 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedHyper: A Universal and Robust Learning Rate Scheduler for Federated Learning with Hypergradient Descent
Oct 06, 2023



The theoretical landscape of federated learning (FL) undergoes rapid evolution, but its practical application encounters a series of intricate challenges, and hyperparameter optimization is one of these critical challenges. Amongst the diverse adjustments in hyperparameters, the adaptation of the learning rate emerges as a crucial component, holding the promise of significantly enhancing the efficacy of FL systems. In response to this critical need, this paper presents FedHyper, a novel hypergradient-based learning rate adaptation algorithm specifically designed for FL. FedHyper serves as a universal learning rate scheduler that can adapt both global and local rates as the training progresses. In addition, FedHyper not only showcases unparalleled robustness to a spectrum of initial learning rate configurations but also significantly alleviates the necessity for laborious empirical learning rate adjustments. We provide a comprehensive theoretical analysis of FedHyper's convergence rate and conduct extensive experiments on vision and language benchmark datasets. The results demonstrate that FEDHYPER consistently converges 1.1-3x faster than FedAvg and the competing baselines while achieving superior final accuracy. Moreover, FedHyper catalyzes a remarkable surge in accuracy, augmenting it by up to 15% compared to FedAvg under suboptimal initial learning rate settings.
FedDisco: Federated Learning with Discrepancy-Aware Collaboration
May 30, 2023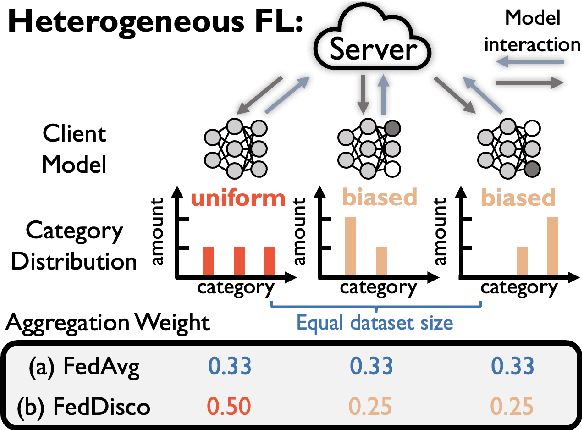
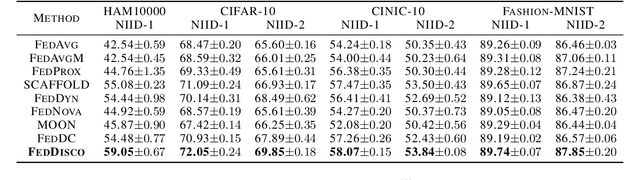
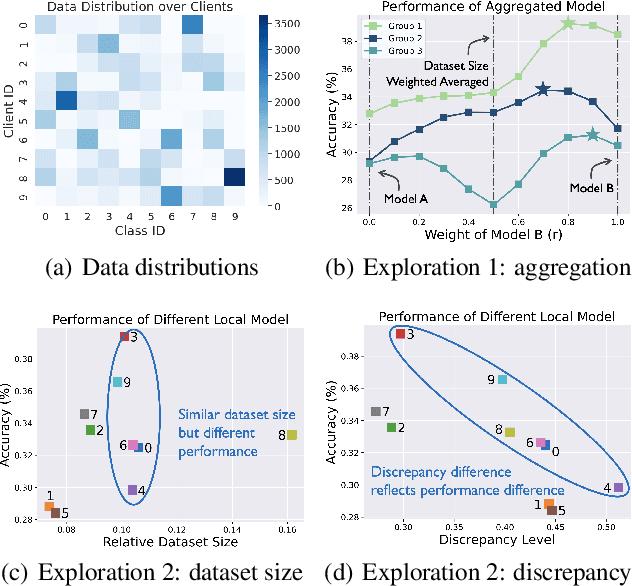
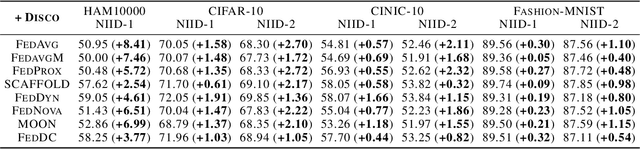
This work considers the category distribution heterogeneity in federated learning. This issue is due to biased labeling preferences at multiple clients and is a typical setting of data heterogeneity. To alleviate this issue, most previous works consider either regularizing local models or fine-tuning the global model, while they ignore the adjustment of aggregation weights and simply assign weights based on the dataset size. However, based on our empirical observations and theoretical analysis, we find that the dataset size is not optimal and the discrepancy between local and global category distributions could be a beneficial and complementary indicator for determining aggregation weights. We thus propose a novel aggregation method, Federated Learning with Discrepancy-aware Collaboration (FedDisco), whose aggregation weights not only involve both the dataset size and the discrepancy value, but also contribute to a tighter theoretical upper bound of the optimization error. FedDisco also promotes privacy-preservation, communication and computation efficiency, as well as modularity. Extensive experiments show that our FedDisco outperforms several state-of-the-art methods and can be easily incorporated with many existing methods to further enhance the performance. Our code will be available at https://github.com/MediaBrain-SJTU/FedDisco.
