 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Sensing and Covert Communication In Low-Altitude Networks: A Smart Radio Environment Perspective
Jun 01, 2026The rise of low-altitude economies and 6G is driving the evolution of low-altitude networks (LANs), making communication security a pressing concern. Unlike traditional security approaches, covert communication offers enhanced protection by hiding the transmission behavior itself. Integrated sensing and communication (ISAC), a key technology of 6G, efficiently supports both sensing and communication tasks through hardware integration, thereby promising significant gains for covert communication. Nevertheless, the complexity and dynamics of urban environments pose critical challenges. Drawing on the latest advances in smart radio environment (SRE) technologies, this paper introduces them into integrated sensing and covert communication (ISACC) to suppress covert channel fading and counteract sensing precision loss in LANs. We first survey the applications and state-of-the-art findings of ISACC in LANs, highlighting key practical challenges. Subsequently, we introduce the core concept of SRE and elaborate on its enabling techniques across four dimensions. To deliver more insights, we explore potential pathways for integrating SRE into ISACC. To maximize covert throughput, a reinforcement learning-based case study is conducted by jointly optimizing flight trajectory, jamming power, movable antenna position, bandwidth allocation, and beamforming vectors. Simulation results show that the proposed scheme achieves superior performance compared to the benchmark. Finally, some open challenges and potential directions are discussed.
World Models: A Comprehensive Survey of Architectures, Methodologies, Reasoning Paradigms, and Applications
May 28, 2026World models, internal simulators that learn the structure and dynamics of an environment, have emerged as a central paradigm in the pursuit of artificial general intelligence, enabling agents to predict, plan, and reason within learned representations. Despite rapid progress across reinforcement learning, robotics, autonomous driving, and video generation, the field lacks a unified framework integrating its diverse architectural choices, training methods, reasoning mechanisms, and application settings. This survey addresses that gap with a multi-axis taxonomy organized along four dimensions: (i) architecture, encompassing representation format, dynamics formulation, input modality, learning paradigm, and downstream application; (ii) methodological family, including state-space and recurrent approaches, transformer-based models, diffusion-based generators, physics-informed networks, and language-augmented multimodal systems; (iii) reasoning strategy, covering imagination-based planning, latent policy learning, counterfactual reasoning, and planning under uncertainty; and (iv) application domain, spanning robotics, autonomous driving, video prediction, multimodal agents, reinforcement learning, scientific modeling, medical imaging, educational measurement, and business and finance. Tracing the field from early cognitive-science foundations to milestone systems such as PlaNet, the Dreamer family, MuZero, Sora, Cosmos, and Genie, we examine how these dimensions interact and highlight the recent convergence of chain-of-thought reasoning with world-model imagination. We review evaluation protocols and benchmarks, identify persistent challenges such as compounding prediction errors, sim-to-real transfer, and fragmented evaluation, and outline future directions toward unified multimodal world models, foundation-scale interactive simulators, and safe deployment in safety-critical domains.
ECHO: Efficient Chest X-ray Report Generation with One-step Block Diffusion
Apr 10, 2026Chest X-ray report generation (CXR-RG) has the potential to substantially alleviate radiologists' workload. However, conventional autoregressive vision--language models (VLMs) suffer from high inference latency due to sequential token decoding. Diffusion-based models offer a promising alternative through parallel generation, but they still require multiple denoising iterations. Compressing multi-step denoising to a single step could further reduce latency, but often degrades textual coherence due to the mean-field bias introduced by token-factorized denoisers. To address this challenge, we propose \textbf{ECHO}, an efficient diffusion-based VLM (dVLM) for chest X-ray report generation. ECHO enables stable one-step-per-block inference via a novel Direct Conditional Distillation (DCD) framework, which mitigates the mean-field limitation by constructing unfactorized supervision from on-policy diffusion trajectories to encode joint token dependencies. In addition, we introduce a Response-Asymmetric Diffusion (RAD) training strategy that further improves training efficiency while maintaining model effectiveness. Extensive experiments demonstrate that ECHO surpasses state-of-the-art autoregressive methods, improving RaTE and SemScore by \textbf{64.33\%} and \textbf{60.58\%} respectively, while achieving an \textbf{$8\times$} inference speedup without compromising clinical accuracy.
Detail++: Training-Free Detail Enhancer for Text-to-Image Diffusion Models
Jul 23, 2025Recent advances in text-to-image (T2I) generation have led to impressive visual results. However, these models still face significant challenges when handling complex prompt, particularly those involving multiple subjects with distinct attributes. Inspired by the human drawing process, which first outlines the composition and then incrementally adds details, we propose Detail++, a training-free framework that introduces a novel Progressive Detail Injection (PDI) strategy to address this limitation. Specifically, we decompose a complex prompt into a sequence of simplified sub-prompts, guiding the generation process in stages. This staged generation leverages the inherent layout-controlling capacity of self-attention to first ensure global composition, followed by precise refinement. To achieve accurate binding between attributes and corresponding subjects, we exploit cross-attention mechanisms and further introduce a Centroid Alignment Loss at test time to reduce binding noise and enhance attribute consistency. Extensive experiments on T2I-CompBench and a newly constructed style composition benchmark demonstrate that Detail++ significantly outperforms existing methods, particularly in scenarios involving multiple objects and complex stylistic conditions.
Blind Spot Navigation: Evolutionary Discovery of Sensitive Semantic Concepts for LVLMs
May 21, 2025



