 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDOL-Net: An Interactive Dual-Domain Parallel Network for CT Metal Artifact Reduction
Apr 03, 2021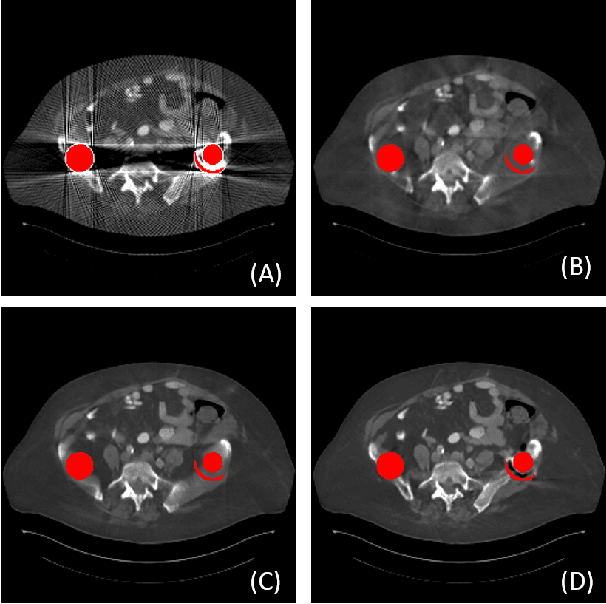
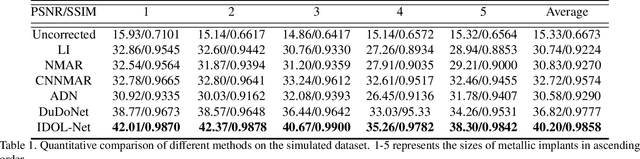
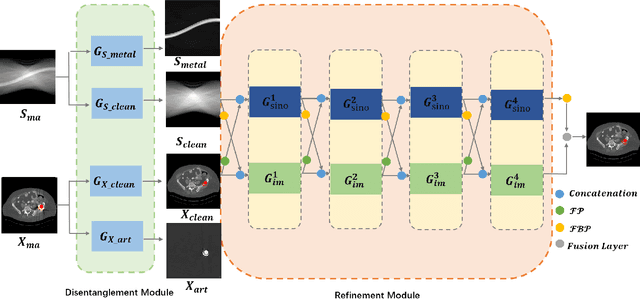

Due to the presence of metallic implants, the imaging quality of computed tomography (CT) would be heavily degraded. With the rapid development of deep learning, several network models have been proposed for metal artifact reduction (MAR). Since the dual-domain MAR methods can leverage the hybrid information from both sinogram and image domains, they have significantly improved the performance compared to single-domain methods. However,current dual-domain methods usually operate on both domains in a specific order, which implicitly imposes a certain priority prior into MAR and may ignore the latent information interaction between both domains. To address this problem, in this paper, we propose a novel interactive dualdomain parallel network for CT MAR, dubbed as IDOLNet. Different from existing dual-domain methods, the proposed IDOL-Net is composed of two modules. The disentanglement module is utilized to generate high-quality prior sinogram and image as the complementary inputs. The follow-up refinement module consists of two parallel and interactive branches that simultaneously operate on image and sinogram domain, fully exploiting the latent information interaction between both domains. The simulated and clinical results demonstrate that the proposed IDOL-Net outperforms several state-of-the-art models in both qualitative and quantitative aspects.