Few-shot Non-line-of-sight Imaging with Signal-surface Collaborative Regularization
Nov 21, 2022



The non-line-of-sight imaging technique aims to reconstruct targets from multiply reflected light. For most existing methods, dense points on the relay surface are raster scanned to obtain high-quality reconstructions, which requires a long acquisition time. In this work, we propose a signal-surface collaborative regularization (SSCR) framework that provides noise-robust reconstructions with a minimal number of measurements. Using Bayesian inference, we design joint regularizations of the estimated signal, the 3D voxel-based representation of the objects, and the 2D surface-based description of the targets. To our best knowledge, this is the first work that combines regularizations in mixed dimensions for hidden targets. Experiments on synthetic and experimental datasets illustrated the efficiency and robustness of the proposed method under both confocal and non-confocal settings. We report the reconstruction of the hidden targets with complex geometric structures with only $5 \times 5$ confocal measurements from public datasets, indicating an acceleration of the conventional measurement process by a factor of 10000. Besides, the proposed method enjoys low time and memory complexities with sparse measurements. Our approach has great potential in real-time non-line-of-sight imaging applications such as rescue operations and autonomous driving.
Robust Manifold Nonnegative Tucker Factorization for Tensor Data Representation
Nov 08, 2022



Nonnegative Tucker Factorization (NTF) minimizes the euclidean distance or Kullback-Leibler divergence between the original data and its low-rank approximation which often suffers from grossly corruptions or outliers and the neglect of manifold structures of data. In particular, NTF suffers from rotational ambiguity, whose solutions with and without rotation transformations are equally in the sense of yielding the maximum likelihood. In this paper, we propose three Robust Manifold NTF algorithms to handle outliers by incorporating structural knowledge about the outliers. They first applies a half-quadratic optimization algorithm to transform the problem into a general weighted NTF where the weights are influenced by the outliers. Then, we introduce the correntropy induced metric, Huber function and Cauchy function for weights respectively, to handle the outliers. Finally, we introduce a manifold regularization to overcome the rotational ambiguity of NTF. We have compared the proposed method with a number of representative references covering major branches of NTF on a variety of real-world image databases. Experimental results illustrate the effectiveness of the proposed method under two evaluation metrics (accuracy and nmi).
