 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
Derain-Agent: A Plug-and-Play Agent Framework for Rainy Image Restoration
Mar 12, 2026While deep learning has advanced single-image deraining, existing models suffer from a fundamental limitation: they employ a static inference paradigm that fails to adapt to the complex, coupled degradations (e.g., noise artifacts, blur, and color deviation) of real-world rain. Consequently, restored images often exhibit residual artifacts and inconsistent perceptual quality. In this work, we present Derain-Agent, a plug-and-play refinement framework that transitions deraining from static processing to dynamic, agent-based restoration. Derain-Agent equips a base deraining model with two core capabilities: 1) a Planning Network that intelligently schedules an optimal sequence of restoration tools for each instance, and 2) a Strength Modulation mechanism that applies these tools with spatially adaptive intensity. This design enables precise, region-specific correction of residual errors without the prohibitive cost of iterative search. Our method demonstrates strong generalization, consistently boosting the performance of state-of-the-art deraining models on both synthetic and real-world benchmarks.
Semantics and Content Matter: Towards Multi-Prior Hierarchical Mamba for Image Deraining
Nov 17, 2025Rain significantly degrades the performance of computer vision systems, particularly in applications like autonomous driving and video surveillance. While existing deraining methods have made considerable progress, they often struggle with fidelity of semantic and spatial details. To address these limitations, we propose the Multi-Prior Hierarchical Mamba (MPHM) network for image deraining. This novel architecture synergistically integrates macro-semantic textual priors (CLIP) for task-level semantic guidance and micro-structural visual priors (DINOv2) for scene-aware structural information. To alleviate potential conflicts between heterogeneous priors, we devise a progressive Priors Fusion Injection (PFI) that strategically injects complementary cues at different decoder levels. Meanwhile, we equip the backbone network with an elaborate Hierarchical Mamba Module (HMM) to facilitate robust feature representation, featuring a Fourier-enhanced dual-path design that concurrently addresses global context modeling and local detail recovery. Comprehensive experiments demonstrate MPHM's state-of-the-art performance, achieving a 0.57 dB PSNR gain on the Rain200H dataset while delivering superior generalization on real-world rainy scenarios.
Always Clear Depth: Robust Monocular Depth Estimation under Adverse Weather
May 18, 2025
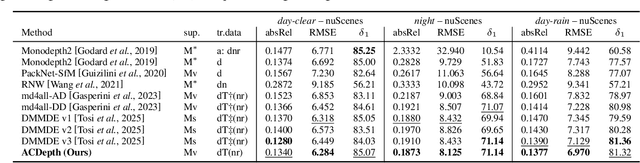
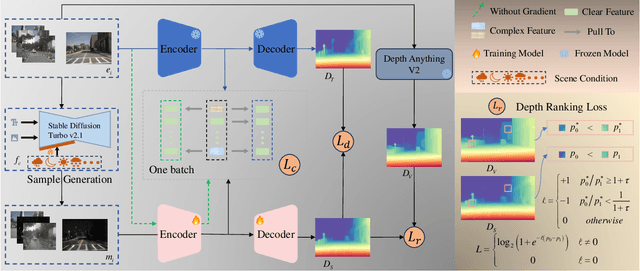
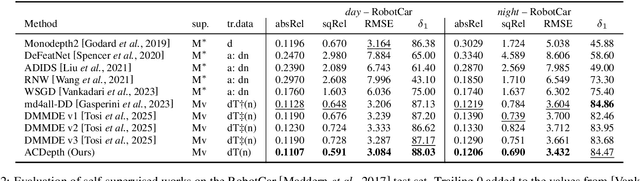
Monocular depth estimation is critical for applications such as autonomous driving and scene reconstruction. While existing methods perform well under normal scenarios, their performance declines in adverse weather, due to challenging domain shifts and difficulties in extracting scene information. To address this issue, we present a robust monocular depth estimation method called \textbf{ACDepth} from the perspective of high-quality training data generation and domain adaptation. Specifically, we introduce a one-step diffusion model for generating samples that simulate adverse weather conditions, constructing a multi-tuple degradation dataset during training. To ensure the quality of the generated degradation samples, we employ LoRA adapters to fine-tune the generation weights of diffusion model. Additionally, we integrate circular consistency loss and adversarial training to guarantee the fidelity and naturalness of the scene contents. Furthermore, we elaborate on a multi-granularity knowledge distillation strategy (MKD) that encourages the student network to absorb knowledge from both the teacher model and pretrained Depth Anything V2. This strategy guides the student model in learning degradation-agnostic scene information from various degradation inputs. In particular, we introduce an ordinal guidance distillation mechanism (OGD) that encourages the network to focus on uncertain regions through differential ranking, leading to a more precise depth estimation. Experimental results demonstrate that our ACDepth surpasses md4all-DD by 2.50\% for night scene and 2.61\% for rainy scene on the nuScenes dataset in terms of the absRel metric.