 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapGo: Model-Assisted Policy Optimization for Goal-Oriented Tasks
May 13, 2021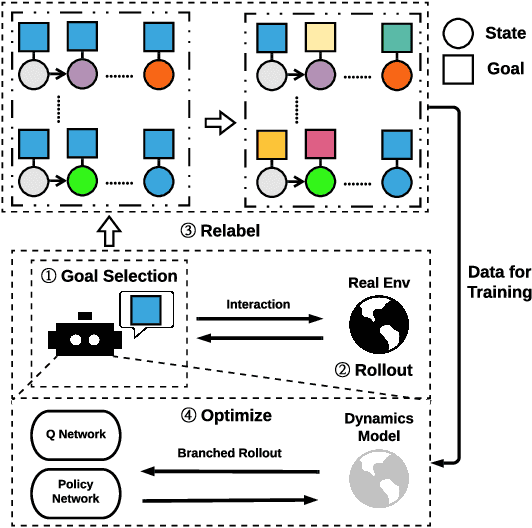
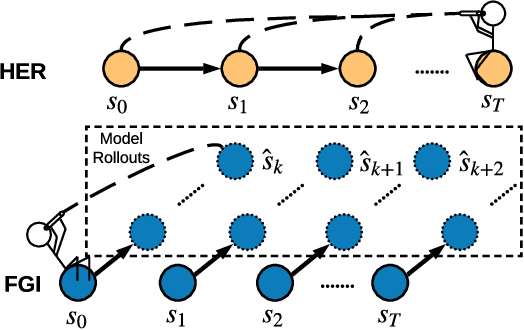

In Goal-oriented Reinforcement learning, relabeling the raw goals in past experience to provide agents with hindsight ability is a major solution to the reward sparsity problem. In this paper, to enhance the diversity of relabeled goals, we develop FGI (Foresight Goal Inference), a new relabeling strategy that relabels the goals by looking into the future with a learned dynamics model. Besides, to improve sample efficiency, we propose to use the dynamics model to generate simulated trajectories for policy training. By integrating these two improvements, we introduce the MapGo framework (Model-Assisted Policy Optimization for Goal-oriented tasks). In our experiments, we first show the effectiveness of the FGI strategy compared with the hindsight one, and then show that the MapGo framework achieves higher sample efficiency when compared to model-free baselines on a set of complicated tasks.
Improving Knowledge Tracing via Pre-training Question Embeddings
Dec 09, 2020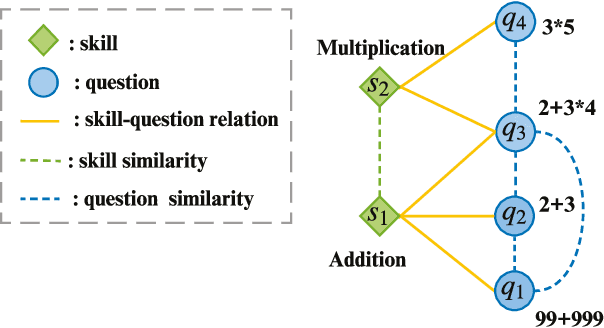
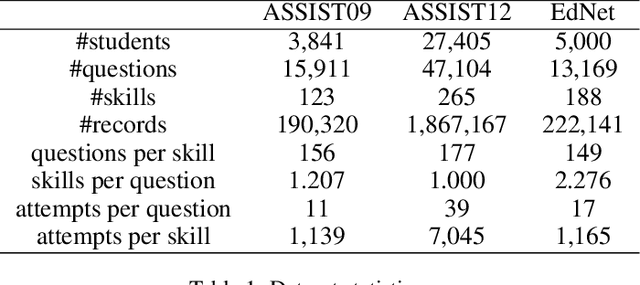
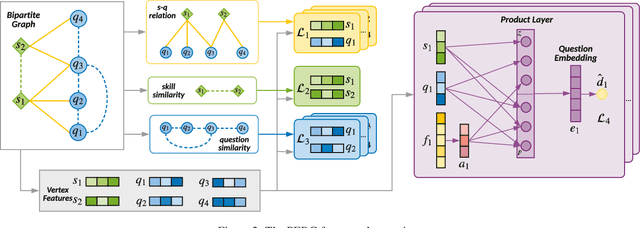
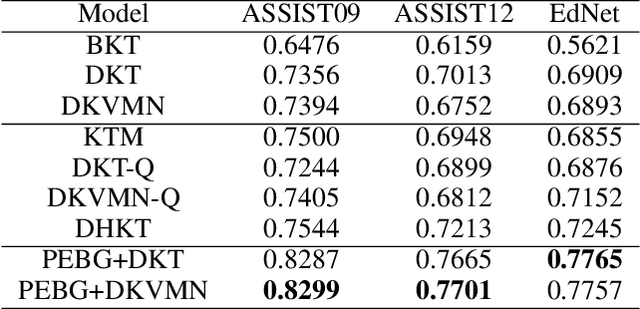
Knowledge tracing (KT) defines the task of predicting whether students can correctly answer questions based on their historical response. Although much research has been devoted to exploiting the question information, plentiful advanced information among questions and skills hasn't been well extracted, making it challenging for previous work to perform adequately. In this paper, we demonstrate that large gains on KT can be realized by pre-training embeddings for each question on abundant side information, followed by training deep KT models on the obtained