 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeVLBert: Learning Deconfounded Visio-Linguistic Representations
Aug 16, 2020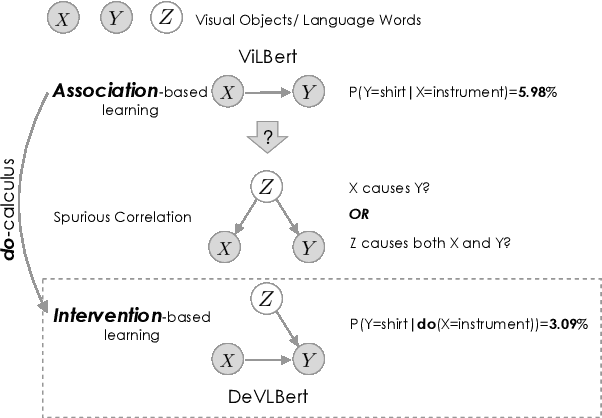
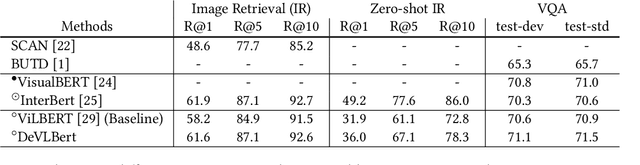
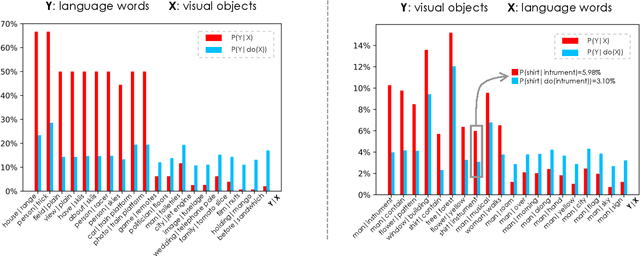
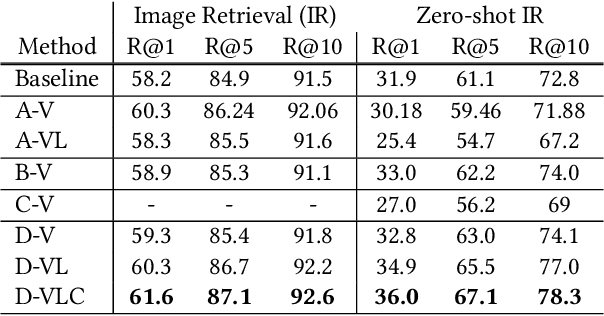
In this paper, we propose to investigate the problem of out-of-domain visio-linguistic pretraining, where the pretraining data distribution differs from that of downstream data on which the pretrained model will be fine-tuned. Existing methods for this problem are purely likelihood-based, leading to the spurious correlations and hurt the generalization ability when transferred to out-of-domain downstream tasks. By spurious correlation, we mean that the conditional probability of one token (object or word) given another one can be high (due to the dataset biases) without robust (causal) relationships between them. To mitigate such dataset biases, we propose a Deconfounded Visio-Linguistic Bert framework, abbreviated as DeVLBert, to perform intervention-based learning. We borrow the idea of the backdoor adjustment from the research field of causality and propose several neural-network based architectures for Bert-style out-of-domain pretraining. The quantitative results on three downstream tasks, Image Retrieval (IR), Zero-shot IR, and Visual Question Answering, show the effectiveness of DeVLBert by boosting generalization ability.
