 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoGCN: Second-Order Graph Convolutional Networks
Oct 14, 2021
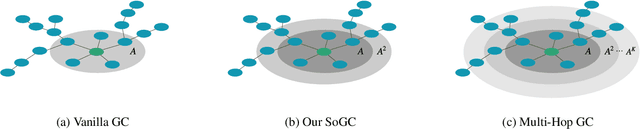
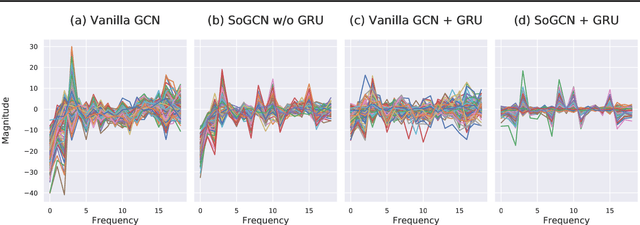
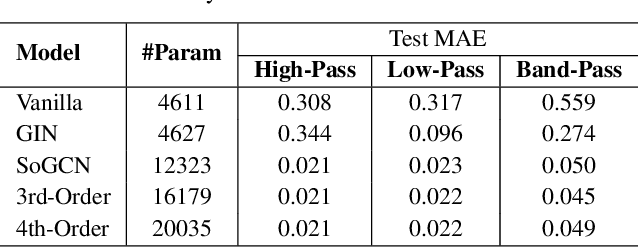
Graph Convolutional Networks (GCN) with multi-hop aggregation is more expressive than one-hop GCN but suffers from higher model complexity. Finding the shortest aggregation range that achieves comparable expressiveness and minimizes this side effect remains an open question. We answer this question by showing that multi-layer second-order graph convolution (SoGC) is sufficient to attain the ability of expressing polynomial spectral filters with arbitrary coefficients. Compared to models with one-hop aggregation, multi-hop propagation, and jump connections, SoGC possesses filter representational completeness while being lightweight, efficient, and easy to implement. Thereby, we suggest that SoGC is a simple design capable of forming the basic building block of GCNs, playing the same role as $3 \times 3$ kernels in CNNs. We build our Second-Order Graph Convolutional Networks (SoGCN) with SoGC and design a synthetic dataset to verify its filter fitting capability to validate these points. For real-world tasks, we present the state-of-the-art performance of SoGCN on the benchmark of node classification, graph classification, and graph regression datasets.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Efficient Visual Recognition with Deep Neural Networks: A Survey on Recent Advances and New Directions
Sep 09, 2021
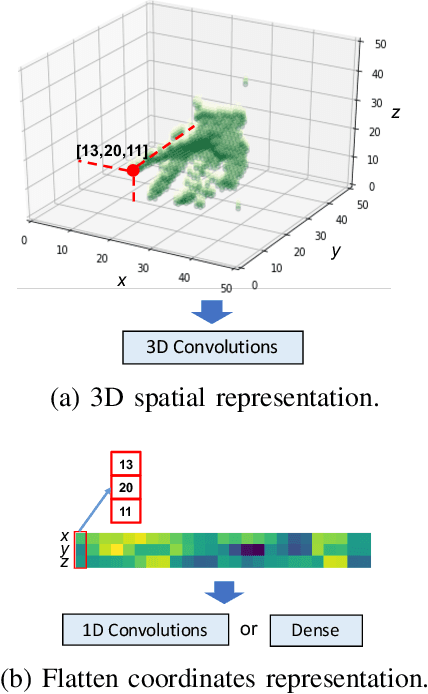
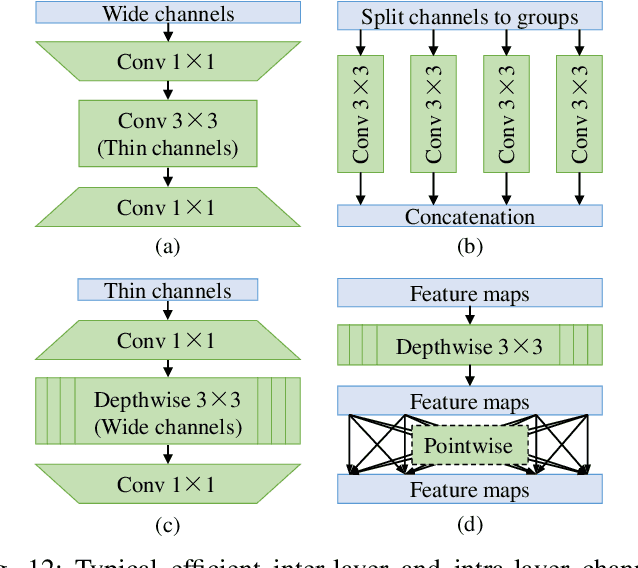
Visual recognition is currently one of the most important and active research areas in computer vision, pattern recognition, and even the general field of artificial intelligence. It has great fundamental importance and strong industrial needs. Deep neural networks (DNNs) have largely boosted their performances on many concrete tasks, with the help of large amounts of training data and new powerful computation resources. Though recognition accuracy is usually the first concern for new progresses, efficiency is actually rather important and sometimes critical for both academic research and industrial