 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMER 2023: Multi-label Learning, Modality Robustness, and Semi-Supervised Learning
Apr 18, 2023



Over the past few decades, multimodal emotion recognition has made remarkable progress with the development of deep learning. However, existing technologies are difficult to meet the demand for practical applications. To improve the robustness, we launch a Multimodal Emotion Recognition Challenge (MER 2023) to motivate global researchers to build innovative technologies that can further accelerate and foster research. For this year's challenge, we present three distinct sub-challenges: (1) MER-MULTI, in which participants recognize both discrete and dimensional emotions; (2) MER-NOISE, in which noise is added to test videos for modality robustness evaluation; (3) MER-SEMI, which provides large amounts of unlabeled samples for semi-supervised learning. In this paper, we test a variety of multimodal features and provide a competitive baseline for each sub-challenge. Our system achieves 77.57% on the F1 score and 0.82 on the mean squared error (MSE) for MER-MULTI, 69.82% on the F1 score and 1.12 on MSE for MER-NOISE, and 86.75% on the F1 score for MER-SEMI, respectively. Baseline code is available at https://github.com/zeroQiaoba/MER2023-Baseline.
Exploiting modality-invariant feature for robust multimodal emotion recognition with missing modalities
Oct 27, 2022



Multimodal emotion recognition leverages complementary information across modalities to gain performance. However, we cannot guarantee that the data of all modalities are always present in practice. In the studies to predict the missing data across modalities, the inherent difference between heterogeneous modalities, namely the modality gap, presents a challenge. To address this, we propose to use invariant features for a missing modality imagination network (IF-MMIN) which includes two novel mechanisms: 1) an invariant feature learning strategy that is based on the central moment discrepancy (CMD) distance under the full-modality scenario; 2) an invariant feature based imagination module (IF-IM) to alleviate the modality gap during the missing modalities prediction, thus improving the robustness of multimodal joint representation. Comprehensive experiments on the benchmark dataset IEMOCAP demonstrate that the proposed model outperforms all baselines and invariantly improves the overall emotion recognition performance under uncertain missing-modality conditions. We release the code at: https://github.com/ZhuoYulang/IF-MMIN.
Self-supervised Rewiring of Pre-trained Speech Encoders: Towards Faster Fine-tuning with Less Labels in Speech Processing
Oct 24, 2022



Pre-trained speech Transformers have facilitated great success across various speech processing tasks. However, fine-tuning these encoders for downstream tasks require sufficiently large training data to converge or to achieve state-of-the-art. In text domain this has been partly attributed to sub-optimality of the representation space in pre-trained Transformers. In this work, we take a sober look into pre-trained speech encoders and rewire their representation space without requiring any task-specific labels. Our method utilises neutrally synthesised version of audio inputs along with frame masking to construct positive pairs for contrastive self-supervised learning. When used for augmenting the wav2vec 2 encoder, we observe consistent improvement of isotropy in the representation space. Our experiments on 6 speech processing tasks, exhibit a significant convergence speedup during task fine-tuning as well as consistent task improvement, specially in low-resource settings.
Towards Relation Extraction From Speech
Oct 17, 2022



Relation extraction typically aims to extract semantic relationships between entities from the unstructured text. One of the most essential data sources for relation extraction is the spoken language, such as interviews and dialogues. However, the error propagation introduced in automatic speech recognition (ASR) has been ignored in relation extraction, and the end-to-end speech-based relation extraction method has been rarely explored. In this paper, we propose a new listening information extraction task, i.e., speech relation extraction. We construct the training dataset for speech relation extraction via text-to-speech systems, and we construct the testing dataset via crowd-sourcing with native English speakers. We explore speech relation extraction via two approaches: the pipeline approach conducting text-based extraction with a pretrained ASR module, and the end2end approach via a new proposed encoder-decoder model, or what we called SpeechRE. We conduct comprehensive experiments to distinguish the challenges in speech relation extraction, which may shed light on future explorations. We share the code and data on https://github.com/wutong8023/SpeechRE.
