 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJie Huang
Neural Degradation Representation Learning for All-In-One Image Restoration
Oct 19, 2023
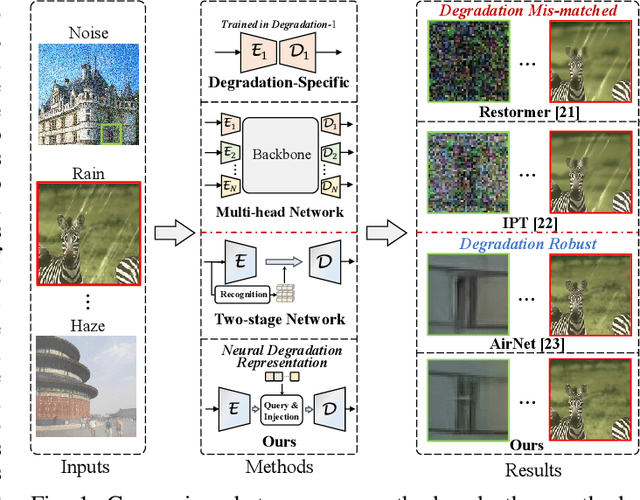
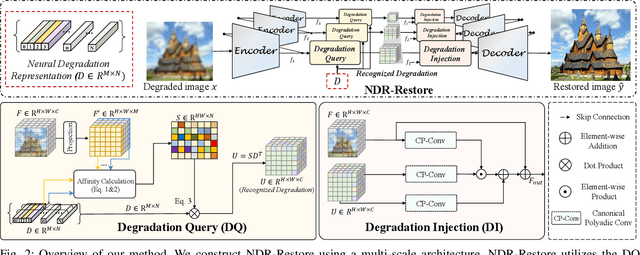
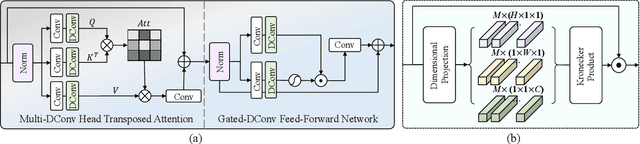
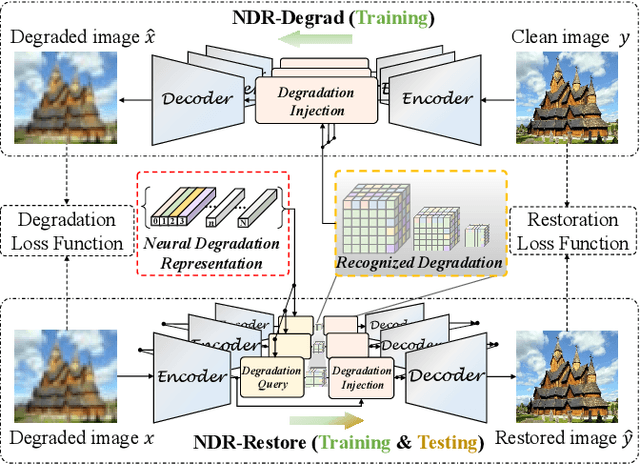
Existing methods have demonstrated effective performance on a single degradation type. In practical applications, however, the degradation is often unknown, and the mismatch between the model and the degradation will result in a severe performance drop. In this paper, we propose an all-in-one image restoration network that tackles multiple degradations. Due to the heterogeneous nature of different types of degradations, it is difficult to process multiple degradations in a single network. To this end, we propose to learn a neural degradation representation (NDR) that captures the underlying characteristics of various degradations. The learned NDR decomposes different types of degradations adaptively, similar to a neural dictionary that represents basic degradation components. Subsequently, we develop a degradation query module and a degradation injection module to effectively recognize and utilize the specific degradation based on NDR, enabling the all-in-one restoration ability for multiple degradations. Moreover, we propose a bidirectional optimization strategy to effectively drive NDR to learn the degradation representation by optimizing the degradation and restoration processes alternately. Comprehensive experiments on representative types of degradations (including noise, haze, rain, and downsampling) demonstrate the effectiveness and generalization capability of our method.
