 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere and How: Mitigating Confusion in Neural Radiance Fields from Sparse Inputs
Aug 05, 2023Neural Radiance Fields from Sparse input} (NeRF-S) have shown great potential in synthesizing novel views with a limited number of observed viewpoints. However, due to the inherent limitations of sparse inputs and the gap between non-adjacent views, rendering results often suffer from over-fitting and foggy surfaces, a phenomenon we refer to as "CONFUSION" during volume rendering. In this paper, we analyze the root cause of this confusion and attribute it to two fundamental questions: "WHERE" and "HOW". To this end, we present a novel learning framework, WaH-NeRF, which effectively mitigates confusion by tackling the following challenges: (i)"WHERE" to Sample? in NeRF-S -- we introduce a Deformable Sampling strategy and a Weight-based Mutual Information Loss to address sample-position confusion arising from the limited number of viewpoints; and (ii) "HOW" to Predict? in NeRF-S -- we propose a Semi-Supervised NeRF learning Paradigm based on pose perturbation and a Pixel-Patch Correspondence Loss to alleviate prediction confusion caused by the disparity between training and testing viewpoints. By integrating our proposed modules and loss functions, WaH-NeRF outperforms previous methods under the NeRF-S setting. Code is available https://github.com/bbbbby-99/WaH-NeRF.
A Unified Framework for Contrastive Learning from a Perspective of Affinity Matrix
Nov 26, 2022In recent years, a variety of contrastive learning based unsupervised visual representation learning methods have been designed and achieved great success in many visual tasks. Generally, these methods can be roughly classified into four categories: (1) standard contrastive methods with an InfoNCE like loss, such as MoCo and SimCLR; (2) non-contrastive methods with only positive pairs, such as BYOL and SimSiam; (3) whitening regularization based methods, such as W-MSE and VICReg; and (4) consistency regularization based methods, such as CO2. In this study, we present a new unified contrastive learning representation framework (named UniCLR) suitable for all the above four kinds of methods from a novel perspective of basic affinity matrix. Moreover, three variants, i.e., SimAffinity, SimWhitening and SimTrace, are presented based on UniCLR. In addition, a simple symmetric loss, as a new consistency regularization term, is proposed based on this framework. By symmetrizing the affinity matrix, we can effectively accelerate the convergence of the training process. Extensive experiments have been conducted to show that (1) the proposed UniCLR framework can achieve superior results on par with and even be better than the state of the art, (2) the proposed symmetric loss can significantly accelerate the convergence of models, and (3) SimTrace can avoid the mode collapse problem by maximizing the trace of a whitened affinity matrix without relying on asymmetry designs or stop-gradients.
Modeling Inter-Class and Intra-Class Constraints in Novel Class Discovery
Oct 07, 2022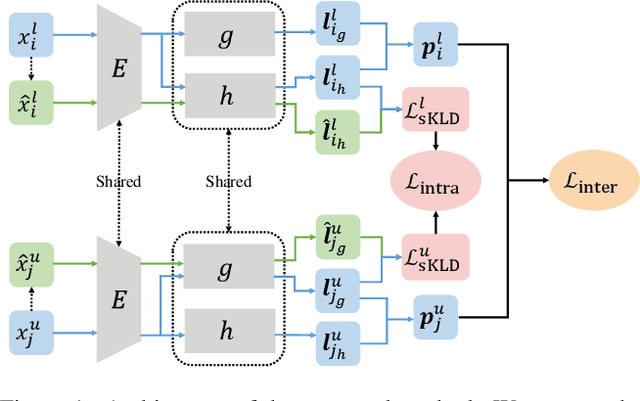
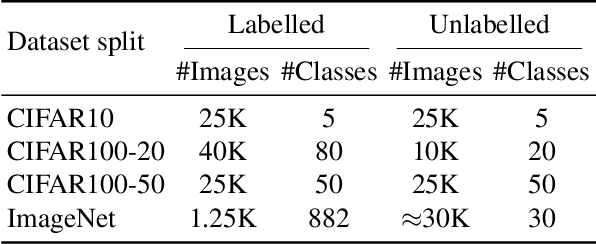
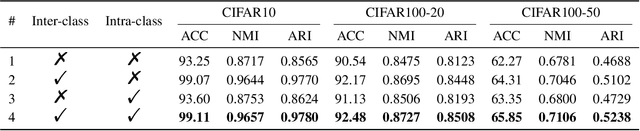
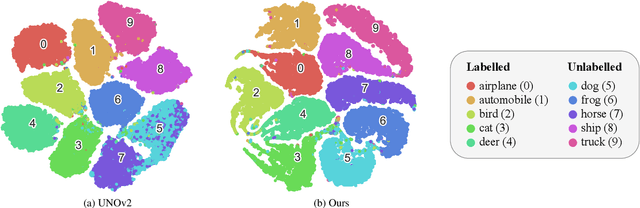
