 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing No More: Dictionary-Guided Cross-Modal Image Fusion under Missing Infrared
Mar 09, 2026Infrared-visible (IR-VIS) image fusion is vital for perception and security, yet most methods rely on the availability of both modalities during training and inference. When the infrared modality is absent, pixel-space generative substitutes become hard to control and inherently lack interpretability. We address missing-IR fusion by proposing a dictionary-guided, coefficient-domain framework built upon a shared convolutional dictionary. The pipeline comprises three key components: (1) Joint Shared-dictionary Representation Learning (JSRL) learns a unified and interpretable atom space shared by both IR and VIS modalities; (2) VIS-Guided IR Inference (VGII) transfers VIS coefficients to pseudo-IR coefficients in the coefficient domain and performs a one-step closed-loop refinement guided by a frozen large language model as a weak semantic prior; and (3) Adaptive Fusion via Representation Inference (AFRI) merges VIS structures and inferred IR cues at the atom level through window attention and convolutional mixing, followed by reconstruction with the shared dictionary. This encode-transfer-fuse-reconstruct pipeline avoids uncontrolled pixel-space generation while ensuring prior preservation within interpretable dictionary-coefficient representation. Experiments under missing-IR settings demonstrate consistent improvements in perceptual quality and downstream detection performance. To our knowledge, this represents the first framework that jointly learns a shared dictionary and performs coefficient-domain inference-fusion to tackle missing-IR fusion. The source code is publicly available at https://github.com/harukiv/DCMIF.
Realistic Corner Case Generation for Autonomous Vehicles with Multimodal Large Language Model
Nov 29, 2024



To guarantee the safety and reliability of autonomous vehicle (AV) systems, corner cases play a crucial role in exploring the system's behavior under rare and challenging conditions within simulation environments. However, current approaches often fall short in meeting diverse testing needs and struggle to generalize to novel, high-risk scenarios that closely mirror real-world conditions. To tackle this challenge, we present AutoScenario, a multimodal Large Language Model (LLM)-based framework for realistic corner case generation. It converts safety-critical real-world data from multiple sources into textual representations, enabling the generalization of key risk factors while leveraging the extensive world knowledge and advanced reasoning capabilities of LLMs.Furthermore, it integrates tools from the Simulation of Urban Mobility (SUMO) and CARLA simulators to simplify and execute the code generated by LLMs. Our experiments demonstrate that AutoScenario can generate realistic and challenging test scenarios, precisely tailored to specific testing requirements or textual descriptions. Additionally, we validated its ability to produce diverse and novel scenarios derived from multimodal real-world data involving risky situations, harnessing the powerful generalization capabilities of LLMs to effectively simulate a wide range of corner cases.
Hypergraph Multi-modal Large Language Model: Exploiting EEG and Eye-tracking Modalities to Evaluate Heterogeneous Responses for Video Understanding
Jul 11, 2024



Understanding of video creativity and content often varies among individuals, with differences in focal points and cognitive levels across different ages, experiences, and genders. There is currently a lack of research in this area, and most existing benchmarks suffer from several drawbacks: 1) a limited number of modalities and answers with restrictive length; 2) the content and scenarios within the videos are excessively monotonous, transmitting allegories and emotions that are overly simplistic. To bridge the gap to real-world applications, we introduce a large-scale \textbf{S}ubjective \textbf{R}esponse \textbf{I}ndicators for \textbf{A}dvertisement \textbf{V}ideos dataset, namely SRI-ADV. Specifically, we collected real changes in Electroencephalographic (EEG) and eye-tracking regions from different demographics while they viewed identical video content. Utilizing this multi-modal dataset, we developed tasks and protocols to analyze and evaluate the extent of cognitive understanding of video content among different users. Along with the dataset, we designed a \textbf{H}ypergraph \textbf{M}ulti-modal \textbf{L}arge \textbf{L}anguage \textbf{M}odel (HMLLM) to explore the associations among different demographics, video elements, EEG and eye-tracking indicators. HMLLM could bridge semantic gaps across rich modalities and integrate information beyond different modalities to perform logical reasoning. Extensive experimental evaluations on SRI-ADV and other additional video-based generative performance benchmarks demonstrate the effectiveness of our method. The codes and dataset will be released at \url{https://github.com/suay1113/HMLLM}.
