 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360-Indoor: Towards Learning Real-World Objects in 360° Indoor Equirectangular Images
Oct 03, 2019


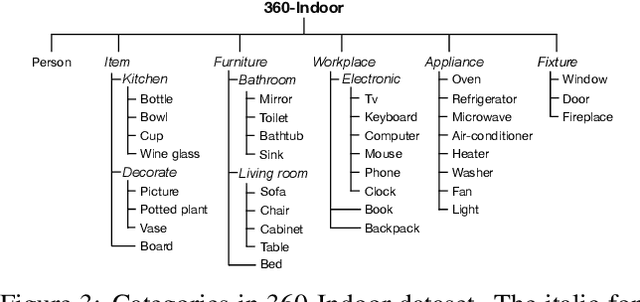
While there are several widely used object detection datasets, current computer vision algorithms are still limited in conventional images. Such images narrow our vision in a restricted region. On the other hand, 360{\deg} images provide a thorough sight. In this paper, our goal is to provide a standard dataset to facilitate the vision and machine learning communities in 360{\deg} domain. To facilitate the research, we present a real-world 360{\deg} panoramic object detection dataset, 360-Indoor, which is a new benchmark for visual object detection and class recognition in 360{\deg} indoor images. It is achieved by gathering images of complex indoor scenes containing common objects and the intensive annotated bounding field-of-view. In addition, 360-Indoor has several distinct properties: (1) the largest category number (37 labels in total). (2) the most complete annotations on average (27 bounding boxes per image). The selected 37 objects are all common in indoor scene. With around 3k images and 90k labels in total, 360-Indoor achieves the largest dataset for detection in 360{\deg} images. In the end, extensive experiments on the state-of-the-art methods for both classification and detection are provided. We will release this dataset in the near future.
WSOD^2: Learning Bottom-up and Top-down Objectness Distillation for Weakly-supervised Object Detection
Sep 11, 2019

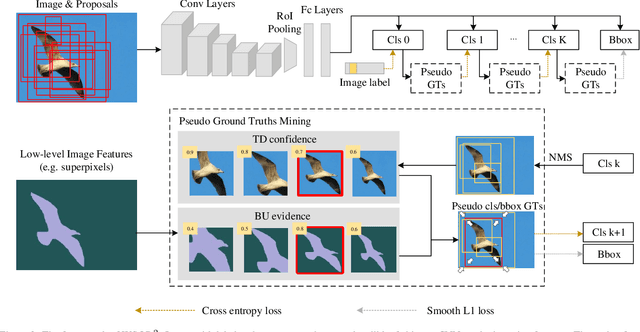
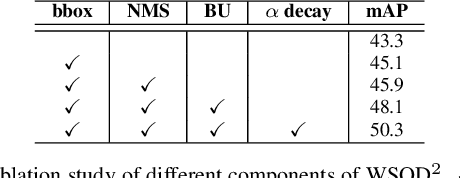
We study on weakly-supervised object detection (WSOD) which plays a vital role in relieving human involvement from object-level annotations. Predominant works integrate region proposal mechanisms with convolutional neural networks (CNN). Although CNN is proficient in extracting discriminative local features, grand challenges still exist to measure the likelihood of a bounding box containing a complete object (i.e., "objectness"). In this paper, we propose a novel WSOD framework with Objectness Distillation (i.e., WSOD^2) by designing a tailored training mechanism for weakly-supervised object detection. Multiple regression targets are specifically determined by jointly considering bottom-up (BU) and top-down (TD) objectness from low-level measurement and CNN confidences with an adaptive linear combination. As bounding box regression can facilitate a region proposal learning to approach its regression target with high objectness during training, deep objectness representation learned from bottom-up evidences can be gradually distilled into CNN by optimization. We explore different adaptive training curves for BU/TD objectness, and show that the proposed WSOD^2 can achieve state-of-the-art results.