Novel class discovery (NCD) aims at learning a model that transfers the common knowledge from a class-disjoint labelled dataset to another unlabelled dataset and discovers new classes (clusters) within it. Many methods have been proposed as well as elaborate training pipelines and appropriate objectives and considerably boosted the performance on NCD tasks. Despite all this, we find that the existing methods do not sufficiently take advantage of the essence of the NCD setting. To this end, in this paper, we propose to model both inter-class and intra-class constraints in NCD based on the symmetric Kullback-Leibler divergence (sKLD). Specifically, we propose an inter-class sKLD constraint to effectively exploit the disjoint relationship between labelled and unlabelled classes, enforcing the separability for different classes in the embedding space. In addition, we present an intra-class sKLD constraint to explicitly constrain the intra-relationship between samples and their augmentations and ensure the stability of the training process at the same time. We conduct extensive experiments on the popular CIFAR10, CIFAR100 and ImageNet benchmarks and successfully demonstrate that our method can establish a new state of the art and can achieve significantly performance improvements, e.g., $3.6\%$/$7.9\%$ clustering accuracy improvements on CIFAR100-50 under the task-aware/-agnostic evaluation protocol, over previous state-of-the-art methods.
Playing Lottery Tickets in Style Transfer Models
Apr 10, 2022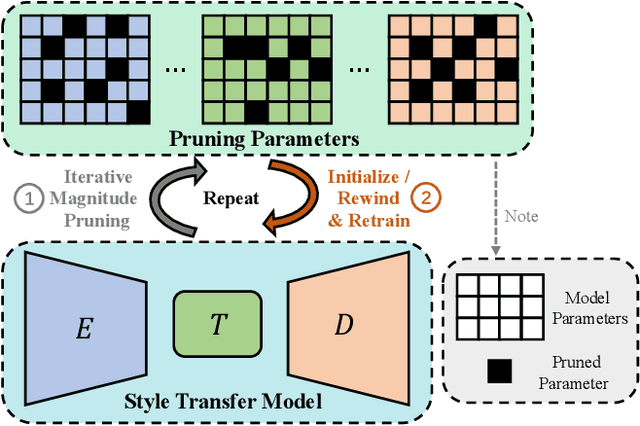
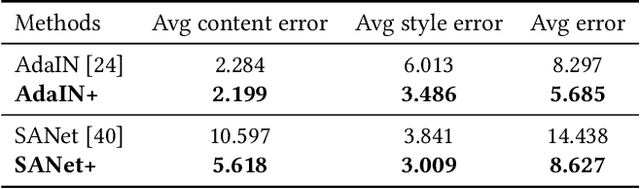

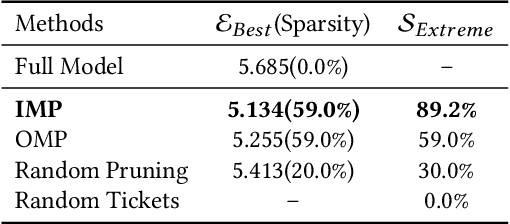
Style transfer has achieved great success and attracted a wide range of attention from both academic and industrial communities due to its flexible application scenarios. However, the dependence on a pretty large VGG-based autoencoder leads to existing style transfer models having high parameter complexities, which limits their applications on resource-constrained devices. Compared with many other tasks, the compression of style transfer models has been less explored. Recently, the lottery ticket hypothesis (LTH) has shown great potential in finding extremely sparse matching subnetworks which can achieve on par or even better performance than the original full networks when trained in isolation. In this work, we for the first time perform an empirical study to verify whether such trainable matching subnetworks also exist in style transfer models. Specifically, we take two most popular style transfer models, i.e., AdaIN and SANet, as the main testbeds, which represent global and local transformation based style transfer methods respectively. We carry out extensive experiments and comprehensive analysis, and draw the following conclusions. (1) Compared with fixing the VGG encoder, style transfer models can benefit more from training the whole network together. (2) Using iterative magnitude pruning, we find the matching subnetworks at 89.2% sparsity in AdaIN and 73.7% sparsity in SANet, which demonstrates that style transfer models can play lottery tickets too. (3) The feature transformation module should also be pruned to obtain a much sparser model without affecting the existence and quality of the matching subnetworks. (4) Besides AdaIN and SANet, other models such as LST, MANet, AdaAttN and MCCNet can also play lottery tickets, which shows that LTH can be generalized to various style transfer models.