Recursive Least Squares Advantage Actor-Critic Algorithms
Jan 15, 2022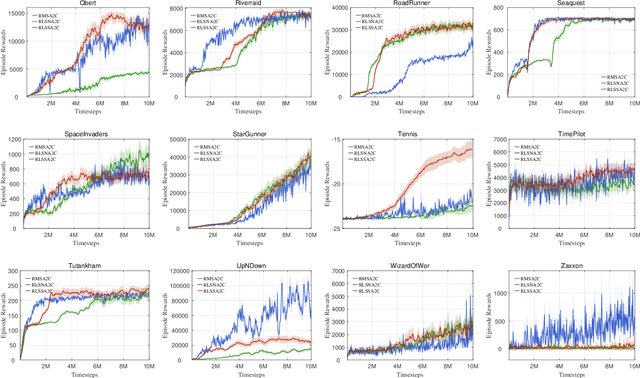
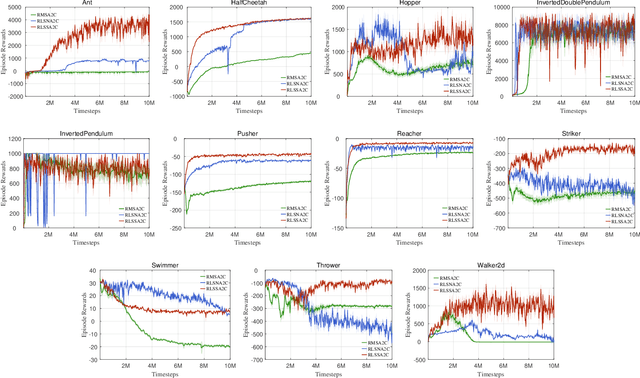
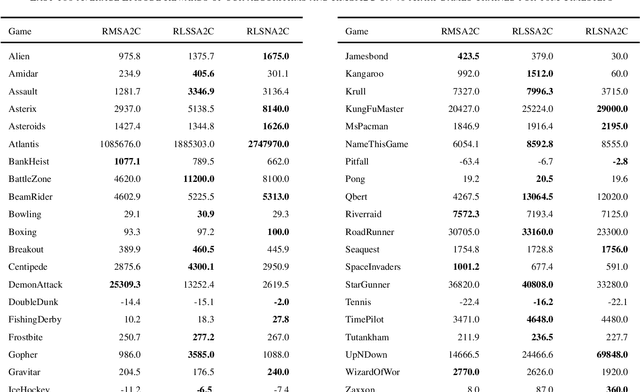
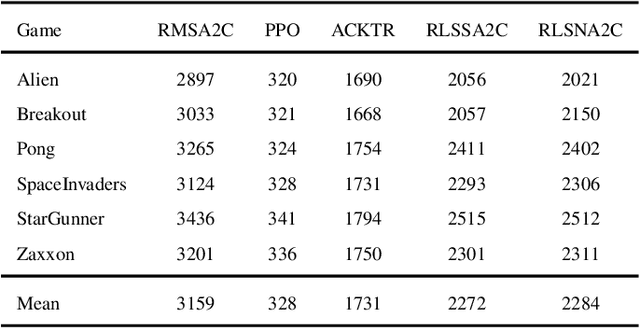
As an important algorithm in deep reinforcement learning, advantage actor critic (A2C) has been widely succeeded in both discrete and continuous control tasks with raw pixel inputs, but its sample efficiency still needs to improve more. In traditional reinforcement learning, actor-critic algorithms generally use the recursive least squares (RLS) technology to update the parameter of linear function approximators for accelerating their convergence speed. However, A2C algorithms seldom use this technology to train deep neural networks (DNNs) for improving their sample efficiency. In this paper, we propose two novel RLS-based A2C algorithms and investigate their performance. Both proposed algorithms, called RLSSA2C and RLSNA2C, use the RLS method to train the critic network and the hidden layers of the actor network. The main difference between them is at the policy learning step. RLSSA2C uses an ordinary first-order gradient descent algorithm and the standard policy gradient to learn the policy parameter. RLSNA2C uses the Kronecker-factored approximation, the RLS method and the natural policy gradient to learn the compatible parameter and the policy parameter. In addition, we analyze the complexity and convergence of both algorithms, and present three tricks for further improving their convergence speed. Finally, we demonstrate the effectiveness of both algorithms on 40 games in the Atari 2600 environment and 11 tasks in the MuJoCo environment. From the experimental results, it is shown that our both algorithms have better sample efficiency than the vanilla A2C on most games or tasks, and have higher computational efficiency than other two state-of-the-art algorithms.