Non-line-of-sight imaging with arbitrary illumination and detection pattern
Nov 01, 2022Non-line-of-sight (NLOS) imaging aims at reconstructing targets obscured from the direct line of sight. Existing NLOS imaging algorithms require dense measurements at rectangular grid points in a large area of the relay surface, which severely hinders their availability to variable relay scenarios in practical applications such as robotic vision, autonomous driving, rescue operations and remote sensing. In this work, we propose a Bayesian framework for NLOS imaging with no specific requirements on the spatial pattern of illumination and detection points. By introducing virtual confocal signals, we design a confocal complemented signal-object collaborative regularization (CC-SOCR) algorithm for high quality reconstructions. Our approach is capable of reconstructing both albedo and surface normal of the hidden objects with fine details under the most general relay setting. Moreover, with a regular relay surface, coarse rather than dense measurements are enough for our approach such that the acquisition time can be reduced significantly. As demonstrated in multiple experiments, the new framework substantially enhances the applicability of NLOS imaging.
Where to Begin? On the Impact of Pre-Training and Initialization in Federated Learning
Oct 14, 2022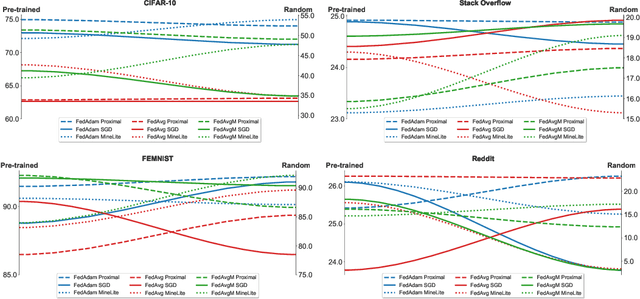

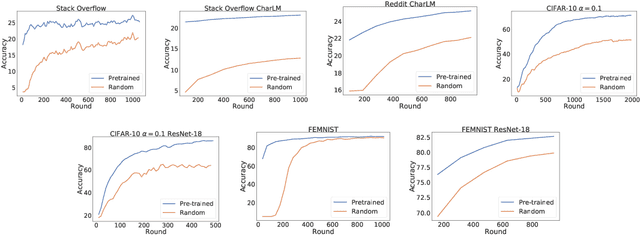
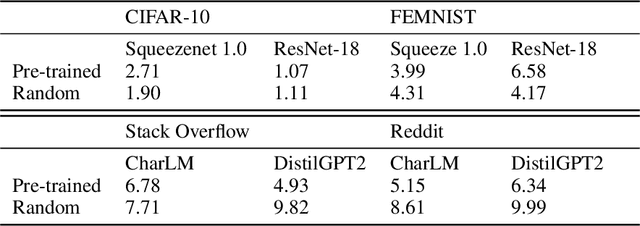
An oft-cited challenge of federated learning is the presence of heterogeneity. \emph{Data heterogeneity} refers to the fact that data from different clients may follow very different distributions. \emph{System heterogeneity} refers to the fact that client devices have different system capabilities. A considerable number of federated optimization methods address this challenge. In the literature, empirical evaluations usually start federated training from random initialization. However, in many practical applications of federated learning, the server has access to proxy data for the training task that can be used to pre-train a model before starting federated training. We empirically study the impact of starting from a pre-trained model in federated learning using four standard federated learning benchmark datasets. Unsurprisingly, starting from a pre-trained model reduces the training time required to reach a target error rate and enables the training of more accurate models (up to 40\%) than is possible when starting from random initialization. Surprisingly, we also find that starting federated learning from a pre-trained initialization reduces the effect of both data and system heterogeneity. We recommend that future work proposing and evaluating federated optimization methods evaluate the performance when starting from random and pre-trained initializations. We also believe this study raises several questions for further work on understanding the role of heterogeneity in federated optimization.
