 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Policy-Adaptive Image Guardrail: Benchmark and Method
Mar 01, 2026Accurate rejection of sensitive or harmful visual content, i.e., harmful image guardrail, is critical in many application scenarios. This task must continuously adapt to the evolving safety policies and content across various domains and over time. However, traditional classifiers, confined to fixed categories, require frequent retraining when new policies are introduced. Vision-language models (VLMs) offer a more adaptable and generalizable foundation for dynamic safety guardrails. Despite this potential, existing VLM-based safeguarding methods are typically trained and evaluated under only a fixed safety policy. We find that these models are heavily overfitted to the seen policy, fail to generalize to unseen policies, and even lose the basic instruction-following ability and general knowledge. To address this issue, in this paper we make two key contributions. First, we benchmark the cross-policy generalization performance of existing VLMs with SafeEditBench, a new evaluation suite. SafeEditBench leverages image-editing models to convert unsafe images into safe counterparts, producing policy-aligned datasets where each safe-unsafe image pair remains visually similar except for localized regions violating specific safety rules. Human annotators then provide accurate safe/unsafe labels under five distinct policies, enabling fine-grained assessment of policy-aware generalization. Second, we introduce SafeGuard-VL, a reinforcement learning-based method with verifiable rewards (RLVR) for robust unsafe-image guardrails. Instead of relying solely on supervised fine-tuning (SFT) under fixed policies, SafeGuard-VL explicitly optimizes the model with policy-grounded rewards, promoting verifiable adaptation across evolving policies. Extensive experiments verify the effectiveness of our method for unsafe image guardrails across various policies.
DyFo: A Training-Free Dynamic Focus Visual Search for Enhancing LMMs in Fine-Grained Visual Understanding
Apr 21, 2025



Humans can effortlessly locate desired objects in cluttered environments, relying on a cognitive mechanism known as visual search to efficiently filter out irrelevant information and focus on task-related regions. Inspired by this process, we propose Dyfo (Dynamic Focus), a training-free dynamic focusing visual search method that enhances fine-grained visual understanding in large multimodal models (LMMs). Unlike existing approaches which require additional modules or data collection, Dyfo leverages a bidirectional interaction between LMMs and visual experts, using a Monte Carlo Tree Search (MCTS) algorithm to simulate human-like focus adjustments. This enables LMMs to focus on key visual regions while filtering out irrelevant content, without introducing additional training caused by vocabulary expansion or the integration of specialized localization modules. Experimental results demonstrate that Dyfo significantly improves fine-grained visual understanding and reduces hallucination issues in LMMs, achieving superior performance across both fixed and dynamic resolution models. The code is available at https://github.com/PKU-ICST-MIPL/DyFo_CVPR2025
Two-stream Collaborative Learning with Spatial-Temporal Attention for Video Classification
Nov 09, 2017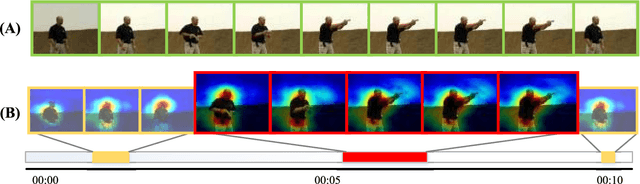
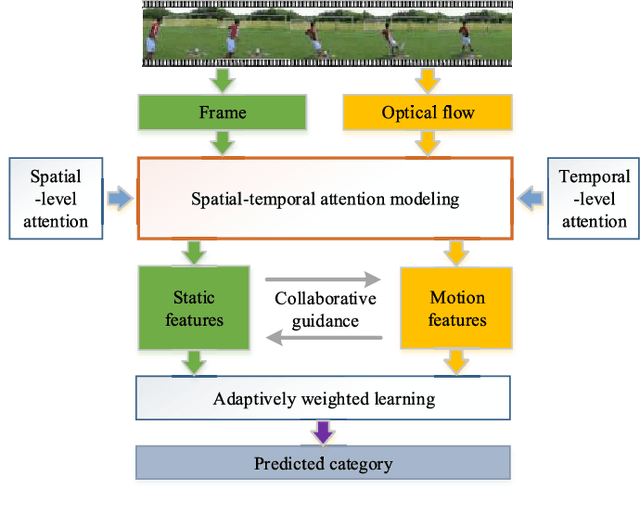
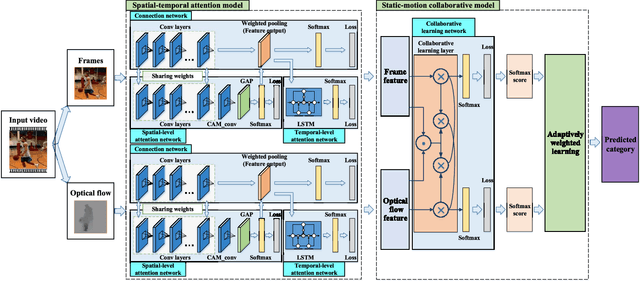