RedApt: An Adaptor for wav2vec 2 Encoding \\ Faster and Smaller Speech Translation without Quality Compromise
Oct 16, 2022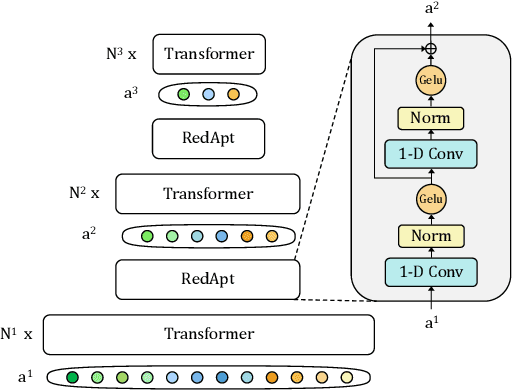
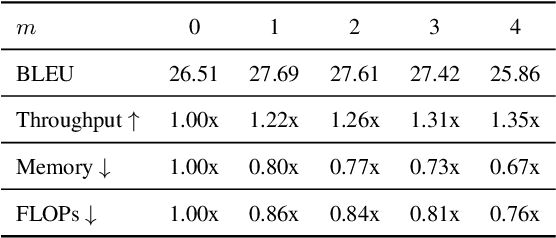
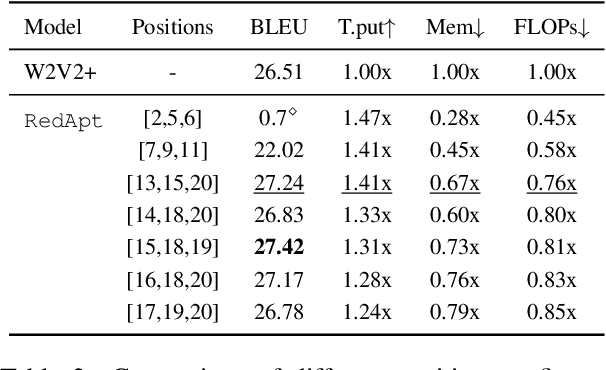
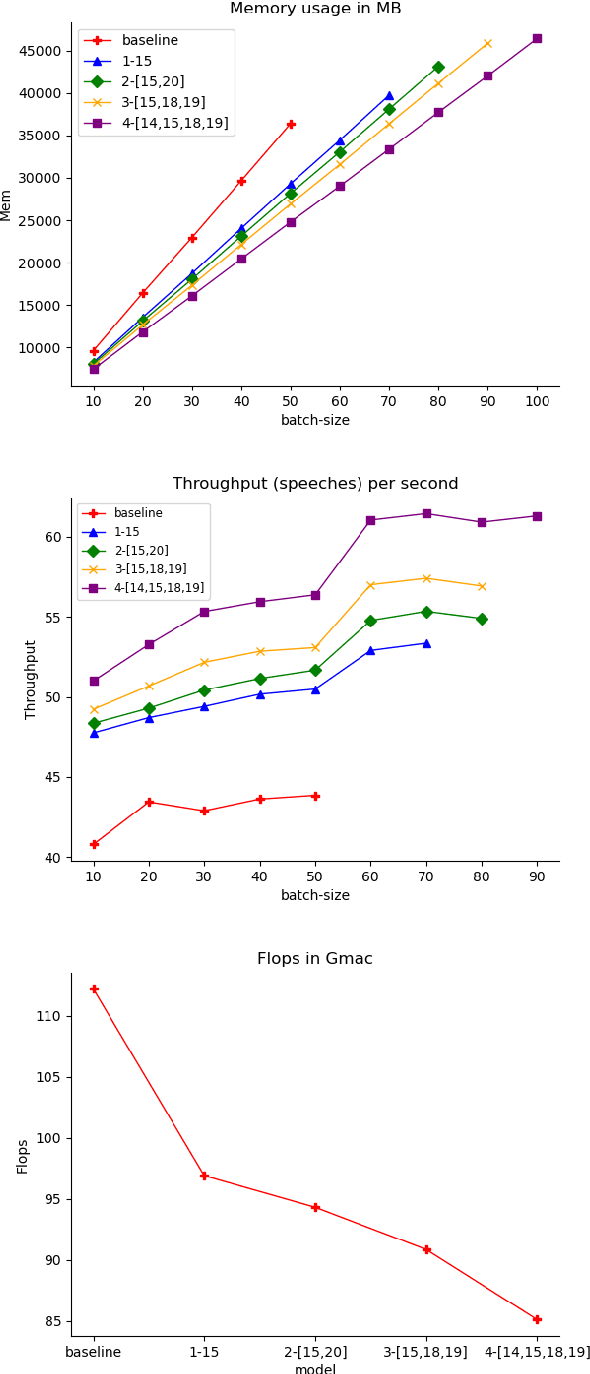
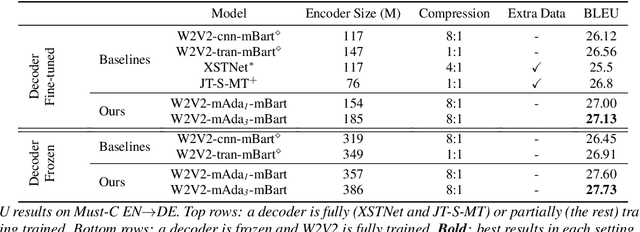
Pre-trained speech Transformers in speech translation (ST) have facilitated state-of-the-art (SotA) results; yet, using such encoders is computationally expensive. To improve this, we present a novel Reducer Adaptor block, RedApt, that could be seamlessly integrated within any Transformer-based speech encoding architecture. Integrating the pretrained wav2vec 2 speech encoder with RedAptbrings 41% speedup, 33% memory reduction with 24% fewer FLOPs at inference. To our positive surprise, our ST model with RedApt outperforms the SotA architecture by an average of 0.68 BLEU score on 8 language pairs from Must-C.
Generating Synthetic Speech from SpokenVocab for Speech Translation
Oct 15, 2022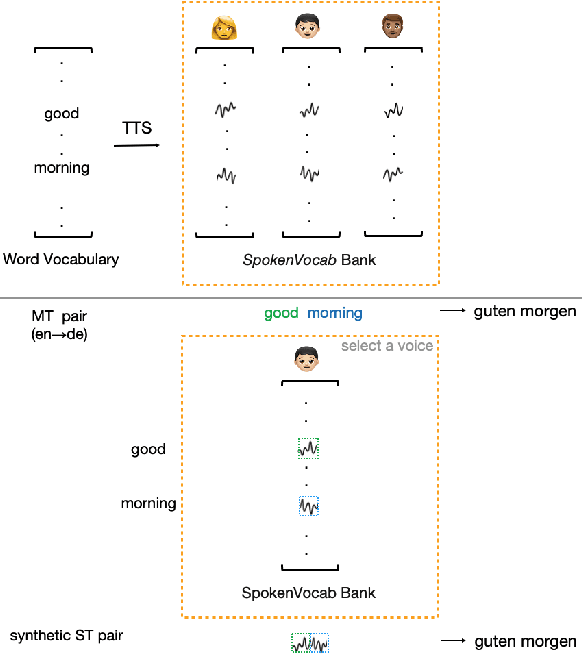
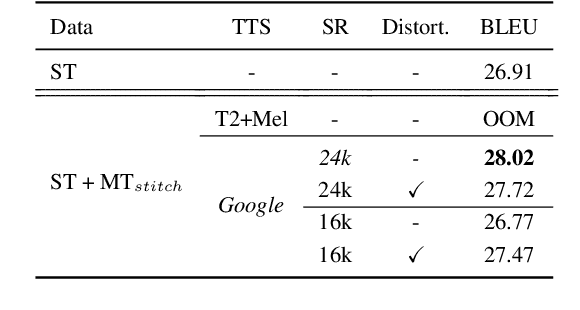
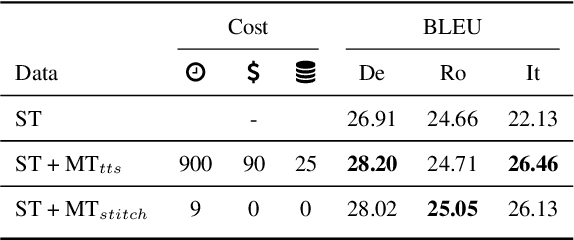
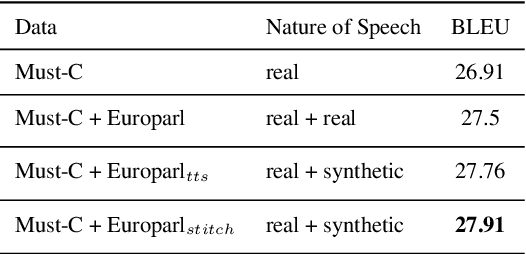