Poet: Product-oriented Video Captioner for E-commerce
Aug 16, 2020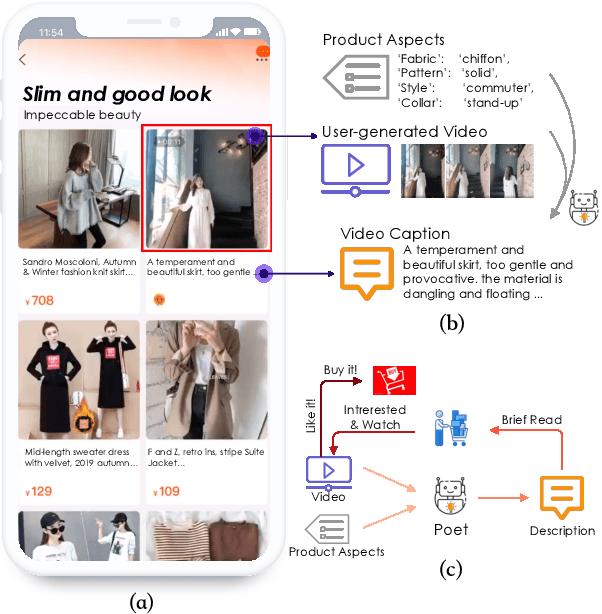
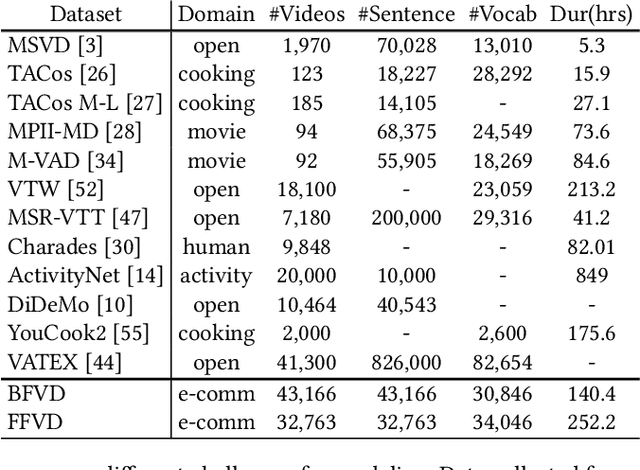
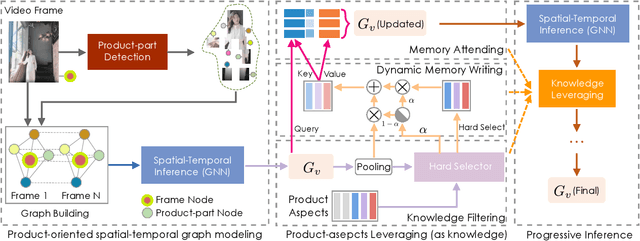
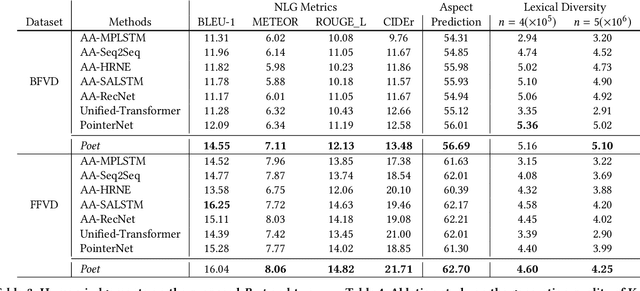
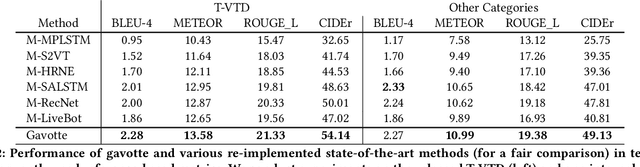
In e-commerce, a growing number of user-generated videos are used for product promotion. How to generate video descriptions that narrate the user-preferred product characteristics depicted in the video is vital for successful promoting. Traditional video captioning methods, which focus on routinely describing what exists and happens in a video, are not amenable for product-oriented video captioning. To address this problem, we propose a product-oriented video captioner framework, abbreviated as Poet. Poet firstly represents the videos as product-oriented spatial-temporal graphs. Then, based on the aspects of the video-associated product, we perform knowledge-enhanced spatial-temporal inference on those graphs for capturing the dynamic change of fine-grained product-part characteristics. The knowledge leveraging module in Poet differs from the traditional design by performing knowledge filtering and dynamic memory modeling. We show that Poet achieves consistent performance improvement over previous methods concerning generation quality, product aspects capturing, and lexical diversity. Experiments are performed on two product-oriented video captioning datasets, buyer-generated fashion video dataset (BFVD) and fan-generated fashion video dataset (FFVD), collected from Mobile Taobao. We will release the desensitized datasets to promote further investigations on both video captioning and general video analysis problems.