Video classification is highly important with wide applications, such as video search and intelligent surveillance. Video naturally consists of static and motion information, which can be represented by frame and optical flow. Recently, researchers generally adopt the deep networks to capture the static and motion information \textbf{\emph{separately}}, which mainly has two limitations: (1) Ignoring the coexistence relationship between spatial and temporal attention, while they should be jointly modelled as the spatial and temporal evolutions of video, thus discriminative video features can be extracted.(2) Ignoring the strong complementarity between static and motion information coexisted in video, while they should be collaboratively learned to boost each other. For addressing the above two limitations, this paper proposes the approach of two-stream collaborative learning with spatial-temporal attention (TCLSTA), which consists of two models: (1) Spatial-temporal attention model: The spatial-level attention emphasizes the salient regions in frame, and the temporal-level attention exploits the discriminative frames in video. They are jointly learned and mutually boosted to learn the discriminative static and motion features for better classification performance. (2) Static-motion collaborative model: It not only achieves mutual guidance on static and motion information to boost the feature learning, but also adaptively learns the fusion weights of static and motion streams, so as to exploit the strong complementarity between static and motion information to promote video classification. Experiments on 4 widely-used datasets show that our TCLSTA approach achieves the best performance compared with more than 10 state-of-the-art methods.
Saliency-guided video classification via adaptively weighted learning
Mar 26, 2017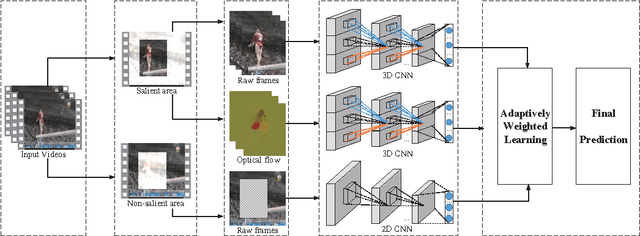

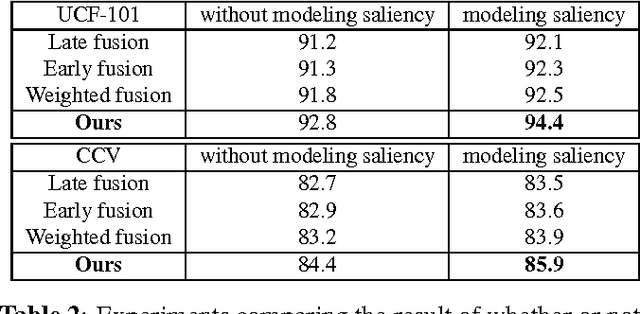
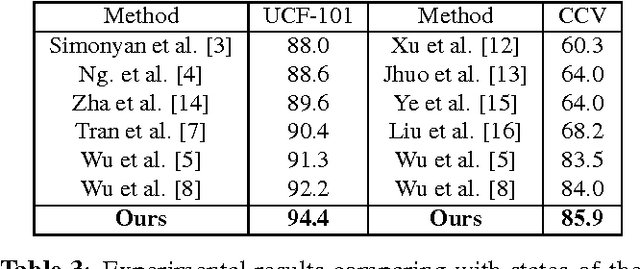
Video classification is productive in many practical applications, and the recent deep learning has greatly improved its accuracy. However, existing works often model video frames indiscriminately, but from the view of motion, video frames can be decomposed into salient and non-salient areas naturally. Salient and non-salient areas should be modeled with different networks, for the former present both appearance and motion information, and the latter present static background information. To address this problem, in this paper, video saliency is predicted by optical flow without supervision firstly. Then two streams of 3D CNN are trained individually for raw frames and optical flow on salient areas, and another 2D CNN is trained for raw frames on non-salient areas. For the reason that these three streams play different roles for each class, the weights of each stream are adaptively learned for each class. Experimental results show that saliency-guided modeling and adaptively weighted learning can reinforce each other, and we achieve the state-of-the-art results.