applications. Moreover, insightful views on the opportunities and challenges of efficiency are also highly required for the entire community. While general surveys on the efficiency issue of DNNs have been done from various perspectives, as far as we are aware, scarcely any of them focused on visual recognition systematically, and thus it is unclear which progresses are applicable to it and what else should be concerned. In this paper, we present the review of the recent advances with our suggestions on the new possible directions towards improving the efficiency of DNN-related visual recognition approaches. We investigate not only from the model but also the data point of view (which is not the case in existing surveys), and focus on three most studied data types (images, videos and points). This paper attempts to provide a systematic summary via a comprehensive survey which can serve as a valuable reference and inspire both researchers and practitioners who work on visual recognition problems.
Deep Ordinal Regression Forests
Aug 07, 2020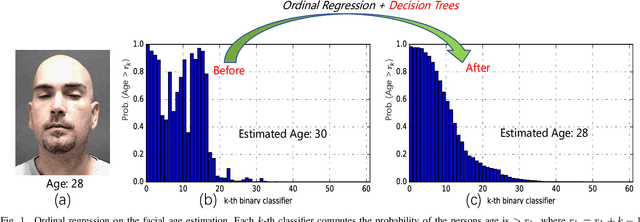
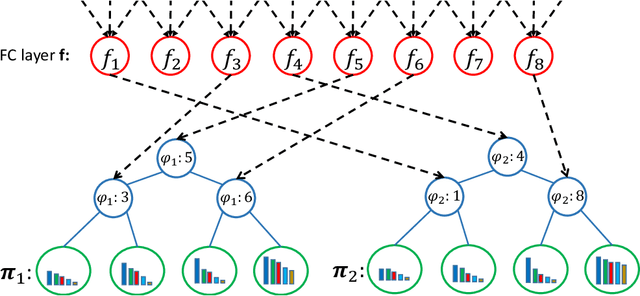


Ordinal regression is a type of regression techniques used for predicting an ordinal variable. Recent methods formulate an ordinal regression problem as a series of binary classification problems. Such methods cannot ensure the global ordinal relationship is preserved since the relationships among different binary classifiers are neglected. We propose a novel ordinal regression approach called Deep Ordinal Regression Forests (DORFs), which is constructed with the differentiable decision trees for obtaining precise and stable global ordinal relationships. The advantages of the proposed DORFs are twofold. First, instead of learning a series of binary classifiers independently, the proposed method learns an ordinal distribution for ordinal regression. Second, the differentiable decision trees can be trained together with the ordinal distribution in an end-to-end manner. The effectiveness of the proposed DORFs is verified on two ordinal regression tasks, i.e., facial age estimation and image aesthetic assessment, showing significant improvements and better stability over the state-of-the-art ordinal regression methods.