embeddings. To be specific, the side information includes question difficulty and three kinds of relations contained in a bipartite graph between questions and skills. To pre-train the question embeddings, we propose to use product-based neural networks to recover the side information. As a result, adopting the pre-trained embeddings in existing deep KT models significantly outperforms state-of-the-art baselines on three common KT datasets.
Model-based Policy Optimization with Unsupervised Model Adaptation
Oct 28, 2020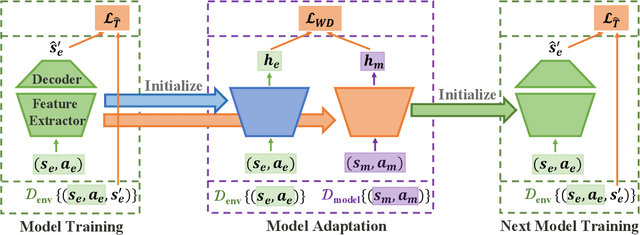
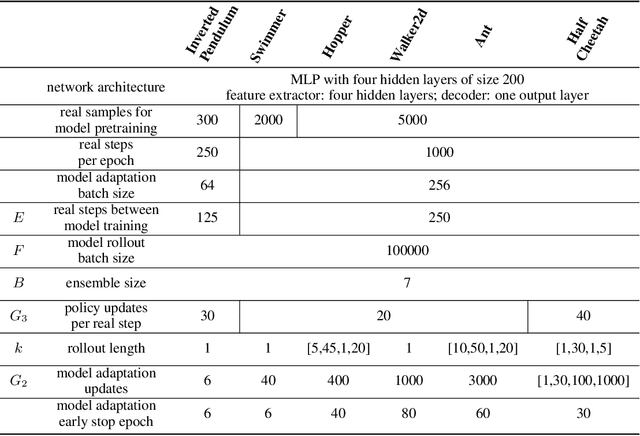
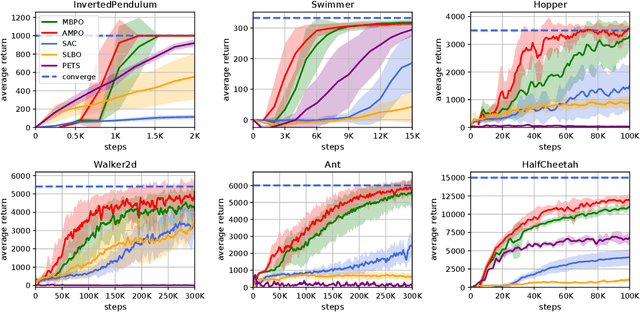
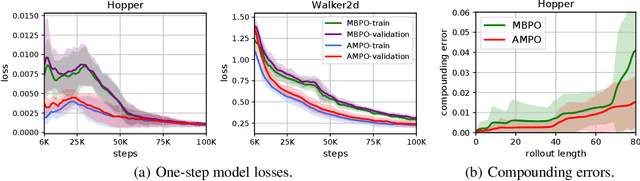
Model-based reinforcement learning methods learn a dynamics model with real data sampled from the environment and leverage it to generate simulated data to derive an agent. However, due to the potential distribution mismatch between simulated data and real data, this could lead to degraded performance. Despite much effort being devoted to reducing this distribution mismatch, existing methods fail to solve it explicitly. In this paper, we investigate how to bridge the gap between real and simulated data due to inaccurate model estimation for better policy optimization. To begin with, we first derive a lower bound of the expected return, which naturally inspires a bound maximization algorithm by aligning the simulated and real data distributions. To this end, we propose a novel model-based reinforcement learning framework AMPO, which introduces unsupervised model adaptation to minimize the integral probability metric (IPM) between feature distributions from real and simulated data. Instantiating our framework with Wasserstein-1 distance gives a practical model-based approach. Empirically, our approach achieves state-of-the-art performance in terms of sample efficiency on a range of continuous control benchmark tasks.
