 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing AI vs Human-Authored Spear Phishing SMS Attacks: An Empirical Study Using the TRAPD Method
Jun 18, 2024



This paper explores the rising concern of utilizing Large Language Models (LLMs) in spear phishing message generation, and their performance compared to human-authored counterparts. Our pilot study compares the effectiveness of smishing (SMS phishing) messages created by GPT-4 and human authors, which have been personalized to willing targets. The targets assessed the messages in a modified ranked-order experiment using a novel methodology we call TRAPD (Threshold Ranking Approach for Personalized Deception). Specifically, targets provide personal information (job title and location, hobby, item purchased online), spear smishing messages are created using this information by humans and GPT-4, targets are invited back to rank-order 12 messages from most to least convincing (and identify which they would click on), and then asked questions about why they ranked messages the way they did. They also guess which messages are created by an LLM and their reasoning. Results from 25 targets show that LLM-generated messages are most often perceived as more convincing than those authored by humans, with messages related to jobs being the most convincing. We characterize different criteria used when assessing the authenticity of messages including word choice, style, and personal relevance. Results also show that targets were unable to identify whether the messages was AI-generated or human-authored and struggled to identify criteria to use in order to make this distinction. This study aims to highlight the urgent need for further research and improved countermeasures against personalized AI-enabled social engineering attacks.
Decentralized Coordination of Distributed Energy Resources through Local Energy Markets and Deep Reinforcement Learning
Apr 19, 2024



As the energy landscape evolves toward sustainability, the accelerating integration of distributed energy resources poses challenges to the operability and reliability of the electricity grid. One significant aspect of this issue is the notable increase in net load variability at the grid edge. Transactive energy, implemented through local energy markets, has recently garnered attention as a promising solution to address the grid challenges in the form of decentralized, indirect demand response on a community level. Given the nature of these challenges, model-free control approaches, such as deep reinforcement learning, show promise for the decentralized automation of participation within this context. Existing studies at the intersection of transactive energy and model-free control primarily focus on socioeconomic and self-consumption metrics, overlooking the crucial goal of reducing community-level net load variability. This study addresses this gap by training a set of deep reinforcement learning agents to automate end-user participation in ALEX, an economy-driven local energy market. In this setting, agents do not share information and only prioritize individual bill optimization. The study unveils a clear correlation between bill reduction and reduced net load variability in this setup. The impact on net load variability is assessed over various time horizons using metrics such as ramping rate, daily and monthly load factor, as well as daily average and total peak export and import on an open-source dataset. Agents are then benchmarked against several baselines, with their performance levels showing promising results, approaching those of a near-optimal dynamic programming benchmark.
Semi-Centralised Multi-Agent Reinforcement Learning with Policy-Embedded Training
Sep 02, 2022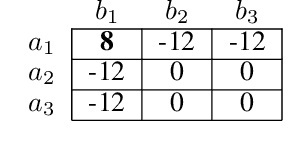
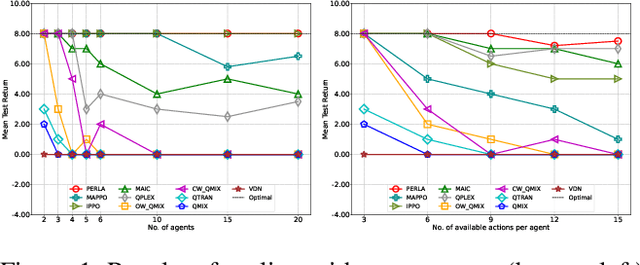
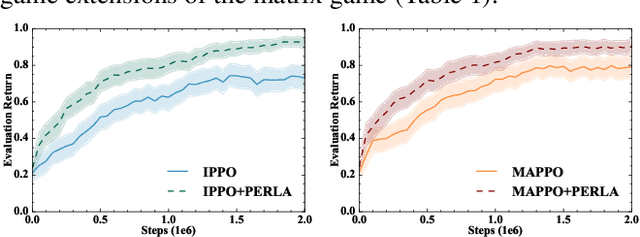
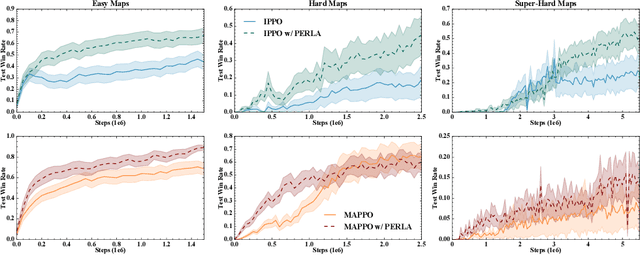
Centralised training (CT) is the basis for many popular multi-agent reinforcement learning (MARL) methods because it allows agents to quickly learn high-performing policies. However, CT relies on agents learning from one-off observations of other agents' actions at a given state. Because MARL agents explore and update their policies during training, these observations often provide poor predictions about other agents' behaviour and the expected return for a given action. CT methods therefore suffer from high variance and error-prone estimates, harming learning. CT methods also suffer from explosive growth in complexity due to the reliance on global observations, unless strong factorisation restrictions are imposed (e.g., monotonic reward functions for QMIX). We address these challenges with a new semi-centralised MARL framework that performs policy-embedded training and decentralised execution. Our method, policy embedded reinforcement learning algorithm (PERLA), is an enhancement tool for Actor-Critic MARL algorithms that leverages a novel parameter sharing protocol and policy embedding method to maintain estimates that account for other agents' behaviour. Our theory proves PERLA dramatically reduces the variance in value estimates. Unlike various CT methods, PERLA, which seamlessly adopts MARL algorithms, scales easily with the number of agents without the need for restrictive factorisation assumptions. We demonstrate PERLA's superior empirical performance and efficient scaling in benchmark environments including StarCraft Micromanagement II and Multi-agent Mujoco
Towards Cooperation in Sequential Prisoner's Dilemmas: a Deep Multiagent Reinforcement Learning Approach
Mar 01, 2018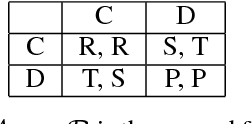
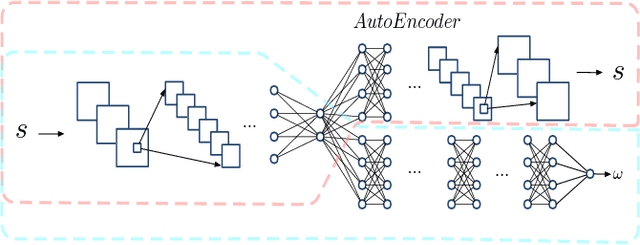
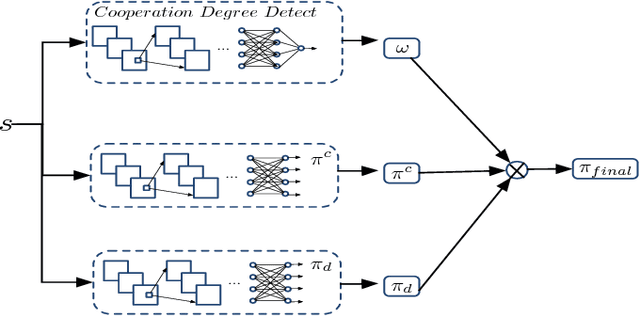