A Multi-Semantic Metapath Model for Large Scale Heterogeneous Network Representation Learning
Jul 19, 2020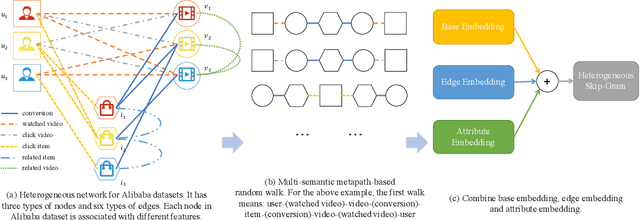
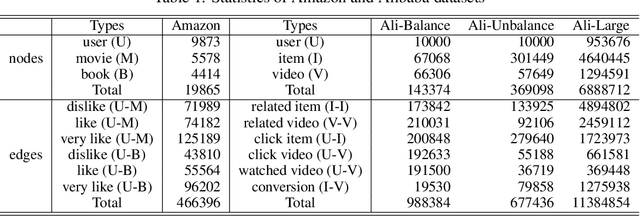
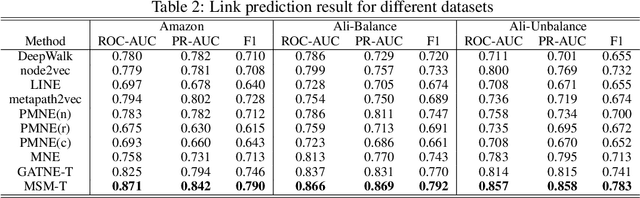

Network Embedding has been widely studied to model and manage data in a variety of real-world applications. However, most existing works focus on networks with single-typed nodes or edges, with limited consideration of unbalanced distributions of nodes and edges. In real-world applications, networks usually consist of billions of various types of nodes and edges with abundant attributes. To tackle these challenges, in this paper we propose a multi-semantic metapath (MSM) model for large scale heterogeneous representation learning. Specifically, we generate multi-semantic metapath-based random walks to construct the heterogeneous neighborhood to handle the unbalanced distributions and propose a unified framework for the embedding learning. We conduct systematical evaluations for the proposed framework on two challenging datasets: Amazon and Alibaba. The results empirically demonstrate that MSM can achieve relatively significant gains over previous state-of-arts on link prediction.