Recursive Least Squares for Training and Pruning Convolutional Neural Networks
Jan 13, 2022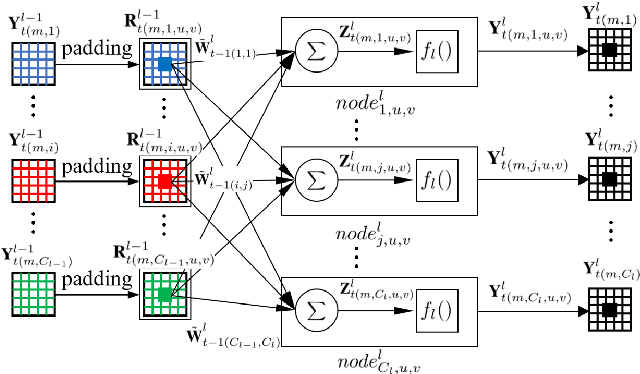
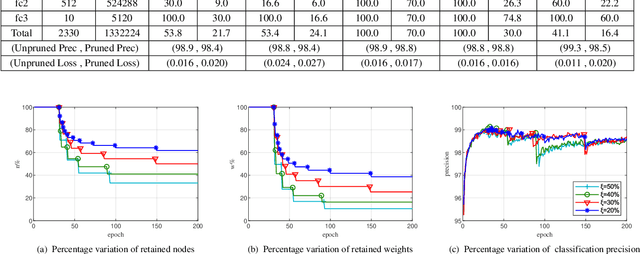
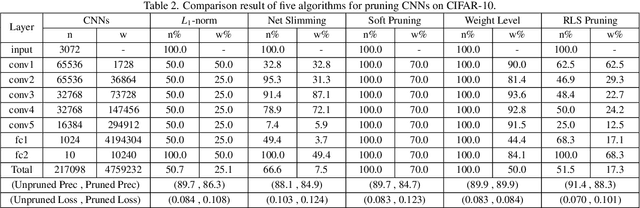
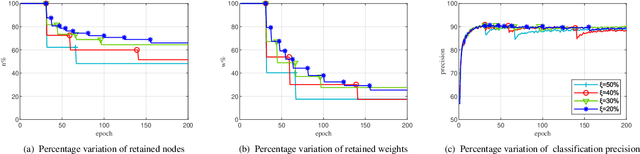
Convolutional neural networks (CNNs) have succeeded in many practical applications. However, their high computation and storage requirements often make them difficult to deploy on resource-constrained devices. In order to tackle this issue, many pruning algorithms have been proposed for CNNs, but most of them can't prune CNNs to a reasonable level. In this paper, we propose a novel algorithm for training and pruning CNNs based on the recursive least squares (RLS) optimization. After training a CNN for some epochs, our algorithm combines inverse input autocorrelation matrices and weight matrices to evaluate and prune unimportant input channels or nodes layer by layer. Then, our algorithm will continue to train the pruned network, and won't do the next pruning until the pruned network recovers the full performance of the old network. Besides for CNNs, the proposed algorithm can be used for feedforward neural networks (FNNs). Three experiments on MNIST, CIFAR-10 and SVHN datasets show that our algorithm can achieve the more reasonable pruning and have higher learning efficiency than other four popular pruning algorithms.