GIKT: A Graph-based Interaction Model for Knowledge Tracing
Sep 13, 2020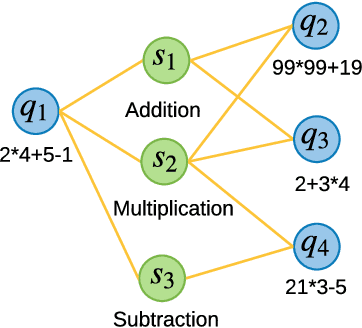
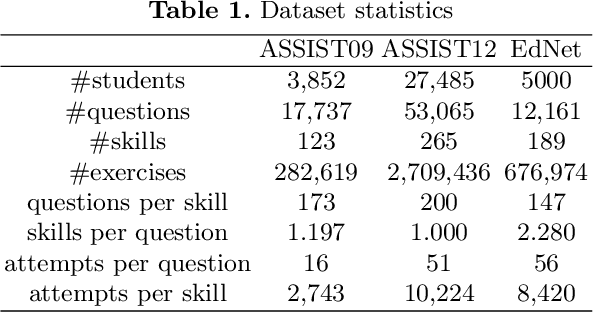
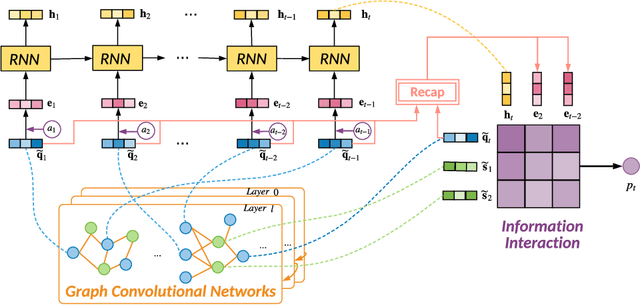
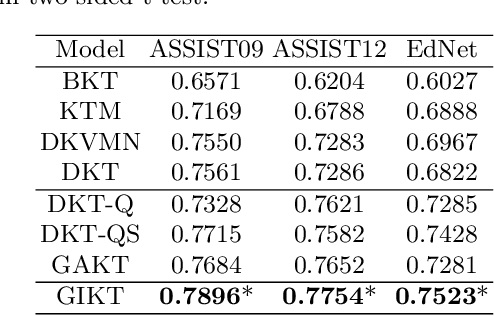
With the rapid development in online education, knowledge tracing (KT) has become a fundamental problem which traces students' knowledge status and predicts their performance on new questions. Questions are often numerous in online education systems, and are always associated with much fewer skills. However, the previous literature fails to involve question information together with high-order question-skill correlations, which is mostly limited by data sparsity and multi-skill problems. From the model perspective, previous models can hardly capture the long-term dependency of student exercise history, and cannot model the interactions between student-questions, and student-skills in a consistent way. In this paper, we propose a Graph-based Interaction model for Knowledge Tracing (GIKT) to tackle the above probems. More specifically, GIKT utilizes graph convolutional network (GCN) to substantially incorporate question-skill correlations via embedding propagation. Besides, considering that relevant questions are usually scattered throughout the exercise history, and that question and skill are just different instantiations of knowledge, GIKT generalizes the degree of students' master of the question to the interactions between the student's current state, the student's history related exercises, the target question, and related skills. Experiments on three datasets demonstrate that GIKT achieves the new state-of-the-art performance, with at least 1% absolute AUC improvement.