Nested Scale Editing for Conditional Image Synthesis
Jun 03, 2020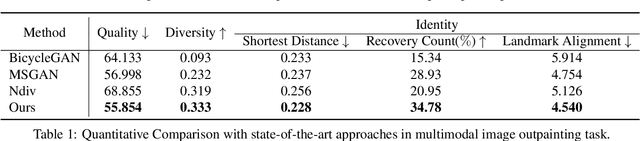
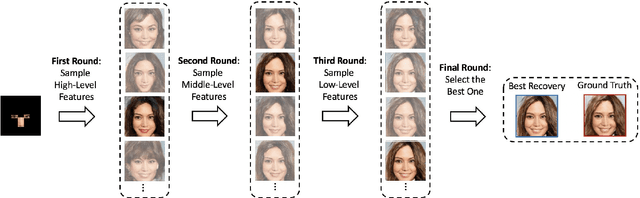
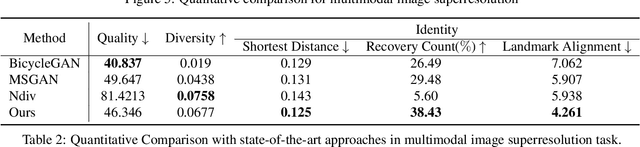
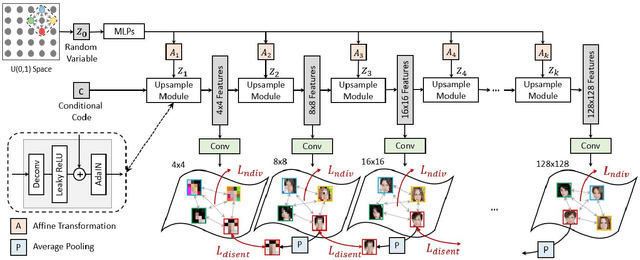
We propose an image synthesis approach that provides stratified navigation in the latent code space. With a tiny amount of partial or very low-resolution image, our approach can consistently out-perform state-of-the-art counterparts in terms of generating the closest sampled image to the ground truth. We achieve this through scale-independent editing while expanding scale-specific diversity. Scale-independence is achieved with a nested scale disentanglement loss. Scale-specific diversity is created by incorporating a progressive diversification constraint. We introduce semantic persistency across the scales by sharing common latent codes. Together they provide better control of the image synthesis process. We evaluate the effectiveness of our proposed approach through various tasks, including image outpainting, image superresolution, and cross-domain image translation.
Potential Field: Interpretable and Unified Representation for Trajectory Prediction
Nov 18, 2019
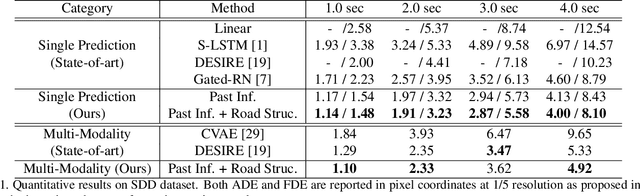
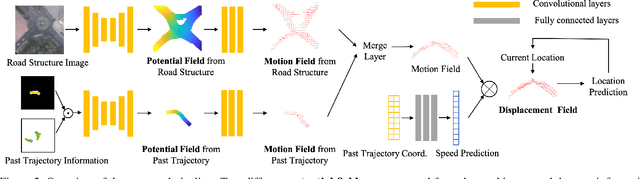

Predicting an agent's future trajectory is a challenging task given the complicated stimuli (environmental/inertial/social) of motion. Prior works learn individual stimulus from different modules and fuse the representations in an end-to-end manner, which makes it hard to understand what are actually captured and how they are fused. In this work, we borrow the notion of potential field from physics as an interpretable and unified representation to model all stimuli. This allows us to not only supervise the intermediate learning process, but also have a coherent method to fuse the information of different sources. From the generated potential fields, we further estimate future motion direction and speed, which are modeled as Gaussian distributions to account for the multi-modal nature of the problem. The final prediction results are generated by recurrently moving past location based on the estimated motion direction and speed. We show state-of-the-art results on the ETH, UCY, and Stanford Drone datasets.