Distributionally Robust Semi-Supervised Learning Over Graphs
Oct 20, 2021
Semi-supervised learning (SSL) over graph-structured data emerges in many network science applications. To efficiently manage learning over graphs, variants of graph neural networks (GNNs) have been developed recently. By succinctly encoding local graph structures and features of nodes, state-of-the-art GNNs can scale linearly with the size of graph. Despite their success in practice, most of existing methods are unable to handle graphs with uncertain nodal attributes. Specifically whenever mismatches between training and testing data distribution exists, these models fail in practice. Challenges also arise due to distributional uncertainties associated with data acquired by noisy measurements. In this context, a distributionally robust learning framework is developed, where the objective is to train models that exhibit quantifiable robustness against perturbations. The data distribution is considered unknown, but lies within a Wasserstein ball centered around empirical data distribution. A robust model is obtained by minimizing the worst expected loss over this ball. However, solving the emerging functional optimization problem is challenging, if not impossible. Advocating a strong duality condition, we develop a principled method that renders the problem tractable and efficiently solvable. Experiments assess the performance of the proposed method.
RAGA: Relation-aware Graph Attention Networks for Global Entity Alignment
Mar 01, 2021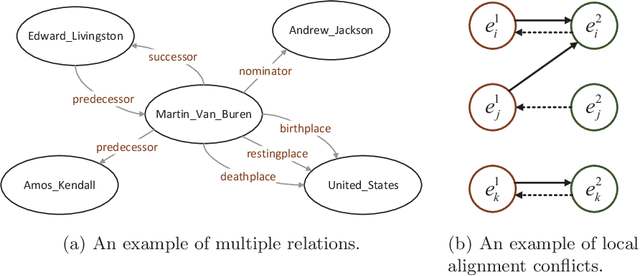
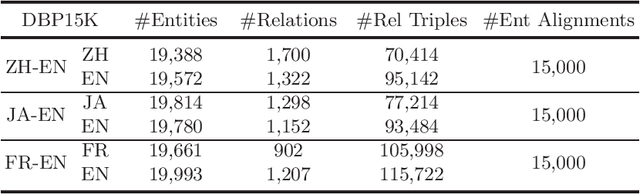
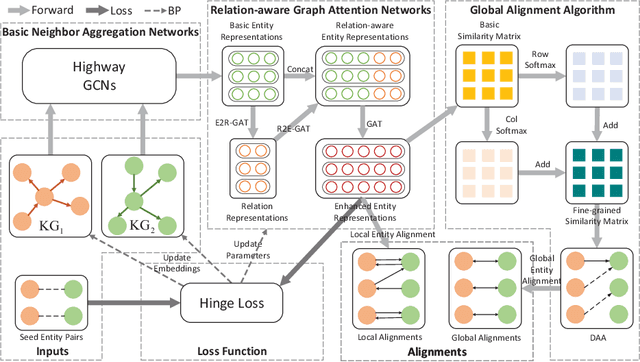

Entity alignment (EA) is the task to discover entities referring to the same real-world object from different knowledge graphs (KGs), which is the most crucial step in integrating multi-source KGs. The majority of the existing embeddings-based entity alignment methods embed entities and relations into a vector space based on relation triples of KGs for local alignment. As these methods insufficiently consider the multiple relations between entities, the structure information of KGs has not been fully leveraged. In this paper, we propose a novel framework based on Relation-aware Graph Attention Networks to capture the interactions between entities and relations. Our framework adopts the self-attention mechanism to spread entity information to the relations and then aggregate relation information back to entities. Furthermore, we propose a global alignment algorithm to make one-to-one entity alignments with a fine-grained similarity matrix. Experiments on three real-world cross-lingual datasets show that our framework outperforms the state-of-the-art methods.