Comprehensive Information Integration Modeling Framework for Video Titling
Jun 24, 2020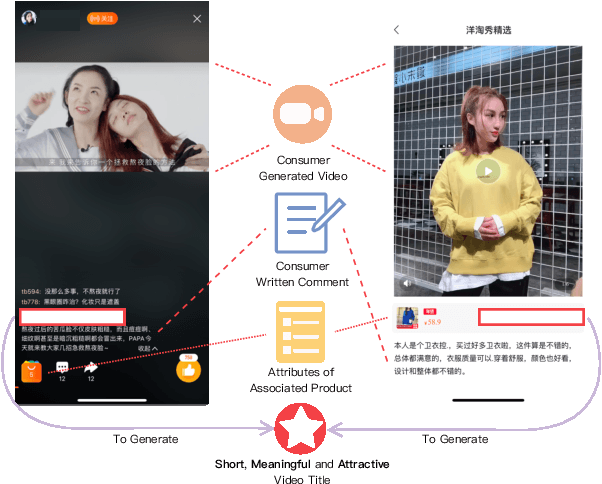

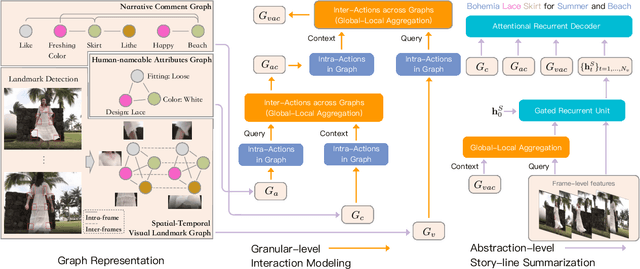
In e-commerce, consumer-generated videos, which in general deliver consumers' individual preferences for the different aspects of certain products, are massive in volume. To recommend these videos to potential consumers more effectively, diverse and catchy video titles are critical. However, consumer-generated videos seldom accompany appropriate titles. To bridge this gap, we integrate comprehensive sources of information, including the content of consumer-generated videos, the narrative comment sentences supplied by consumers, and the product attributes, in an end-to-end modeling framework. Although automatic video titling is very useful and demanding, it is much less addressed than video captioning. The latter focuses on generating sentences that describe videos as a whole while our task requires the product-aware multi-grained video analysis. To tackle this issue, the proposed method consists of two processes, i.e., granular-level interaction modeling and abstraction-level story-line summarization. Specifically, the granular-level interaction modeling first utilizes temporal-spatial landmark cues, descriptive words, and abstractive attributes to builds three individual graphs and recognizes the intra-actions in each graph through Graph Neural Networks (GNN). Then the global-local aggregation module is proposed to model inter-actions across graphs and aggregate heterogeneous graphs into a holistic graph representation. The abstraction-level story-line summarization further considers both frame-level video features and the holistic graph to utilize the interactions between products and backgrounds, and generate the story-line topic of the video. We collect a large-scale dataset accordingly from real-world data in Taobao, a world-leading e-commerce platform, and will make the desensitized version publicly available to nourish further development of the research community...
Grounded and Controllable Image Completion by Incorporating Lexical Semantics
Feb 29, 2020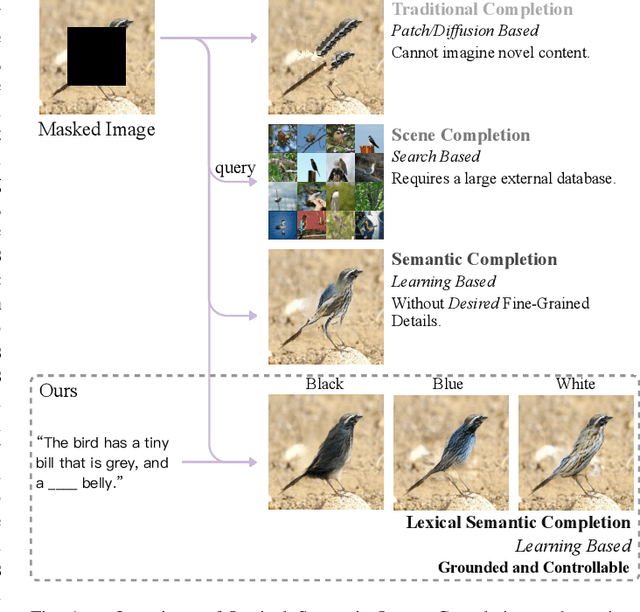
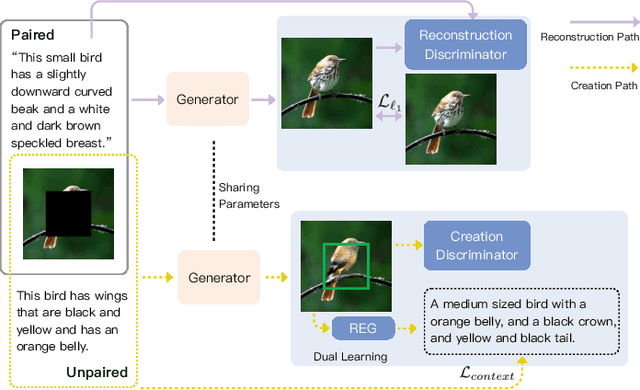
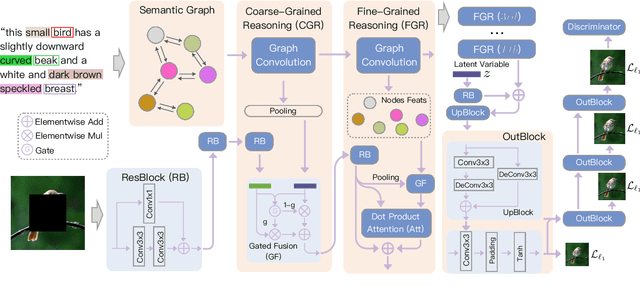