SegSort: Segmentation by Discriminative Sorting of Segments
Oct 30, 2019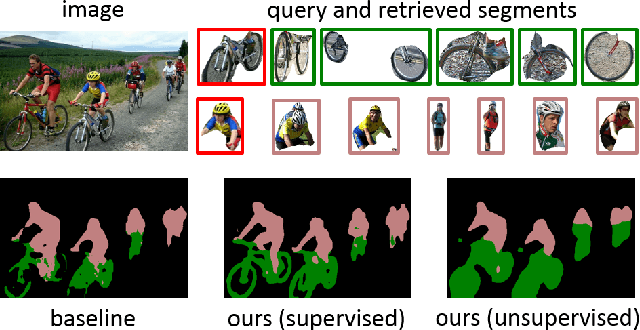
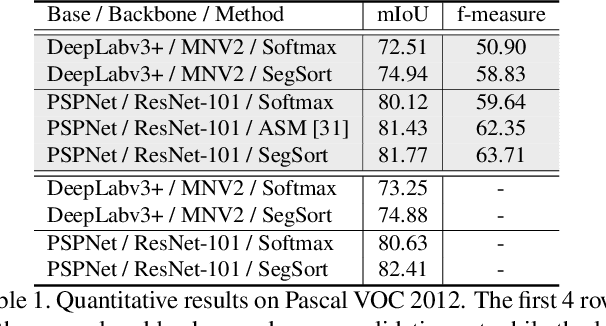
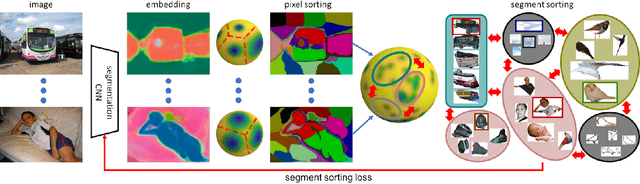
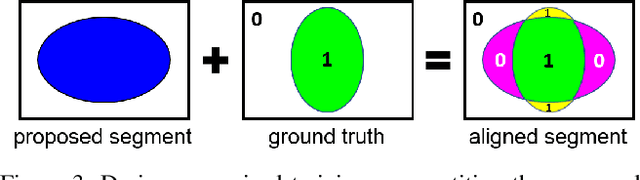
Almost all existing deep learning approaches for semantic segmentation tackle this task as a pixel-wise classification problem. Yet humans understand a scene not in terms of pixels, but by decomposing it into perceptual groups and structures that are the basic building blocks of recognition. This motivates us to propose an end-to-end pixel-wise metric learning approach that mimics this process. In our approach, the optimal visual representation determines the right segmentation within individual images and associates segments with the same semantic classes across images. The core visual learning problem is therefore to maximize the similarity within segments and minimize the similarity between segments. Given a model trained this way, inference is performed consistently by extracting pixel-wise embeddings and clustering, with the semantic label determined by the majority vote of its nearest neighbors from an annotated set. As a result, we present the SegSort, as a first attempt using deep learning for unsupervised semantic segmentation, achieving $76\%$ performance of its supervised counterpart. When supervision is available, SegSort shows consistent improvements over conventional approaches based on pixel-wise softmax training. Additionally, our approach produces more precise boundaries and consistent region predictions. The proposed SegSort further produces an interpretable result, as each choice of label can be easily understood from the retrieved nearest segments.