MANAS: Multi-Scale and Multi-Level Neural Architecture Search for Low-Dose CT Denoising
Mar 24, 2021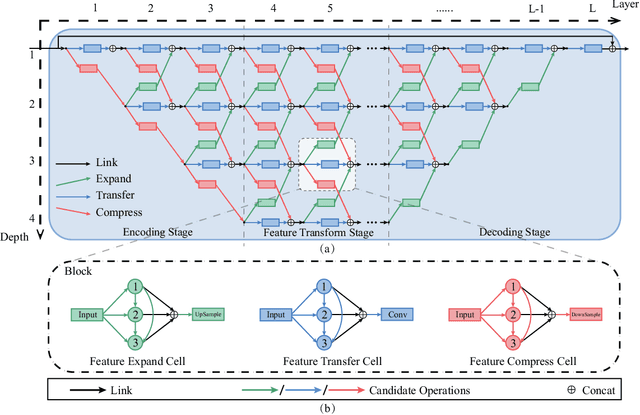

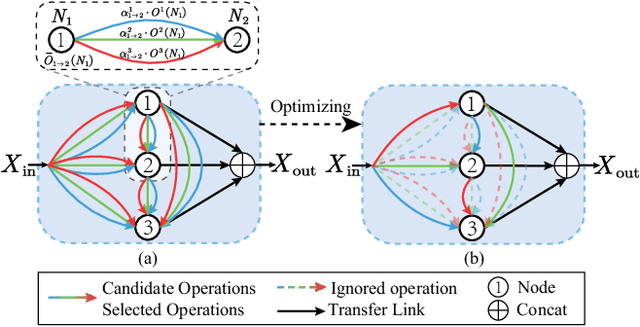
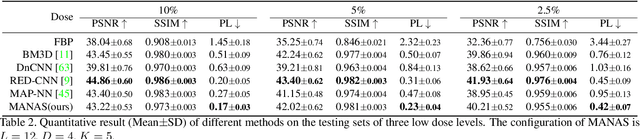
Lowering the radiation dose in computed tomography (CT) can greatly reduce the potential risk to public health. However, the reconstructed images from the dose-reduced CT or low-dose CT (LDCT) suffer from severe noise, compromising the subsequent diagnosis and analysis. Recently, convolutional neural networks have achieved promising results in removing noise from LDCT images; the network architectures used are either handcrafted or built on top of conventional networks such as ResNet and U-Net. Recent advance on neural network architecture search (NAS) has proved that the network architecture has a dramatic effect on the model performance, which indicates that current network architectures for LDCT may be sub-optimal. Therefore, in this paper, we make the first attempt to apply NAS to LDCT and propose a multi-scale and multi-level NAS for LDCT denoising, termed MANAS. On the one hand, the proposed MANAS fuses features extracted by different scale cells to capture multi-scale image structural details. On the other hand, the proposed MANAS can search a hybrid cell- and network-level structure for better performance. Extensively experimental results on three different dose levels demonstrate that the proposed MANAS can achieve better performance in terms of preserving image structural details than several state-of-the-art methods. In addition, we also validate the effectiveness of the multi-scale and multi-level architecture for LDCT denoising.
TPPI-Net: Towards Efficient and Practical Hyperspectral Image Classification
Mar 18, 2021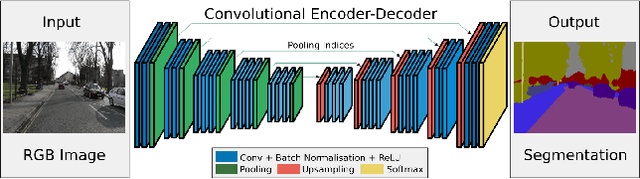
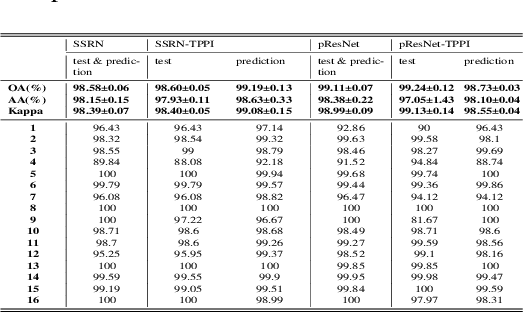
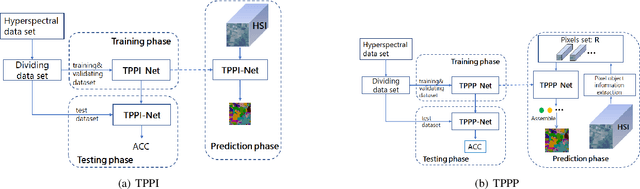
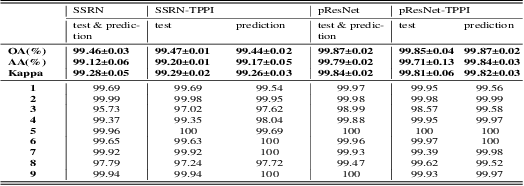
Hyperspectral Image(HSI) classification is the most vibrant field of research in the hyperspectral community, which aims to assign each pixel in the image to one certain category based on its spectral-spatial characteristics. Recently, some spectral-spatial-feature based DCNNs have been proposed and demonstrated remarkable classification performance. When facing a real HSI, however, these Networks have to deal with the pixels in the image one by one. The pixel-wise processing strategy is inefficient since there are numerous repeated calculations between adjacent pixels. In this paper, firstly, a brand new Network design mechanism TPPI (training based on pixel and prediction based on image) is proposed for HSI classification, which makes it possible to provide efficient and practical HSI classification with the restrictive conditions attached to the hyperspectral dataset. And then, according to the TPPI mechanism, TPPI-Net is derived based on the state of the art networks for HSI classification. Experimental results show that the proposed TPPI-Net can not only obtain high classification accuracy equivalent to the state of the art networks for HSI classification, but also greatly reduce the computational complexity of hyperspectral image prediction.