In this paper, we present an approach, namely Lexical Semantic Image Completion (LSIC), that may have potential applications in art, design, and heritage conservation, among several others. Existing image completion procedure is highly subjective by considering only visual context, which may trigger unpredictable results which are plausible but not faithful to a grounded knowledge. To permit both grounded and controllable completion process, we advocate generating results faithful to both visual and lexical semantic context, i.e., the description of leaving holes or blank regions in the image (e.g., hole description). One major challenge for LSIC comes from modeling and aligning the structure of visual-semantic context and translating across different modalities. We term this process as structure completion, which is realized by multi-grained reasoning blocks in our model. Another challenge relates to the unimodal biases, which occurs when the model generates plausible results without using the textual description. This can be true since the annotated captions for an image are often semantically equivalent in existing datasets, and thus there is only one paired text for a masked image in training. We devise an unsupervised unpaired-creation learning path besides the over-explored paired-reconstruction path, as well as a multi-stage training strategy to mitigate the insufficiency of labeled data. We conduct extensive quantitative and qualitative experiments as well as ablation studies, which reveal the efficacy of our proposed LSIC.
The Entire Quantile Path of a Risk-Agnostic SVM Classifier
May 09, 2012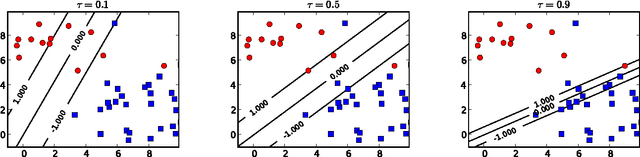
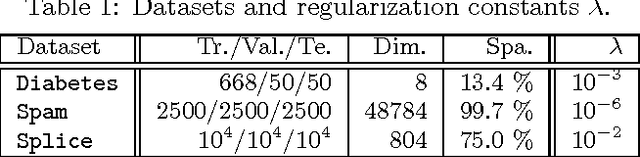
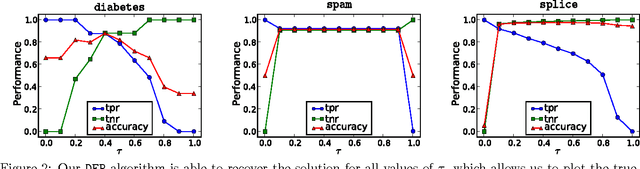
A quantile binary classifier uses the rule: Classify x as +1 if P(Y = 1|X = x) >= t, and as -1 otherwise, for a fixed quantile parameter t {[0, 1]. It has been shown that Support Vector Machines (SVMs) in the limit are quantile classifiers with t = 1/2 . In this paper, we show that by using asymmetric cost of misclassification SVMs can be appropriately extended to recover, in the limit, the quantile binary classifier for any t. We then present a principled algorithm to solve the extended SVM classifier for all values of t simultaneously. This has two implications: First, one can recover the entire conditional distribution P(Y = 1|X = x) = t for t {[0, 1]. Second, we can build a risk-agnostic SVM classifier where the cost of misclassification need not be known apriori. Preliminary numerical experiments show the effectiveness of the proposed algorithm.