Descriptive Knowledge Graph in Biomedical Domain
Oct 18, 2023


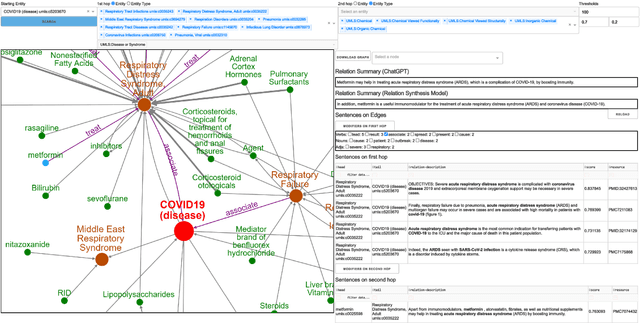
We present a novel system that automatically extracts and generates informative and descriptive sentences from the biomedical corpus and facilitates the efficient search for relational knowledge. Unlike previous search engines or exploration systems that retrieve unconnected passages, our system organizes descriptive sentences as a relational graph, enabling researchers to explore closely related biomedical entities (e.g., diseases treated by a chemical) or indirectly connected entities (e.g., potential drugs for treating a disease). Our system also uses ChatGPT and a fine-tuned relation synthesis model to generate concise and reliable descriptive sentences from retrieved information, reducing the need for extensive human reading effort. With our system, researchers can easily obtain both high-level knowledge and detailed references and interactively steer to the information of interest. We spotlight the application of our system in COVID-19 research, illustrating its utility in areas such as drug repurposing and literature curation.
Configuration Validation with Large Language Models
Oct 15, 2023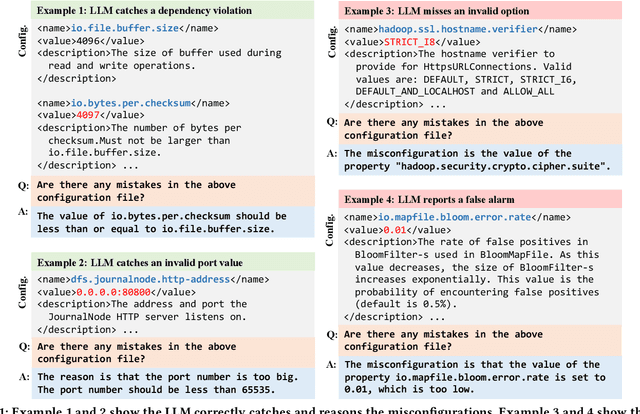

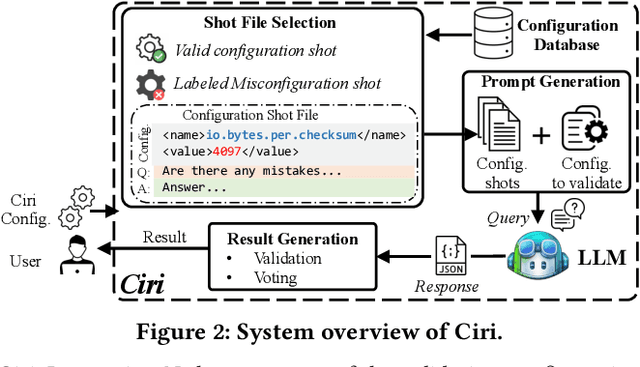
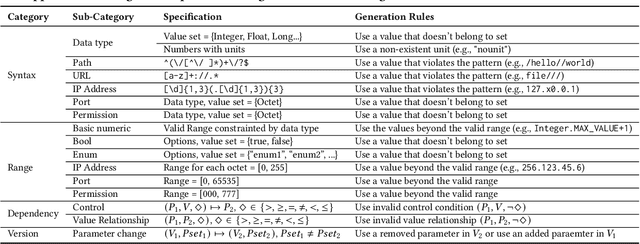
Misconfigurations are the major causes of software failures. Existing configuration validation techniques rely on manually written rules or test cases, which are expensive to implement and maintain, and are hard to be comprehensive. Leveraging machine learning (ML) and natural language processing (NLP) for configuration validation is considered a promising direction, but has been facing challenges such as the need of not only large-scale configuration data, but also system-specific features and models which are hard to generalize. Recent advances in Large Language Models (LLMs) show the promises to address some of the long-lasting limitations of ML/NLP-based configuration validation techniques. In this paper, we present an exploratory analysis on the feasibility and effectiveness of using LLMs like GPT and Codex for configuration validation. Specifically, we take a first step to empirically evaluate LLMs as configuration validators without additional fine-tuning or code generation. We develop a generic LLM-based validation framework, named Ciri, which integrates different LLMs. Ciri devises effective prompt engineering with few-shot learning based on both valid configuration and misconfiguration data. Ciri also validates and aggregates the outputs of LLMs to generate validation results, coping with known hallucination and nondeterminism of LLMs. We evaluate the validation effectiveness of Ciri on five popular LLMs using configuration data of six mature, widely deployed open-source systems. Our analysis (1) confirms the potential of using LLMs for configuration validation, (2) understands the design space of LLMbased validators like Ciri, especially in terms of prompt engineering with few-shot learning, and (3) reveals open challenges such as ineffectiveness in detecting certain types of misconfigurations and biases to popular configuration parameters.
