 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor Box Optimization for Object Detection
Dec 02, 2018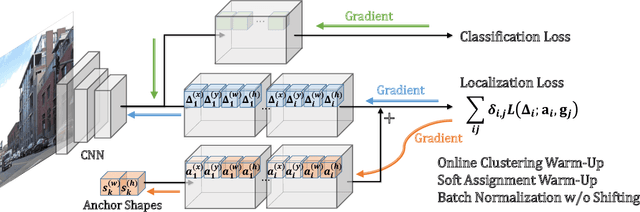
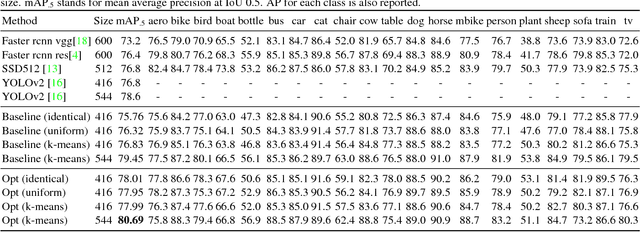
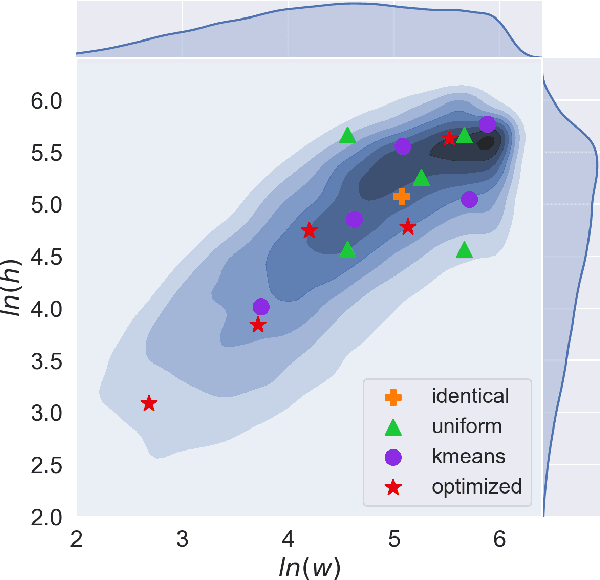
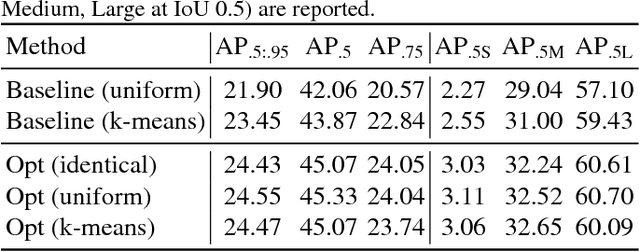
In this paper, we propose a general approach to optimize anchor boxes for object detection. Nowadays, anchor boxes are widely adopted in state-of-the-art detection frameworks. However, all these frameworks pre-define anchor box shapes in a heuristic way and fix the size during training. To improve the accuracy and reduce the effort to design the anchor boxes, we propose to dynamically learn the shapes, which allows the anchors to automatically adapt to the data distribution and the network learning capability. The learning approach can be easily implemented in the stochastic gradient descent way and be plugged into any anchor box-based detection framework. The extra training cost is almost negligible and it has no impact on the inference time cost. Exhaustive experiments also demonstrate that the proposed anchor optimization method consistently achieves significant improvement ($\ge 1\%$ mAP absolute gain) over the baseline method on several benchmark datasets including Pascal VOC 07+12, MS COCO and Brainwash. Meanwhile, the robustness is also verified towards different anchor box initialization methods, which greatly simplifies the problem of anchor box design.
