 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOv3R: Open-Vocabulary Semantic 3D Reconstruction from RGB Videos
Jul 29, 2025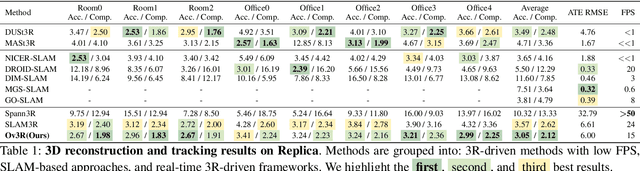
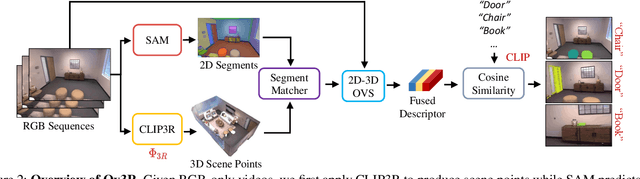

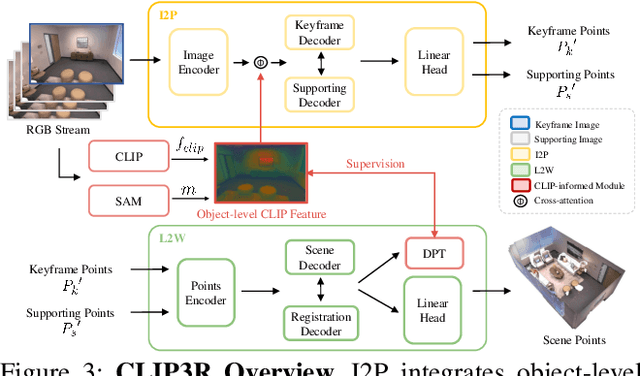
We present Ov3R, a novel framework for open-vocabulary semantic 3D reconstruction from RGB video streams, designed to advance Spatial AI. The system features two key components: CLIP3R, a CLIP-informed 3D reconstruction module that predicts dense point maps from overlapping clips while embedding object-level semantics; and 2D-3D OVS, a 2D-3D open-vocabulary semantic module that lifts 2D features into 3D by learning fused descriptors integrating spatial, geometric, and semantic cues. Unlike prior methods, Ov3R incorporates CLIP semantics directly into the reconstruction process, enabling globally consistent geometry and fine-grained semantic alignment. Our framework achieves state-of-the-art performance in both dense 3D reconstruction and open-vocabulary 3D segmentation, marking a step forward toward real-time, semantics-aware Spatial AI.
TaxoAdapt: Aligning LLM-Based Multidimensional Taxonomy Construction to Evolving Research Corpora
Jun 12, 2025The rapid evolution of scientific fields introduces challenges in organizing and retrieving scientific literature. While expert-curated taxonomies have traditionally addressed this need, the process is time-consuming and expensive. Furthermore, recent automatic taxonomy construction methods either (1) over-rely on a specific corpus, sacrificing generalizability, or (2) depend heavily on the general knowledge of large language models (LLMs) contained within their pre-training datasets, often overlooking the dynamic nature of evolving scientific domains. Additionally, these approaches fail to account for the multi-faceted nature of scientific literature, where a single research paper may contribute to multiple dimensions (e.g., methodology, new tasks, evaluation metrics, benchmarks). To address these gaps, we propose TaxoAdapt, a framework that dynamically adapts an LLM-generated taxonomy to a given corpus across multiple dimensions. TaxoAdapt performs iterative hierarchical classification, expanding both the taxonomy width and depth based on corpus' topical distribution. We demonstrate its state-of-the-art performance across a diverse set of computer science conferences over the years to showcase its ability to structure and capture the evolution of scientific fields. As a multidimensional method, TaxoAdapt generates taxonomies that are 26.51% more granularity-preserving and 50.41% more coherent than the most competitive baselines judged by LLMs.
Beyond True or False: Retrieval-Augmented Hierarchical Analysis of Nuanced Claims
Jun 12, 2025



