 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEFA: Parameter-Free Adapters for Large-scale Embedding-based Retrieval Models
Dec 06, 2023



Embedding-based Retrieval Models (ERMs) have emerged as a promising framework for large-scale text retrieval problems due to powerful large language models. Nevertheless, fine-tuning ERMs to reach state-of-the-art results can be expensive due to the extreme scale of data as well as the complexity of multi-stages pipelines (e.g., pre-training, fine-tuning, distillation). In this work, we propose the PEFA framework, namely ParamEter-Free Adapters, for fast tuning of ERMs without any backward pass in the optimization. At index building stage, PEFA equips the ERM with a non-parametric k-nearest neighbor (kNN) component. At inference stage, PEFA performs a convex combination of two scoring functions, one from the ERM and the other from the kNN. Based on the neighborhood definition, PEFA framework induces two realizations, namely PEFA-XL (i.e., extra large) using double ANN indices and PEFA-XS (i.e., extra small) using a single ANN index. Empirically, PEFA achieves significant improvement on two retrieval applications. For document retrieval, regarding Recall@100 metric, PEFA improves not only pre-trained ERMs on Trivia-QA by an average of 13.2%, but also fine-tuned ERMs on NQ-320K by an average of 5.5%, respectively. For product search, PEFA improves the Recall@100 of the fine-tuned ERMs by an average of 5.3% and 14.5%, for PEFA-XS and PEFA-XL, respectively. Our code is available at https://github.com/amzn/pecos/tree/mainline/examples/pefa-wsdm24.
Toward Understanding Privileged Features Distillation in Learning-to-Rank
Sep 19, 2022
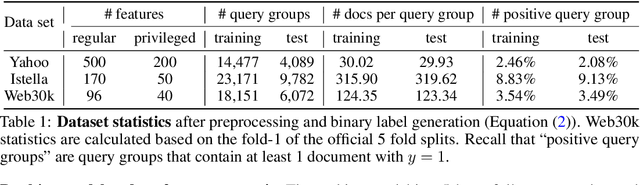
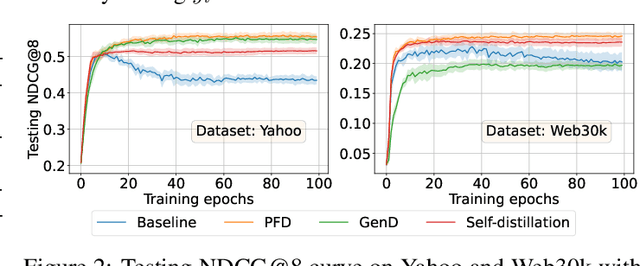
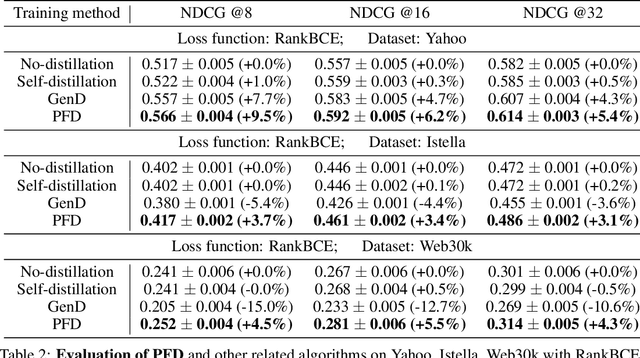
In learning-to-rank problems, a privileged feature is one that is available during model training, but not available at test time. Such features naturally arise in merchandised recommendation systems; for instance, "user clicked this item" as a feature is predictive of "user purchased this item" in the offline data, but is clearly not available during online serving. Another source of privileged features is those that are too expensive to compute online but feasible to be added offline. Privileged features distillation (PFD) refers to a natural idea: train a "teacher" model using all features (including privileged ones) and then use it to train a "student" model that does not use the privileged features. In this paper, we first study PFD empirically on three public ranking datasets and an industrial-scale ranking problem derived from Amazon's logs. We show that PFD outperforms several baselines (no-distillation, pretraining-finetuning, self-distillation, and generalized distillation) on all these datasets. Next, we analyze why and when PFD performs well via both empirical ablation studies and theoretical analysis for linear models. Both investigations uncover an interesting non-monotone behavior: as the predictive power of a privileged feature increases, the performance of the resulting student model initially increases but then decreases. We show the reason for the later decreasing performance is that a very predictive privileged teacher produces predictions with high variance, which lead to high variance student estimates and inferior testing performance.