Debias the Training of Diffusion Models
Oct 12, 2023Diffusion models have demonstrated compelling generation quality by optimizing the variational lower bound through a simple denoising score matching loss. In this paper, we provide theoretical evidence that the prevailing practice of using a constant loss weight strategy in diffusion models leads to biased estimation during the training phase. Simply optimizing the denoising network to predict Gaussian noise with constant weighting may hinder precise estimations of original images. To address the issue, we propose an elegant and effective weighting strategy grounded in the theoretically unbiased principle. Moreover, we conduct a comprehensive and systematic exploration to dissect the inherent bias problem deriving from constant weighting loss from the perspectives of its existence, impact and reasons. These analyses are expected to advance our understanding and demystify the inner workings of diffusion models. Through empirical evaluation, we demonstrate that our proposed debiased estimation method significantly enhances sample quality without the reliance on complex techniques, and exhibits improved efficiency compared to the baseline method both in training and sampling processes.
Large Language Models Cannot Self-Correct Reasoning Yet
Oct 03, 2023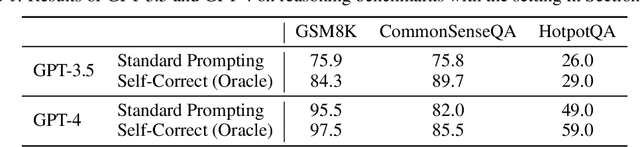
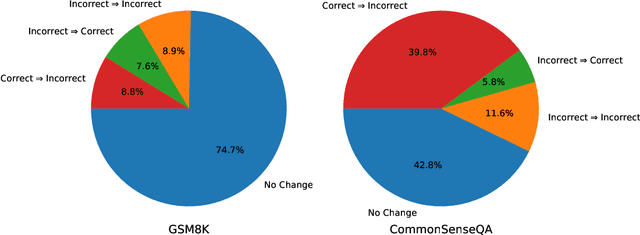
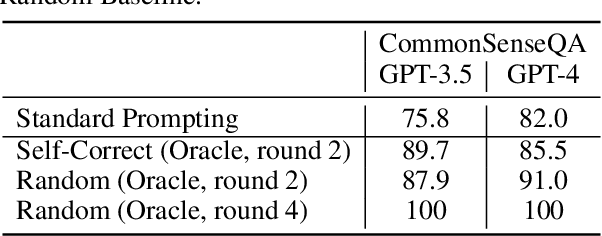

Large Language Models (LLMs) have emerged as a groundbreaking technology with their unparalleled text generation capabilities across various applications. Nevertheless, concerns persist regarding the accuracy and appropriateness of their generated content. A contemporary methodology, self-correction, has been proposed as a remedy to these issues. Building upon this premise, this paper critically examines the role and efficacy of self-correction within LLMs, shedding light on its true potential and limitations. Central to our investigation is the notion of intrinsic self-correction, whereby an LLM attempts to correct its initial responses based solely on its inherent capabilities, without the crutch of external feedback. In the context of reasoning, our research indicates that LLMs struggle to self-correct their responses without external feedback, and at times, their performance might even degrade post self-correction. Drawing from these insights, we offer suggestions for future research and practical applications in this field.