Training end-to-end speech translation (ST) systems requires sufficiently large-scale data, which is unavailable for most language pairs and domains. One practical solution to the data scarcity issue is to convert machine translation data (MT) to ST data via text-to-speech (TTS) systems. Yet, using TTS systems can be tedious and slow, as the conversion needs to be done for each MT dataset. In this work, we propose a simple, scalable and effective data augmentation technique, i.e., SpokenVocab, to convert MT data to ST data on-the-fly. The idea is to retrieve and stitch audio snippets from a SpokenVocab bank according to words in an MT sequence. Our experiments on multiple language pairs from Must-C show that this method outperforms strong baselines by an average of 1.83 BLEU scores, and it performs equally well as TTS-generated speech. We also showcase how SpokenVocab can be applied in code-switching ST for which often no TTS systems exit. Our code is available at https://github.com/mingzi151/SpokenVocab
M-Adapter: Modality Adaptation for End-to-End Speech-to-Text Translation
Jul 03, 2022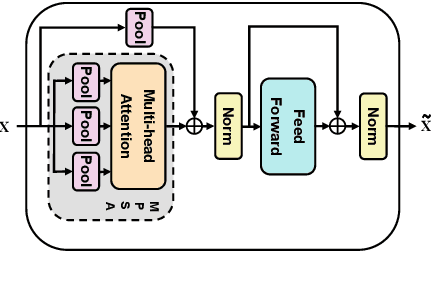
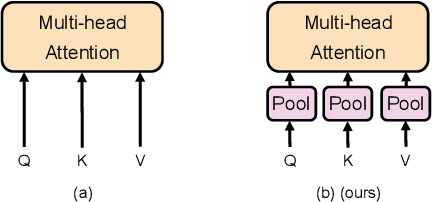