Incremental Top-k List Comparison Approach to Robust Multi-Structure Model Fitting
May 31, 2011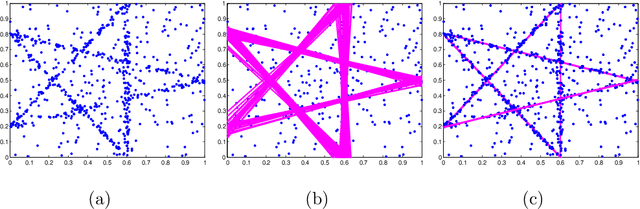
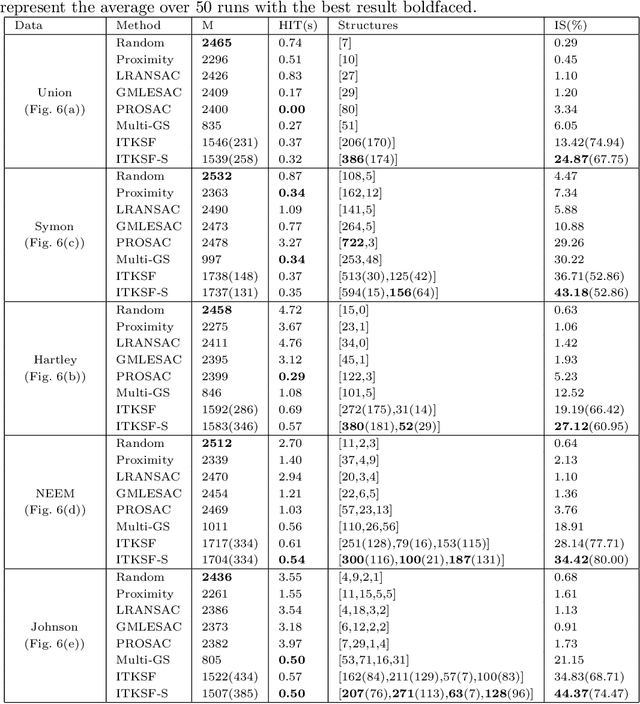
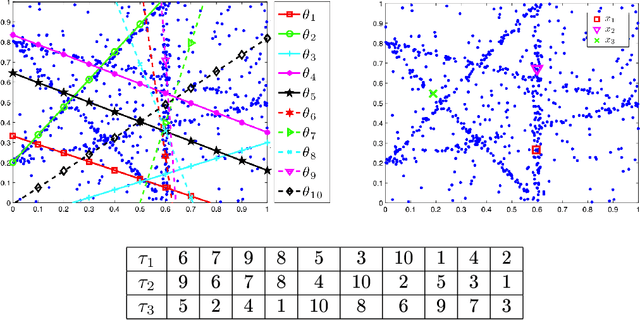
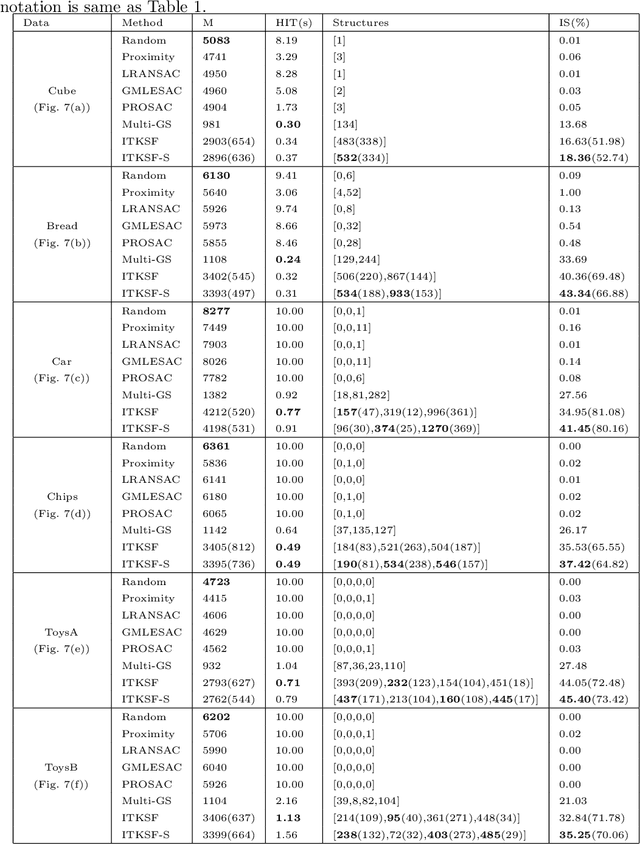
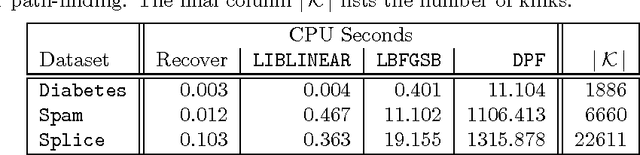
Random hypothesis sampling lies at the core of many popular robust fitting techniques such as RANSAC. In this paper, we propose a novel hypothesis sampling scheme based on incremental computation of distances between partial rankings (top-$k$ lists) derived from residual sorting information. Our method simultaneously (1) guides the sampling such that hypotheses corresponding to all true structures can be quickly retrieved and (2) filters the hypotheses such that only a small but very promising subset remain. This permits the usage of simple agglomerative clustering on the surviving hypotheses for accurate model selection. The outcome is a highly efficient multi-structure robust estimation technique. Experiments on synthetic and real data show the superior performance of our approach over previous methods.
A Quasi-Newton Approach to Nonsmooth Convex Optimization Problems in Machine Learning
Feb 22, 2010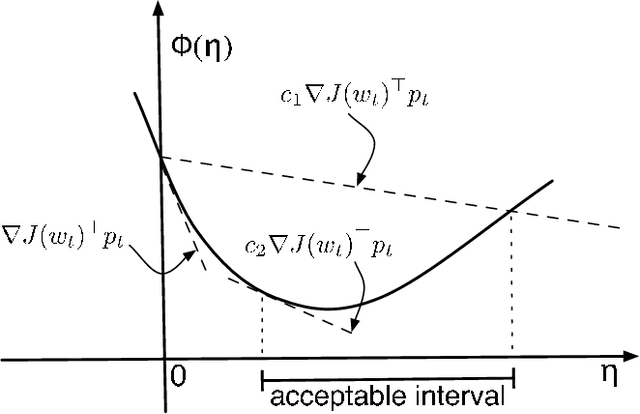