DAN-Net: Dual-Domain Adaptive-Scaling Non-local Network for CT Metal Artifact Reduction
Feb 16, 2021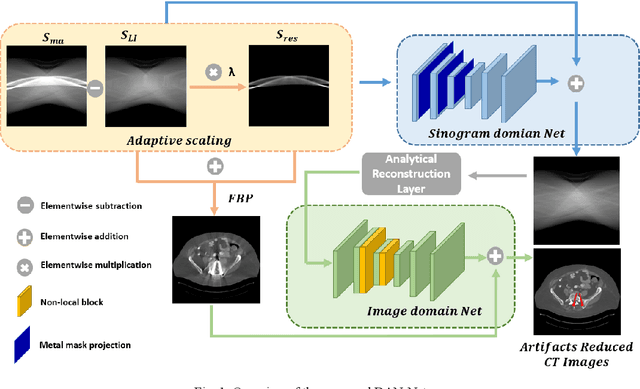
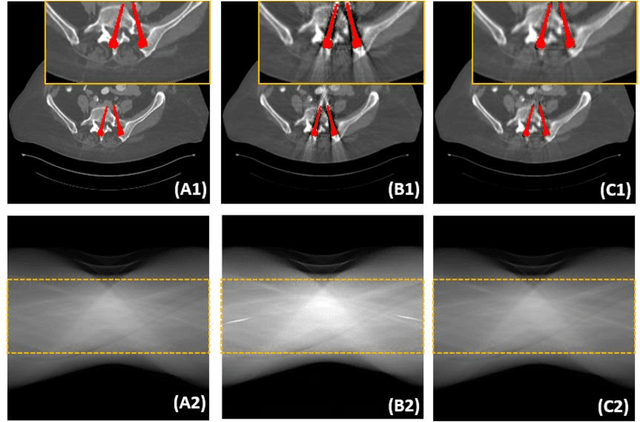
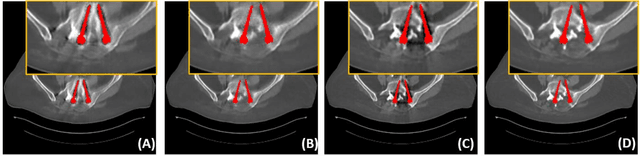
Metal implants can heavily attenuate X-rays in computed tomography (CT) scans, leading to severe artifacts in reconstructed images, which significantly jeopardize image quality and negatively impact subsequent diagnoses and treatment planning. With the rapid development of deep learning in the field of medical imaging, several network models have been proposed for metal artifact reduction (MAR) in CT. Despite the encouraging results achieved by these methods, there is still much room to further improve performance. In this paper, a novel Dual-domain Adaptive-scaling Non-local network (DAN-Net) for MAR. We correct the corrupted sinogram using adaptive scaling first to preserve more tissue and bone details as a more informative input. Then, an end-to-end dual-domain network is adopted to successively process the sinogram and its corresponding reconstructed image generated by the analytical reconstruction layer. In addition, to better suppress the existing artifacts and restrain the potential secondary artifacts caused by inaccurate results of the sinogram-domain network, a novel residual sinogram learning strategy and nonlocal module are leveraged in the proposed network model. In the experiments, the proposed DAN-Net demonstrates performance competitive with several state-of-the-art MAR methods in both qualitative and quantitative aspects.
