 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Potential Field: Interpretable and Unified Representation for Trajectory Prediction
Nov 18, 2019
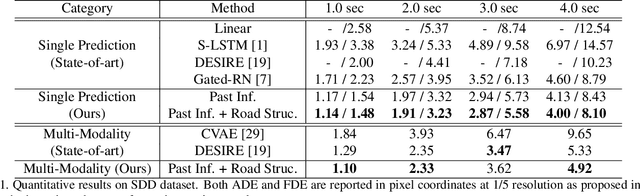
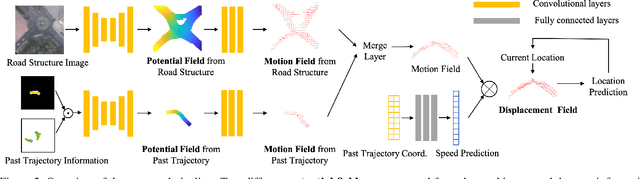

Predicting an agent's future trajectory is a challenging task given the complicated stimuli (environmental/inertial/social) of motion. Prior works learn individual stimulus from different modules and fuse the representations in an end-to-end manner, which makes it hard to understand what are actually captured and how they are fused. In this work, we borrow the notion of potential field from physics as an interpretable and unified representation to model all stimuli. This allows us to not only supervise the intermediate learning process, but also have a coherent method to fuse the information of different sources. From the generated potential fields, we further estimate future motion direction and speed, which are modeled as Gaussian distributions to account for the multi-modal nature of the problem. The final prediction results are generated by recurrently moving past location based on the estimated motion direction and speed. We show state-of-the-art results on the ETH, UCY, and Stanford Drone datasets.
Customizing First Person Image Through Desired Actions
Apr 01, 2017

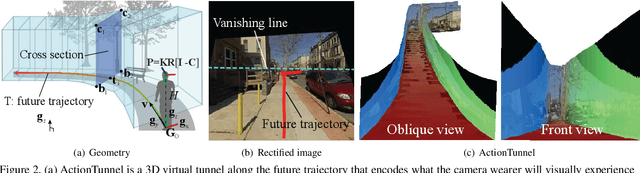
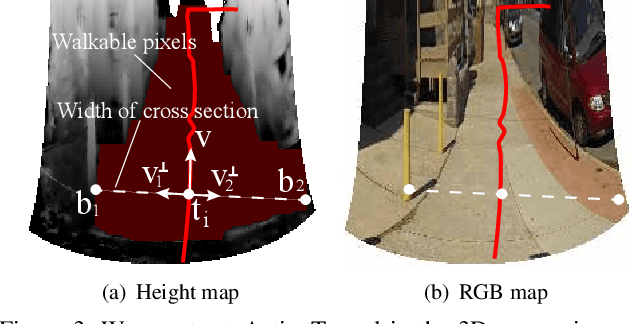
This paper studies a problem of inverse visual path planning: creating a visual scene from a first person action. Our conjecture is that the spatial arrangement of a first person visual scene is deployed to afford an action, and therefore, the action can be inversely used to synthesize a new scene such that the action is feasible. As a proof-of-concept, we focus on linking visual experiences induced by walking. A key innovation of this paper is a concept of ActionTunnel---a 3D virtual tunnel along the future trajectory encoding what the wearer will visually experience as moving into the scene. This connects two distinctive first person images through similar walking paths. Our method takes a first person image with a user defined future trajectory and outputs a new image that can afford the future motion. The image is created by combining present and future ActionTunnels in 3D where the missing pixels in adjoining area are computed by a generative adversarial network. Our work can provide a travel across different first person experiences in diverse real world scenes.
Social Behavior Prediction from First Person Videos
Nov 29, 2016


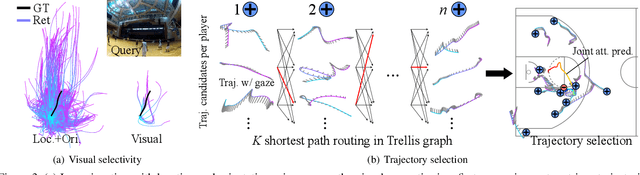
This paper presents a method to predict the future movements (location and gaze direction) of basketball players as a whole from their first person videos. The predicted behaviors reflect an individual physical space that affords to take the next actions while conforming to social behaviors by engaging to joint attention. Our key innovation is to use the 3D reconstruction of multiple first person cameras to automatically annotate each other's the visual semantics of social configurations. We leverage two learning signals uniquely embedded in first person videos. Individually, a first person video records the visual semantics of a spatial and social layout around a person that allows associating with past similar situations. Collectively, first person videos follow joint attention that can link the individuals to a group. We learn the egocentric visual semantics of group movements using a Siamese neural network to retrieve future trajectories. We consolidate the retrieved trajectories from all players by maximizing a measure of social compatibility---the gaze alignment towards joint attention predicted by their social formation, where the dynamics of joint attention is learned by a long-term recurrent convolutional network. This allows us to characterize which social configuration is more plausible and predict future group trajectories.