Claims made by individuals or entities are oftentimes nuanced and cannot be clearly labeled as entirely "true" or "false" -- as is frequently the case with scientific and political claims. However, a claim (e.g., "vaccine A is better than vaccine B") can be dissected into its integral aspects and sub-aspects (e.g., efficacy, safety, distribution), which are individually easier to validate. This enables a more comprehensive, structured response that provides a well-rounded perspective on a given problem while also allowing the reader to prioritize specific angles of interest within the claim (e.g., safety towards children). Thus, we propose ClaimSpect, a retrieval-augmented generation-based framework for automatically constructing a hierarchy of aspects typically considered when addressing a claim and enriching them with corpus-specific perspectives. This structure hierarchically partitions an input corpus to retrieve relevant segments, which assist in discovering new sub-aspects. Moreover, these segments enable the discovery of varying perspectives towards an aspect of the claim (e.g., support, neutral, or oppose) and their respective prevalence (e.g., "how many biomedical papers believe vaccine A is more transportable than B?"). We apply ClaimSpect to a wide variety of real-world scientific and political claims featured in our constructed dataset, showcasing its robustness and accuracy in deconstructing a nuanced claim and representing perspectives within a corpus. Through real-world case studies and human evaluation, we validate its effectiveness over multiple baselines.
CC-RAG: Structured Multi-Hop Reasoning via Theme-Based Causal Graphs
Jun 11, 2025Understanding cause and effect relationships remains a formidable challenge for Large Language Models (LLMs), particularly in specialized domains where reasoning requires more than surface-level correlations. Retrieval-Augmented Generation (RAG) improves factual accuracy, but standard RAG pipelines treat evidence as flat context, lacking the structure required to model true causal dependencies. We introduce Causal-Chain RAG (CC-RAG), a novel approach that integrates zero-shot triple extraction and theme-aware graph chaining into the RAG pipeline, enabling structured multi-hop inference. Given a domain specific corpus, CC-RAG constructs a Directed Acyclic Graph (DAG) of <cause, relation, effect> triples and uses forward/backward chaining to guide structured answer generation. Experiments on two real-world domains: Bitcoin price fluctuations and Gaucher disease, show that CC-RAG outperforms standard RAG and zero-shot LLMs in chain similarity, information density, and lexical diversity. Both LLM-as-a-Judge and human evaluations consistently favor CC-RAG. Our results demonstrate that explicitly modeling causal structure enables LLMs to generate more accurate and interpretable responses, especially in specialized domains where flat retrieval fails.
Zero-Shot Open-Schema Entity Structure Discovery
Jun 04, 2025Entity structure extraction, which aims to extract entities and their associated attribute-value structures from text, is an essential task for text understanding and knowledge graph construction. Existing methods based on large language models (LLMs) typically rely heavily on predefined entity attribute schemas or annotated datasets, often leading to incomplete extraction results. To address these challenges, we introduce Zero-Shot Open-schema Entity Structure Discovery (ZOES), a novel approach to entity structure extraction that does not require any schema or annotated samples. ZOES operates via a principled mechanism of enrichment, refinement, and unification, based on the insight that an entity and its associated structure are mutually reinforcing. Experiments demonstrate that ZOES consistently enhances LLMs' ability to extract more complete entity structures across three different domains, showcasing both the effectiveness and generalizability of the method. These findings suggest that such an enrichment, refinement, and unification mechanism may serve as a principled approach to improving the quality of LLM-based entity structure discovery in various scenarios.
Scientific Paper Retrieval with LLM-Guided Semantic-Based Ranking
May 27, 2025Scientific paper retrieval is essential for supporting literature discovery and research. While dense retrieval methods demonstrate effectiveness in general-purpose tasks, they often fail to capture fine-grained scientific concepts that are essential for accurate understanding of scientific queries. Recent studies also use large language models (LLMs) for query understanding; however, these methods often lack grounding in corpus-specific knowledge and may generate unreliable or unfaithful content. To overcome these limitations, we propose SemRank, an effective and efficient paper retrieval framework that combines LLM-guided query understanding with a concept-based semantic index. Each paper is indexed using multi-granular scientific concepts, including general research topics and detailed key phrases. At query time, an LLM identifies core concepts derived from the corpus to explicitly capture the query's information need. These identified concepts enable precise semantic matching, significantly enhancing retrieval accuracy. Experiments show that SemRank consistently improves the performance of various base retrievers, surpasses strong existing LLM-based baselines, and remains highly efficient.
Hypercube-RAG: Hypercube-Based Retrieval-Augmented Generation for In-domain Scientific Question-Answering
May 25, 2025



