 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM3D: Zero-Shot Semi-Automatic Segmentation in 3D Medical Images with the Segment Anything Model
May 10, 2024



We introduce SAM3D, a new approach to semi-automatic zero-shot segmentation of 3D images building on the existing Segment Anything Model. We achieve fast and accurate segmentations in 3D images with a four-step strategy comprising: volume slicing along non-orthogonal axes, efficient prompting in 3D, slice-wise inference using the pretrained SAM, and recoposition and refinement in 3D. We evaluated SAM3D performance qualitatively on an array of imaging modalities and anatomical structures and quantify performance for specific organs in body CT and tumors in brain MRI. By enabling users to create 3D segmentations of unseen data quickly and with dramatically reduced manual input, these methods have the potential to aid surgical planning and education, diagnostic imaging, and scientific research.
Region-specific Risk Quantification for Interpretable Prognosis of COVID-19
May 05, 2024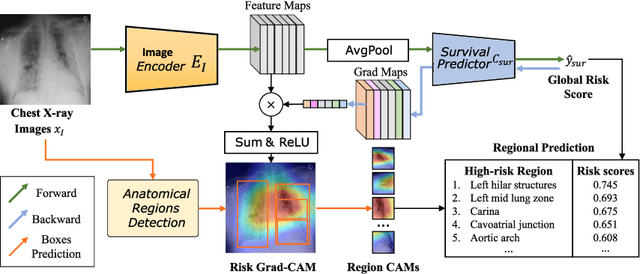
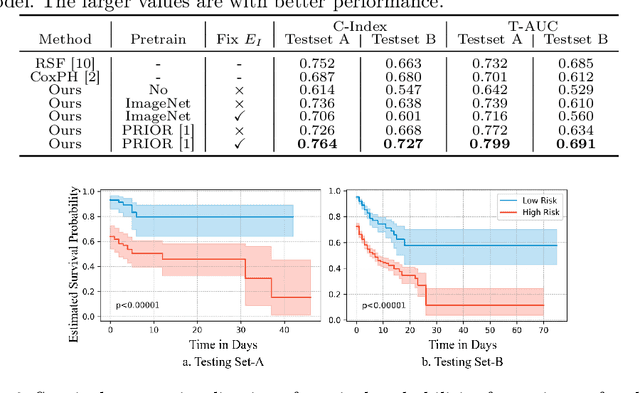

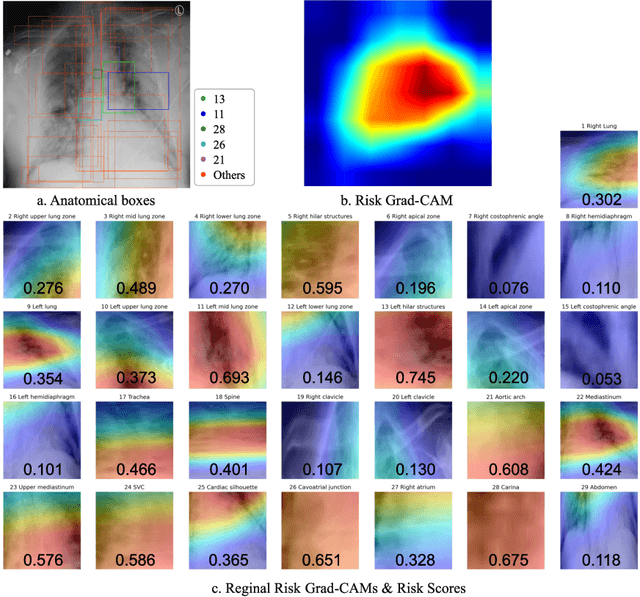
The COVID-19 pandemic has strained global public health, necessitating accurate diagnosis and intervention to control disease spread and reduce mortality rates. This paper introduces an interpretable deep survival prediction model designed specifically for improved understanding and trust in COVID-19 prognosis using chest X-ray (CXR) images. By integrating a large-scale pretrained image encoder, Risk-specific Grad-CAM, and anatomical region detection techniques, our approach produces regional interpretable outcomes that effectively capture essential disease features while focusing on rare but critical abnormal regions. Our model's predictive results provide enhanced clarity and transparency through risk area localization, enabling clinicians to make informed decisions regarding COVID-19 diagnosis with better understanding of prognostic insights. We evaluate the proposed method on a multi-center survival dataset and demonstrate its effectiveness via quantitative and qualitative assessments, achieving superior C-indexes (0.764 and 0.727) and time-dependent AUCs (0.799 and 0.691). These results suggest that our explainable deep survival prediction model surpasses traditional survival analysis methods in risk prediction, improving interpretability for clinical decision making and enhancing AI system trustworthiness.
Policy Bifurcation in Safe Reinforcement Learning
Mar 28, 2024