Deep Image Blending
Oct 25, 2019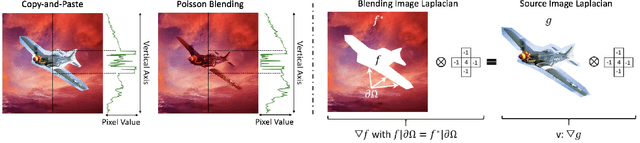
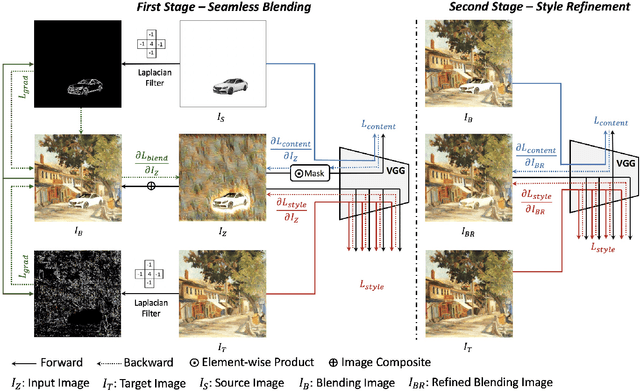


Image composition is an important operation to create visual content. Among image composition tasks, image blending aims to seamlessly blend an object from a source image onto a target image with lightly mask adjustment. A popular approach is Poisson image blending, which enforces the gradient domain smoothness in the composite image. However, this approach only considers the boundary pixels of target image, and thus can not adapt to texture of target image. In addition, the colors of the target image often seep through the original source object too much causing a significant loss of content of the source object. We propose a Poisson blending loss that achieves the same purpose of Poisson image blending. In addition, we jointly optimize the proposed Poisson blending loss as well as the style and content loss computed from a deep network, and reconstruct the blending region by iteratively updating the pixels using the L-BFGS solver. In the blending image, we not only smooth out gradient domain of the blending boundary but also add consistent texture into the blending region. User studies show that our method outperforms strong baselines as well as state-of-the-art approaches when placing objects onto both paintings and real-world images.
Multimodal Image Outpainting With Regularized Normalized Diversification
Oct 25, 2019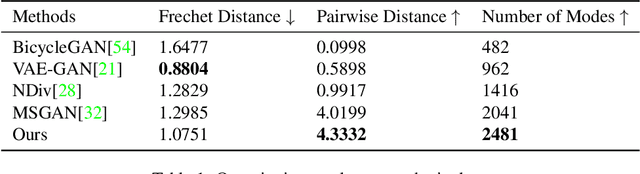
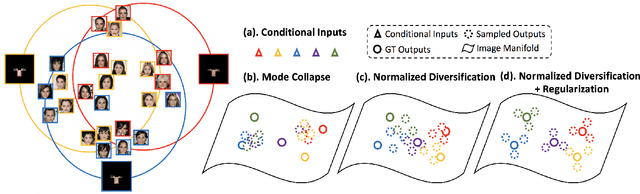
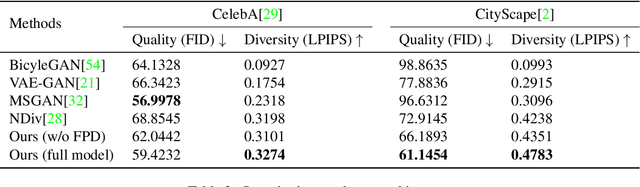
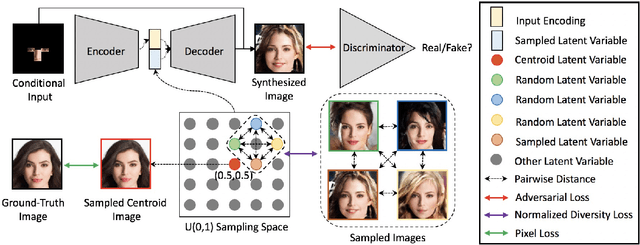
In this paper, we study the problem of generating a set ofrealistic and diverse backgrounds when given only a smallforeground region. We refer to this task as image outpaint-ing. The technical challenge of this task is to synthesize notonly plausible but also diverse image outputs. Traditionalgenerative adversarial networks suffer from mode collapse.While recent approaches propose to maximize orpreserve the pairwise distance between generated sampleswith respect to their latent distance, they do not explicitlyprevent the diverse samples of different conditional inputsfrom collapsing. Therefore, we propose a new regulariza-tion method to encourage diverse sampling in conditionalsynthesis. In addition, we propose a feature pyramid dis-criminator to improve the image quality. Our experimen-tal results show that our model can produce more diverseimages without sacrificing visual quality compared to state-of-the-arts approaches in both the CelebA face dataset and the Cityscape scene dataset.