Large language models (LLMs) often need to incorporate external knowledge to solve theme-specific problems. Retrieval-augmented generation (RAG), which empowers LLMs to generate more qualified responses with retrieved external data and knowledge, has shown its high promise. However, traditional semantic similarity-based RAGs struggle to return concise yet highly relevant information for domain knowledge-intensive tasks, such as scientific question-answering (QA). Built on a multi-dimensional (cube) structure called Hypercube, which can index documents in an application-driven, human-defined, multi-dimensional space, we introduce the Hypercube-RAG, a novel RAG framework for precise and efficient retrieval. Given a query, Hypercube-RAG first decomposes it based on its entities and topics and then retrieves relevant documents from cubes by aligning these decomposed components with hypercube dimensions. Experiments on three in-domain scientific QA datasets demonstrate that our method improves accuracy by 3.7% and boosts retrieval efficiency by 81.2%, measured as relative gains over the strongest RAG baseline. More importantly, our Hypercube-RAG inherently offers explainability by revealing the underlying predefined hypercube dimensions used for retrieval. The code and data sets are available at https://github.com/JimengShi/Hypercube-RAG.
Hybrid Latent Reasoning via Reinforcement Learning
May 24, 2025Recent advances in large language models (LLMs) have introduced latent reasoning as a promising alternative to autoregressive reasoning. By performing internal computation with hidden states from previous steps, latent reasoning benefit from more informative features rather than sampling a discrete chain-of-thought (CoT) path. Yet latent reasoning approaches are often incompatible with LLMs, as their continuous paradigm conflicts with the discrete nature of autoregressive generation. Moreover, these methods rely on CoT traces for training and thus fail to exploit the inherent reasoning patterns of LLMs. In this work, we explore latent reasoning by leveraging the intrinsic capabilities of LLMs via reinforcement learning (RL). To this end, we introduce hybrid reasoning policy optimization (HRPO), an RL-based hybrid latent reasoning approach that (1) integrates prior hidden states into sampled tokens with a learnable gating mechanism, and (2) initializes training with predominantly token embeddings while progressively incorporating more hidden features. This design maintains LLMs' generative capabilities and incentivizes hybrid reasoning using both discrete and continuous representations. In addition, the hybrid HRPO introduces stochasticity into latent reasoning via token sampling, thereby enabling RL-based optimization without requiring CoT trajectories. Extensive evaluations across diverse benchmarks show that HRPO outperforms prior methods in both knowledge- and reasoning-intensive tasks. Furthermore, HRPO-trained LLMs remain interpretable and exhibit intriguing behaviors like cross-lingual patterns and shorter completion lengths, highlighting the potential of our RL-based approach and offer insights for future work in latent reasoning.
An Empirical Study on Reinforcement Learning for Reasoning-Search Interleaved LLM Agents
May 21, 2025



Reinforcement learning (RL) has demonstrated strong potential in training large language models (LLMs) capable of complex reasoning for real-world problem solving. More recently, RL has been leveraged to create sophisticated LLM-based search agents that adeptly combine reasoning with search engine use. While the use of RL for training search agents is promising, the optimal design of such agents remains not fully understood. In particular, key factors -- such as (1) reward formulation, (2) the choice and characteristics of the underlying LLM, and (3) the role of the search engine in the RL process -- require further investigation. In this work, we conduct comprehensive empirical studies to systematically investigate these and offer actionable insights. We highlight several key findings: format rewards are effective in improving final performance, whereas intermediate retrieval rewards have limited impact; the scale and initialization of the LLM (general-purpose vs. reasoning-specialized) significantly influence RL outcomes; and the choice of search engine plays a critical role in shaping RL training dynamics and the robustness of the trained agent during inference. These establish important guidelines for successfully building and deploying LLM-based search agents in real-world applications. Code is available at https://github.com/PeterGriffinJin/Search-R1.
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
May 21, 2025



Entropy minimization (EM) trains the model to concentrate even more probability mass on its most confident outputs. We show that this simple objective alone, without any labeled data, can substantially improve large language models' (LLMs) performance on challenging math, physics, and coding tasks. We explore three approaches: (1) EM-FT minimizes token-level entropy similarly to instruction finetuning, but on unlabeled outputs drawn from the model; (2) EM-RL: reinforcement learning with negative entropy as the only reward to maximize; (3) EM-INF: inference-time logit adjustment to reduce entropy without any training data or parameter updates. On Qwen-7B, EM-RL, without any labeled data, achieves comparable or better performance than strong RL baselines such as GRPO and RLOO that are trained on 60K labeled examples. Furthermore, EM-INF enables Qwen-32B to match or exceed the performance of proprietary models like GPT-4o, Claude 3 Opus, and Gemini 1.5 Pro on the challenging SciCode benchmark, while being 3x more efficient than self-consistency and sequential refinement. Our findings reveal that many pretrained LLMs possess previously underappreciated reasoning capabilities that can be effectively elicited through entropy minimization alone, without any labeled data or even any parameter updates.