LEARN++: Recurrent Dual-Domain Reconstruction Network for Compressed Sensing CT
Dec 13, 2020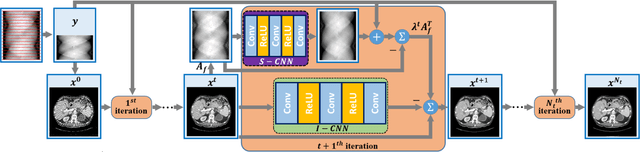
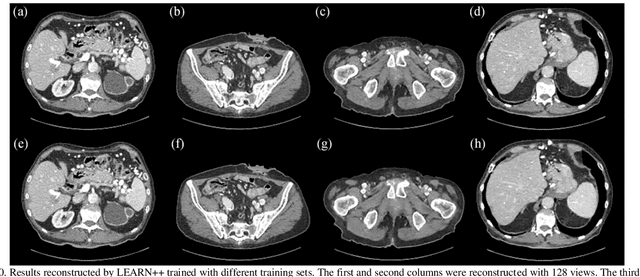
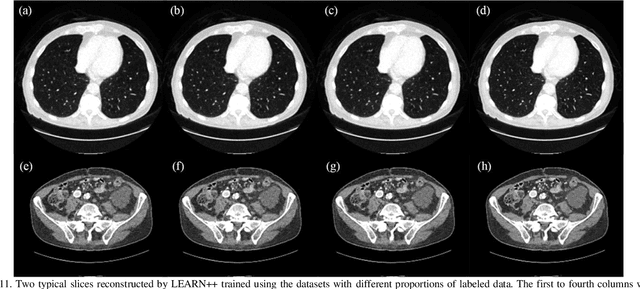
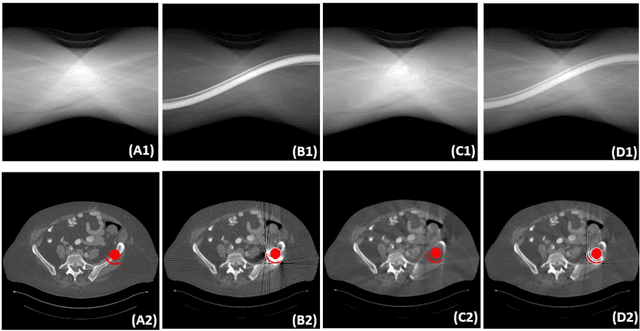
Compressed sensing (CS) computed tomography has been proven to be important for several clinical applications, such as sparse-view computed tomography (CT), digital tomosynthesis and interior tomography. Traditional compressed sensing focuses on the design of handcrafted prior regularizers, which are usually image-dependent and time-consuming. Inspired by recently proposed deep learning-based CT reconstruction models, we extend the state-of-the-art LEARN model to a dual-domain version, dubbed LEARN++. Different from existing iteration unrolling methods, which only involve projection data in the data consistency layer, the proposed LEARN++ model integrates two parallel and interactive subnetworks to perform image restoration and sinogram inpainting operations on both the image and projection domains simultaneously, which can fully explore the latent relations between projection data and reconstructed images. The experimental results demonstrate that the proposed LEARN++ model achieves competitive qualitative and quantitative results compared to several state-of-the-art methods in terms of both artifact reduction and detail preservation.