Bidirectional Model-based Policy Optimization
Jul 04, 2020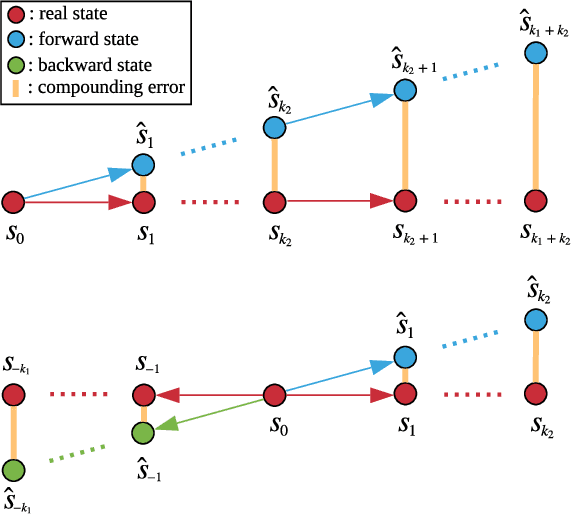
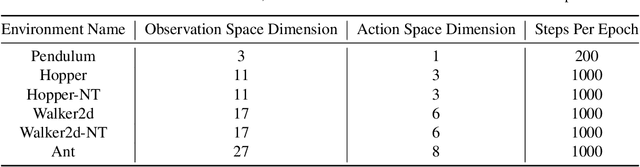
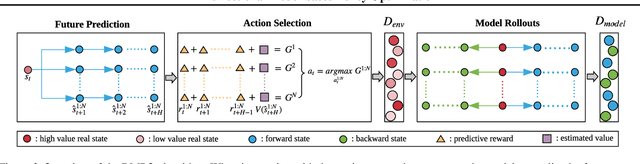

Model-based reinforcement learning approaches leverage a forward dynamics model to support planning and decision making, which, however, may fail catastrophically if the model is inaccurate. Although there are several existing methods dedicated to combating the model error, the potential of the single forward model is still limited. In this paper, we propose to additionally construct a backward dynamics model to reduce the reliance on accuracy in forward model predictions. We develop a novel method, called Bidirectional Model-based Policy Optimization (BMPO) to utilize both the forward model and backward model to generate short branched rollouts for policy optimization. Furthermore, we theoretically derive a tighter bound of return discrepancy, which shows the superiority of BMPO against the one using merely the forward model. Extensive experiments demonstrate that BMPO outperforms state-of-the-art model-based methods in terms of sample efficiency and asymptotic performance.
Large-Scale Optimal Transport via Adversarial Training with Cycle-Consistency
Mar 14, 2020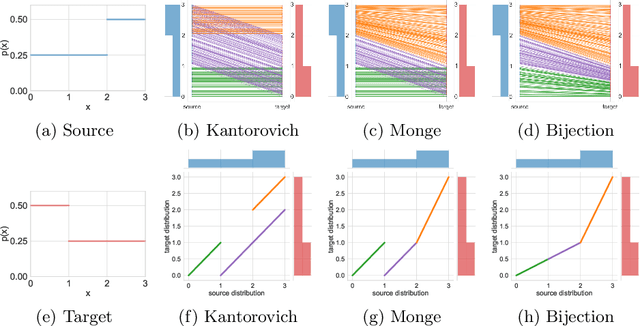
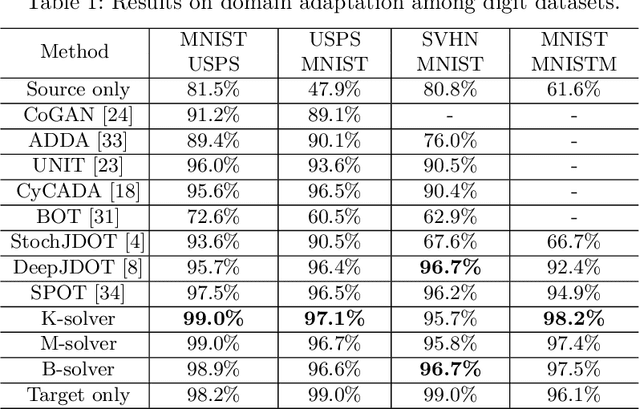
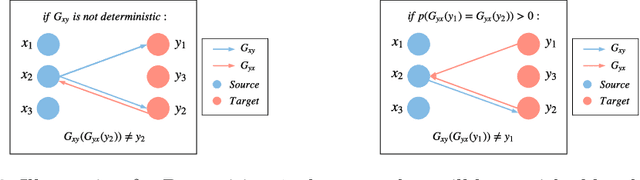
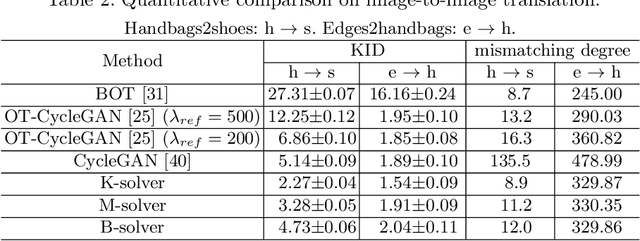
Recent advances in large-scale optimal transport have greatly extended its application scenarios in machine learning. However, existing methods either not explicitly learn the transport map or do not support general cost function. In this paper, we propose an end-to-end approach for large-scale optimal transport, which directly solves the transport map and is compatible with general cost function. It models the