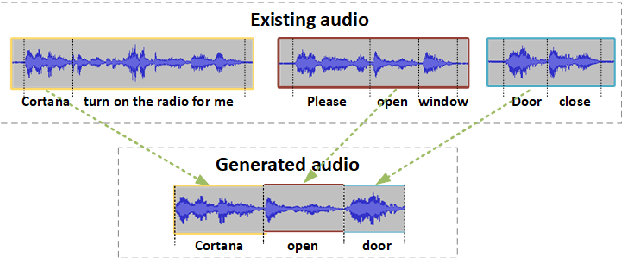

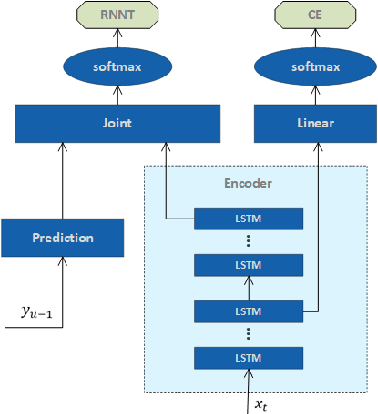

In this paper, several works are proposed to address practical challenges for deploying RNN Transducer (RNN-T) based speech recognition system. These challenges are adapting a well-trained RNN-T model to a new domain without collecting the audio data, obtaining time stamps and confidence scores at word level. The first challenge is solved with a splicing data method which concatenates the speech segments extracted from the source domain data. To get the time stamp, a phone prediction branch is added to the RNN-T model by sharing the encoder for the purpose of force alignment. Finally, we obtain word-level confidence scores by utilizing several types of features calculated during decoding and from confusion network. Evaluated with Microsoft production data, the splicing data adaptation method improves the baseline and adaption with the text to speech method by 58.03% and 15.25% relative word error rate reduction, respectively. The proposed time stamping method can get less than 50ms word timing difference on average while maintaining the recognition accuracy of the RNN-T model. We also obtain high confidence annotation performance with limited computation cost.