DS-FACTO: Doubly Separable Factorization Machines
Apr 29, 2020
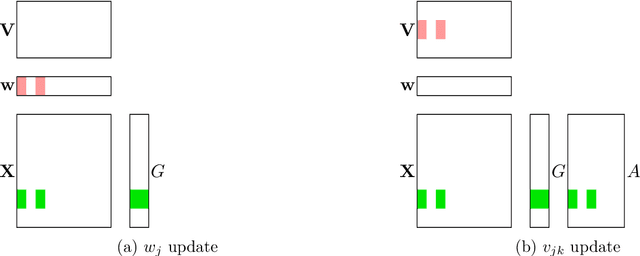
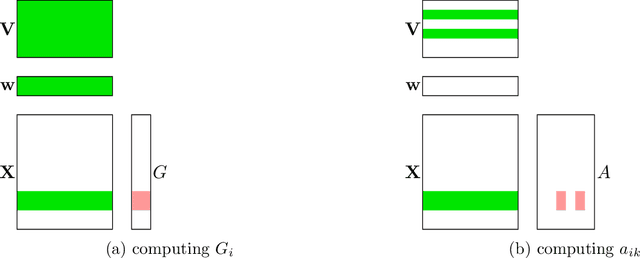
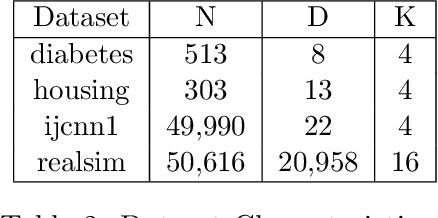
Factorization Machines (FM) are powerful class of models that incorporate higher-order interaction among features to add more expressive power to linear models. They have been used successfully in several real-world tasks such as click-prediction, ranking and recommender systems. Despite using a low-rank representation for the pairwise features, the memory overheads of using factorization machines on large-scale real-world datasets can be prohibitively high. For instance on the criteo tera dataset, assuming a modest $128$ dimensional latent representation and $10^{9}$ features, the memory requirement for the model is in the order of $1$ TB. In addition, the data itself occupies $2.1$ TB. Traditional algorithms for FM which work on a single-machine are not equipped to handle this scale and therefore, using a distributed algorithm to parallelize the computation across a cluster is inevitable. In this work, we propose a hybrid-parallel stochastic optimization algorithm DS-FACTO, which partitions both the data as well as parameters of the factorization machine simultaneously. Our solution is fully de-centralized and does not require the use of any parameter servers. We present empirical results to analyze the convergence behavior, predictive power and scalability of DS-FACTO.
DS-MLR: Exploiting Double Separability for Scaling up Distributed Multinomial Logistic Regression
Aug 03, 2018
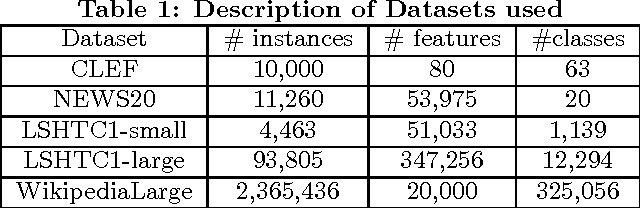
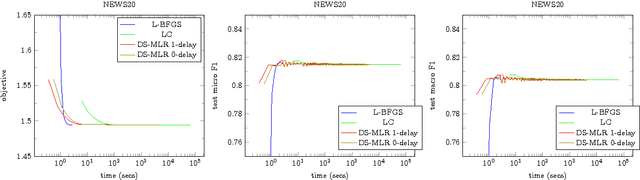
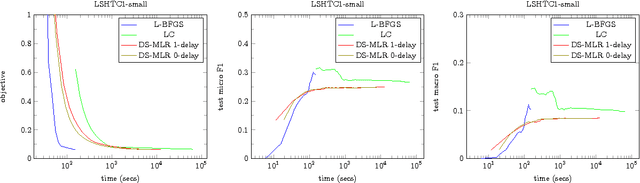
Scaling multinomial logistic regression to datasets with very large number of data points and classes is challenging. This is primarily because one needs to compute the log-partition function on every data point. This makes distributing the computation hard. In this paper, we present a distributed stochastic gradient descent based optimization method (DS-MLR) for scaling up multinomial logistic regression problems to massive scale datasets without hitting any storage constraints on the data and model parameters. Our algorithm exploits double-separability, an attractive property that allows us to achieve both data as well as model parallelism simultaneously. In addition, we introduce a non-blocking and asynchronous variant of our algorithm that avoids bulk-synchronization. We demonstrate the versatility of DS-MLR to various scenarios in data and model parallelism, through an extensive empirical study using several real-world datasets. In particular, we demonstrate the scalability of DS-MLR by solving an extreme multi-class classification problem on the Reddit dataset (159 GB data, 358 GB parameters) where, to the best of our knowledge, no other existing methods apply.