LibFewShot: A Comprehensive Library for Few-shot Learning
Sep 10, 2021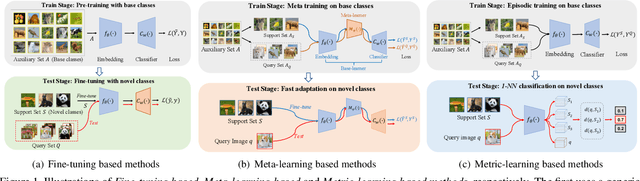
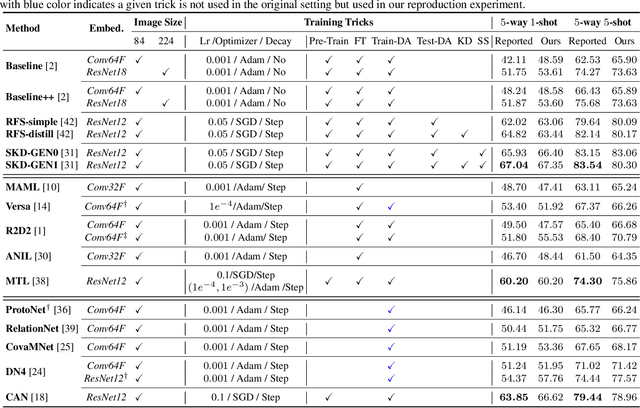
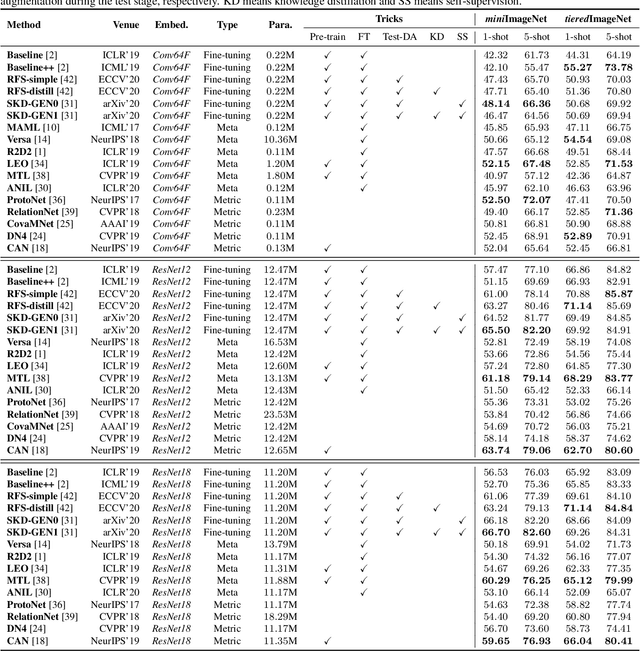
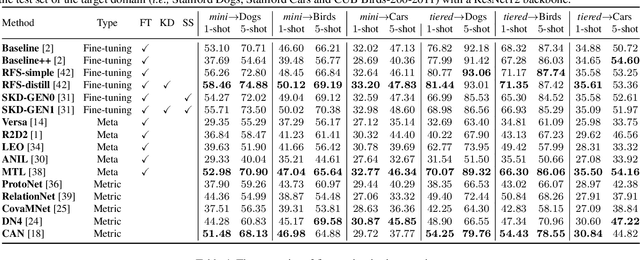
Few-shot learning, especially few-shot image classification, has received increasing attention and witnessed significant advances in recent years. Some recent studies implicitly show that many generic techniques or ``tricks'', such as data augmentation, pre-training, knowledge distillation, and self-supervision, may greatly boost the performance of a few-shot learning method. Moreover, different works may employ different software platforms, different training schedules, different backbone architectures and even different input image sizes, making fair comparisons difficult and practitioners struggle with reproducibility. To address these situations, we propose a comprehensive library for few-shot learning (LibFewShot) by re-implementing seventeen state-of-the-art few-shot learning methods in a unified framework with the same single codebase in PyTorch. Furthermore, based on LibFewShot, we provide comprehensive evaluations on multiple benchmark datasets with multiple backbone architectures to evaluate common pitfalls and effects of different training tricks. In addition, given the recent doubts on the necessity of meta- or episodic-training mechanism, our evaluation results show that such kind of mechanism is still necessary especially when combined with pre-training. We hope our work can not only lower the barriers for beginners to work on few-shot learning but also remove the effects of the nontrivial tricks to facilitate intrinsic research on few-shot learning. The source code is available from https://github.com/RL-VIG/LibFewShot.