Fourth-Order Nonlocal Tensor Decomposition Model for Spectral Computed Tomography
Oct 27, 2020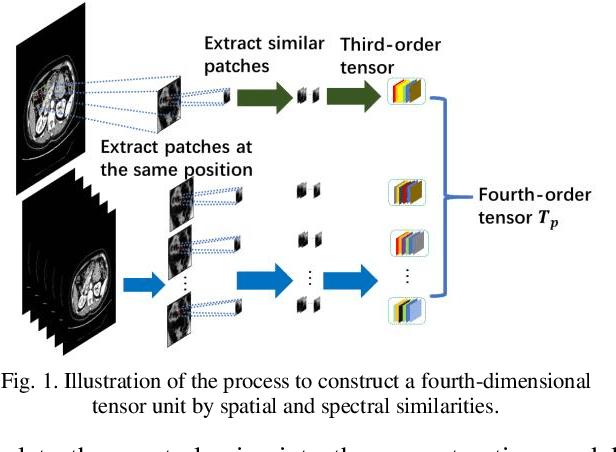

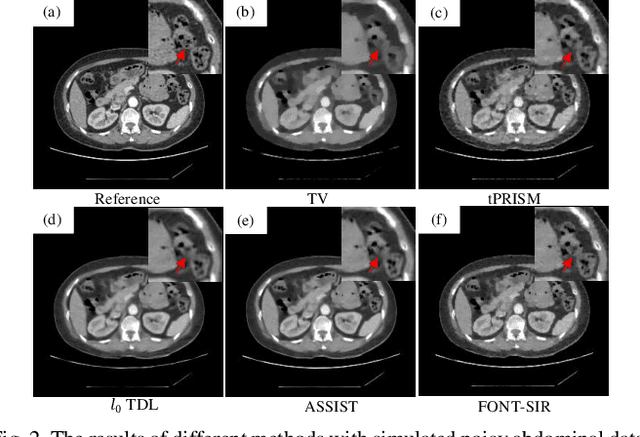
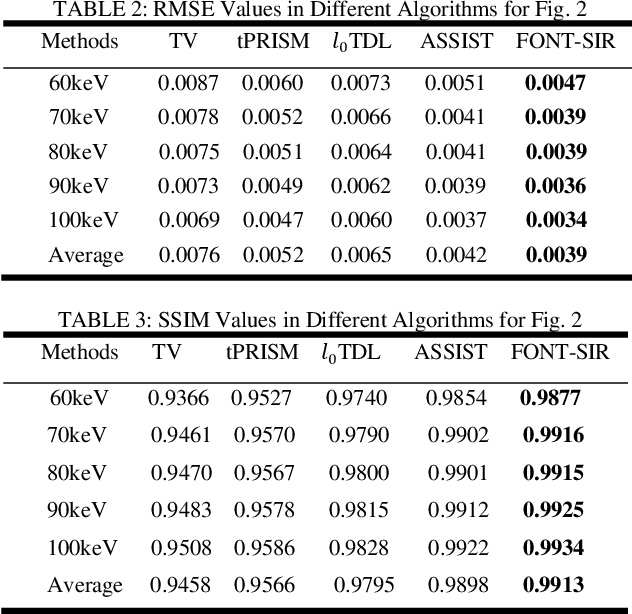
Spectral computed tomography (CT) can reconstruct spectral images from different energy bins using photon counting detectors (PCDs). However, due to the limited photons and counting rate in the corresponding spectral fraction, the reconstructed spectral images usually suffer from severe noise. In this paper, a fourth-order nonlocal tensor decomposition model for spectral CT image reconstruction (FONT-SIR) method is proposed. Similar patches are collected in both spatial and spectral dimensions simultaneously to form the basic tensor unit. Additionally, principal component analysis (PCA) is applied to extract latent features from the patches for a robust and efficient similarity measure. Then, low-rank and sparsity decomposition is performed on the produced fourth-order tensor unit, and the weighted nuclear norm and total variation (TV) norm are used to enforce the low-rank and sparsity constraints, respectively. The alternating direction method of multipliers (ADMM) is adopted to optimize the objective function. The experimental results with our proposed FONT-SIR demonstrates a superior qualitative and quantitative performance for both simulated and real data sets relative to several state-of-the-art methods, in terms of noise suppression and detail preservation.
