 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-term electricity load forecasting with multi-frequency reconstruction diffusion
Jan 10, 2026Diffusion models have emerged as a powerful method in various applications. However, their application to Short-Term Electricity Load Forecasting (STELF) -- a typical scenario in energy systems -- remains largely unexplored. Considering the nonlinear and fluctuating characteristics of the load data, effectively utilizing the powerful modeling capabilities of diffusion models to enhance STELF accuracy remains a challenge. This paper proposes a novel diffusion model with multi-frequency reconstruction for STELF, referred to as the Multi-Frequency-Reconstruction-based Diffusion (MFRD) model. The MFRD model achieves accurate load forecasting through four key steps: (1) The original data is combined with the decomposed multi-frequency modes to form a new data representation; (2) The diffusion model adds noise to the new data, effectively reducing and weakening the noise in the original data; (3) The reverse process adopts a denoising network that combines Long Short-Term Memory (LSTM) and Transformer to enhance noise removal; and (4) The inference process generates the final predictions based on the trained denoising network. To validate the effectiveness of the MFRD model, we conducted experiments on two data platforms: Australian Energy Market Operator (AEMO) and Independent System Operator of New England (ISO-NE). The experimental results show that our model consistently outperforms the compared models.
Integrating Artificial Intelligence with Human Expertise: An In-depth Analysis of ChatGPT's Capabilities in Generating Metamorphic Relations
Mar 28, 2025Context: This paper provides an in-depth examination of the generation and evaluation of Metamorphic Relations (MRs) using GPT models developed by OpenAI, with a particular focus on the capabilities of GPT-4 in software testing environments. Objective: The aim is to examine the quality of MRs produced by GPT-3.5 and GPT-4 for a specific System Under Test (SUT) adopted from an earlier study, and to introduce and apply an improved set of evaluation criteria for a diverse range of SUTs. Method: The initial phase evaluates MRs generated by GPT-3.5 and GPT-4 using criteria from a prior study, followed by an application of an enhanced evaluation framework on MRs created by GPT-4 for a diverse range of nine SUTs, varying from simple programs to complex systems incorporating AI/ML components. A custom-built GPT evaluator, alongside human evaluators, assessed the MRs, enabling a direct comparison between automated and human evaluation methods. Results: The study finds that GPT-4 outperforms GPT-3.5 in generating accurate and useful MRs. With the advanced evaluation criteria, GPT-4 demonstrates a significant ability to produce high-quality MRs across a wide range of SUTs, including complex systems incorporating AI/ML components. Conclusions: GPT-4 exhibits advanced capabilities in generating MRs suitable for various applications. The research underscores the growing potential of AI in software testing, particularly in the generation and evaluation of MRs, and points towards the complementarity of human and AI skills in this domain.
Short-Term Electricity-Load Forecasting by Deep Learning: A Comprehensive Survey
Aug 29, 2024Short-Term Electricity-Load Forecasting (STELF) refers to the prediction of the immediate demand (in the next few hours to several days) for the power system. Various external factors, such as weather changes and the emergence of new electricity consumption scenarios, can impact electricity demand, causing load data to fluctuate and become non-linear, which increases the complexity and difficulty of STELF. In the past decade, deep learning has been applied to STELF, modeling and predicting electricity demand with high accuracy, and contributing significantly to the development of STELF. This paper provides a comprehensive survey on deep-learning-based STELF over the past ten years. It examines the entire forecasting process, including data pre-processing, feature extraction, deep-learning modeling and optimization, and results evaluation. This paper also identifies some research challenges and potential research directions to be further investigated in future work.
Uncovering the Metaverse within Everyday Environments: a Coarse-to-Fine Approach
Apr 11, 2024



The recent release of the Apple Vision Pro has reignited interest in the metaverse, showcasing the intensified efforts of technology giants in developing platforms and devices to facilitate its growth. As the metaverse continues to proliferate, it is foreseeable that everyday environments will become increasingly saturated with its presence. Consequently, uncovering links to these metaverse items will be a crucial first step to interacting with this new augmented world. In this paper, we address the problem of establishing connections with virtual worlds within everyday environments, especially those that are not readily discernible through direct visual inspection. We introduce a vision-based approach leveraging Artcode visual markers to uncover hidden metaverse links embedded in our ambient surroundings. This approach progressively localises the access points to the metaverse, transitioning from coarse to fine localisation, thus facilitating an exploratory interaction process. Detailed experiments are conducted to study the performance of the proposed approach, demonstrating its effectiveness in Artcode localisation and enabling new interaction opportunities.
TransformCode: A Contrastive Learning Framework for Code Embedding via Subtree transformation
Nov 10, 2023Large-scale language models have made great progress in the field of software engineering in recent years. They can be used for many code-related tasks such as code clone detection, code-to-code search, and method name prediction. However, these large-scale language models based on each code token have several drawbacks: They are usually large in scale, heavily dependent on labels, and require a lot of computing power and time to fine-tune new datasets.Furthermore, code embedding should be performed on the entire code snippet rather than encoding each code token. The main reason for this is that encoding each code token would cause model parameter inflation, resulting in a lot of parameters storing information that we are not very concerned about. In this paper, we propose a novel framework, called TransformCode, that learns about code embeddings in a contrastive learning manner. The framework uses the Transformer encoder as an integral part of the model. We also introduce a novel data augmentation technique called abstract syntax tree transformation: This technique applies syntactic and semantic transformations to the original code snippets to generate more diverse and robust anchor samples. Our proposed framework is both flexible and adaptable: It can be easily extended to other downstream tasks that require code representation such as code clone detection and classification. The framework is also very efficient and scalable: It does not require a large model or a large amount of training data, and can support any programming language.Finally, our framework is not limited to unsupervised learning, but can also be applied to some supervised learning tasks by incorporating task-specific labels or objectives. To explore the effectiveness of our framework, we conducted extensive experiments on different software engineering tasks using different programming languages and multiple datasets.
Elongated Physiological Structure Segmentation via Spatial and Scale Uncertainty-aware Network
May 30, 2023