Triplet is All You Need with Random Mappings for Unsupervised Visual Representation Learning
Jul 22, 2021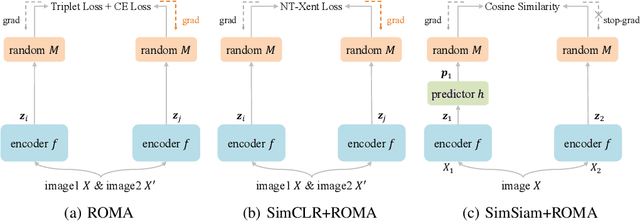
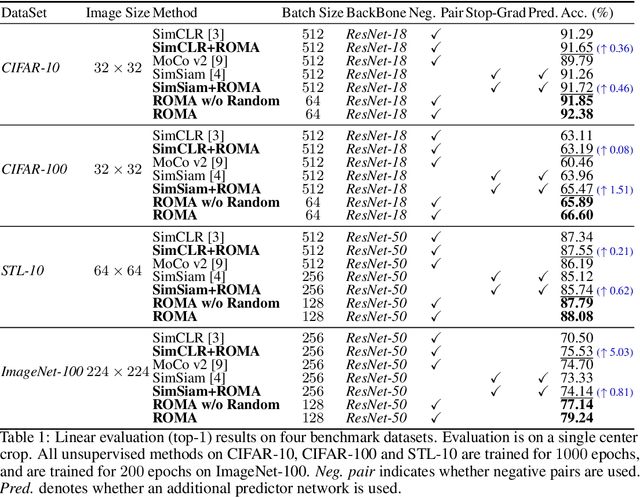
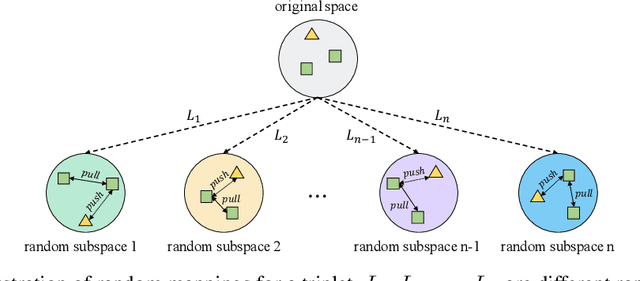

Contrastive self-supervised learning (SSL) has achieved great success in unsupervised visual representation learning by maximizing the similarity between two augmented views of the same image (positive pairs) and simultaneously contrasting other different images (negative pairs). However, this type of methods, such as SimCLR and MoCo, relies heavily on a large number of negative pairs and thus requires either large batches or memory banks. In contrast, some recent non-contrastive SSL methods, such as BYOL and SimSiam, attempt to discard negative pairs by introducing asymmetry and show remarkable performance. Unfortunately, to avoid collapsed solutions caused by not using negative pairs, these methods require sophisticated asymmetry designs. In this paper, we argue that negative pairs are still necessary but one is sufficient, i.e., triplet is all you need. A simple triplet-based loss can achieve surprisingly good performance without requiring large batches or asymmetry. Moreover, we observe that unsupervised visual representation learning can gain significantly from randomness. Based on this observation, we propose a simple plug-in RandOm MApping (ROMA) strategy by randomly mapping samples into other spaces and enforcing these randomly projected samples to satisfy the same correlation requirement. The proposed ROMA strategy not only achieves the state-of-the-art performance in conjunction with the triplet-based loss, but also can further effectively boost other SSL methods.