BiTT: Bidirectional Tree Tagging for Joint Extraction of Overlapping Entities and Relations
Sep 07, 2020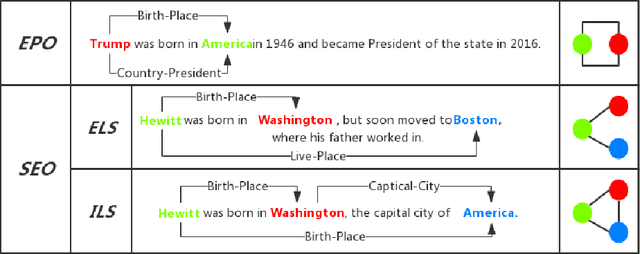
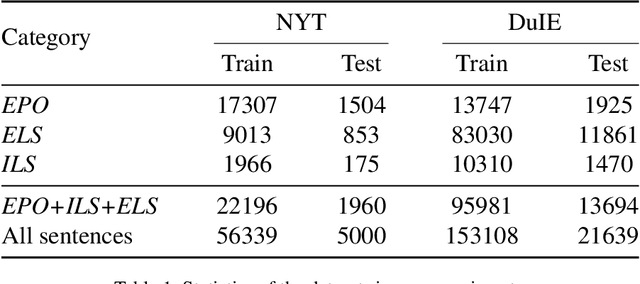
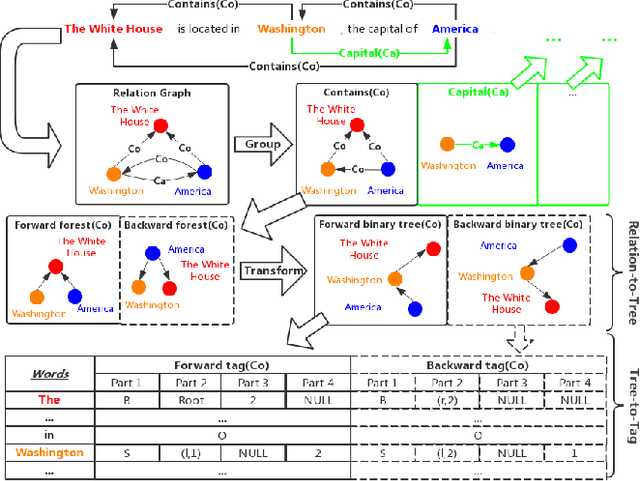
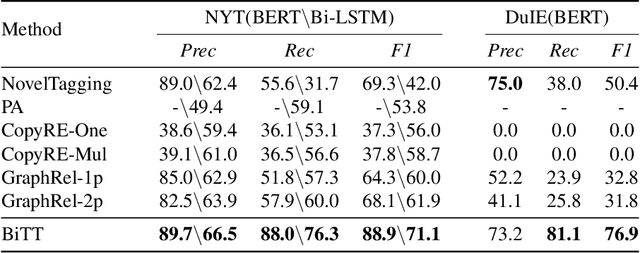
Joint extraction refers to extracting triples, composed of entities and relations, simultaneously from the text with a single model. However, most existing methods fail to extract all triples accurately and efficiently from sentences with overlapping issue, i.e., the same entity is included in multiple triples. In this paper, we propose a novel scheme called Bidirectional Tree Tagging (BiTT) to label overlapping triples in text. In BiTT, the triples with the same relation category in a sentence are especially represented as two binary trees, each of which is converted into a word-level tags sequence to label each word. Based on BiTT scheme, we develop an end-to-end extraction framework to predict the BiTT tags and further extract triples efficiently. We adopt the Bi-LSTM and the BERT as the encoder in our framework respectively, and obtain promising results in public English as well as Chinese datasets.
Learning while Respecting Privacy and Robustness to Distributional Uncertainties and Adversarial Data
Jul 07, 2020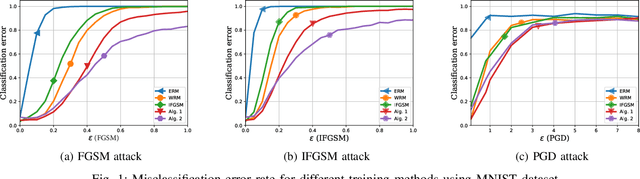
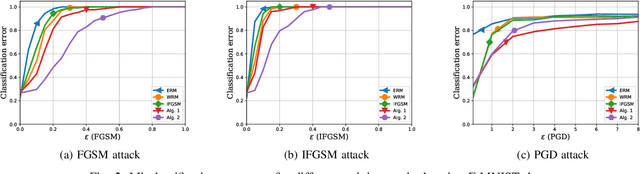
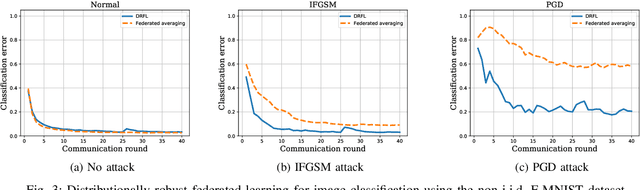
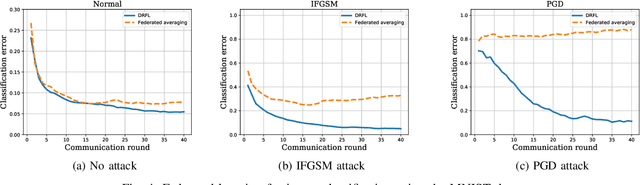
Data used to train machine learning models can be adversarial--maliciously constructed by adversaries to fool the model. Challenge also arises by privacy, confidentiality, or due to legal constraints when data are geographically gathered and stored across multiple learners, some of which may hold even an "anonymized" or unreliable dataset. In this context, the distributionally robust optimization framework is considered for training a parametric model, both in centralized and federated learning settings. The objective is to endow the trained model with robustness against adversarially manipulated input data, or, distributional uncertainties, such as mismatches between training and testing data distributions, or among datasets stored at different workers. To this aim, the data distribution is assumed unknown, and lies within a Wasserstein ball centered around the empirical data distribution. This robust learning task entails an infinite-dimensional optimization problem, which is challenging. Leveraging