Robust and accurate segmentation for elongated physiological structures is challenging, especially in the ambiguous region, such as the corneal endothelium microscope image with uneven illumination or the fundus image with disease interference. In this paper, we present a spatial and scale uncertainty-aware network (SSU-Net) that fully uses both spatial and scale uncertainty to highlight ambiguous regions and integrate hierarchical structure contexts. First, we estimate epistemic and aleatoric spatial uncertainty maps using Monte Carlo dropout to approximate Bayesian networks. Based on these spatial uncertainty maps, we propose the gated soft uncertainty-aware (GSUA) module to guide the model to focus on ambiguous regions. Second, we extract the uncertainty under different scales and propose the multi-scale uncertainty-aware (MSUA) fusion module to integrate structure contexts from hierarchical predictions, strengthening the final prediction. Finally, we visualize the uncertainty map of final prediction, providing interpretability for segmentation results. Experiment results show that the SSU-Net performs best on cornea endothelial cell and retinal vessel segmentation tasks. Moreover, compared with counterpart uncertainty-based methods, SSU-Net is more accurate and robust.
Using Metamorphic Relations to Verify and Enhance Artcode Classification
Aug 05, 2021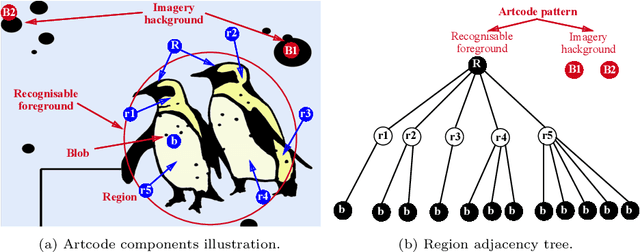
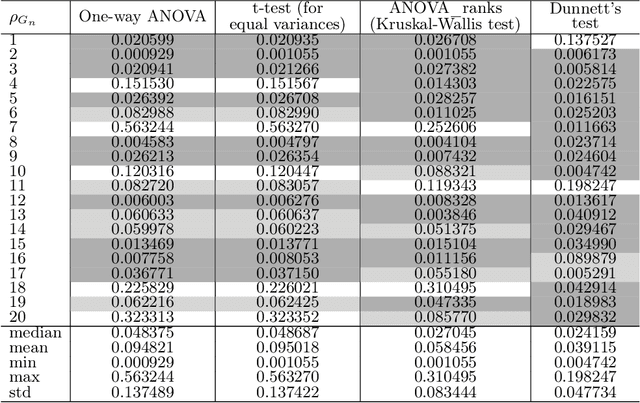


Software testing is often hindered where it is impossible or impractical to determine the correctness of the behaviour or output of the software under test (SUT), a situation known as the oracle problem. An example of an area facing the oracle problem is automatic image classification, using machine learning to classify an input image as one of a set of predefined classes. An approach to software testing that alleviates the oracle problem is metamorphic testing (MT). While traditional software testing examines the correctness of individual test cases, MT instead examines the relations amongst multiple executions of test cases and their outputs. These relations are called metamorphic relations (MRs): if an MR is found to be violated, then a fault must exist in the SUT. This paper examines the problem of classifying images containing visually hidden markers called Artcodes, and applies MT to verify and enhance the trained classifiers. This paper further examines two MRs, Separation and Occlusion, and reports on their capability in verifying the image classification using one-way analysis of variance (ANOVA) in conjunction with three other statistical analysis methods: t-test (for unequal variances), Kruskal-Wallis test, and Dunnett's test. In addition to our previously-studied classifier, that used Random Forests, we introduce a new classifier that uses a support vector machine, and present its MR-augmented version. Experimental evaluations across a number of performance metrics show that the augmented classifiers can achieve better performance than non-augmented classifiers. This paper also analyses how the enhanced performance is obtained.