 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Federated Learning in Unreliable Wireless Networks: A Client Selection Approach
Feb 26, 2025Federated learning (FL) has emerged as a promising distributed learning paradigm for training deep neural networks (DNNs) at the wireless edge, but its performance can be severely hindered by unreliable wireless transmission and inherent data heterogeneity among clients. Existing solutions primarily address these challenges by incorporating wireless resource optimization strategies, often focusing on uplink resource allocation across clients under the assumption of homogeneous client-server network standards. However, these approaches overlooked the fact that mobile clients may connect to the server via diverse network standards (e.g., 4G, 5G, Wi-Fi) with customized configurations, limiting the flexibility of server-side modifications and restricting applicability in real-world commercial networks. This paper presents a novel theoretical analysis about how transmission failures in unreliable networks distort the effective label distributions of local samples, causing deviations from the global data distribution and introducing convergence bias in FL. Our analysis reveals that a carefully designed client selection strategy can mitigate biases induced by network unreliability and data heterogeneity. Motivated by this insight, we propose FedCote, a client selection approach that optimizes client selection probabilities without relying on wireless resource scheduling. Experimental results demonstrate the robustness of FedCote in DNN-based classification tasks under unreliable networks with frequent transmission failures.
BSDB-Net: Band-Split Dual-Branch Network with Selective State Spaces Mechanism for Monaural Speech Enhancement
Dec 26, 2024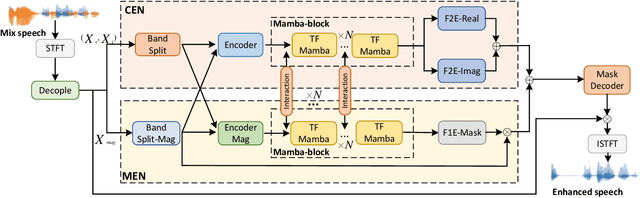
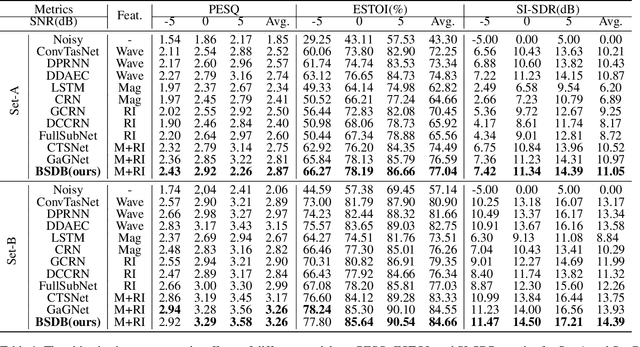
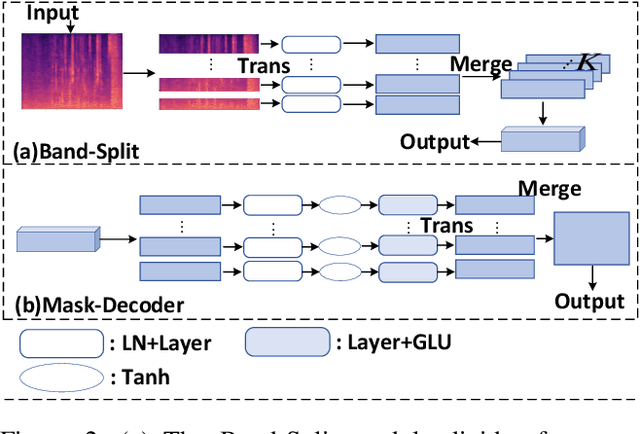
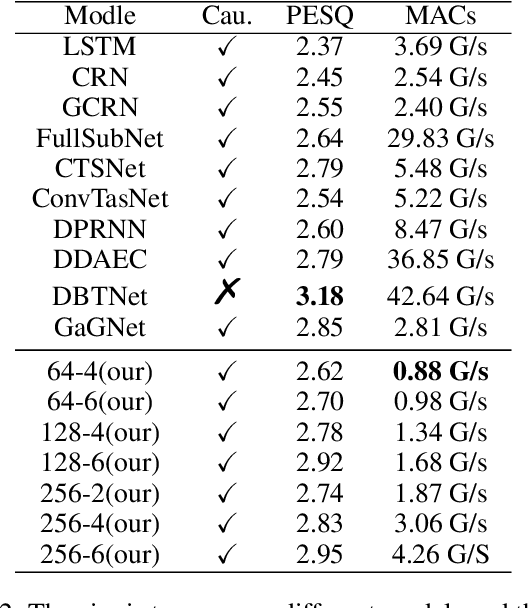
Although the complex spectrum-based speech enhancement(SE) methods have achieved significant performance, coupling amplitude and phase can lead to a compensation effect, where amplitude information is sacrificed to compensate for the phase that is harmful to SE. In addition, to further improve the performance of SE, many modules are stacked onto SE, resulting in increased model complexity that limits the application of SE. To address these problems, we proposed a dual-path network based on compressed frequency using Mamba. First, we extract amplitude and phase information through parallel dual branches. This approach leverages structured complex spectra to implicitly capture phase information and solves the compensation effect by decoupling amplitude and phase, and the network incorporates an interaction module to suppress unnecessary parts and recover missing components from the other branch. Second, to reduce network complexity, the network introduces a band-split strategy to compress the frequency dimension. To further reduce complexity while maintaining good performance, we designed a Mamba-based module that models the time and frequency dimensions under linear complexity. Finally, compared to baselines, our model achieves an average 8.3 times reduction in computational complexity while maintaining superior performance. Furthermore, it achieves a 25 times reduction in complexity compared to transformer-based models.
Uncertainty-Aware Decision-Making and Planning for Autonomous Forced Merging
Oct 27, 2024