The Iterated Prisoner's Dilemma has guided research on social dilemmas for decades. However, it distinguishes between only two atomic actions: cooperate and defect. In real-world prisoner's dilemmas, these choices are temporally extended and different strategies may correspond to sequences of actions, reflecting grades of cooperation. We introduce a Sequential Prisoner's Dilemma (SPD) game to better capture the aforementioned characteristics. In this work, we propose a deep multiagent reinforcement learning approach that investigates the evolution of mutual cooperation in SPD games. Our approach consists of two phases. The first phase is offline: it synthesizes policies with different cooperation degrees and then trains a cooperation degree detection network. The second phase is online: an agent adaptively selects its policy based on the detected degree of opponent cooperation. The effectiveness of our approach is demonstrated in two representative SPD 2D games: the Apple-Pear game and the Fruit Gathering game. Experimental results show that our strategy can avoid being exploited by exploitative opponents and achieve cooperation with cooperative opponents.
Using PCA to Efficiently Represent State Spaces
Jun 03, 2015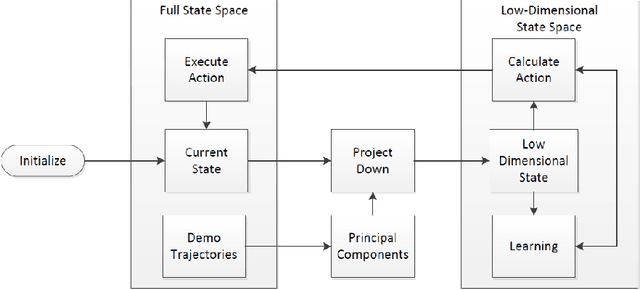
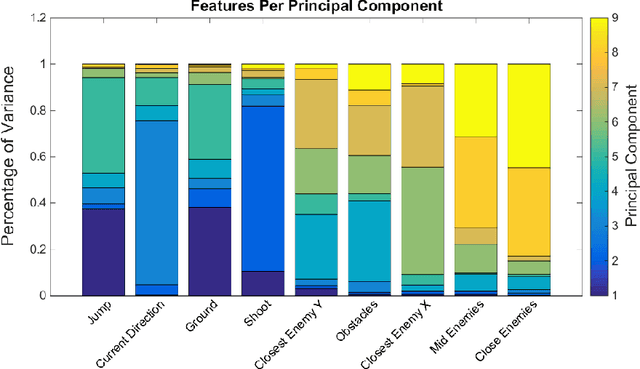
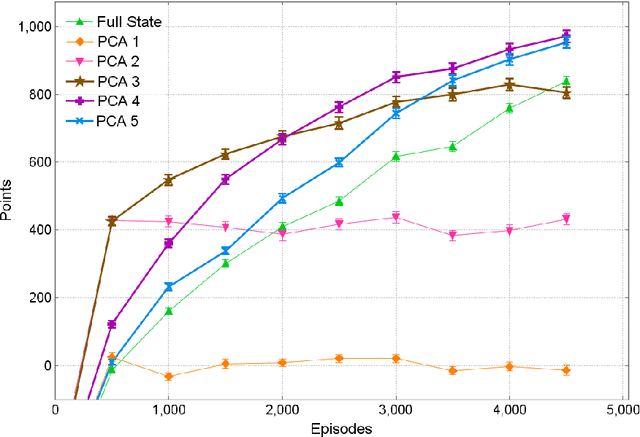
Reinforcement learning algorithms need to deal with the exponential growth of states and actions when exploring optimal control in high-dimensional spaces. This is known as the curse of dimensionality. By projecting the agent's state onto a low-dimensional manifold, we can represent the state space in a smaller and more efficient representation. By using this representation during learning, the agent can converge to a good policy much faster. We test this approach in the Mario Benchmarking Domain. When using dimensionality reduction in Mario, learning converges much faster to a good policy. But, there is a critical convergence-performance trade-off. By projecting onto a low-dimensional manifold, we are ignoring important data. In this paper, we explore this trade-off of convergence and performance. We find that learning in as few as 4 dimensions (instead of 9), we can improve performance past learning in the full dimensional space at a faster convergence rate.