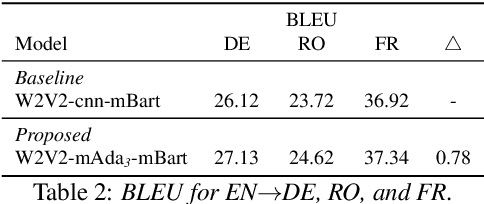
End-to-end speech-to-text translation models are often initialized with pre-trained speech encoder and pre-trained text decoder. This leads to a significant training gap between pre-training and fine-tuning, largely due to the modality differences between speech outputs from the encoder and text inputs to the decoder. In this work, we aim to bridge the modality gap between speech and text to improve translation quality. We propose M-Adapter, a novel Transformer-based module, to adapt speech representations to text. While shrinking the speech sequence, M-Adapter produces features desired for speech-to-text translation via modelling global and local dependencies of a speech sequence. Our experimental results show that our model outperforms a strong baseline by up to 1 BLEU score on the Must-C En$\rightarrow$DE dataset.\footnote{Our code is available at https://github.com/mingzi151/w2v2-st.}
M3ED: Multi-modal Multi-scene Multi-label Emotional Dialogue Database
May 09, 2022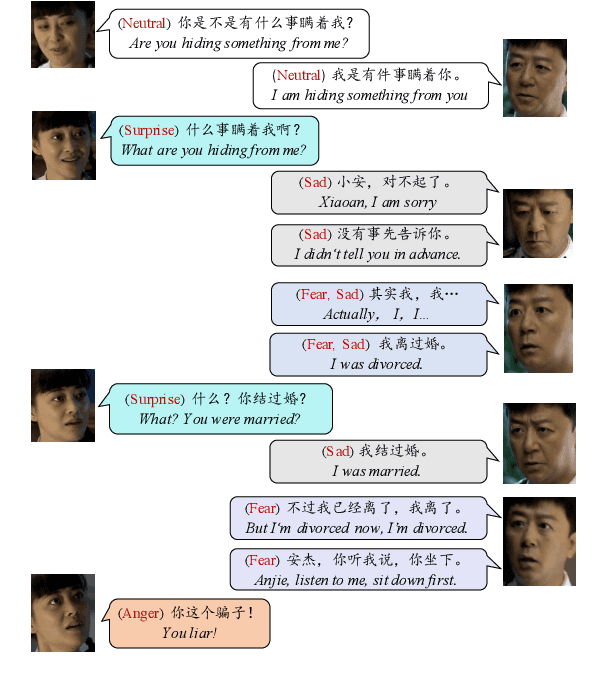

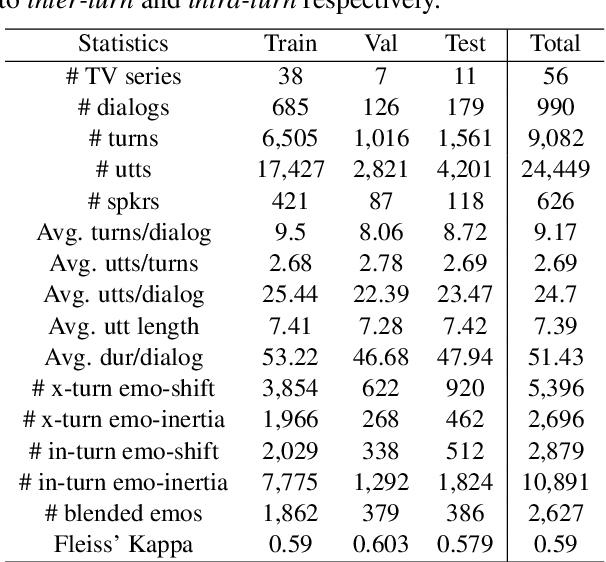
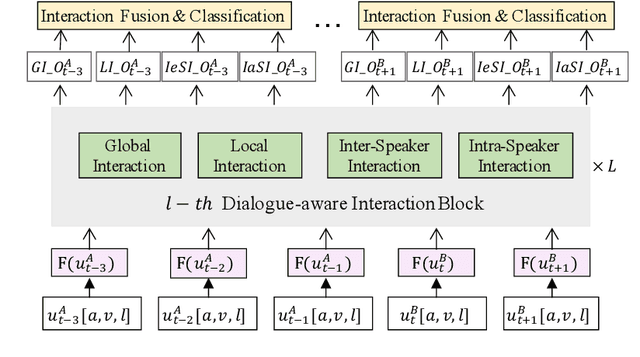
The emotional state of a speaker can be influenced by many different factors in dialogues, such as dialogue scene, dialogue topic, and interlocutor stimulus. The currently available data resources to support such multimodal affective analysis in dialogues are however limited in scale and diversity. In this work, we propose a Multi-modal Multi-scene Multi-label Emotional Dialogue dataset, M3ED, which contains 990 dyadic emotional dialogues from 56 different TV series, a total of 9,082 turns and 24,449 utterances. M3 ED is annotated with 7 emotion categories (happy, surprise, sad, disgust, anger, fear, and neutral) at utterance level, and encompasses acoustic, visual, and textual modalities. To the best of our knowledge, M3ED is the first multimodal emotional dialogue dataset in Chinese. It is valuable for cross-culture emotion analysis and recognition. We apply several state-of-the-art methods on the M3ED dataset to verify the validity and quality of the dataset. We also propose a general Multimodal Dialogue-aware Interaction framework, MDI, to model the dialogue context for emotion recognition, which achieves comparable performance to the state-of-the-art methods on the M3ED. The full dataset and codes are available.