In this paper, we develop an uncertainty-aware decision-making and motion-planning method for an autonomous ego vehicle in forced merging scenarios, considering the motion uncertainty of surrounding vehicles. The method dynamically captures the uncertainty of surrounding vehicles by online estimation of their acceleration bounds, enabling a reactive but rapid understanding of the uncertainty characteristics of the surrounding vehicles. By leveraging these estimated bounds, a non-conservative forward occupancy of surrounding vehicles is predicted over a horizon, which is incorporated in both the decision-making process and the motion-planning strategy, to enhance the resilience and safety of the planned reference trajectory. The method successfully fulfills the tasks in challenging forced merging scenarios, and the properties are illustrated by comparison with several alternative approaches.
Boosting Medical Image-based Cancer Detection via Text-guided Supervision from Reports
May 23, 2024



The absence of adequately sufficient expert-level tumor annotations hinders the effectiveness of supervised learning based opportunistic cancer screening on medical imaging. Clinical reports (that are rich in descriptive textual details) can offer a "free lunch'' supervision information and provide tumor location as a type of weak label to cope with screening tasks, thus saving human labeling workloads, if properly leveraged. However, predicting cancer only using such weak labels can be very changeling since tumors are usually presented in small anatomical regions compared to the whole 3D medical scans. Weakly semi-supervised learning (WSSL) utilizes a limited set of voxel-level tumor annotations and incorporates alongside a substantial number of medical images that have only off-the-shelf clinical reports, which may strike a good balance between minimizing expert annotation workload and optimizing screening efficacy. In this paper, we propose a novel text-guided learning method to achieve highly accurate cancer detection results. Through integrating diagnostic and tumor location text prompts into the text encoder of a vision-language model (VLM), optimization of weakly supervised learning can be effectively performed in the latent space of VLM, thereby enhancing the stability of training. Our approach can leverage clinical knowledge by large-scale pre-trained VLM to enhance generalization ability, and produce reliable pseudo tumor masks to improve cancer detection. Our extensive quantitative experimental results on a large-scale cancer dataset, including 1,651 unique patients, validate that our approach can reduce human annotation efforts by at least 70% while maintaining comparable cancer detection accuracy to competing fully supervised methods (AUC value 0.961 versus 0.966).
Efficient Surgical Tool Recognition via HMM-Stabilized Deep Learning
Apr 07, 2024



Recognizing various surgical tools, actions and phases from surgery videos is an important problem in computer vision with exciting clinical applications. Existing deep-learning-based methods for this problem either process each surgical video as a series of independent images without considering their dependence, or rely on complicated deep learning models to count for dependence of video frames. In this study, we revealed from exploratory data analysis that surgical videos enjoy relatively simple semantic structure, where the presence of surgical phases and tools can be well modeled by a compact hidden Markov model (HMM). Based on this observation, we propose an HMM-stabilized deep learning method for tool presence detection. A wide range of experiments confirm that the proposed approaches achieve better performance with lower training and running costs, and support more flexible ways to construct and utilize training data in scenarios where not all surgery videos of interest are extensively labelled. These results suggest that popular deep learning approaches with over-complicated model structures may suffer from inefficient utilization of data, and integrating ingredients of deep learning and statistical learning wisely may lead to more powerful algorithms that enjoy competitive performance, transparent interpretation and convenient model training simultaneously.
Medical Visual Prompting (MVP): A Unified Framework for Versatile and High-Quality Medical Image Segmentation
Apr 01, 2024



Accurate segmentation of lesion regions is crucial for clinical diagnosis and treatment across various diseases. While deep convolutional networks have achieved satisfactory results in medical image segmentation, they face challenges such as loss of lesion shape information due to continuous convolution and downsampling, as well as the high cost of manually labeling lesions with varying shapes and sizes. To address these issues, we propose a novel medical visual prompting (MVP) framework that leverages pre-training and prompting concepts from natural language processing (NLP). The framework utilizes three key components: Super-Pixel Guided Prompting (SPGP) for superpixelating the input image, Image Embedding Guided Prompting (IEGP) for freezing patch embedding and merging with superpixels to provide visual prompts, and Adaptive Attention Mechanism Guided Prompting (AAGP) for pinpointing prompt content and efficiently adapting all layers. By integrating SPGP, IEGP, and AAGP, the MVP enables the segmentation network to better learn shape prompting information and facilitates mutual learning across different tasks. Extensive experiments conducted on five datasets demonstrate superior performance of this method in various challenging medical image tasks, while simplifying single-task medical segmentation models. This novel framework offers improved performance with fewer parameters and holds significant potential for accurate segmentation of lesion regions in various medical tasks, making it clinically valuable.
Robust Predictive Motion Planning by Learning Obstacle Uncertainty
Mar 10, 2024