Learn to Scale: Generating Multipolar Normalized Density Maps for Crowd Counting
Aug 08, 2019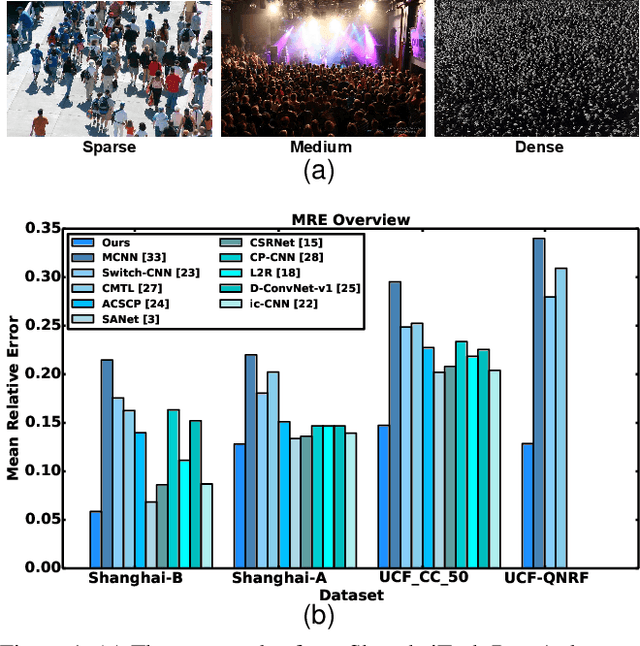
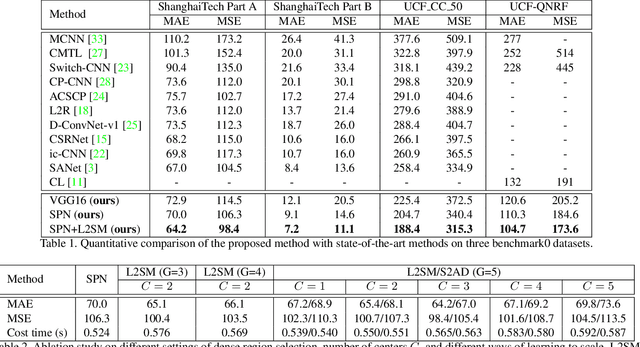

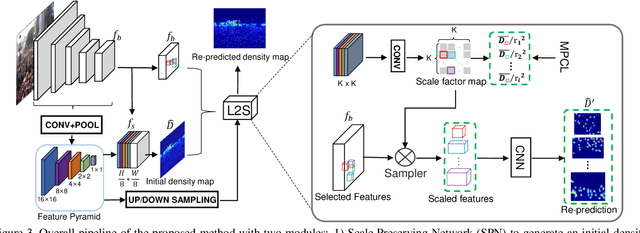
Dense crowd counting aims to predict thousands of human instances from an image, by calculating integrals of a density map over image pixels. Existing approaches mainly suffer from the extreme density variances. Such density pattern shift poses challenges even for multi-scale model ensembling. In this paper, we propose a simple yet effective approach to tackle this problem. First, a patch-level density map is extracted by a density estimation model and further grouped into several density levels which are determined over full datasets. Second, each patch density map is automatically normalized by an online center learning strategy with a multipolar center loss. Such a design can significantly condense the density distribution into several clusters, and enable that the density variance can be learned by a single model. Extensive experiments demonstrate the superiority of the proposed method. Our work outperforms the state-of-the-art by 4.2%, 14.3%, 27.1% and 20.1% in MAE, on ShanghaiTech Part A, ShanghaiTech Part B, UCF_CC_50 and UCF-QNRF datasets, respectively.
Activitynet 2019 Task 3: Exploring Contexts for Dense Captioning Events in Videos
Jul 11, 2019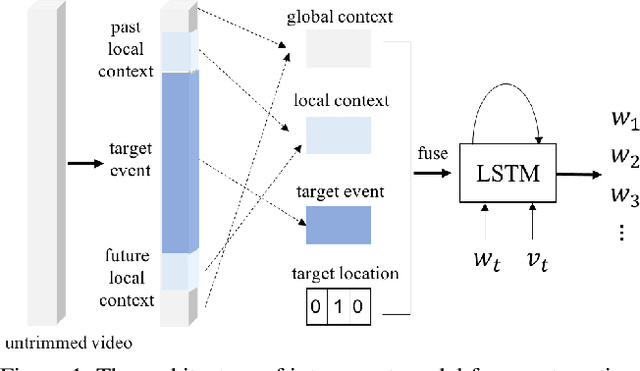
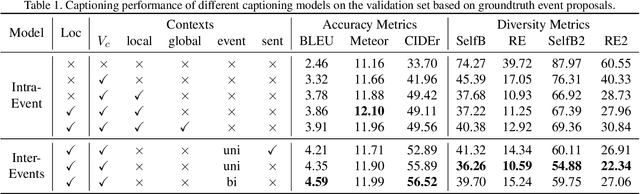
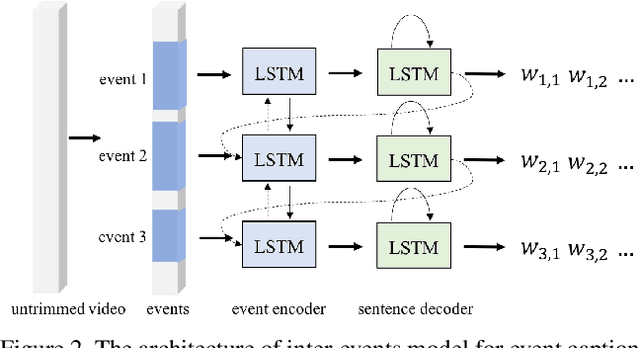
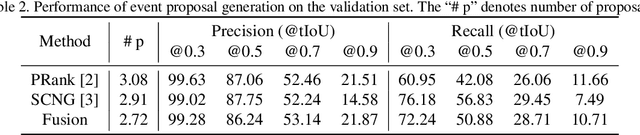