MEmoBERT: Pre-training Model with Prompt-based Learning for Multimodal Emotion Recognition
Oct 27, 2021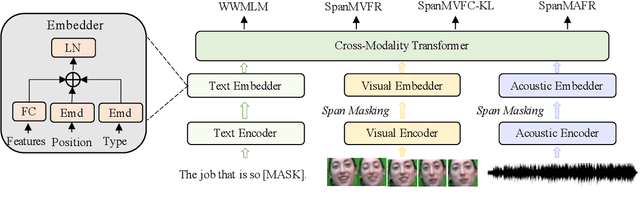

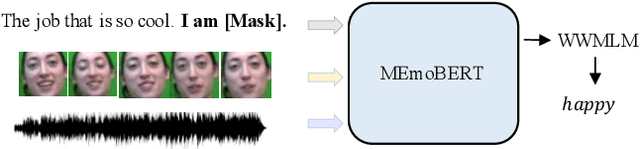
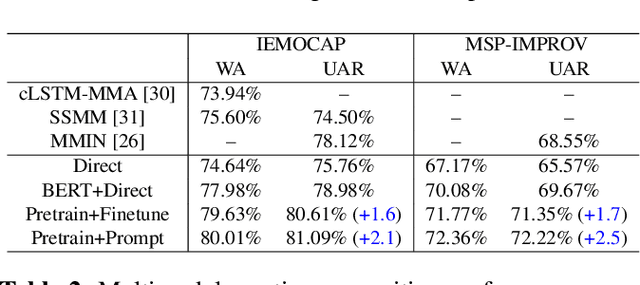
Multimodal emotion recognition study is hindered by the lack of labelled corpora in terms of scale and diversity, due to the high annotation cost and label ambiguity. In this paper, we propose a pre-training model \textbf{MEmoBERT} for multimodal emotion recognition, which learns multimodal joint representations through self-supervised learning from large-scale unlabeled video data that come in sheer volume. Furthermore, unlike the conventional "pre-train, finetune" paradigm, we propose a prompt-based method that reformulates the downstream emotion classification task as a masked text prediction one, bringing the downstream task closer to the pre-training. Extensive experiments on two benchmark datasets, IEMOCAP and MSP-IMPROV, show that our proposed MEmoBERT significantly enhances emotion recognition performance.
It is Not as Good as You Think! Evaluating Simultaneous Machine Translation on Interpretation Data
Oct 11, 2021
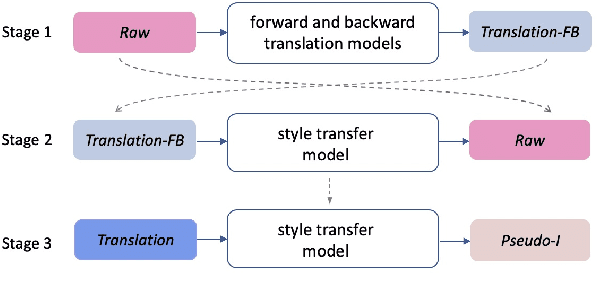
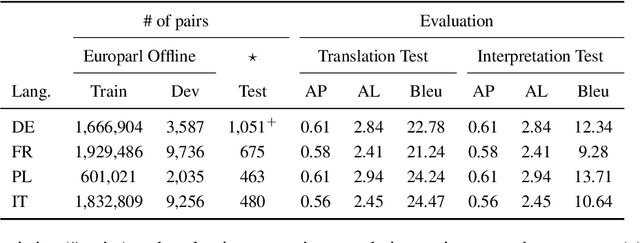
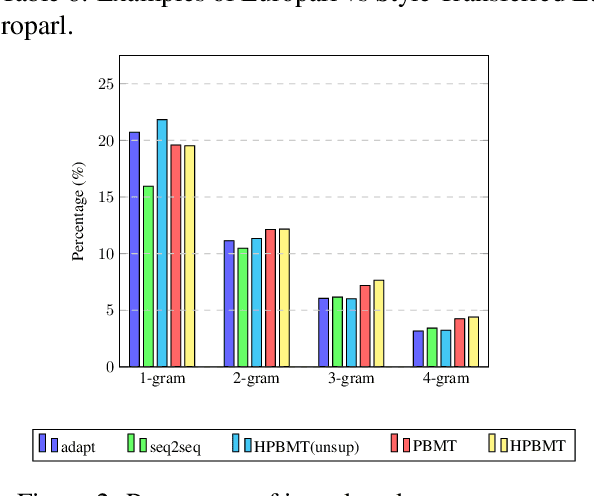
Most existing simultaneous machine translation (SiMT) systems are trained and evaluated on offline translation corpora. We argue that SiMT systems should be trained and tested on real interpretation data. To illustrate this argument, we propose an interpretation test set and conduct a realistic evaluation of SiMT trained on offline translations. Our results, on our test set along with 3 existing smaller scale language pairs, highlight the difference of up-to 13.83 BLEU score when SiMT models are evaluated on translation vs interpretation data. In the absence of interpretation training data, we propose a translation-to-interpretation (T2I) style transfer method which allows converting existing offline translations into interpretation-style data, leading to up-to 2.8 BLEU improvement. However, the evaluation gap remains notable, calling for constructing large-scale interpretation corpora better suited for evaluating and developing SiMT systems.