 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Open-Schema Entity Structure Discovery
Jun 04, 2025Entity structure extraction, which aims to extract entities and their associated attribute-value structures from text, is an essential task for text understanding and knowledge graph construction. Existing methods based on large language models (LLMs) typically rely heavily on predefined entity attribute schemas or annotated datasets, often leading to incomplete extraction results. To address these challenges, we introduce Zero-Shot Open-schema Entity Structure Discovery (ZOES), a novel approach to entity structure extraction that does not require any schema or annotated samples. ZOES operates via a principled mechanism of enrichment, refinement, and unification, based on the insight that an entity and its associated structure are mutually reinforcing. Experiments demonstrate that ZOES consistently enhances LLMs' ability to extract more complete entity structures across three different domains, showcasing both the effectiveness and generalizability of the method. These findings suggest that such an enrichment, refinement, and unification mechanism may serve as a principled approach to improving the quality of LLM-based entity structure discovery in various scenarios.
QGen Studio: An Adaptive Question-Answer Generation, Training and Evaluation Platform
Apr 08, 2025We present QGen Studio: an adaptive question-answer generation, training, and evaluation platform. QGen Studio enables users to leverage large language models (LLMs) to create custom question-answer datasets and fine-tune models on this synthetic data. It features a dataset viewer and model explorer to streamline this process. The dataset viewer provides key metrics and visualizes the context from which the QA pairs are generated, offering insights into data quality. The model explorer supports model comparison, allowing users to contrast the performance of their trained LLMs against other models, supporting performance benchmarking and refinement. QGen Studio delivers an interactive, end-to-end solution for generating QA datasets and training scalable, domain-adaptable models. The studio will be open-sourced soon, allowing users to deploy it locally.
A Simple LSTM model for Transition-based Dependency Parsing
Sep 08, 2017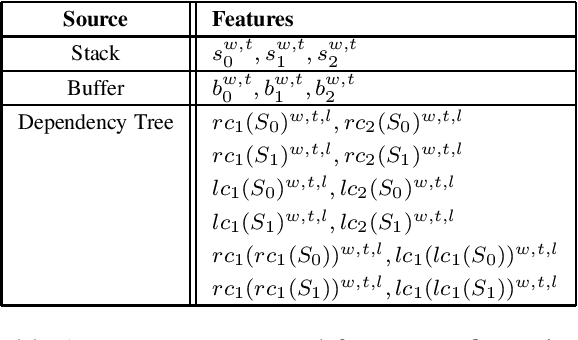
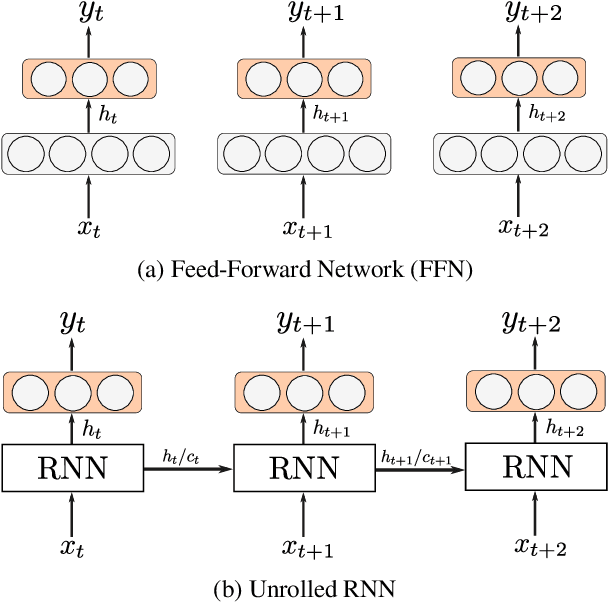
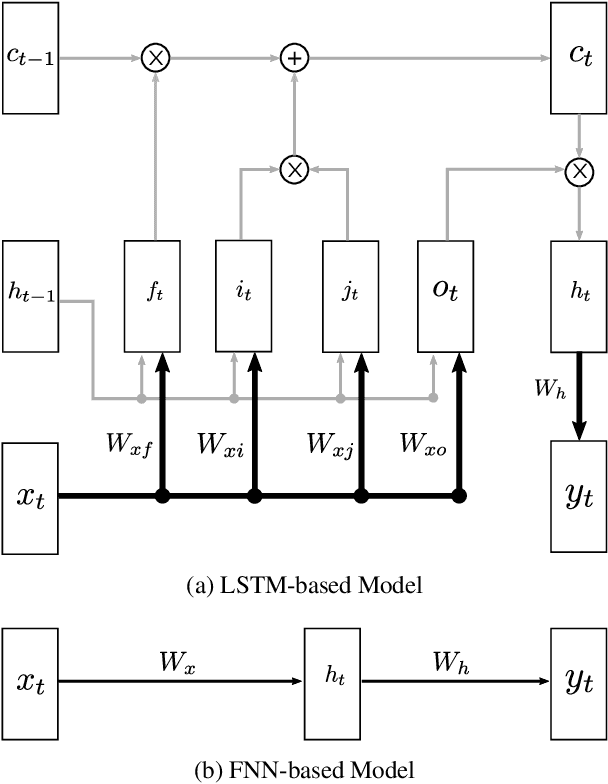
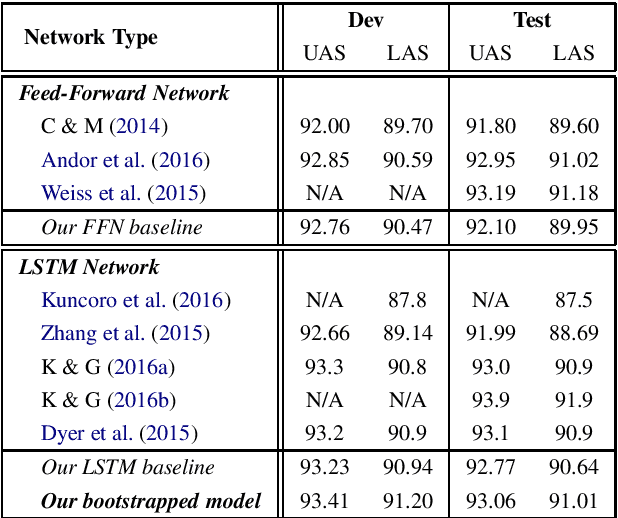
We present a simple LSTM-based transition-based dependency parser. Our model is composed of a single LSTM hidden layer replacing the hidden layer in the usual feed-forward network architecture. We also propose a new initialization method that uses the pre-trained weights from a feed-forward neural network to initialize our LSTM-based model. We also show that using dropout on the input layer has a positive effect on performance. Our final parser achieves a 93.06% unlabeled and 91.01% labeled attachment score on the Penn Treebank. We additionally replace LSTMs with GRUs and Elman units in our model and explore the effectiveness of our initialization method on individual gates constituting all three types of RNN units.