FedFM: Anchor-based Feature Matching for Data Heterogeneity in Federated Learning
Oct 14, 2022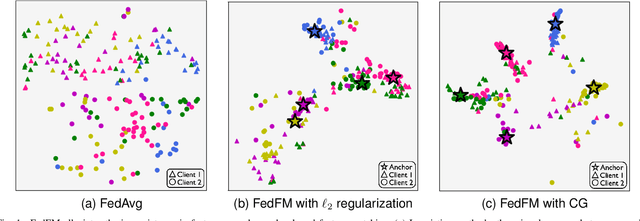
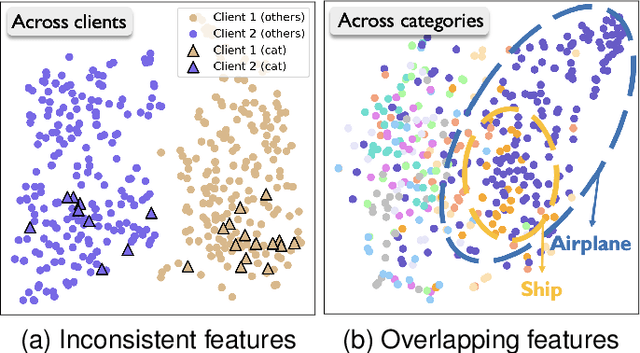
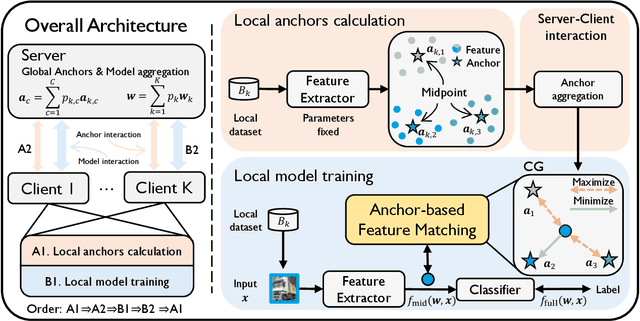
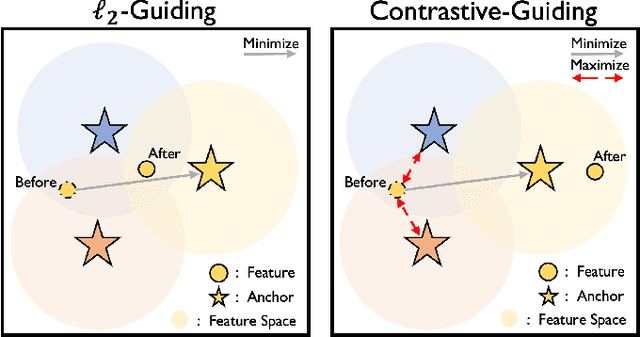
One of the key challenges in federated learning (FL) is local data distribution heterogeneity across clients, which may cause inconsistent feature spaces across clients. To address this issue, we propose a novel method FedFM, which guides each client's features to match shared category-wise anchors (landmarks in feature space). This method attempts to mitigate the negative effects of data heterogeneity in FL by aligning each client's feature space. Besides, we tackle the challenge of varying objective function and provide convergence guarantee for FedFM. In FedFM, to mitigate the phenomenon of overlapping feature spaces across categories and enhance the effectiveness of feature matching, we further propose a more precise and effective feature matching loss called contrastive-guiding (CG), which guides each local feature to match with the corresponding anchor while keeping away from non-corresponding anchors. Additionally, to achieve higher efficiency and flexibility, we propose a FedFM variant, called FedFM-Lite, where clients communicate with server with fewer synchronization times and communication bandwidth costs. Through extensive experiments, we demonstrate that FedFM with CG outperforms several works by quantitative and qualitative comparisons. FedFM-Lite can achieve better performance than state-of-the-art methods with five to ten times less communication costs.
