 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
An interactive enhanced driving dataset for autonomous driving
Feb 24, 2026The evolution of autonomous driving towards full automation demands robust interactive capabilities; however, the development of Vision-Language-Action (VLA) models is constrained by the sparsity of interactive scenarios and inadequate multimodal alignment in existing data. To this end, this paper proposes the Interactive Enhanced Driving Dataset (IEDD). We develop a scalable pipeline to mine million-level interactive segments from naturalistic driving data based on interactive trajectories, and design metrics to quantify the interaction processes. Furthermore, the IEDD-VQA dataset is constructed by generating synthetic Bird's Eye View (BEV) videos where semantic actions are strictly aligned with structured language. Benchmark results evaluating ten mainstream Vision Language Models (VLMs) are provided to demonstrate the dataset's reuse value in assessing and fine-tuning the reasoning capabilities of autonomous driving models.
Short-term electricity load forecasting with multi-frequency reconstruction diffusion
Jan 10, 2026Diffusion models have emerged as a powerful method in various applications. However, their application to Short-Term Electricity Load Forecasting (STELF) -- a typical scenario in energy systems -- remains largely unexplored. Considering the nonlinear and fluctuating characteristics of the load data, effectively utilizing the powerful modeling capabilities of diffusion models to enhance STELF accuracy remains a challenge. This paper proposes a novel diffusion model with multi-frequency reconstruction for STELF, referred to as the Multi-Frequency-Reconstruction-based Diffusion (MFRD) model. The MFRD model achieves accurate load forecasting through four key steps: (1) The original data is combined with the decomposed multi-frequency modes to form a new data representation; (2) The diffusion model adds noise to the new data, effectively reducing and weakening the noise in the original data; (3) The reverse process adopts a denoising network that combines Long Short-Term Memory (LSTM) and Transformer to enhance noise removal; and (4) The inference process generates the final predictions based on the trained denoising network. To validate the effectiveness of the MFRD model, we conducted experiments on two data platforms: Australian Energy Market Operator (AEMO) and Independent System Operator of New England (ISO-NE). The experimental results show that our model consistently outperforms the compared models.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Kimi-Audio Technical Report