Safe reinforcement learning (RL) offers advanced solutions to constrained optimal control problems. Existing studies in safe RL implicitly assume continuity in policy functions, where policies map states to actions in a smooth, uninterrupted manner; however, our research finds that in some scenarios, the feasible policy should be discontinuous or multi-valued, interpolating between discontinuous local optima can inevitably lead to constraint violations. We are the first to identify the generating mechanism of such a phenomenon, and employ topological analysis to rigorously prove the existence of policy bifurcation in safe RL, which corresponds to the contractibility of the reachable tuple. Our theorem reveals that in scenarios where the obstacle-free state space is non-simply connected, a feasible policy is required to be bifurcated, meaning its output action needs to change abruptly in response to the varying state. To train such a bifurcated policy, we propose a safe RL algorithm called multimodal policy optimization (MUPO), which utilizes a Gaussian mixture distribution as the policy output. The bifurcated behavior can be achieved by selecting the Gaussian component with the highest mixing coefficient. Besides, MUPO also integrates spectral normalization and forward KL divergence to enhance the policy's capability of exploring different modes. Experiments with vehicle control tasks show that our algorithm successfully learns the bifurcated policy and ensures satisfying safety, while a continuous policy suffers from inevitable constraint violations.
Towards Balanced RGB-TSDF Fusion for Consistent Semantic Scene Completion by 3D RGB Feature Completion and a Classwise Entropy Loss Function
Mar 25, 2024Semantic Scene Completion (SSC) aims to jointly infer semantics and occupancies of 3D scenes. Truncated Signed Distance Function (TSDF), a 3D encoding of depth, has been a common input for SSC. Furthermore, RGB-TSDF fusion, seems promising since these two modalities provide color and geometry information, respectively. Nevertheless, RGB-TSDF fusion has been considered nontrivial and commonly-used naive addition will result in inconsistent results. We argue that the inconsistency comes from the sparsity of RGB features upon projecting into 3D space, while TSDF features are dense, leading to imbalanced feature maps when summed up. To address this RGB-TSDF distribution difference, we propose a two-stage network with a 3D RGB feature completion module that completes RGB features with meaningful values for occluded areas. Moreover, we propose an effective classwise entropy loss function to punish inconsistency. Extensive experiments on public datasets verify that our method achieves state-of-the-art performance among methods that do not adopt extra data.
TBI Image/Text : Comprehensive Text and Image Datasets for Traumatic Brain Injury Research
Mar 14, 2024

In this paper, we introduce a new dataset in the medical field of Traumatic Brain Injury (TBI), called TBI-IT, which includes both electronic medical records (EMRs) and head CT images. This dataset is designed to enhance the accuracy of artificial intelligence in the diagnosis and treatment of TBI. This dataset, built upon the foundation of standard text and image data, incorporates specific annotations within the EMRs, extracting key content from the text information, and categorizes the annotation content of imaging data into five types: brain midline, hematoma, left cerebral ventricle, right cerebral ventricle and fracture. TBI-IT aims to be a foundational dataset for feature learning in image segmentation tasks and named entity recognition.
LocalGCL: Local-aware Contrastive Learning for Graphs
Feb 27, 2024Graph representation learning (GRL) makes considerable progress recently, which encodes graphs with topological structures into low-dimensional embeddings. Meanwhile, the time-consuming and costly process of annotating graph labels manually prompts the growth of self-supervised learning (SSL) techniques. As a dominant approach of SSL, Contrastive learning (CL) learns discriminative representations by differentiating between positive and negative samples. However, when applied to graph data, it overemphasizes global patterns while neglecting local structures. To tackle the above issue, we propose \underline{Local}-aware \underline{G}raph \underline{C}ontrastive \underline{L}earning (\textbf{\methnametrim}), a self-supervised learning framework that supplementarily captures local graph information with masking-based modeling compared with vanilla contrastive learning. Extensive experiments validate the superiority of \methname against state-of-the-art methods, demonstrating its promise as a comprehensive graph representation learner.
Diffusion Model Based Visual Compensation Guidance and Visual Difference Analysis for No-Reference Image Quality Assessment
Feb 22, 2024