Image-based marker tracking and registration for intraoperative 3D image-guided interventions using augmented reality
Aug 08, 2019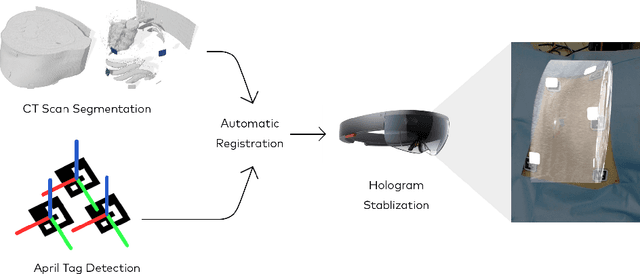
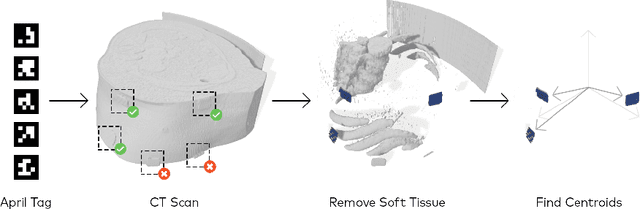
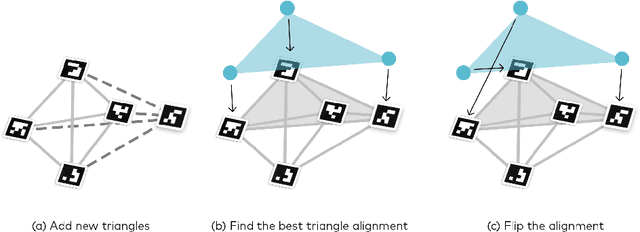
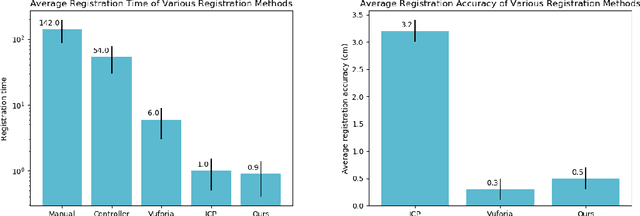
Augmented reality has the potential to improve operating room workflow by allowing physicians to "see" inside a patient through the projection of imaging directly onto the surgical field. For this to be useful the acquired imaging must be quickly and accurately registered with patient and the registration must be maintained. Here we describe a method for projecting a CT scan with Microsoft Hololens and then aligning that projection to a set of fiduciary markers. Radio-opaque stickers with unique QR-codes are placed on an object prior to acquiring a CT scan. The location of the markers in the CT scan are extracted and the CT scan is converted into a 3D surface object. The 3D object is then projected using the Hololens onto a table on which the same markers are placed. We designed an algorithm that aligns the markers on the 3D object with the markers on the table. To extract the markers and convert the CT into a 3D object took less than 5 seconds. To align three markers, it took $0.9 \pm 0.2$ seconds to achieve an accuracy of $5 \pm 2$ mm. These findings show that it is feasible to use a combined radio-opaque optical marker, placed on a patient prior to a CT scan, to subsequently align the acquired CT scan with the patient.