Extreme Stochastic Variational Inference: Distributed and Asynchronous
Aug 03, 2018
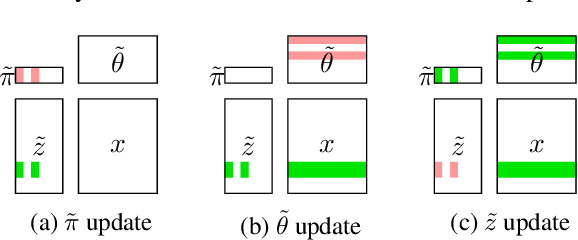
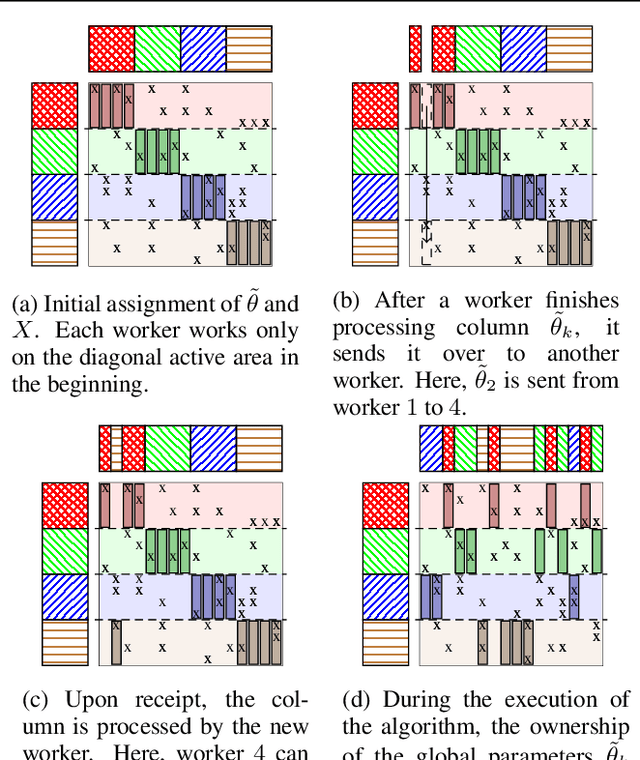
Stochastic variational inference (SVI), the state-of-the-art algorithm for scaling variational inference to large-datasets, is inherently serial. Moreover, it requires the parameters to fit in the memory of a single processor; this is problematic when the number of parameters is in billions. In this paper, we propose extreme stochastic variational inference (ESVI), an asynchronous and lock-free algorithm to perform variational inference for mixture models on massive real world datasets. ESVI overcomes the limitations of SVI by requiring that each processor only access a subset of the data and a subset of the parameters, thus providing data and model parallelism simultaneously. We demonstrate the effectiveness of ESVI by running Latent Dirichlet Allocation (LDA) on UMBC-3B, a dataset that has a vocabulary of 3 million and a token size of 3 billion. In our experiments, we found that ESVI not only outperforms VI and SVI in wallclock-time, but also achieves a better quality solution. In addition, we propose a strategy to speed up computation and save memory when fitting large number of topics.