Cross-Modality Brain Tumor Segmentation via Bidirectional Global-to-Local Unsupervised Domain Adaptation
May 17, 2021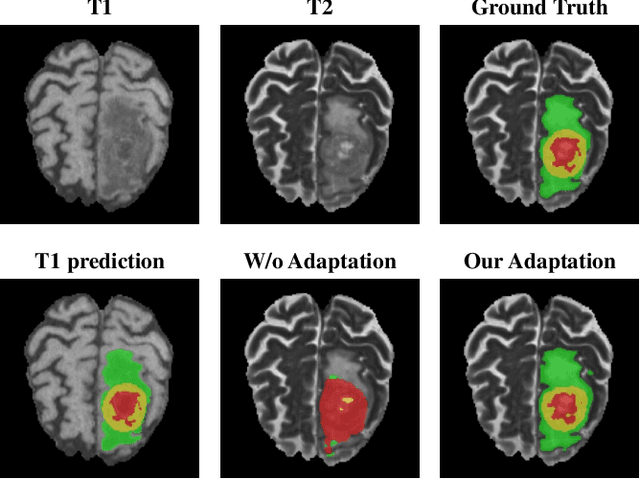
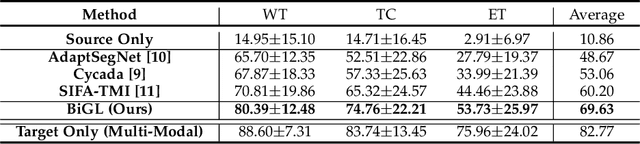
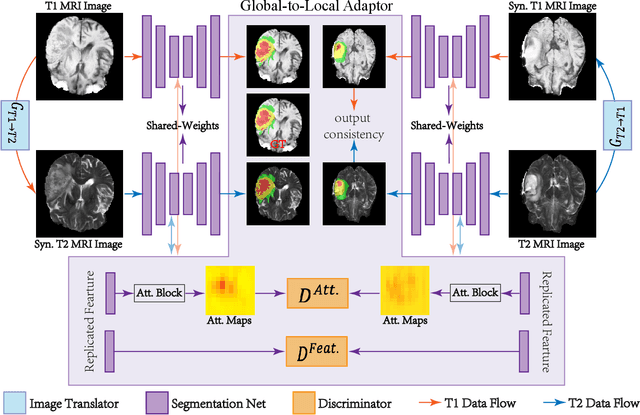
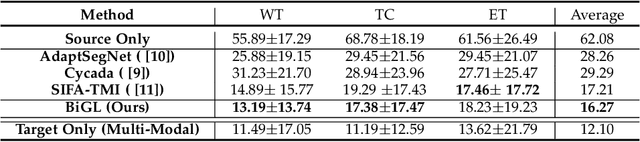
Accurate segmentation of brain tumors from multi-modal Magnetic Resonance (MR) images is essential in brain tumor diagnosis and treatment. However, due to the existence of domain shifts among different modalities, the performance of networks decreases dramatically when training on one modality and performing on another, e.g., train on T1 image while performing on T2 image, which is often required in clinical applications. This also prohibits a network from being trained on labeled data and then transferred to unlabeled data from a different domain. To overcome this, unsupervised domain adaptation (UDA) methods provide effective solutions to alleviate the domain shift between labeled source data and unlabeled target data. In this paper, we propose a novel Bidirectional Global-to-Local (BiGL) adaptation framework under a UDA scheme. Specifically, a bidirectional image synthesis and segmentation module is proposed to segment the brain tumor using the intermediate data distributions generated for the two domains, which includes an image-to-image translator and a shared-weighted segmentation network. Further, a global-to-local consistency learning module is proposed to build robust representation alignments in an integrated way. Extensive experiments on a multi-modal brain MR benchmark dataset demonstrate that the proposed method outperforms several state-of-the-art unsupervised domain adaptation methods by a large margin, while a comprehensive ablation study validates the effectiveness of each key component. The implementation code of our method will be released at \url{https://github.com/KeleiHe/BiGL}.