transport map via stochastic neural networks and enforces the constraint on the marginal distributions via adversarial training. The proposed framework can be further extended towards learning Monge map or optimal bijection via adopting cycle-consistency constraint(s). We verify the effectiveness of the proposed method and demonstrate its superior performance against existing methods with large-scale real-world applications, including domain adaptation, image-to-image translation, and color transfer.
Improving Unsupervised Domain Adaptation with Variational Information Bottleneck
Nov 21, 2019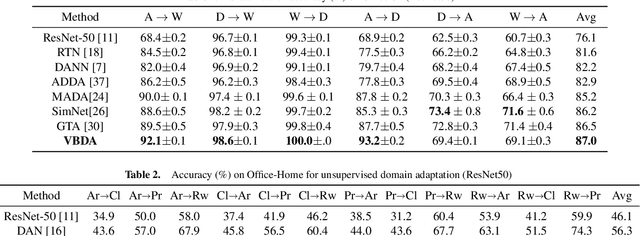
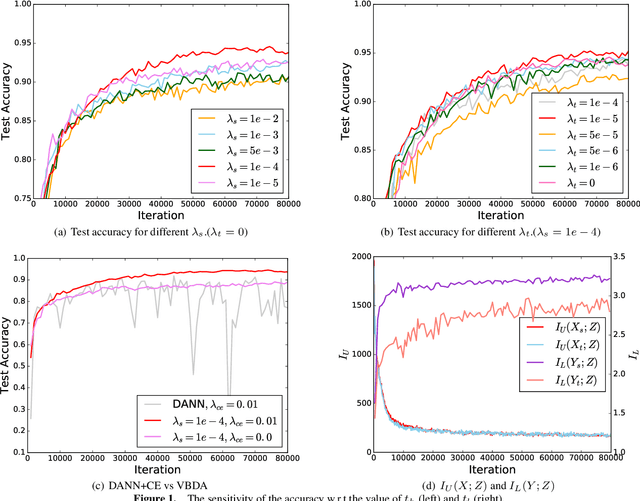
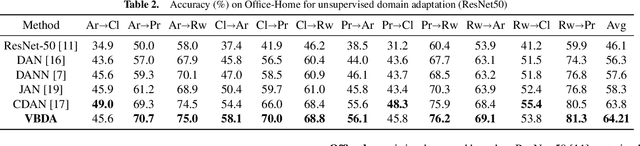
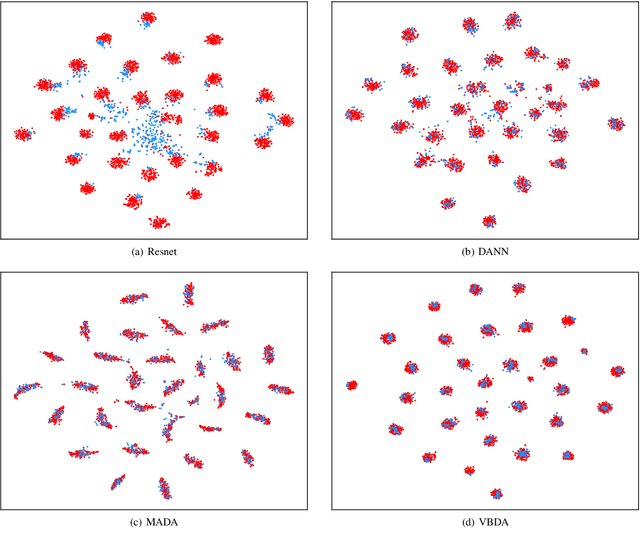
Domain adaptation aims to leverage the supervision signal of source domain to obtain an accurate model for target domain, where the labels are not available. To leverage and adapt the label information from source domain, most existing methods employ a feature extracting function and match the marginal distributions of source and target domains in a shared feature space. In this paper, from the perspective of information theory, we show that representation matching is actually an insufficient constraint on the feature space for obtaining a model with good generalization performance in target domain. We then propose variational bottleneck domain adaptation (VBDA), a new domain adaptation method which improves feature transferability by explicitly enforcing the feature extractor to ignore the task-irrelevant factors and focus on the information that is essential to the task of interest for both source and target domains. Extensive experimental results demonstrate that VBDA significantly outperforms state-of-the-art methods across three domain adaptation benchmark datasets.