Safe motion planning for robotic systems in dynamic environments is nontrivial in the presence of uncertain obstacles, where estimation of obstacle uncertainties is crucial in predicting future motions of dynamic obstacles. The worst-case characterization gives a conservative uncertainty prediction and may result in infeasible motion planning for the ego robotic system. In this paper, an efficient, robust, and safe motion-planing algorithm is developed by learning the obstacle uncertainties online. More specifically, the unknown yet intended control set of obstacles is efficiently computed by solving a linear programming problem. The learned control set is used to compute forward reachable sets of obstacles that are less conservative than the worst-case prediction. Based on the forward prediction, a robust model predictive controller is designed to compute a safe reference trajectory for the ego robotic system that remains outside the reachable sets of obstacles over the prediction horizon. The method is applied to a car-like mobile robot in both simulations and hardware experiments to demonstrate its effectiveness.
Improved Prognostic Prediction of Pancreatic Cancer Using Multi-Phase CT by Integrating Neural Distance and Texture-Aware Transformer
Aug 01, 2023



Pancreatic ductal adenocarcinoma (PDAC) is a highly lethal cancer in which the tumor-vascular involvement greatly affects the resectability and, thus, overall survival of patients. However, current prognostic prediction methods fail to explicitly and accurately investigate relationships between the tumor and nearby important vessels. This paper proposes a novel learnable neural distance that describes the precise relationship between the tumor and vessels in CT images of different patients, adopting it as a major feature for prognosis prediction. Besides, different from existing models that used CNNs or LSTMs to exploit tumor enhancement patterns on dynamic contrast-enhanced CT imaging, we improved the extraction of dynamic tumor-related texture features in multi-phase contrast-enhanced CT by fusing local and global features using CNN and transformer modules, further enhancing the features extracted across multi-phase CT images. We extensively evaluated and compared the proposed method with existing methods in the multi-center (n=4) dataset with 1,070 patients with PDAC, and statistical analysis confirmed its clinical effectiveness in the external test set consisting of three centers. The developed risk marker was the strongest predictor of overall survival among preoperative factors and it has the potential to be combined with established clinical factors to select patients at higher risk who might benefit from neoadjuvant therapy.
Hybrid Control Policy for Artificial Pancreas via Ensemble Deep Reinforcement Learning
Jul 14, 2023Objective: The artificial pancreas (AP) has shown promising potential in achieving closed-loop glucose control for individuals with type 1 diabetes mellitus (T1DM). However, designing an effective control policy for the AP remains challenging due to the complex physiological processes, delayed insulin response, and inaccurate glucose measurements. While model predictive control (MPC) offers safety and stability through the dynamic model and safety constraints, it lacks individualization and is adversely affected by unannounced meals. Conversely, deep reinforcement learning (DRL) provides personalized and adaptive strategies but faces challenges with distribution shifts and substantial data requirements. Methods: We propose a hybrid control policy for the artificial pancreas (HyCPAP) to address the above challenges. HyCPAP combines an MPC policy with an ensemble DRL policy, leveraging the strengths of both policies while compensating for their respective limitations. To facilitate faster deployment of AP systems in real-world settings, we further incorporate meta-learning techniques into HyCPAP, leveraging previous experience and patient-shared knowledge to enable fast adaptation to new patients with limited available data. Results: We conduct extensive experiments using the FDA-accepted UVA/Padova T1DM simulator across three scenarios. Our approaches achieve the highest percentage of time spent in the desired euglycemic range and the lowest occurrences of hypoglycemia. Conclusion: The results clearly demonstrate the superiority of our methods for closed-loop glucose management in individuals with T1DM. Significance: The study presents novel control policies for AP systems, affirming the great potential of proposed methods for efficient closed-loop glucose control.
Dirichlet Diffusion Score Model for Biological Sequence Generation
May 18, 2023



Designing biological sequences is an important challenge that requires satisfying complex constraints and thus is a natural problem to address with deep generative modeling. Diffusion generative models have achieved considerable success in many applications. Score-based generative stochastic differential equations (SDE) model is a continuous-time diffusion model framework that enjoys many benefits, but the originally proposed SDEs are not naturally designed for modeling discrete data. To develop generative SDE models for discrete data such as biological sequences, here we introduce a diffusion process defined in the probability simplex space with stationary distribution being the Dirichlet distribution. This makes diffusion in continuous space natural for modeling discrete data. We refer to this approach as Dirchlet diffusion score model. We demonstrate that this technique can generate samples that satisfy hard constraints using a Sudoku generation task. This generative model can also solve Sudoku, including hard puzzles, without additional training. Finally, we applied this approach to develop the first human promoter DNA sequence design model and showed that designed sequences share similar properties with natural promoter sequences.