a strong duality result, a surrogate is obtained, for which three stochastic primal-dual algorithms are developed: i) stochastic proximal gradient descent with an $\epsilon$-accurate oracle, which invokes an oracle to solve the convex sub-problems; ii) stochastic proximal gradient descent-ascent, which approximates the solution of the convex sub-problems via a single gradient ascent step; and, iii) a distributionally robust federated learning algorithm, which solves the sub-problems locally at different workers where data are stored. Compared to the empirical risk minimization and federated learning methods, the proposed algorithms offer robustness with little computation overhead. Numerical tests using image datasets showcase the merits of the proposed algorithms under several existing adversarial attacks and distributional uncertainties.
Gate Decorator: Global Filter Pruning Method for Accelerating Deep Convolutional Neural Networks
Sep 18, 2019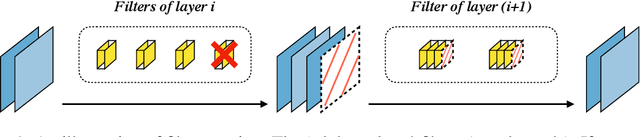

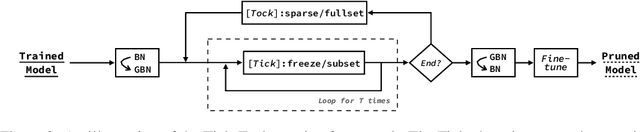
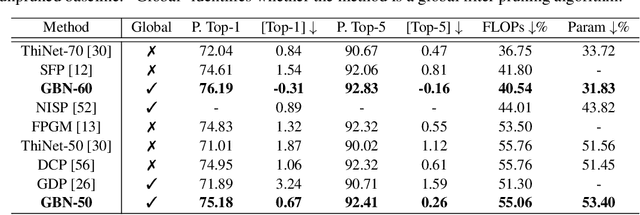
Filter pruning is one of the most effective ways to accelerate and compress convolutional neural networks (CNNs). In this work, we propose a global filter pruning algorithm called Gate Decorator, which transforms a vanilla CNN module by multiplying its output by the channel-wise scaling factors, i.e. gate. When the scaling factor is set to zero, it is equivalent to removing the corresponding filter. We use Taylor expansion to estimate the change in the loss function caused by setting the scaling factor to zero and use the estimation for the global filter importance ranking. Then we prune the network by removing those unimportant filters. After pruning, we merge all the scaling factors into its original module, so no special operations or structures are introduced. Moreover, we propose an iterative pruning framework called Tick-Tock to improve pruning accuracy. The extensive experiments demonstrate the effectiveness of our approaches. For example, we achieve the state-of-the-art pruning ratio on ResNet-56 by reducing 70% FLOPs without noticeable loss in accuracy. For ResNet-50 on ImageNet, our pruned model with 40% FLOPs reduction outperforms the baseline model by 0.31% in top-1 accuracy. Various datasets are used, including CIFAR-10, CIFAR-100, CUB-200, ImageNet ILSVRC-12 and PASCAL VOC 2011. Code is available at github.com/youzhonghui/gate-decorator-pruning