On the Unreasonable Effectiveness of Federated Averaging with Heterogeneous Data
Jun 09, 2022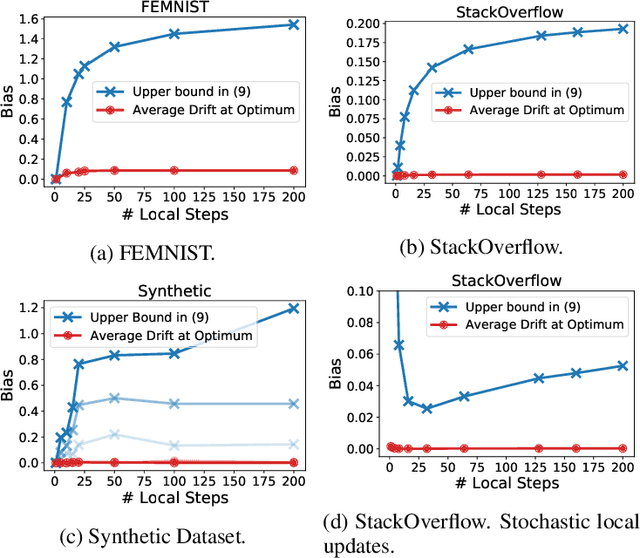
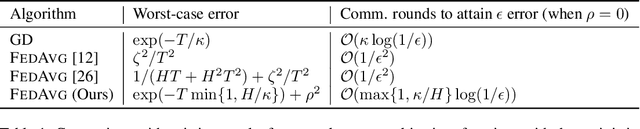
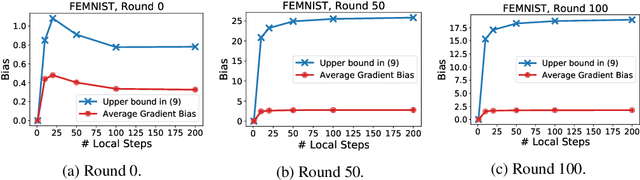
Existing theory predicts that data heterogeneity will degrade the performance of the Federated Averaging (FedAvg) algorithm in federated learning. However, in practice, the simple FedAvg algorithm converges very well. This paper explains the seemingly unreasonable effectiveness of FedAvg that contradicts the previous theoretical predictions. We find that the key assumption of bounded gradient dissimilarity in previous theoretical analyses is too pessimistic to characterize data heterogeneity in practical applications. For a simple quadratic problem, we demonstrate there exist regimes where large gradient dissimilarity does not have any negative impact on the convergence of FedAvg. Motivated by this observation, we propose a new quantity, average drift at optimum, to measure the effects of data heterogeneity, and explicitly use it to present a new theoretical analysis of FedAvg. We show that the average drift at optimum is nearly zero across many real-world federated training tasks, whereas the gradient dissimilarity can be large. And our new analysis suggests FedAvg can have identical convergence rates in homogeneous and heterogeneous data settings, and hence, leads to better understanding of its empirical success.
Federated Learning under Distributed Concept Drift
Jun 01, 2022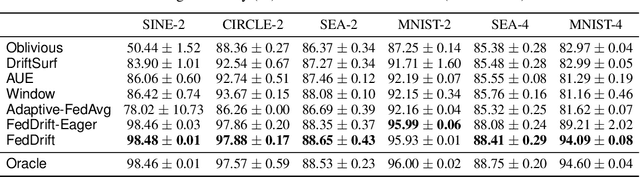


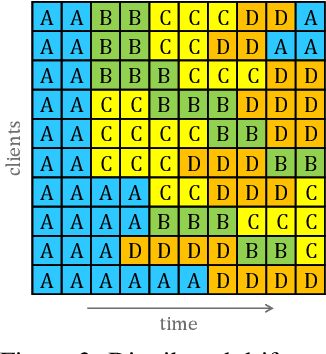
Federated Learning (FL) under distributed concept drift is a largely unexplored area. Although concept drift is itself a well-studied phenomenon, it poses particular challenges for FL, because drifts arise staggered in time and space (across clients). Our work is the first to explicitly study data heterogeneity in both dimensions. We first demonstrate that prior solutions to drift adaptation, with their single global model, are ill-suited to staggered drifts, necessitating multi-model solutions. We identify the problem of drift adaptation as a time-varying clustering problem, and we propose two new clustering algorithms for reacting to drifts based on local drift detection and hierarchical clustering. Empirical evaluation shows that our solutions achieve significantly higher accuracy than existing baselines, and are comparable to an idealized algorithm with oracle knowledge of the ground-truth clustering of clients to concepts at each time step.