Empowering Low-Light Image Enhancer through Customized Learnable Priors
Sep 05, 2023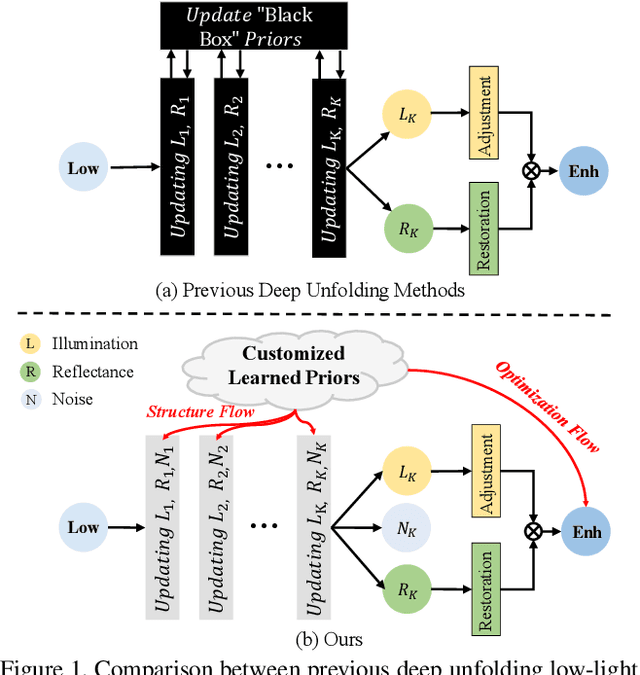
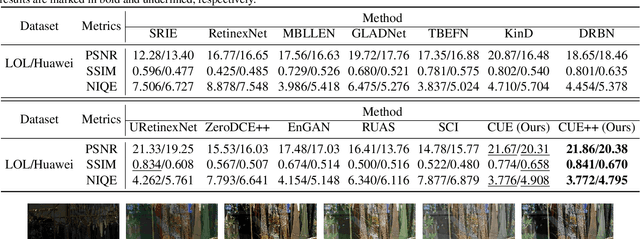
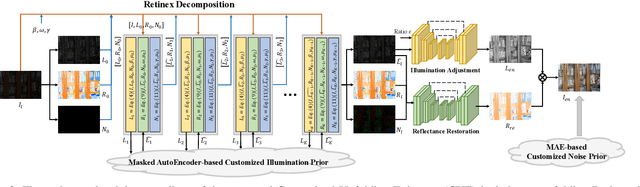

Deep neural networks have achieved remarkable progress in enhancing low-light images by improving their brightness and eliminating noise. However, most existing methods construct end-to-end mapping networks heuristically, neglecting the intrinsic prior of image enhancement task and lacking transparency and interpretability. Although some unfolding solutions have been proposed to relieve these issues, they rely on proximal operator networks that deliver ambiguous and implicit priors. In this work, we propose a paradigm for low-light image enhancement that explores the potential of customized learnable priors to improve the transparency of the deep unfolding paradigm. Motivated by the powerful feature representation capability of Masked Autoencoder (MAE), we customize MAE-based illumination and noise priors and redevelop them from two perspectives: 1) \textbf{structure flow}: we train the MAE from a normal-light image to its illumination properties and then embed it into the proximal operator design of the unfolding architecture; and m2) \textbf{optimization flow}: we train MAE from a normal-light image to its gradient representation and then employ it as a regularization term to constrain noise in the model output. These designs improve the interpretability and representation capability of the model.Extensive experiments on multiple low-light image enhancement datasets demonstrate the superiority of our proposed paradigm over state-of-the-art methods. Code is available at https://github.com/zheng980629/CUE.