CariMe: Unpaired Caricature Generation with Multiple Exaggerations
Oct 01, 2020



Caricature generation aims to translate real photos into caricatures with artistic styles and shape exaggerations while maintaining the identity of the subject. Different from the generic image-to-image translation, drawing a caricature automatically is a more challenging task due to the existence of various spacial deformations. Previous caricature generation methods are obsessed with predicting definite image warping from a given photo while ignoring the intrinsic representation and distribution for exaggerations in caricatures. This limits their ability on diverse exaggeration generation. In this paper, we generalize the caricature generation problem from instance-level warping prediction to distribution-level deformation modeling. Based on this assumption, we present the first exploration for unpaired CARIcature generation with Multiple Exaggerations (CariMe). Technically, we propose a Multi-exaggeration Warper network to learn the distribution-level mapping from photo to facial exaggerations. This makes it possible to generate diverse and reasonable exaggerations from randomly sampled warp codes given one input photo. To better represent the facial exaggeration and produce fine-grained warping, a deformation-field-based warping method is also proposed, which helps us to capture more detailed exaggerations than other point-based warping methods. Experiments and two perceptual studies prove the superiority of our method comparing with other state-of-the-art methods, showing the improvement of our work on caricature generation.
Unsupervised Domain Attention Adaptation Network for Caricature Attribute Recognition
Jul 18, 2020
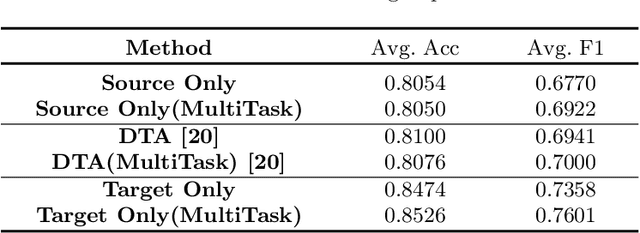
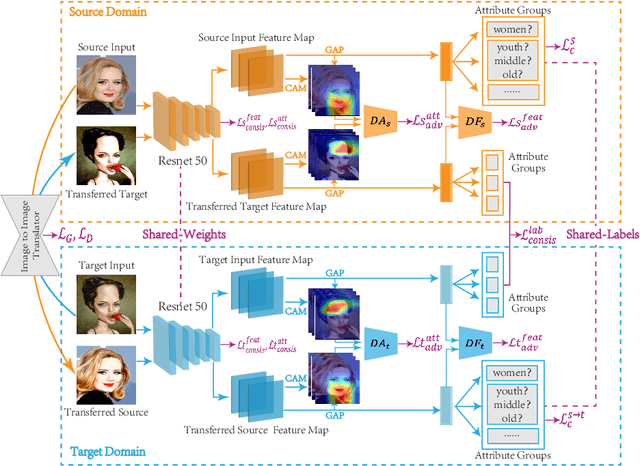
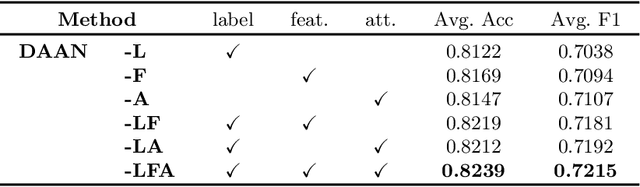
Caricature attributes provide distinctive facial features to help research in Psychology and Neuroscience. However, unlike the facial photo attribute datasets that have a quantity of annotated images, the annotations of caricature attributes are rare. To facility the research in attribute learning of caricatures, we propose a caricature attribute dataset, namely WebCariA. Moreover, to utilize models that trained by face attributes, we propose a novel unsupervised domain adaptation framework for cross-modality (i.e., photos to caricatures) attribute recognition, with an integrated inter- and