Towards Efficient and Unbiased Implementation of Lipschitz Continuity in GANs
Apr 02, 2019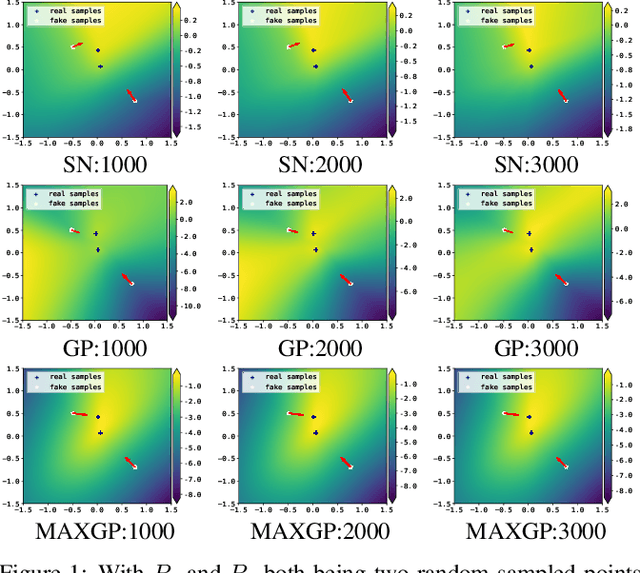

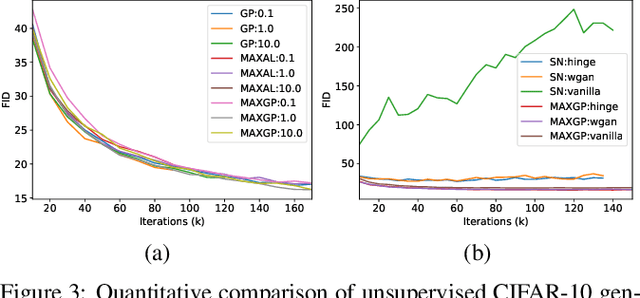
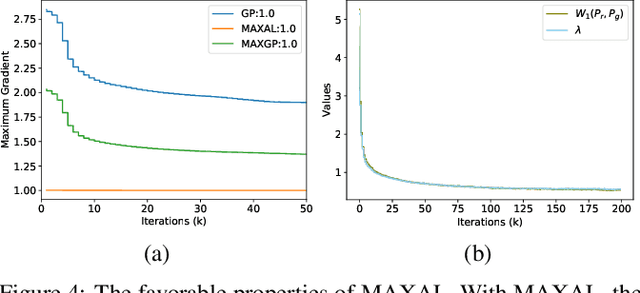
Lipschitz continuity recently becomes popular in generative adversarial networks (GANs). It was observed that the Lipschitz regularized discriminator leads to improved training stability and sample quality. The mainstream implementations of Lipschitz continuity include gradient penalty and spectral normalization. In this paper, we demonstrate that gradient penalty introduces undesired bias, while spectral normalization might be over restrictive. We accordingly propose a new method which is efficient and unbiased. Our experiments verify our analysis and show that the proposed method is able to achieve successful training in various situations where gradient penalty and spectral normalization fail.