Learned Image Reasoning Prior Penetrates Deep Unfolding Network for Panchromatic and Multi-Spectral Image Fusion
Aug 30, 2023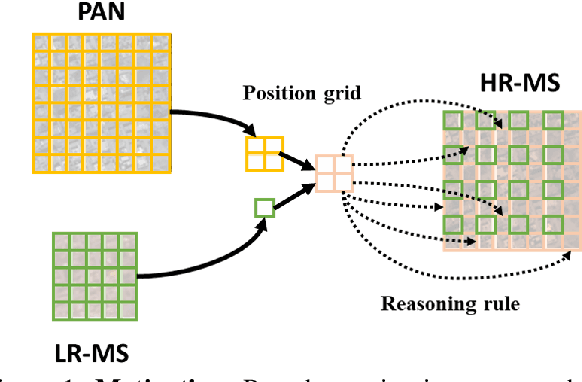
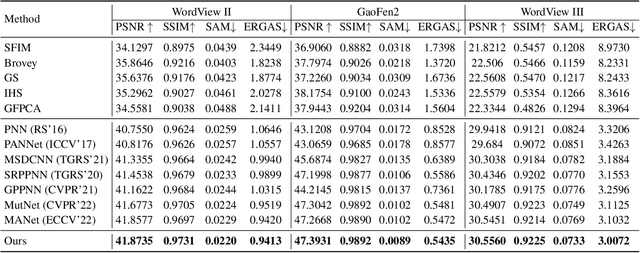
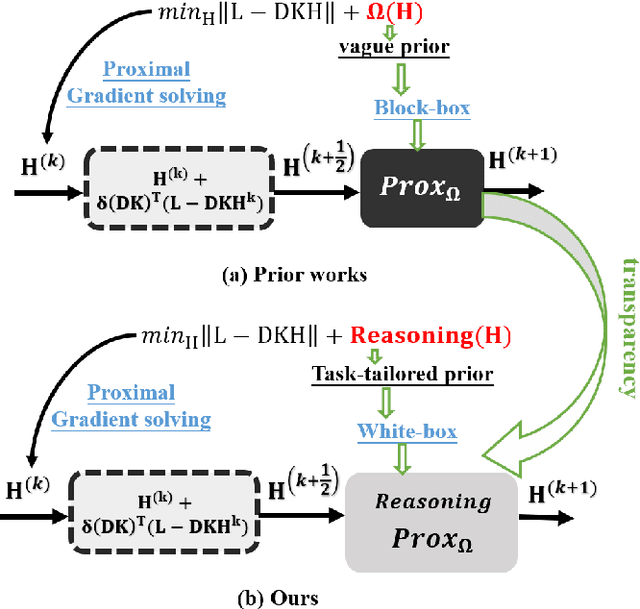
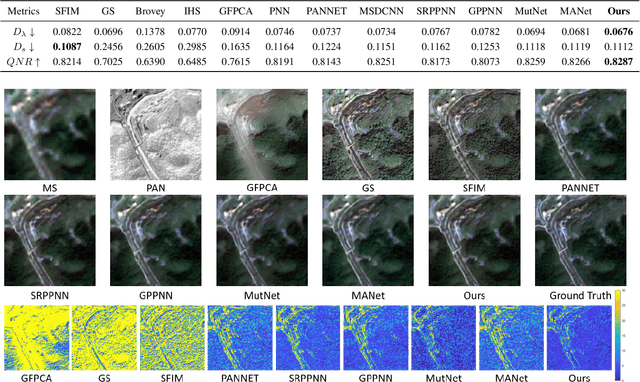
The success of deep neural networks for pan-sharpening is commonly in a form of black box, lacking transparency and interpretability. To alleviate this issue, we propose a novel model-driven deep unfolding framework with image reasoning prior tailored for the pan-sharpening task. Different from existing unfolding solutions that deliver the proximal operator networks as the uncertain and vague priors, our framework is motivated by the content reasoning ability of masked autoencoders (MAE) with insightful designs. Specifically, the pre-trained MAE with spatial masking strategy, acting as intrinsic reasoning prior, is embedded into unfolding architecture. Meanwhile, the pre-trained MAE with spatial-spectral masking strategy is treated as the regularization term within loss function to constrain the spatial-spectral consistency. Such designs penetrate the image reasoning prior into deep unfolding networks while improving its interpretability and representation capability. The uniqueness of our framework is that the holistic learning process is explicitly integrated with the inherent physical mechanism underlying the pan-sharpening task. Extensive experiments on multiple satellite datasets demonstrate the superiority of our method over the existing state-of-the-art approaches. Code will be released at \url{https://manman1995.github.io/}.
Situated Natural Language Explanations
Aug 27, 2023


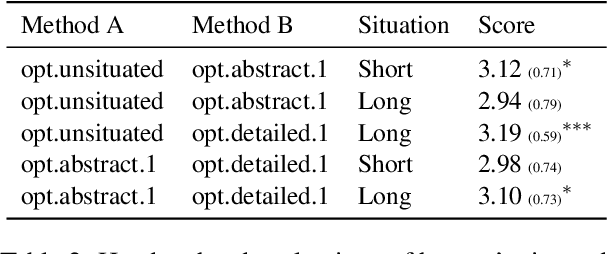
Natural language is among the most accessible tools for explaining decisions to humans, and large pretrained language models (PLMs) have demonstrated impressive abilities to generate coherent natural language explanations (NLE). The existing NLE research perspectives do not take the audience into account. An NLE can have high textual quality, but it might not accommodate audiences' needs and preference. To address this limitation, we propose an alternative perspective, situated NLE, including a situated generation framework and a situated evaluation framework. On the generation side, we propose simple prompt engineering methods that adapt the NLEs to situations. In human studies, the annotators preferred the situated NLEs. On the evaluation side, we set up automated evaluation scores in lexical, semantic, and pragmatic categories. The scores can be used to select the most suitable prompts to generate NLEs. Situated NLE provides a perspective to conduct further research on automatic NLE generations.