CT Reconstruction with PDF: Parameter-Dependent Framework for Multiple Scanning Geometries and Dose Levels
Oct 27, 2020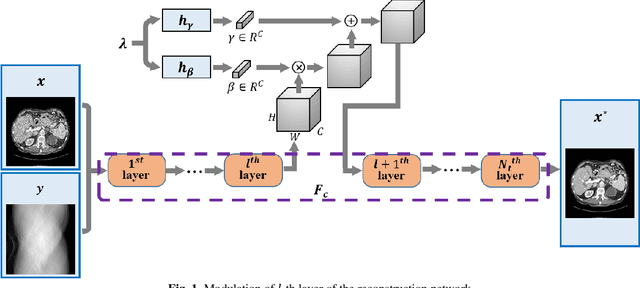
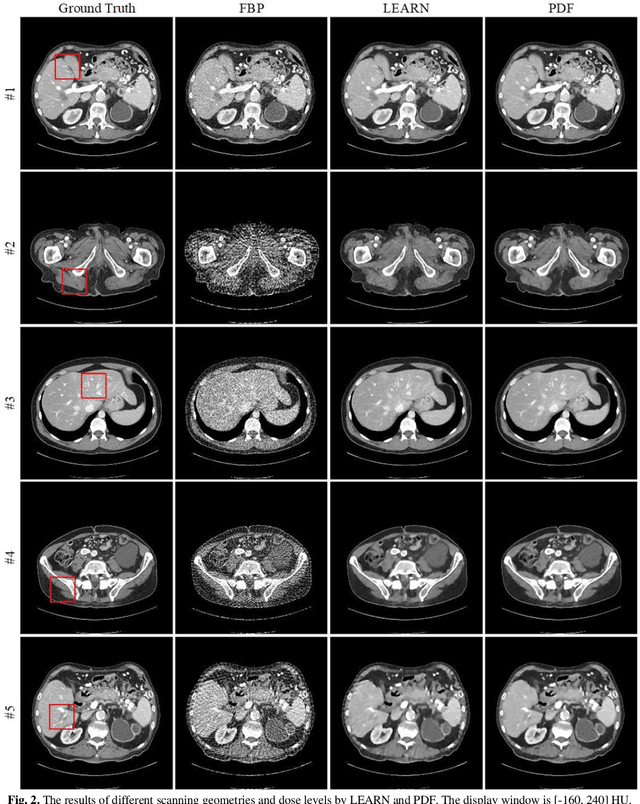
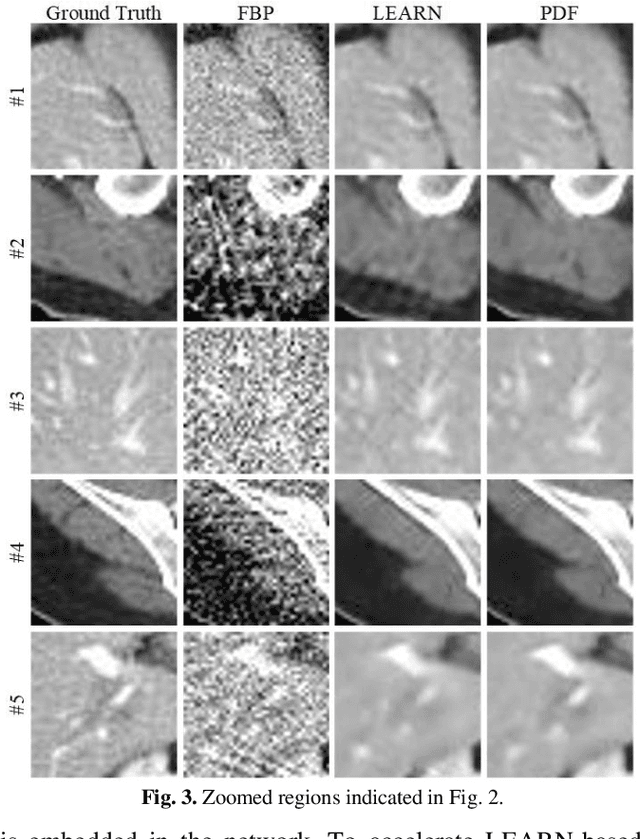
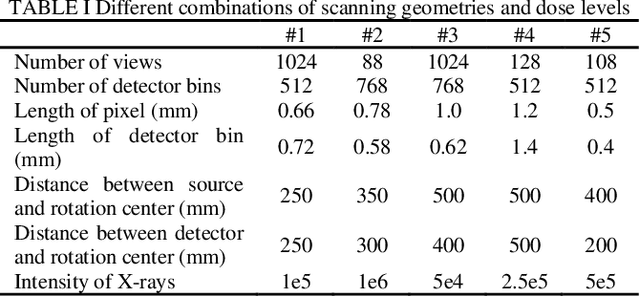
Current mainstream of CT reconstruction methods based on deep learning usually needs to fix the scanning geometry and dose level, which will significantly aggravate the training cost and need more training data for clinical application. In this paper, we propose a parameter-dependent framework (PDF) which trains data with multiple scanning geometries and dose levels simultaneously. In the proposed PDF, the geometry and dose level are parameterized and fed into two multi-layer perceptrons (MLPs). The MLPs are leveraged to modulate the feature maps of CT reconstruction network, which condition the network outputs on different scanning geometries and dose levels. The experiments show that our proposed method can obtain competing performance similar to the original network trained with specific geometry and dose level, which can efficiently save the extra training cost for multiple scanning geometries and dose levels.