Contextual reasoning is essential to understand events in long untrimmed videos. In this work, we systematically explore different captioning models with various contexts for the dense-captioning events in video task, which aims to generate captions for different events in the untrimmed video. We propose five types of contexts as well as two categories of event captioning models, and evaluate their contributions for event captioning from both accuracy and diversity aspects. The proposed captioning models are plugged into our pipeline system for the dense video captioning challenge. The overall system achieves the state-of-the-art performance on the dense-captioning events in video task with 9.91 METEOR score on the challenge testing set.
From Words to Sentences: A Progressive Learning Approach for Zero-resource Machine Translation with Visual Pivots
Jun 03, 2019
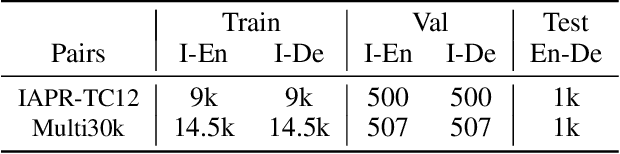
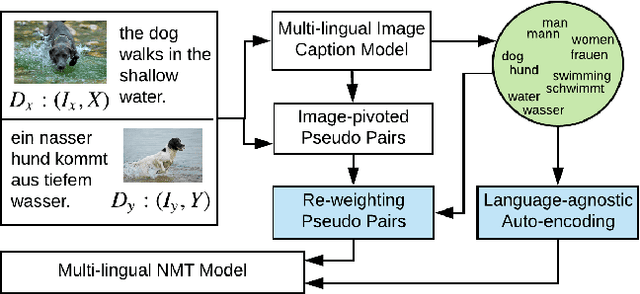
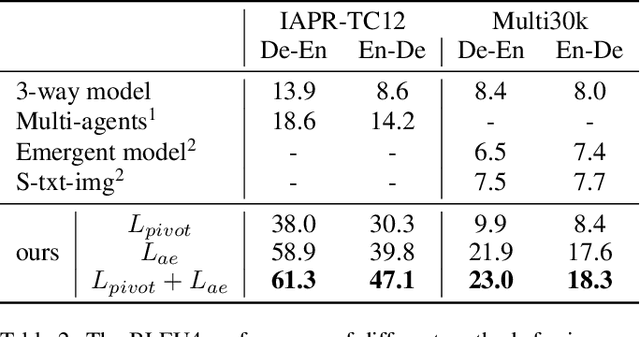
The neural machine translation model has suffered from the lack of large-scale parallel corpora. In contrast, we humans can learn multi-lingual translations even without parallel texts by referring our languages to the external world. To mimic such human learning behavior, we employ images as pivots to enable zero-resource translation learning. However, a picture tells a thousand words, which makes multi-lingual sentences pivoted by the same image noisy as mutual translations and thus hinders the translation model learning. In this work, we propose a progressive learning approach for image-pivoted zero-resource machine translation. Since words are less diverse when grounded in the image, we first learn word-level translation with image pivots, and then progress to learn the sentence-level translation by utilizing the learned word translation to suppress noises in image-pivoted multi-lingual sentences. Experimental results on two widely used image-pivot translation datasets, IAPR-TC12 and Multi30k, show that the proposed approach significantly outperforms other state-of-the-art methods.
Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting
Apr 30, 2019
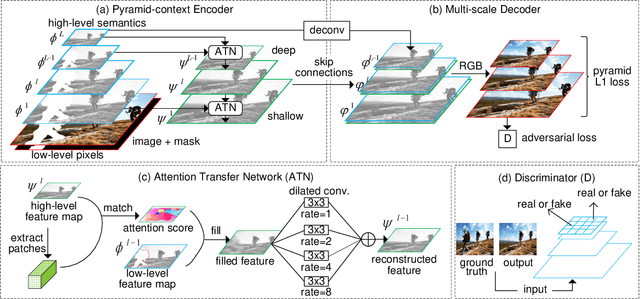

High-quality image inpainting requires filling missing regions in a damaged image with plausible content. Existing works either fill the regions by copying image patches or generating semantically-coherent patches from region context, while neglect the fact that both visual and semantic plausibility are highly-demanded. In this paper, we propose a Pyramid-context ENcoder Network (PEN-Net) for image inpainting by deep generative models. The PEN-Net is built upon a U-Net structure, which can restore an image by encoding contextual semantics from full resolution input, and decoding the learned semantic features back into images. Specifically, we propose a pyramid-context encoder, which progressively learns region affinity by attention from a high-level semantic feature map and transfers the learned attention to the previous low-level feature map. As the missing content can be filled by attention transfer from deep to shallow in a pyramid fashion, both visual and semantic coherence for image inpainting can be ensured. We further propose a multi-scale decoder with deeply-supervised pyramid losses and an adversarial loss. Such a design not only results in fast convergence in training, but more realistic results in testing. Extensive experiments on various datasets show the superior performance of the proposed network
Looking for the Devil in the Details: Learning Trilinear Attention Sampling Network for Fine-grained Image Recognition
Mar 14, 2019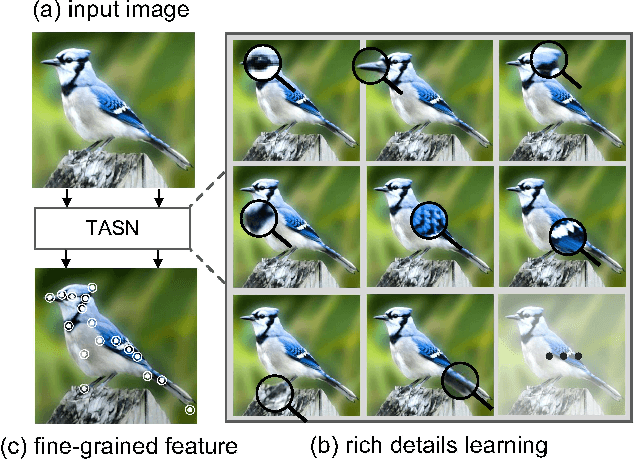
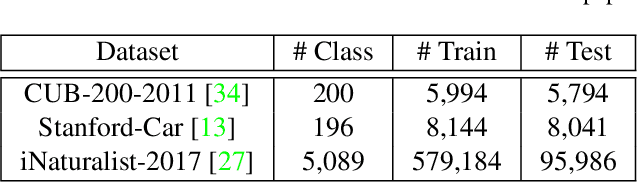
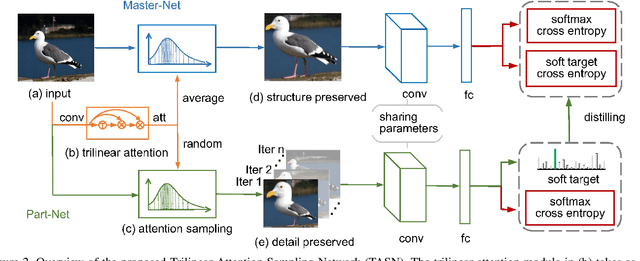
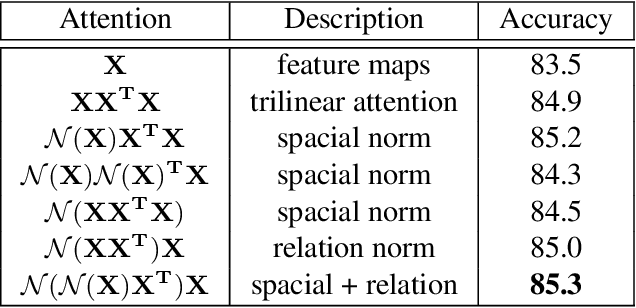
Learning subtle yet discriminative features (e.g., beak and eyes for a bird) plays a significant role in fine-grained image recognition. Existing attention-based approaches localize and amplify significant parts to learn fine-grained details, which often suffer from a limited number of parts and heavy computational cost. In this paper, we propose to learn such fine-grained features from hundreds of part proposals by Trilinear Attention Sampling Network (TASN) in an efficient teacher-student manner. Specifically, TASN consists of 1) a trilinear attention module, which generates attention maps by modeling the inter-channel relationships, 2) an attention-based sampler which highlights attended parts with high resolution, and 3) a feature distiller, which distills part features into a global one by weight sharing and feature preserving strategies. Extensive experiments verify that TASN yields the best performance under the same settings with the most competitive approaches, in iNaturalist-2017, CUB-Bird, and Stanford-Cars datasets.
Beyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training
Oct 10, 2018
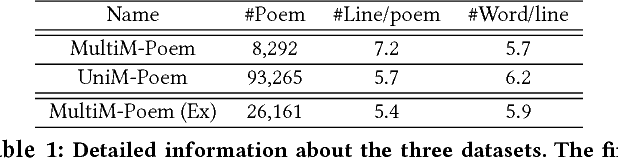
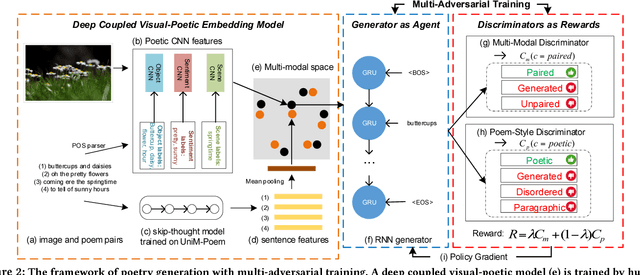

Automatic generation of natural language from images has attracted extensive attention. In this paper, we take one step further to investigate generation of poetic language (with multiple lines) to an image for automatic poetry creation. This task involves multiple challenges, including discovering poetic clues from the image (e.g., hope from green), and generating poems to satisfy both relevance to the image and poeticness in language level. To solve the above challenges, we formulate the task of poem generation into two correlated sub-tasks by multi-adversarial training via policy gradient, through which the cross-modal relevance and poetic language style can be ensured. To extract poetic clues from images, we propose to learn a deep coupled visual-poetic embedding, in which the poetic representation from objects, sentiments and scenes in an image can be jointly learned. Two discriminative networks are further introduced to guide the poem generation, including a multi-modal discriminator and a poem-style discriminator. To facilitate the research, we have released two poem datasets by human annotators with two distinct properties: 1) the first human annotated image-to-poem pair dataset (with 8,292 pairs in total), and 2) to-date the largest public English poem corpus dataset (with 92,265 different poems in total). Extensive experiments are conducted with 8K images, among which 1.5K image are randomly picked for evaluation. Both objective and subjective evaluations show the superior performances against the state-of-the-art methods for poem generation from images. Turing test carried out with over 500 human subjects, among which 30 evaluators are poetry experts, demonstrates the effectiveness of our approach.
Image Inspired Poetry Generation in XiaoIce
Aug 09, 2018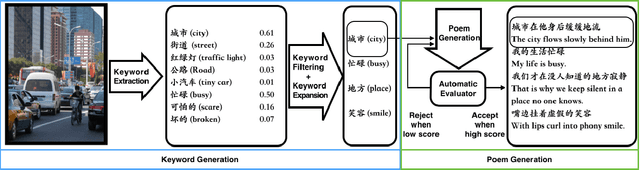
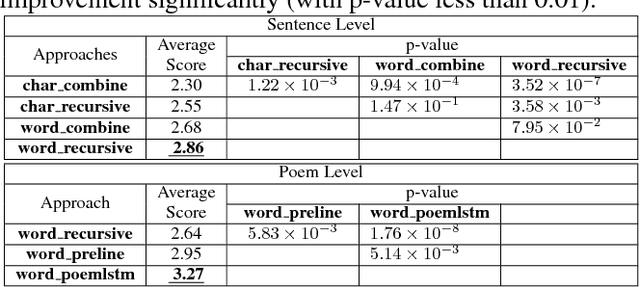
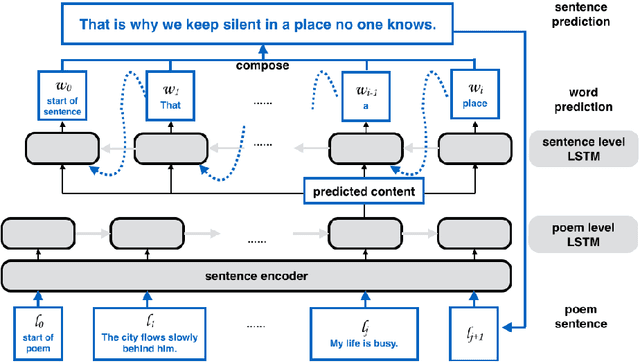
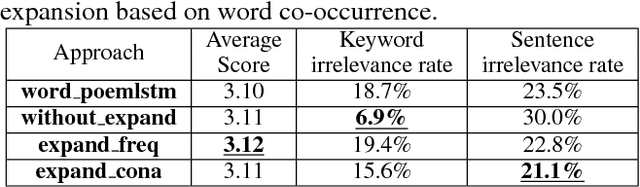