Generalized Lightness Adaptation with Channel Selective Normalization
Aug 26, 2023
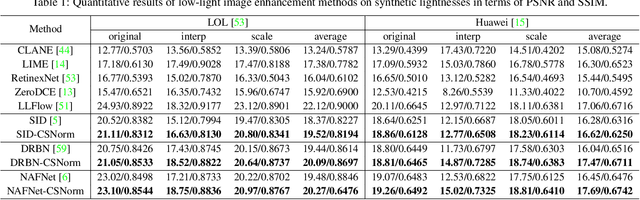
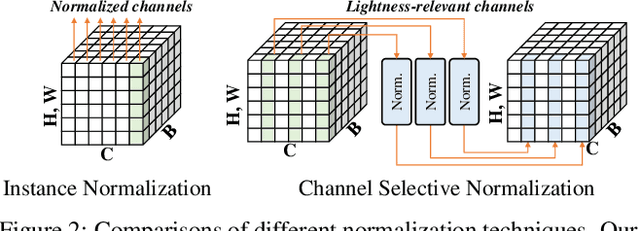
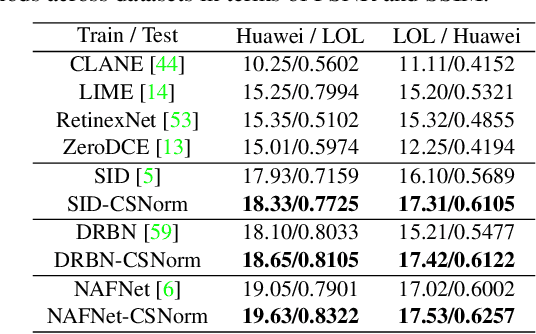
Lightness adaptation is vital to the success of image processing to avoid unexpected visual deterioration, which covers multiple aspects, e.g., low-light image enhancement, image retouching, and inverse tone mapping. Existing methods typically work well on their trained lightness conditions but perform poorly in unknown ones due to their limited generalization ability. To address this limitation, we propose a novel generalized lightness adaptation algorithm that extends conventional normalization techniques through a channel filtering design, dubbed Channel Selective Normalization (CSNorm). The proposed CSNorm purposely normalizes the statistics of lightness-relevant channels and keeps other channels unchanged, so as to improve feature generalization and discrimination. To optimize CSNorm, we propose an alternating training strategy that effectively identifies lightness-relevant channels. The model equipped with our CSNorm only needs to be trained on one lightness condition and can be well generalized to unknown lightness conditions. Experimental results on multiple benchmark datasets demonstrate the effectiveness of CSNorm in enhancing the generalization ability for the existing lightness adaptation methods. Code is available at https://github.com/mdyao/CSNorm.
High-quality Image Dehazing with Diffusion Model
Aug 23, 2023



Image dehazing is quite challenging in dense-haze scenarios, where quite less original information remains in the hazy image. Though previous methods have made marvelous progress, they still suffer from information loss in content and color in dense-haze scenarios. The recently emerged Denoising Diffusion Probabilistic Model (DDPM) exhibits strong generation ability, showing potential for solving this problem. However, DDPM fails to consider the physics property of dehazing task, limiting its information completion capacity. In this work, we propose DehazeDDPM: A DDPM-based and physics-aware image dehazing framework that applies to complex hazy scenarios. Specifically, DehazeDDPM works in two stages. The former stage physically models the dehazing task with the Atmospheric Scattering Model (ASM), pulling the distribution closer to the clear data and endowing DehazeDDPM with fog-aware ability. The latter stage exploits the strong generation ability of DDPM to compensate for the haze-induced huge information loss, by working in conjunction with the physical modelling. Extensive experiments demonstrate that our method attains state-of-the-art performance on both synthetic and real-world hazy datasets.