Adversarial attacks aim to generate malicious inputs that mislead deep models, but beyond causing model failure, they cannot provide certain interpretable information such as ``\textit{What content in inputs make models more likely to fail?}'' However, this information is crucial for researchers to specifically improve model robustness. Recent research suggests that models may be particularly sensitive to certain semantics in visual inputs (such as ``wet,'' ``foggy''), making them prone to errors. Inspired by this, in this paper we conducted the first exploration on large vision-language models (LVLMs) and found that LVLMs indeed are susceptible to hallucinations and various errors when facing specific semantic concepts in images. To efficiently search for these sensitive concepts, we integrated large language models (LLMs) and text-to-image (T2I) models to propose a novel semantic evolution framework. Randomly initialized semantic concepts undergo LLM-based crossover and mutation operations to form image descriptions, which are then converted by T2I models into visual inputs for LVLMs. The task-specific performance of LVLMs on each input is quantified as fitness scores for the involved semantics and serves as reward signals to further guide LLMs in exploring concepts that induce LVLMs. Extensive experiments on seven mainstream LVLMs and two multimodal tasks demonstrate the effectiveness of our method. Additionally, we provide interesting findings about the sensitive semantics of LVLMs, aiming to inspire further in-depth research.
StegaINR4MIH: steganography by implicit neural representation for multi-image hiding
Oct 14, 2024



Multi-image hiding, which embeds multiple secret images into a cover image and is able to recover these images with high quality, has gradually become a research hotspot in the field of image steganography. However, due to the need to embed a large amount of data in a limited cover image space, issues such as contour shadowing or color distortion often arise, posing significant challenges for multi-image hiding. In this paper, we propose StegaINR4MIH, a novel implicit neural representation steganography framework that enables the hiding of multiple images within a single implicit representation function. In contrast to traditional methods that use multiple encoders to achieve multi-image embedding, our approach leverages the redundancy of implicit representation function parameters and employs magnitude-based weight selection and secret weight substitution on pre-trained cover image functions to effectively hide and independently extract multiple secret images. We conduct experiments on images with a resolution of from three different datasets: CelebA-HQ, COCO, and DIV2K. When hiding two secret images, the PSNR values of both the secret images and the stego images exceed 42. When hiding five secret images, the PSNR values of both the secret images and the stego images exceed 39. Extensive experiments demonstrate the superior performance of the proposed method in terms of visual quality and undetectability.
Content and Salient Semantics Collaboration for Cloth-Changing Person Re-Identification
May 26, 2024



Cloth-changing person Re-IDentification (Re-ID) aims at recognizing the same person with clothing changes across non-overlapping cameras. Conventional person Re-ID methods usually bias the model's focus on cloth-related appearance features rather than identity-sensitive features associated with biological traits. Recently, advanced cloth-changing person Re-ID methods either resort to identity-related auxiliary modalities (e.g., sketches, silhouettes, keypoints and 3D shapes) or clothing labels to mitigate the impact of clothes. However, relying on unpractical and inflexible auxiliary modalities or annotations limits their real-world applicability. In this paper, we promote cloth-changing person Re-ID by effectively leveraging abundant semantics present within pedestrian images without the need for any auxiliaries. Specifically, we propose the Content and Salient Semantics Collaboration (CSSC) framework, facilitating cross-parallel semantics interaction and refinement. Our framework is simple yet effective, and the vital design is the Semantics Mining and Refinement (SMR) module. It extracts robust identity features about content and salient semantics, while mitigating interference from clothing appearances effectively. By capitalizing on the mined abundant semantic features, our proposed approach achieves state-of-the-art performance on three cloth-changing benchmarks as well as conventional benchmarks, demonstrating its superiority over advanced competitors.
2SFGL: A Simple And Robust Protocol For Graph-Based Fraud Detection
Oct 12, 2023