Batch-Expansion Training: An Efficient Optimization Framework
Feb 23, 2018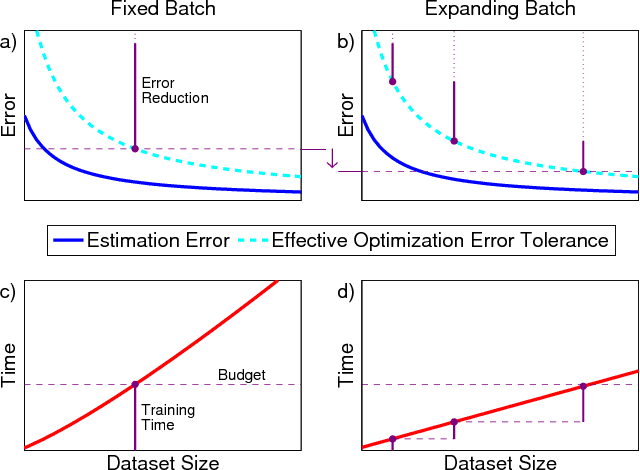
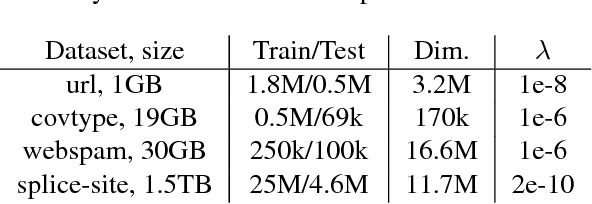
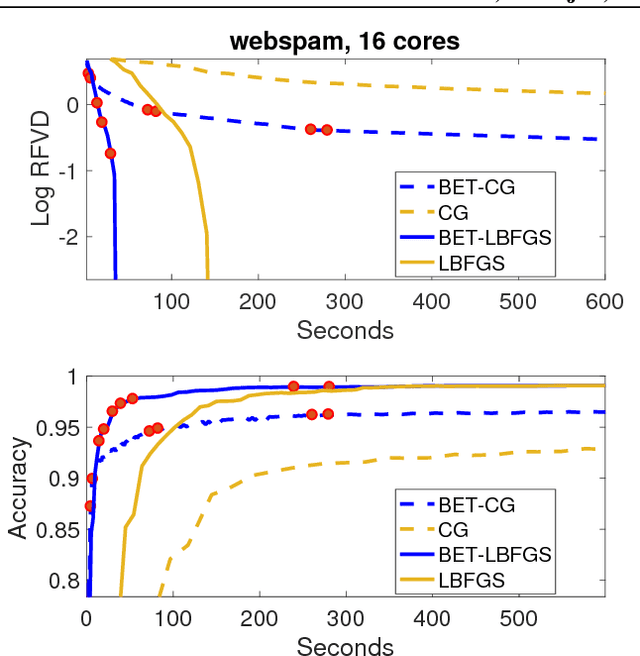
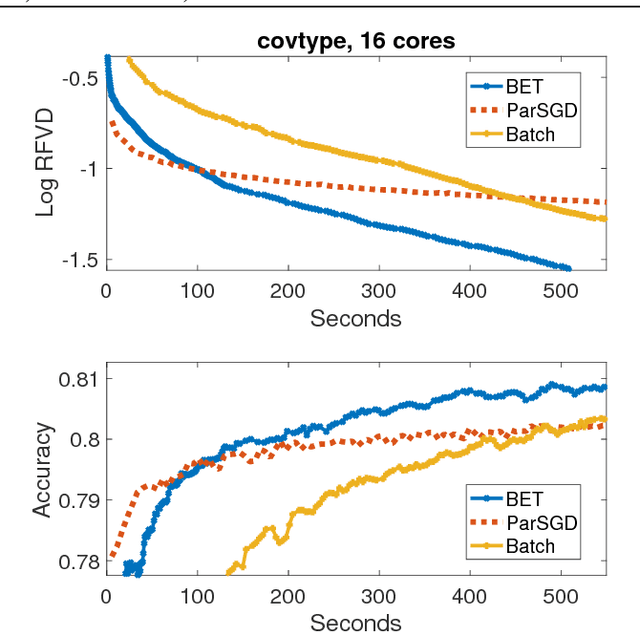
We propose Batch-Expansion Training (BET), a framework for running a batch optimizer on a gradually expanding dataset. As opposed to stochastic approaches, batches do not need to be resampled i.i.d. at every iteration, thus making BET more resource efficient in a distributed setting, and when disk-access is constrained. Moreover, BET can be easily paired with most batch optimizers, does not require any parameter-tuning, and compares favorably to existing stochastic and batch methods. We show that when the batch size grows exponentially with the number of outer iterations, BET achieves optimal $O(1/\epsilon)$ data-access convergence rate for strongly convex objectives. Experiments in parallel and distributed settings show that BET performs better than standard batch and stochastic approaches.