Vision is a common source of inspiration for poetry. The objects and the sentimental imprints that one perceives from an image may lead to various feelings depending on the reader. In this paper, we present a system of poetry generation from images to mimic the process. Given an image, we first extract a few keywords representing objects and sentiments perceived from the image. These keywords are then expanded to related ones based on their associations in human written poems. Finally, verses are generated gradually from the keywords using recurrent neural networks trained on existing poems. Our approach is evaluated by human assessors and compared to other generation baselines. The results show that our method can generate poems that are more artistic than the baseline methods. This is one of the few attempts to generate poetry from images. By deploying our proposed approach, XiaoIce has already generated more than 12 million poems for users since its release in July 2017. A book of its poems has been published by Cheers Publishing, which claimed that the book is the first-ever poetry collection written by an AI in human history.
DA-GAN: Instance-level Image Translation by Deep Attention Generative Adversarial Networks
Feb 18, 2018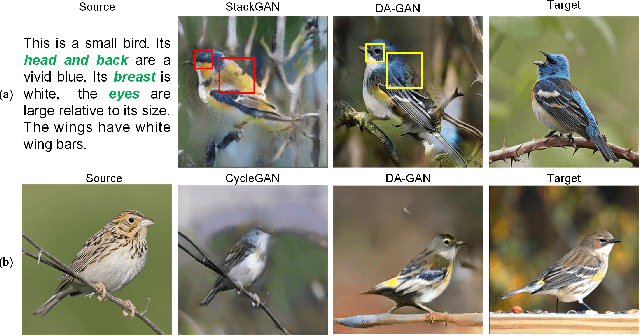
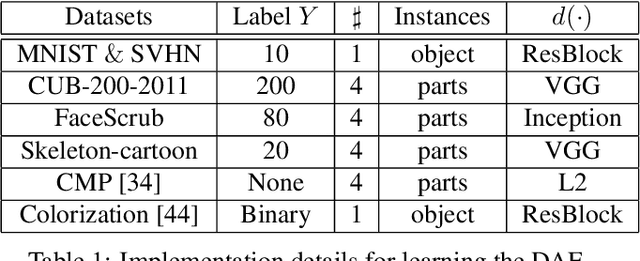
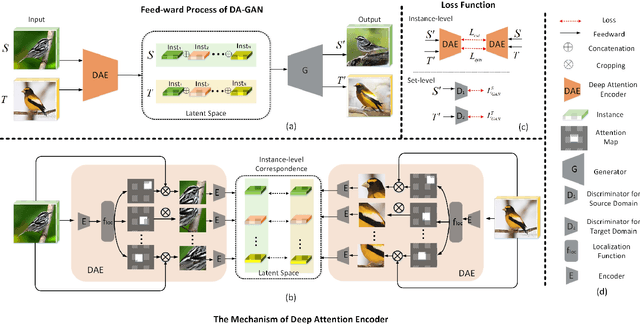

Unsupervised image translation, which aims in translating two independent sets of images, is challenging in discovering the correct correspondences without paired data. Existing works build upon Generative Adversarial Network (GAN) such that the distribution of the translated images are indistinguishable from the distribution of the target set. However, such set-level constraints cannot learn the instance-level correspondences (e.g. aligned semantic parts in object configuration task). This limitation often results in false positives (e.g. geometric or semantic artifacts), and further leads to mode collapse problem. To address the above issues, we propose a novel framework for instance-level image translation by Deep Attention GAN (DA-GAN). Such a design enables DA-GAN to decompose the task of translating samples from two sets into translating instances in a highly-structured latent space. Specifically, we jointly learn a deep attention encoder, and the instancelevel correspondences could be consequently discovered through attending on the learned instance pairs. Therefore, the constraints could be exploited on both set-level and instance-level. Comparisons against several state-ofthe- arts demonstrate the superiority of our approach, and the broad application capability, e.g, pose morphing, data augmentation, etc., pushes the margin of domain translation problem.