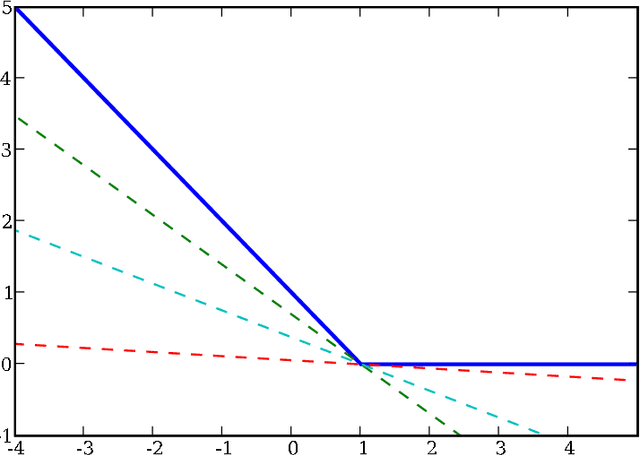
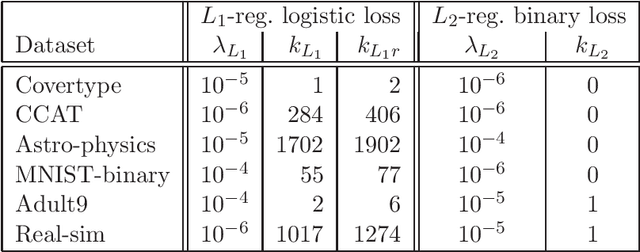
We extend the well-known BFGS quasi-Newton method and its memory-limited variant LBFGS to the optimization of nonsmooth convex objectives. This is done in a rigorous fashion by generalizing three components of BFGS to subdifferentials: the local quadratic model, the identification of a descent direction, and the Wolfe line search conditions. We prove that under some technical conditions, the resulting subBFGS algorithm is globally convergent in objective function value. We apply its memory-limited variant (subLBFGS) to L_2-regularized risk minimization with the binary hinge loss. To extend our algorithm to the multiclass and multilabel settings, we develop a new, efficient, exact line search algorithm. We prove its worst-case time complexity bounds, and show that our line search can also be used to extend a recently developed bundle method to the multiclass and multilabel settings. We also apply the direction-finding component of our algorithm to L_1-regularized risk minimization with logistic loss. In all these contexts our methods perform comparable to or better than specialized state-of-the-art solvers on a number of publicly available datasets. An open source implementation of our algorithms is freely available.