The Importance of Norm Regularization in Linear Graph Embedding: Theoretical Analysis and Empirical Demonstration
Oct 12, 2018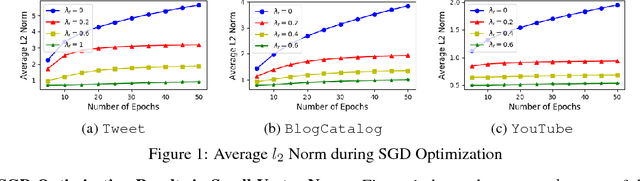
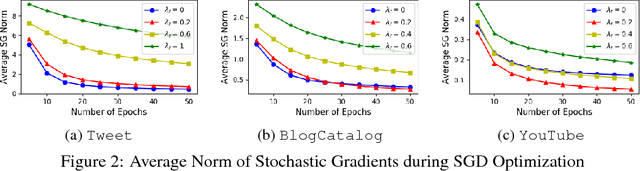
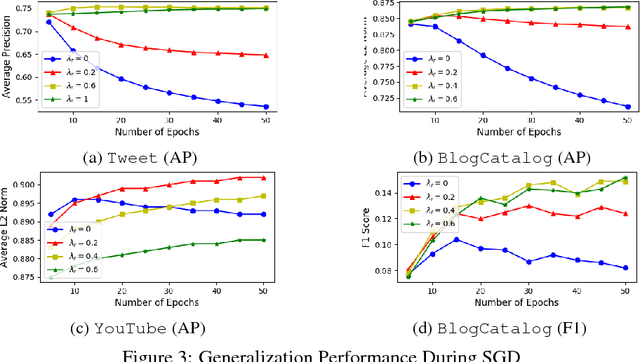
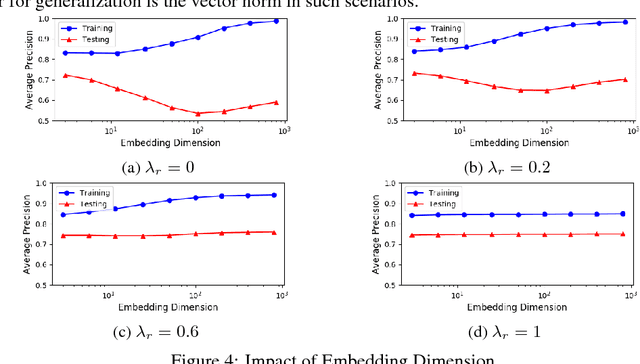
Learning distributed representations for nodes in graphs is a crucial primitive in network analysis with a wide spectrum of applications. Linear graph embedding methods learn such representations by optimizing the likelihood of both positive and negative edges while constraining the dimension of the embedding vectors. We argue that the generalization performance of these methods is not due to the dimensionality constraint as commonly believed, but rather the small norm of embedding vectors. Both theoretical and empirical evidence are provided to support this argument: (a) we prove that the generalization error of these methods can be bounded by limiting the norm of vectors, regardless of the embedding dimension; (b) we show that the generalization performance of linear graph embedding methods is correlated with the norm of embedding vectors, which is small due to the early stopping of SGD and the vanishing gradients. We performed extensive experiments to validate our analysis and showcased the importance of proper norm regularization in practice.
Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling
Sep 10, 2018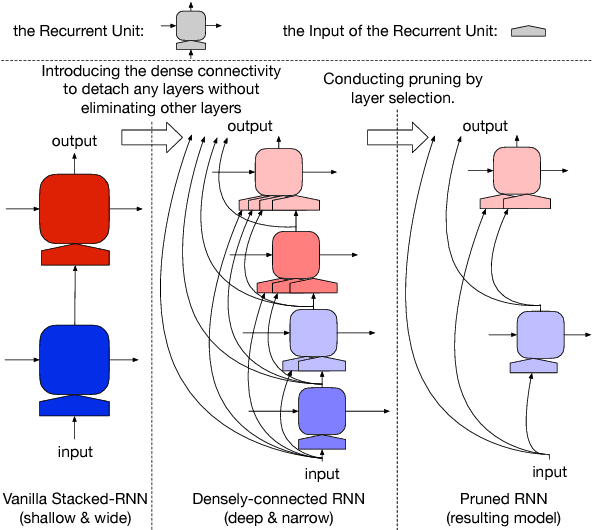
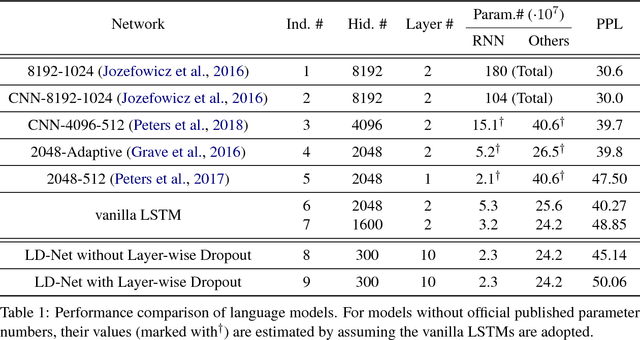
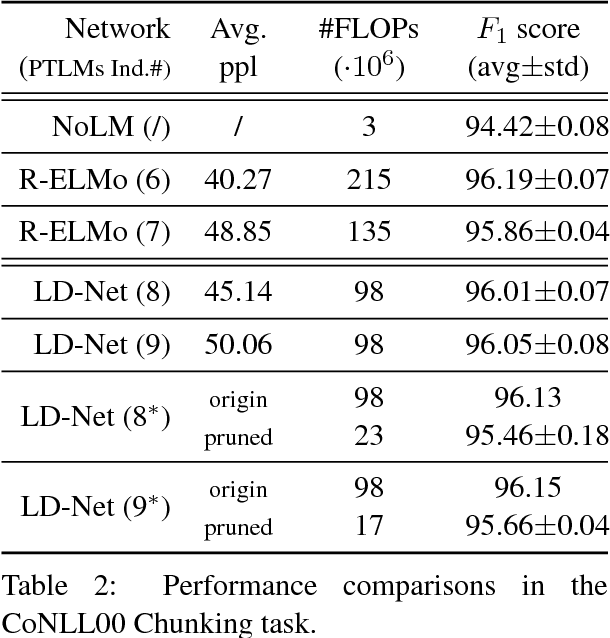
Many efforts have been made to facilitate natural language processing tasks with pre-trained language models (LMs), and brought significant improvements to various applications. To fully leverage the nearly unlimited corpora and capture linguistic information of multifarious levels, large-size LMs are required; but for a specific task, only parts of these information are useful. Such large-sized LMs, even in the inference stage, may cause heavy computation workloads, making them too time-consuming for large-scale applications. Here we propose to compress bulky LMs while preserving useful information with regard to a specific task. As different layers of the model keep different information, we develop a layer selection method for model pruning using sparsity-inducing regularization. By introducing the dense connectivity, we can detach any layer without affecting others, and stretch shallow and wide LMs to be deep and narrow. In model training, LMs are learned with layer-wise dropouts for better robustness. Experiments on two benchmark datasets demonstrate the effectiveness of our method.