Online Learning of Combinatorial Objects via Extended Formulation
Oct 30, 2017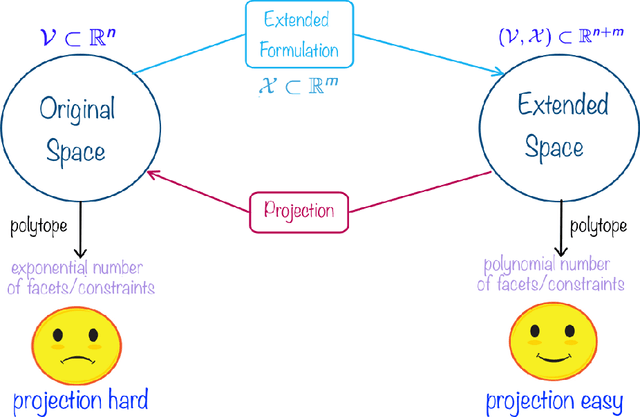
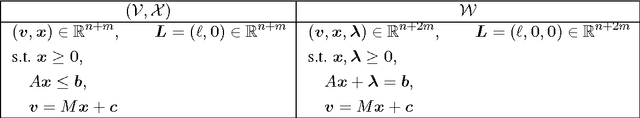
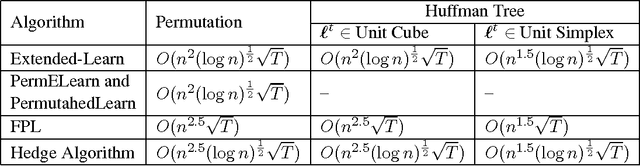
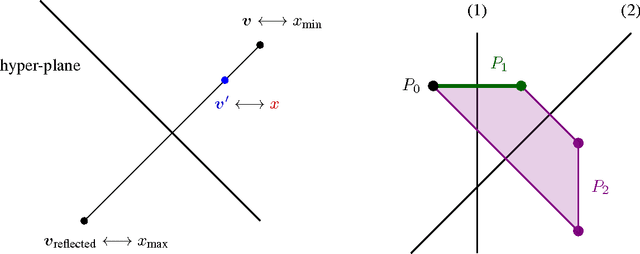
The standard techniques for online learning of combinatorial objects perform multiplicative updates followed by projections into the convex hull of all the objects. However, this methodology can be expensive if the convex hull contains many facets. For example, the convex hull of $n$-symbol Huffman trees is known to have exponentially many facets (Maurras et al., 2010). We get around this difficulty by exploiting extended formulations (Kaibel, 2011), which encode the polytope of combinatorial objects in a higher dimensional "extended" space with only polynomially many facets. We develop a general framework for converting extended formulations into efficient online algorithms with good relative loss bounds. We present applications of our framework to online learning of Huffman trees and permutations. The regret bounds of the resulting algorithms are within a factor of $O(\sqrt{\log(n)})$ of the state-of-the-art specialized algorithms for permutations, and depending on the loss regimes, improve on or match the state-of-the-art for Huffman trees. Our method is general and can be applied to other combinatorial objects.