RLPrompt: Optimizing Discrete Text Prompts With Reinforcement Learning
May 25, 2022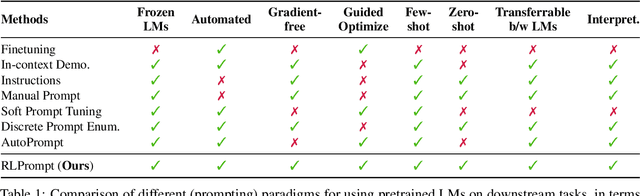
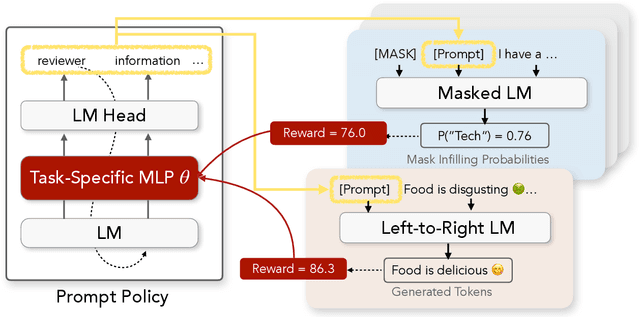
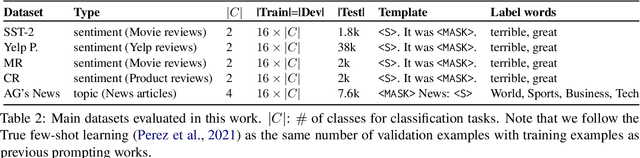
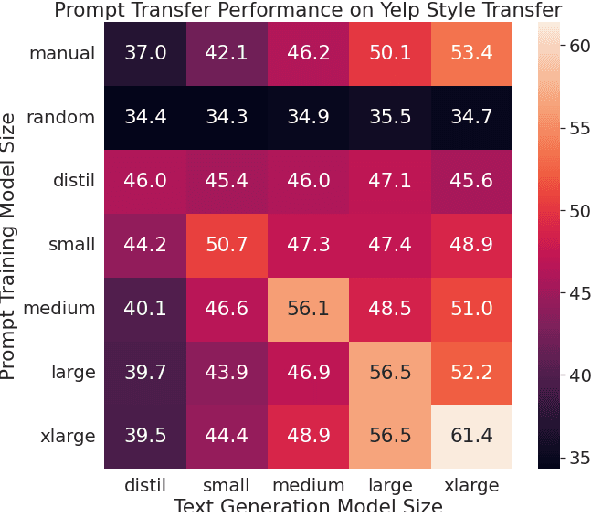
Prompting has shown impressive success in enabling large pretrained language models (LMs) to perform diverse NLP tasks, especially when only few downstream data are available. Automatically finding the optimal prompt for each task, however, is challenging. Most existing work resorts to tuning soft prompt (e.g., embeddings) which falls short of interpretability, reusability across LMs, and applicability when gradients are not accessible. Discrete prompt, on the other hand, is difficult to optimize, and is often created by "enumeration (e.g., paraphrasing)-then-selection" heuristics that do not explore the prompt space systematically. This paper proposes RLPrompt, an efficient discrete prompt optimization approach with reinforcement learning (RL). RLPrompt formulates a parameter-efficient policy network that generates the desired discrete prompt after training with reward. To overcome the complexity and stochasticity of reward signals by the large LM environment, we incorporate effective reward stabilization that substantially enhances the training efficiency. RLPrompt is flexibly applicable to different types of LMs, such as masked (e.g., BERT) and left-to-right models (e.g., GPTs), for both classification and generation tasks. Experiments on few-shot classification and unsupervised text style transfer show superior performance over a wide range of existing finetuning or prompting methods. Interestingly, the resulting optimized prompts are often ungrammatical gibberish text; and surprisingly, those gibberish prompts are transferrable between different LMs to retain significant performance, indicating LM prompting may not follow human language patterns.