ASMFS: Adaptive-Similarity-based Multi-modality Feature Selection for Classification of Alzheimer's Disease
Oct 16, 2020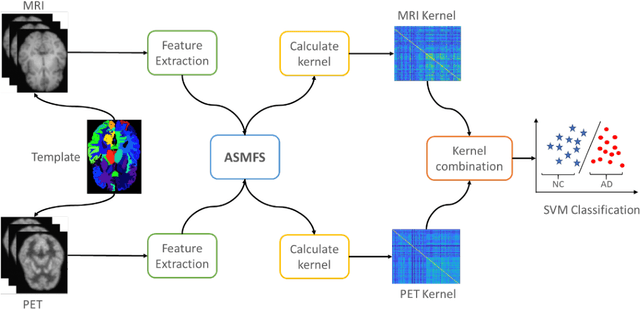
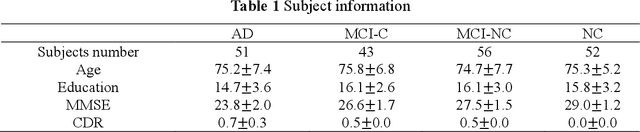
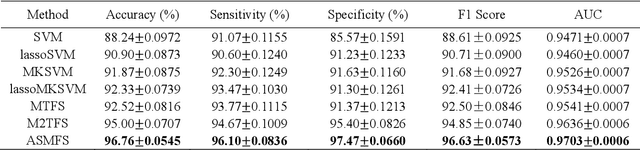
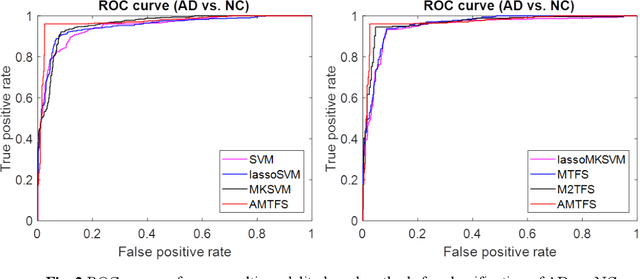
With the increasing amounts of high-dimensional heterogeneous data to be processed, multi-modality feature selection has become an important research direction in medical image analysis. Traditional methods usually depict the data structure using fixed and predefined similarity matrix for each modality separately, without considering the potential relationship structure across different modalities. In this paper, we propose a novel multi-modality feature selection method, which performs feature selection and local similarity learning simultaniously. Specially, a similarity matrix is learned by jointly considering different imaging modalities. And at the same time, feature selection is conducted by imposing sparse l_{2, 1} norm constraint. The effectiveness of our proposed joint learning method can be well demonstrated by the experimental results on Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, which outperforms existing the state-of-the-art multi-modality approaches.