Exponential Family Graph Matching and Ranking
Jun 05, 2009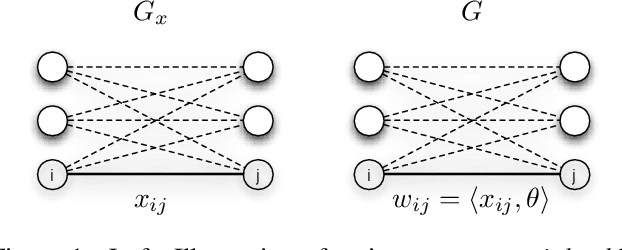
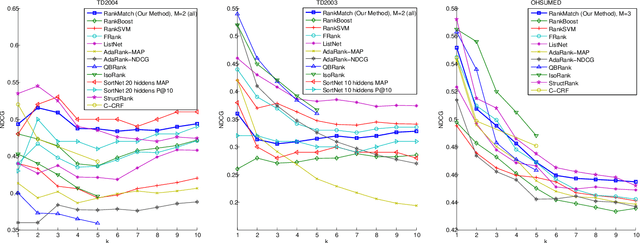
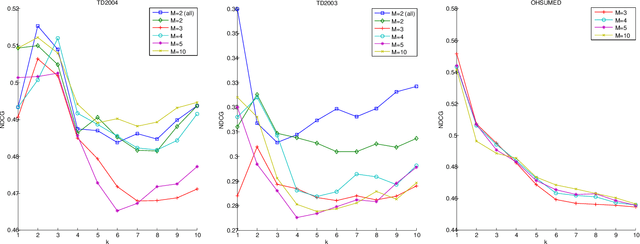
We present a method for learning max-weight matching predictors in bipartite graphs. The method consists of performing maximum a posteriori estimation in exponential families with sufficient statistics that encode permutations and data features. Although inference is in general hard, we show that for one very relevant application - web page ranking - exact inference is efficient. For general model instances, an appropriate sampler is readily available. Contrary to existing max-margin matching models, our approach is statistically consistent and, in addition, experiments with increasing sample sizes indicate superior improvement over such models. We apply the method to graph matching in computer vision as well as to a standard benchmark dataset for learning web page ranking, in which we obtain state-of-the-art results, in particular improving on max-margin variants. The drawback of this method with respect to max-margin alternatives is its runtime for large graphs, which is comparatively high.