Financial crime detection using graph learning improves financial safety and efficiency. However, criminals may commit financial crimes across different institutions to avoid detection, which increases the difficulty of detection for financial institutions which use local data for graph learning. As most financial institutions are subject to strict regulations in regards to data privacy protection, the training data is often isolated and conventional learning technology cannot handle the problem. Federated learning (FL) allows multiple institutions to train a model without revealing their datasets to each other, hence ensuring data privacy protection. In this paper, we proposes a novel two-stage approach to federated graph learning (2SFGL): The first stage of 2SFGL involves the virtual fusion of multiparty graphs, and the second involves model training and inference on the virtual graph. We evaluate our framework on a conventional fraud detection task based on the FraudAmazonDataset and FraudYelpDataset. Experimental results show that integrating and applying a GCN (Graph Convolutional Network) with our 2SFGL framework to the same task results in a 17.6\%-30.2\% increase in performance on several typical metrics compared to the case only using FedAvg, while integrating GraphSAGE with 2SFGL results in a 6\%-16.2\% increase in performance compared to the case only using FedAvg. We conclude that our proposed framework is a robust and simple protocol which can be simply integrated to pre-existing graph-based fraud detection methods.
Local Slot Attention for Vision-and-Language Navigation
Jun 22, 2022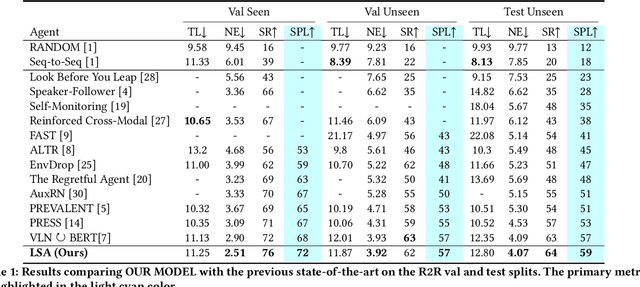
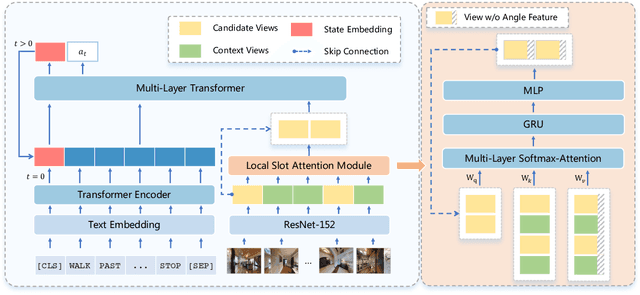
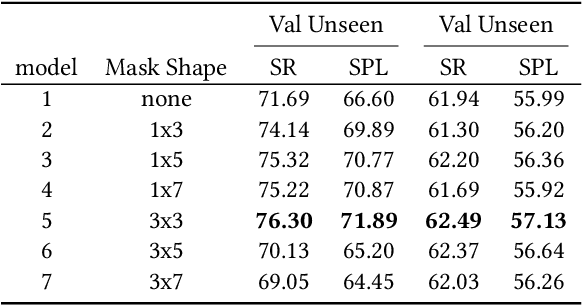

Vision-and-language navigation (VLN), a frontier study aiming to pave the way for general-purpose robots, has been a hot topic in the computer vision and natural language processing community. The VLN task requires an agent to navigate to a goal location following natural language instructions in unfamiliar environments. Recently, transformer-based models have gained significant improvements on the VLN task. Since the attention mechanism in the transformer architecture can better integrate inter- and intra-modal information of vision and language. However, there exist two problems in current transformer-based models. 1) The models process each view independently without taking the integrity of the objects into account. 2) During the self-attention operation in the visual modality, the views that are spatially distant can be inter-weaved with each other without explicit restriction. This kind of mixing may introduce extra noise instead of useful information. To address these issues, we propose 1) A slot-attention based module to incorporate information from segmentation of the same object. 2) A local attention mask mechanism to limit the visual attention span. The proposed modules can be easily plugged into any VLN architecture and we use the Recurrent VLN-Bert as our base model. Experiments on the R2R dataset show that our model has achieved the state-of-the-art results.