WordRank: Learning Word Embeddings via Robust Ranking
Sep 27, 2016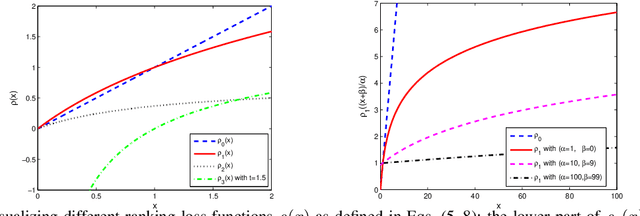
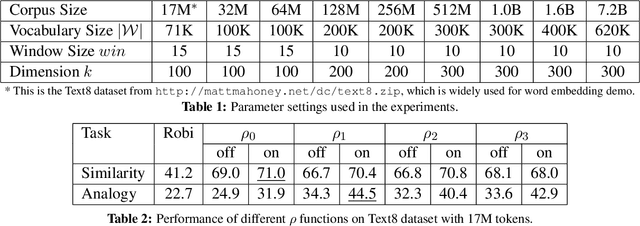
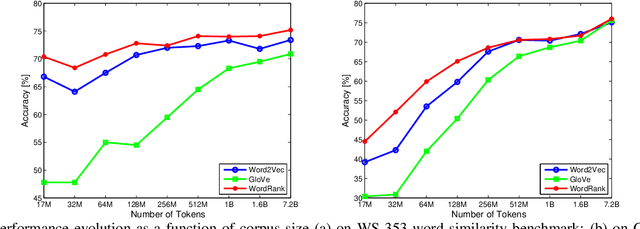
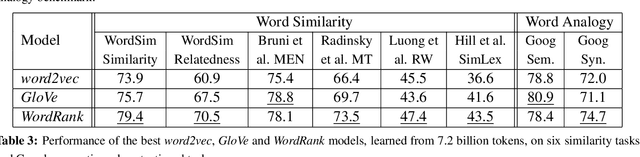
Embedding words in a vector space has gained a lot of attention in recent years. While state-of-the-art methods provide efficient computation of word similarities via a low-dimensional matrix embedding, their motivation is often left unclear. In this paper, we argue that word embedding can be naturally viewed as a ranking problem due to the ranking nature of the evaluation metrics. Then, based on this insight, we propose a novel framework WordRank that efficiently estimates word representations via robust ranking, in which the attention mechanism and robustness to noise are readily achieved via the DCG-like ranking losses. The performance of WordRank is measured in word similarity and word analogy benchmarks, and the results are compared to the state-of-the-art word embedding techniques. Our algorithm is very competitive to the state-of-the- arts on large corpora, while outperforms them by a significant margin when the training set is limited (i.e., sparse and noisy). With 17 million tokens, WordRank performs almost as well as existing methods using 7.2 billion tokens on a popular word similarity benchmark. Our multi-node distributed implementation of WordRank is publicly available for general usage.
BlackOut: Speeding up Recurrent Neural Network Language Models With Very Large Vocabularies
Mar 31, 2016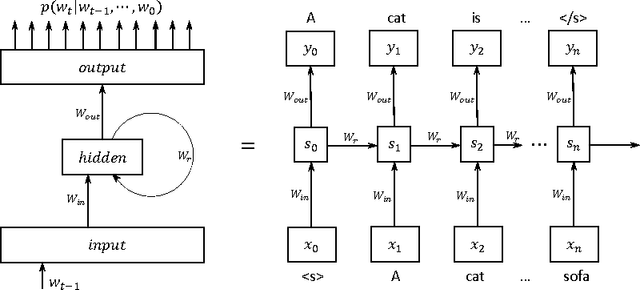
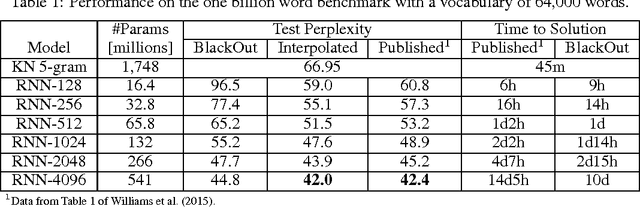
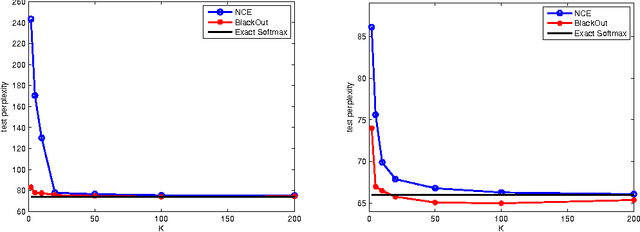
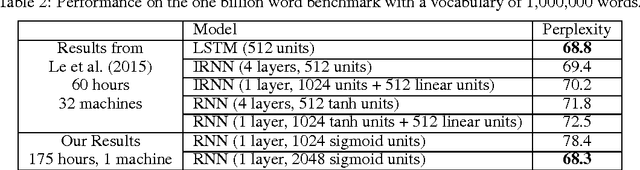
We propose BlackOut, an approximation algorithm to efficiently train massive recurrent neural network language models (RNNLMs) with million word vocabularies. BlackOut is motivated by using a discriminative loss, and we describe a new sampling strategy which significantly reduces computation while improving stability, sample