Label-aware Double Transfer Learning for Cross-Specialty Medical Named Entity Recognition
Apr 28, 2018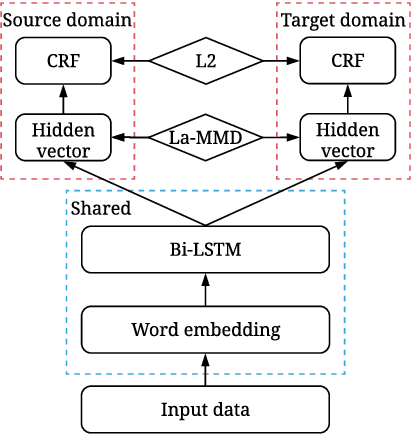
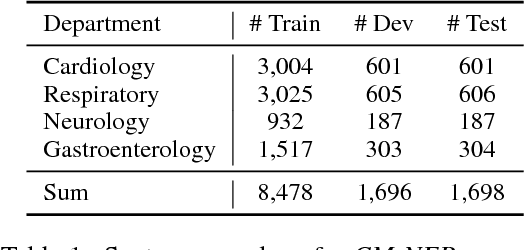
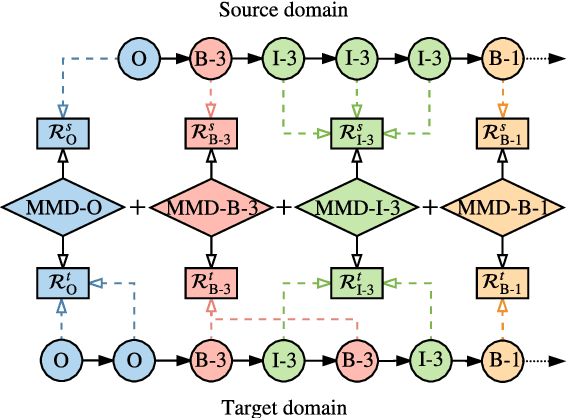
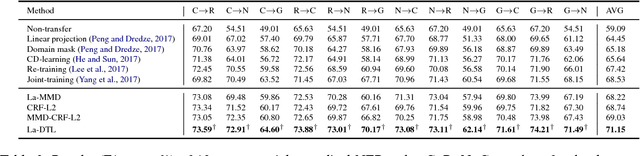
We study the problem of named entity recognition (NER) from electronic medical records, which is one of the most fundamental and critical problems for medical text mining. Medical records which are written by clinicians from different specialties usually contain quite different terminologies and writing styles. The difference of specialties and the cost of human annotation makes it particularly difficult to train a universal medical NER system. In this paper, we propose a label-aware double transfer learning framework (La-DTL) for cross-specialty NER, so that a medical NER system designed for one specialty could be conveniently applied to another one with minimal annotation efforts. The transferability is guaranteed by two components: (i) we propose label-aware MMD for feature representation transfer, and (ii) we perform parameter transfer with a theoretical upper bound which is also label aware. We conduct extensive experiments on 12 cross-specialty NER tasks. The experimental results demonstrate that La-DTL provides consistent accuracy improvement over strong baselines. Besides, the promising experimental results on non-medical NER scenarios indicate that La-DTL is potential to be seamlessly adapted to a wide range of NER tasks.