Existing free-energy guided No-Reference Image Quality Assessment (NR-IQA) methods still suffer from finding a balance between learning feature information at the pixel level of the image and capturing high-level feature information and the efficient utilization of the obtained high-level feature information remains a challenge. As a novel class of state-of-the-art (SOTA) generative model, the diffusion model exhibits the capability to model intricate relationships, enabling a comprehensive understanding of images and possessing a better learning of both high-level and low-level visual features. In view of these, we pioneer the exploration of the diffusion model into the domain of NR-IQA. Firstly, we devise a new diffusion restoration network that leverages the produced enhanced image and noise-containing images, incorporating nonlinear features obtained during the denoising process of the diffusion model, as high-level visual information. Secondly, two visual evaluation branches are designed to comprehensively analyze the obtained high-level feature information. These include the visual compensation guidance branch, grounded in the transformer architecture and noise embedding strategy, and the visual difference analysis branch, built on the ResNet architecture and the residual transposed attention block. Extensive experiments are conducted on seven public NR-IQA datasets, and the results demonstrate that the proposed model outperforms SOTA methods for NR-IQA.
Advancing GenAI Assisted Programming--A Comparative Study on Prompt Efficiency and Code Quality Between GPT-4 and GLM-4
Feb 20, 2024



This study aims to explore the best practices for utilizing GenAI as a programming tool, through a comparative analysis between GPT-4 and GLM-4. By evaluating prompting strategies at different levels of complexity, we identify that simplest and straightforward prompting strategy yields best code generation results. Additionally, adding a CoT-like preliminary confirmation step would further increase the success rate. Our results reveal that while GPT-4 marginally outperforms GLM-4, the difference is minimal for average users. In our simplified evaluation model, we see a remarkable 30 to 100-fold increase in code generation efficiency over traditional coding norms. Our GenAI Coding Workshop highlights the effectiveness and accessibility of the prompting methodology developed in this study. We observe that GenAI-assisted coding would trigger a paradigm shift in programming landscape, which necessitates developers to take on new roles revolving around supervising and guiding GenAI, and to focus more on setting high-level objectives and engaging more towards innovation.
HICH Image/Text : Comprehensive Text and Image Datasets for Hypertensive Intracerebral Hemorrhage Research
Feb 05, 2024In this paper, we introduce a new dataset in the medical field of hypertensive intracerebral hemorrhage (HICH), called HICH-IT, which includes both electronic medical records (EMRs) and head CT images. This dataset is designed to enhance the accuracy of artificial intelligence in the diagnosis and treatment of HICH. This dataset, built upon the foundation of standard text and image data, incorporates specific annotations within the EMRs, extracting key content from the text information, and categorizes the annotation content of imaging data into four types: brain midline, hematoma, left and right cerebral ventricle. HICH-IT aims to be a foundational dataset for feature learning in image segmentation tasks and named entity recognition. To further understand the dataset, we have trained deep learning algorithms to observe the performance. The pretrained models have been released at both www.daip.club and github.com/Deep-AI-Application-DAIP. The dataset has been uploaded to https://github.com/CYBUS123456/HICH-IT-Datasets. Index Terms-HICH, Deep learning, Intraparenchymal hemorrhage, named entity recognition, novel dataset
Seeing is not always believing: The Space of Harmless Perturbations
Feb 03, 2024



In the context of deep neural networks, we expose the existence of a harmless perturbation space, where perturbations leave the network output entirely unaltered. Perturbations within this harmless perturbation space, regardless of their magnitude when applied to images, exhibit no impact on the network's outputs of the original images. Specifically, given any linear layer within the network, where the input dimension $n$ exceeds the output dimension $m$, we demonstrate the existence of a continuous harmless perturbation subspace with a dimension of $(n-m)$. Inspired by this, we solve for a family of general perturbations that consistently influence the network output, irrespective of their magnitudes. With these theoretical findings, we explore the application of harmless perturbations for privacy-preserving data usage. Our work reveals the difference between DNNs and human perception that the significant perturbations captured by humans may not affect the recognition of DNNs. As a result, we utilize this gap to design a type of harmless perturbation that is meaningless for humans while maintaining its recognizable features for DNNs.