efficiency, and rate of convergence. One way to understand BlackOut is to view it as an extension of the DropOut strategy to the output layer, wherein we use a discriminative training loss and a weighted sampling scheme. We also establish close connections between BlackOut, importance sampling, and noise contrastive estimation (NCE). Our experiments, on the recently released one billion word language modeling benchmark, demonstrate scalability and accuracy of BlackOut; we outperform the state-of-the art, and achieve the lowest perplexity scores on this dataset. Moreover, unlike other established methods which typically require GPUs or CPU clusters, we show that a carefully implemented version of BlackOut requires only 1-10 days on a single machine to train a RNNLM with a million word vocabulary and billions of parameters on one billion words. Although we describe BlackOut in the context of RNNLM training, it can be used to any networks with large softmax output layers.
Distributed Stochastic Optimization of the Regularized Risk
Jun 09, 2015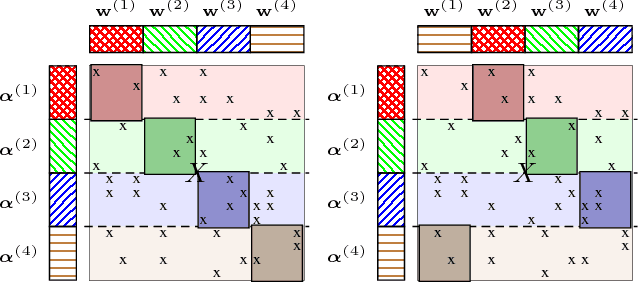

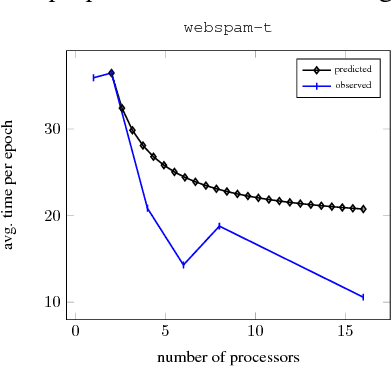
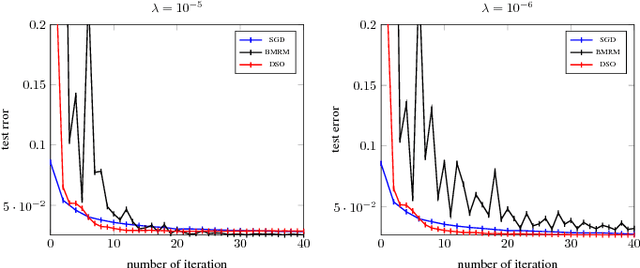
Many machine learning algorithms minimize a regularized risk, and stochastic optimization is widely used for this task. When working with massive data, it is desirable to perform stochastic optimization in parallel. Unfortunately, many existing stochastic optimization algorithms cannot be parallelized efficiently. In this paper we show that one can rewrite the regularized risk minimization problem as an equivalent saddle-point problem, and propose an efficient distributed stochastic optimization (DSO) algorithm. We prove the algorithm's rate of convergence; remarkably, our analysis shows that the algorithm scales almost linearly with the number of processors. We also verify with empirical evaluations that the proposed algorithm is competitive with other parallel, general purpose stochastic and batch optimization algorithms for regularized risk minimization.