Wasserstein Distance Guided Representation Learning for Domain Adaptation
Mar 09, 2018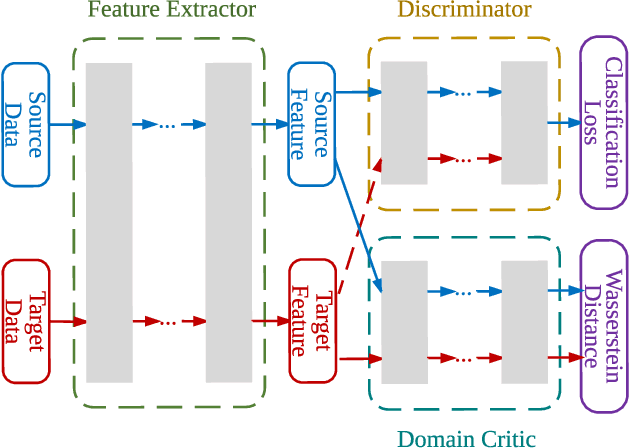
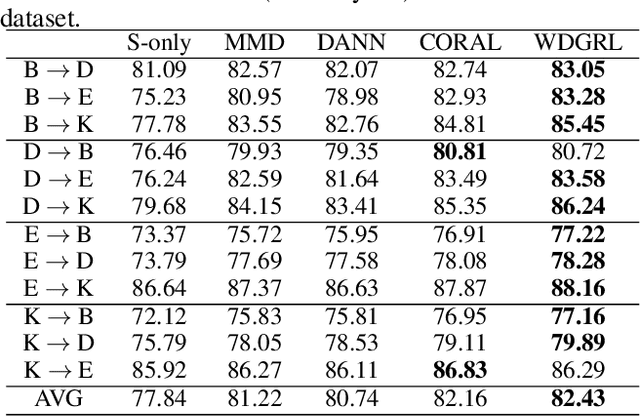
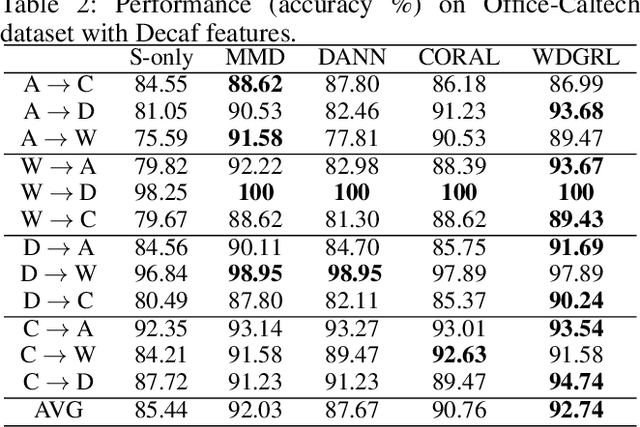
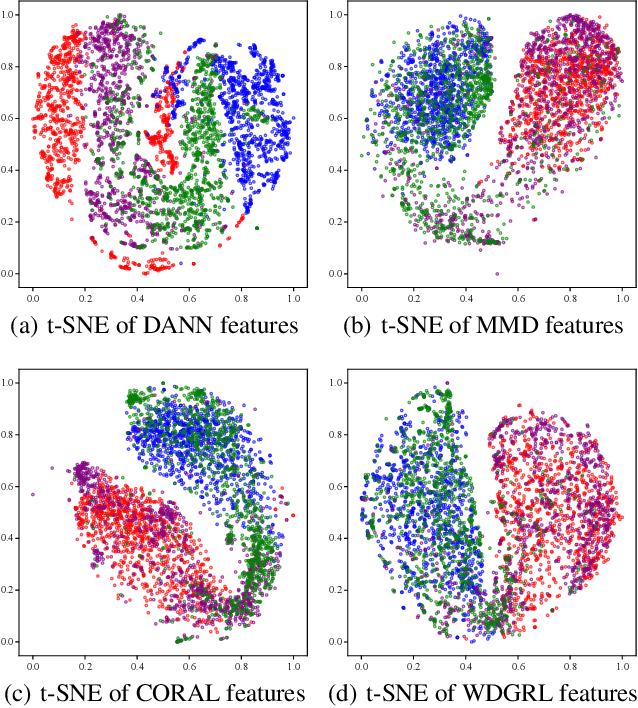
Domain adaptation aims at generalizing a high-performance learner on a target domain via utilizing the knowledge distilled from a source domain which has a different but related data distribution. One solution to domain adaptation is to learn domain invariant feature representations while the learned representations should also be discriminative in prediction. To learn such representations, domain adaptation frameworks usually include a domain invariant representation learning approach to measure and reduce the domain discrepancy, as well as a discriminator for classification. Inspired by Wasserstein GAN, in this paper we propose a novel approach to learn domain invariant feature representations, namely Wasserstein Distance Guided Representation Learning (WDGRL). WDGRL utilizes a neural network, denoted by the domain critic, to estimate empirical Wasserstein distance between the source and target samples and optimizes the feature extractor network to minimize the estimated Wasserstein distance in an adversarial manner. The theoretical advantages of Wasserstein distance for domain adaptation lie in its gradient property and promising generalization bound. Empirical studies on common sentiment and image classification adaptation datasets demonstrate that our proposed WDGRL outperforms the state-of-the-art domain invariant representation learning approaches.