Hyper RPCA: Joint Maximum Correntropy Criterion and Laplacian Scale Mixture Modeling On-the-Fly for Moving Object Detection
Jun 14, 2020
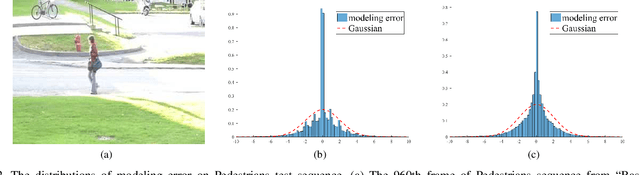

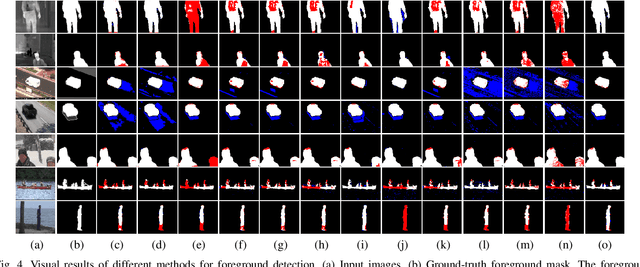
Moving object detection is critical for automated video analysis in many vision-related tasks, such as surveillance tracking, video compression coding, etc. Robust Principal Component Analysis (RPCA), as one of the most popular moving object modelling methods, aims to separate the temporally varying (i.e., moving) foreground objects from the static background in video, assuming the background frames to be low-rank while the foreground to be spatially sparse. Classic RPCA imposes sparsity of the foreground component using l1-norm, and minimizes the modeling error via 2-norm. We show that such assumptions can be too restrictive in practice, which limits the effectiveness of the classic RPCA, especially when processing videos with dynamic background, camera jitter, camouflaged moving object, etc. In this paper, we propose a novel RPCA-based model, called Hyper RPCA, to detect moving objects on the fly. Different from classic RPCA, the proposed Hyper RPCA jointly applies the maximum correntropy criterion (MCC) for the modeling error, and Laplacian scale mixture (LSM) model for foreground objects. Extensive experiments have been conducted, and the results demonstrate that the proposed Hyper RPCA has competitive performance for foreground detection to the state-of-the-art algorithms on several well-known benchmark datasets.
DSU-net: Dense SegU-net for automatic head-and-neck tumor segmentation in MR images
Jun 12, 2020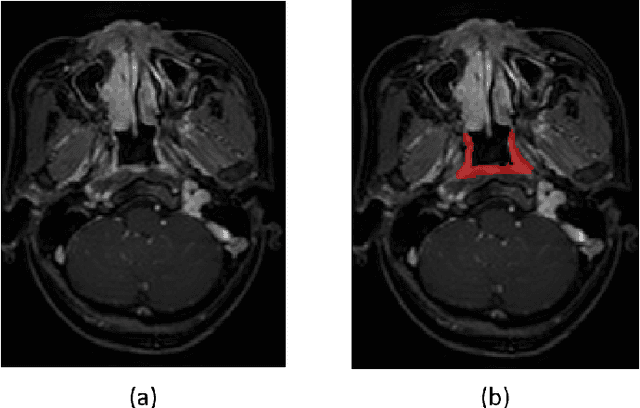

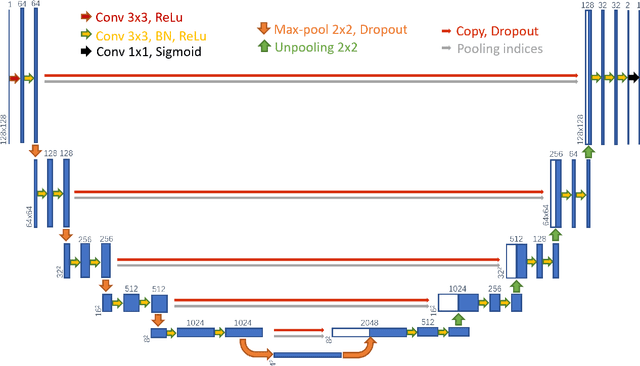

Precise and accurate segmentation of the most common head-and-neck tumor, nasopharyngeal carcinoma (NPC), in MRI sheds light on treatment and regulatory decisions making. However, the large variations in the lesion size and shape of NPC, boundary ambiguity, as well as the limited available annotated samples conspire NPC segmentation in MRI towards a challenging task. In this paper, we propose a Dense SegU-net (DSU-net) framework for automatic NPC segmentation in MRI. Our contribution is threefold. First, different from the traditional decoder in U-net using upconvolution for upsamling, we argue that the restoration from low resolution features to high resolution output should be capable of preserving information significant for precise boundary localization. Hence, we use unpooling to unsample and propose SegU-net. Second, to combat the potential vanishing-gradient problem, we introduce dense blocks which can facilitate feature propagation and reuse. Third, using only cross entropy (CE) as loss function may bring about troubles such as miss-prediction, therefore we propose to use a loss function comprised of both CE loss and Dice loss to train the network. Quantitative and qualitative comparisons are carried out extensively on in-house datasets, the experimental results show that our proposed architecture outperforms the existing state-of-the-art segmentation networks.