Apr 25, 2025
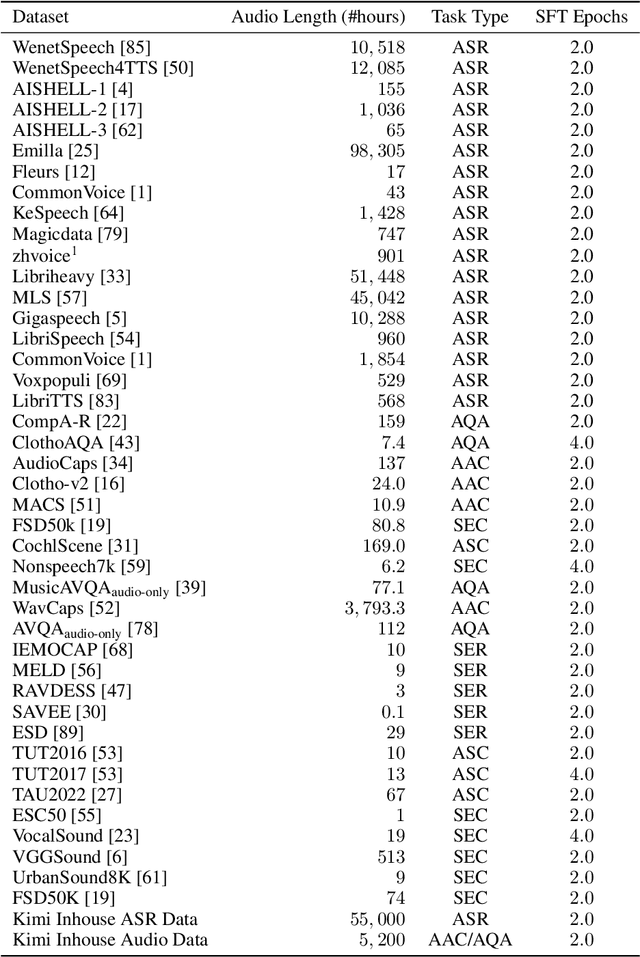
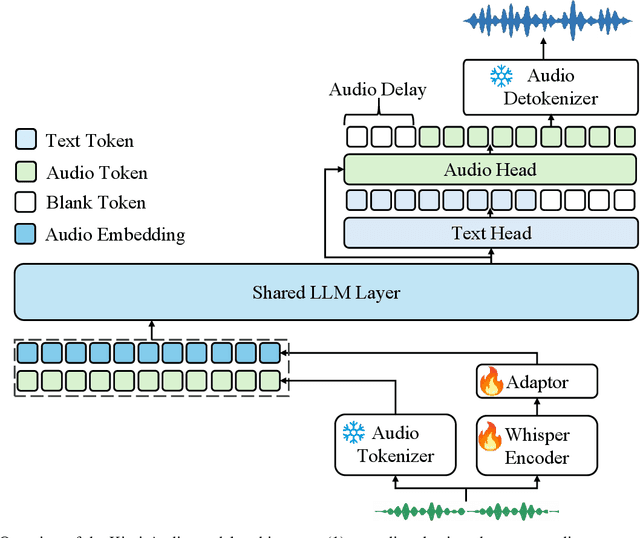
We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Muon is Scalable for LLM Training
Feb 24, 2025Recently, the Muon optimizer based on matrix orthogonalization has demonstrated strong results in training small-scale language models, but the scalability to larger models has not been proven. We identify two crucial techniques for scaling up Muon: (1) adding weight decay and (2) carefully adjusting the per-parameter update scale. These techniques allow Muon to work out-of-the-box on large-scale training without the need of hyper-parameter tuning. Scaling law experiments indicate that Muon achieves $\sim\!2\times$ computational efficiency compared to AdamW with compute optimal training. Based on these improvements, we introduce Moonlight, a 3B/16B-parameter Mixture-of-Expert (MoE) model trained with 5.7T tokens using Muon. Our model improves the current Pareto frontier, achieving better performance with much fewer training FLOPs compared to prior models. We open-source our distributed Muon implementation that is memory optimal and communication efficient. We also release the pretrained, instruction-tuned, and intermediate checkpoints to support future research.
Short-Term Electricity-Load Forecasting by Deep Learning: A Comprehensive Survey
Aug 29, 2024Short-Term Electricity-Load Forecasting (STELF) refers to the prediction of the immediate demand (in the next few hours to several days) for the power system. Various external factors, such as weather changes and the emergence of new electricity consumption scenarios, can impact electricity demand, causing load data to fluctuate and become non-linear, which increases the complexity and difficulty of STELF. In the past decade, deep learning has been applied to STELF, modeling and predicting electricity demand with high accuracy, and contributing significantly to the development of STELF. This paper provides a comprehensive survey on deep-learning-based STELF over the past ten years. It examines the entire forecasting process, including data pre-processing, feature extraction, deep-learning modeling and optimization, and results evaluation. This paper also identifies some research challenges and potential research directions to be further investigated in future work.