intra-domain consistency learning scheme. Specifically, the inter-domain consistency learning scheme consisting an image-to-image translator to first fill the domain gap between photos and caricatures by generating intermediate image samples, and a label consistency learning module to align their semantic information. The intra-domain consistency learning scheme integrates the common feature consistency learning module with a novel attribute-aware attention-consistency learning module for a more efficient alignment. We did an extensive ablation study to show the effectiveness of the proposed method. And the proposed method also outperforms the state-of-the-art methods by a margin. The implementation of the proposed method is available at https://github.com/KeleiHe/DAAN.
Manifold Alignment for Semantically Aligned Style Transfer
May 21, 2020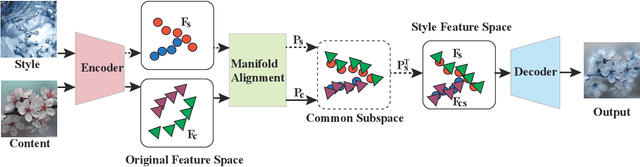
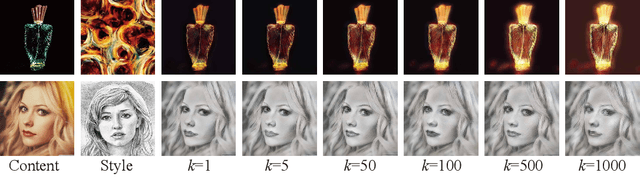
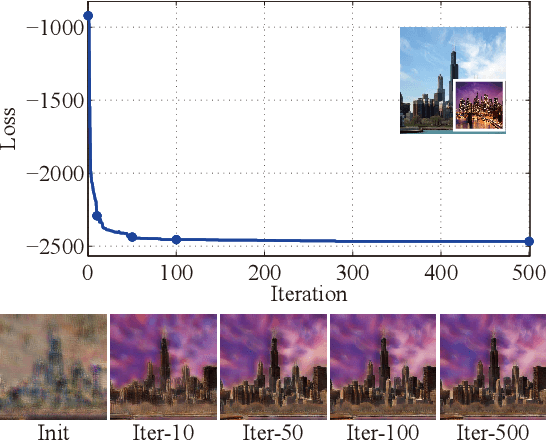

Given a content image and a style image, the goal of style transfer is to synthesize an output image by transferring the target style to the content image. Currently, most of the methods address the problem with global style transfer, assuming styles can be represented by global statistics, such as Gram matrices or covariance matrices. In this paper, we make a different assumption that local semantically aligned (or similar) regions between the content and style images should share similar style patterns. Based on this assumption, content features and style features are seen as two sets of manifolds and a manifold alignment based style transfer (MAST) method is proposed. MAST is a subspace learning method which learns a common subspace of the content and style features. In the common subspace, content and style features with larger feature similarity or the same semantic meaning are forced to be close. The learned projection matrices are added with orthogonality constraints so that the mapping can be bidirectional, which allows us to project the content features into the common subspace, and then into the original style space. By using a pre-trained decoder, promising stylized images are obtained. The method is further extended to allow users to specify corresponding semantic regions between content and style images or using semantic segmentation maps as guidance. Extensive experiments show the proposed MAST achieves appealing results in style transfer.