A novel hybrid model based on multi-objective Harris hawks optimization algorithm for daily PM2.5 and PM10 forecasting
May 30, 2019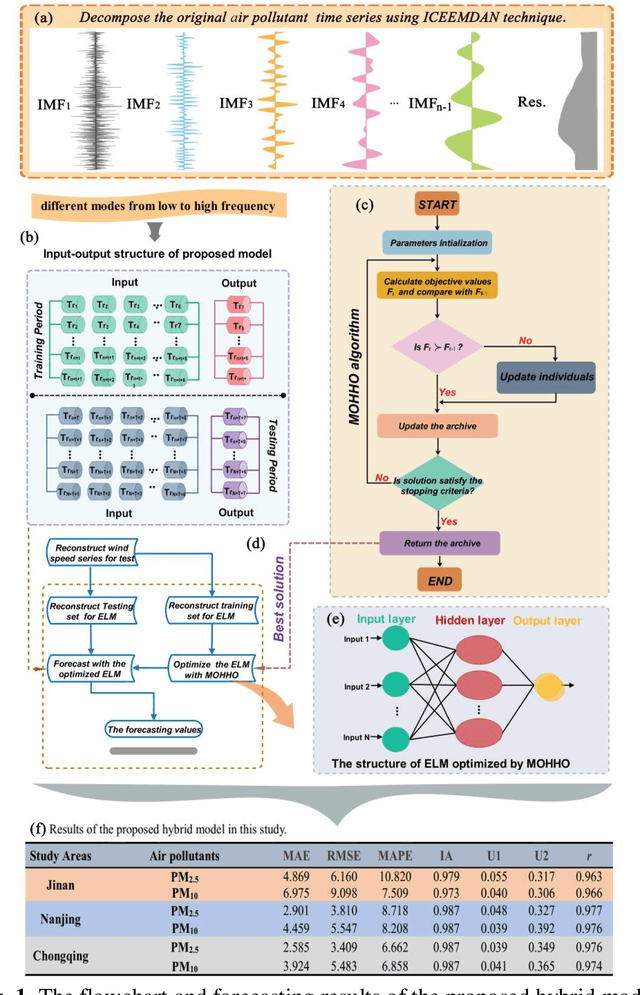
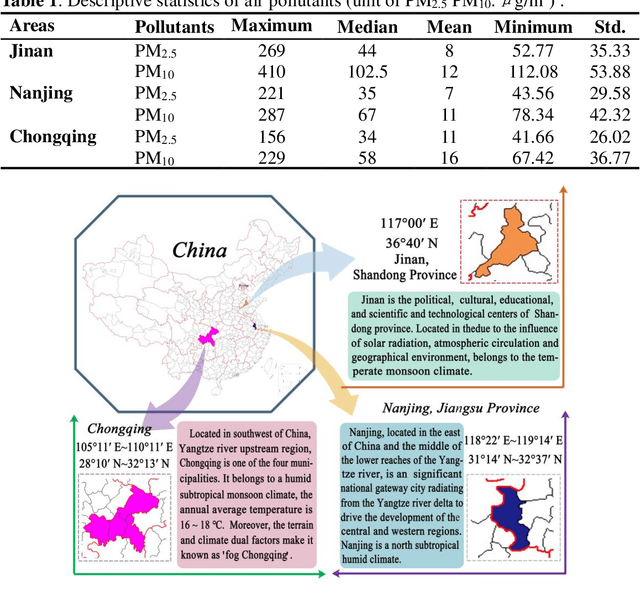
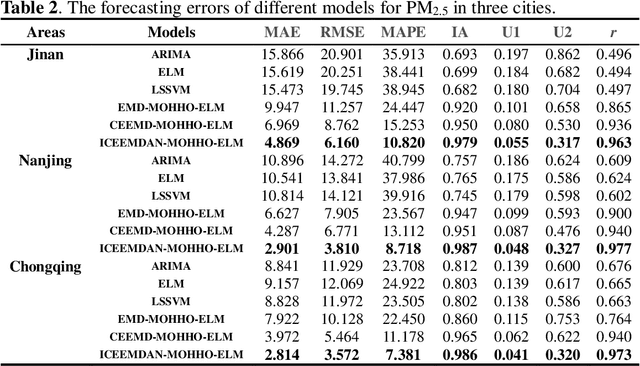
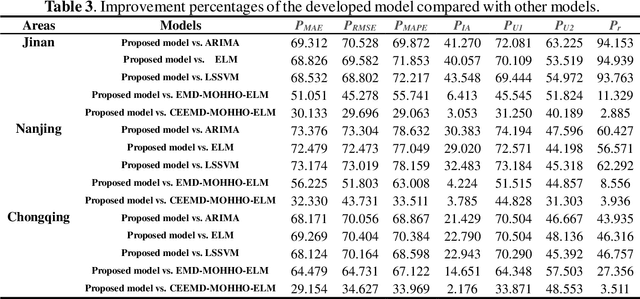
High levels of air pollution may seriously affect people's living environment and even endanger their lives. In order to reduce air pollution concentrations, and warn the public before the occurrence of hazardous air pollutants, it is urgent to design an accurate and reliable air pollutant forecasting model. However, most previous research have many deficiencies, such as ignoring the importance of predictive stability, and poor initial parameters and so on, which have significantly effect on the performance of air pollution prediction. Therefore, to address these issues, a novel hybrid model is proposed in this study. Specifically, a powerful data preprocessing techniques is applied to decompose the original time series into different modes from low- frequency to high- frequency. Next, a new multi-objective algorithm called MOHHO is first developed in this study, which are introduced to tune the parameters of ELM model with high forecasting accuracy and stability for air pollution series prediction, simultaneously. And the optimized ELM model is used to perform the time series prediction. Finally, a scientific and robust evaluation system including several error criteria, benchmark models, and several experiments using six air pollutant concentrations time series from three cities in China is designed to perform a compressive assessment for the presented hybrid forecasting model. Experimental results indicate that the proposed hybrid model can guarantee a more stable and higher predictive performance compared to others, whose superior prediction ability may help to develop effective plans for air pollutant emissions and prevent health problems caused by air pollution.