emrQA: A Large Corpus for Question Answering on Electronic Medical Records
Sep 03, 2018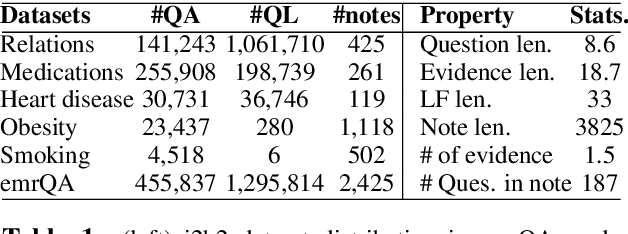
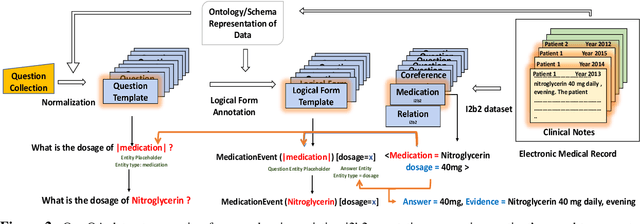
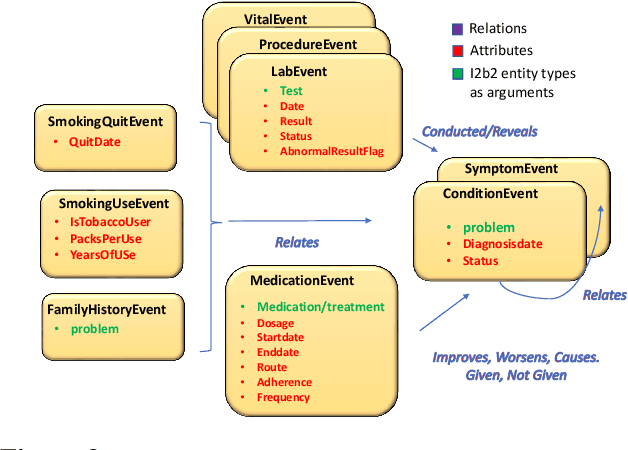

We propose a novel methodology to generate domain-specific large-scale question answering (QA) datasets by re-purposing existing annotations for other NLP tasks. We demonstrate an instance of this methodology in generating a large-scale QA dataset for electronic medical records by leveraging existing expert annotations on clinical notes for various NLP tasks from the community shared i2b2 datasets. The resulting corpus (emrQA) has 1 million question-logical form and 400,000+ question-answer evidence pairs. We characterize the dataset and explore its learning potential by training baseline models for question to logical form and question to answer mapping.
Off-Policy Evaluation and Learning from Logged Bandit Feedback: Error Reduction via Surrogate Policy
Aug 01, 2018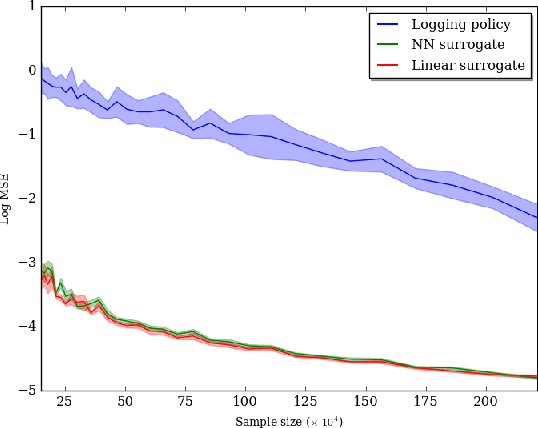
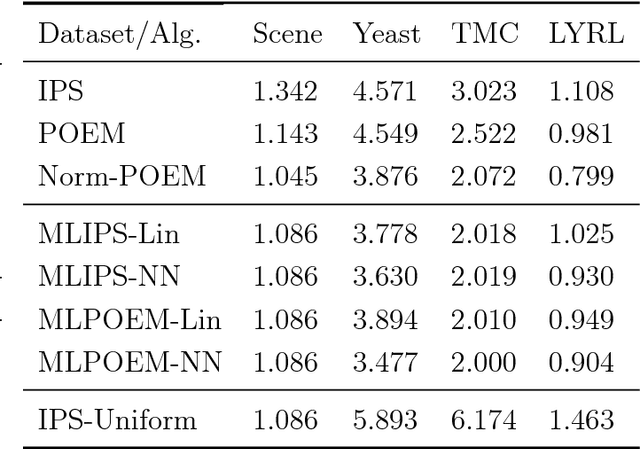
When learning from a batch of logged bandit feedback, the discrepancy between the policy to be learned and the off-policy training data imposes statistical and computational challenges. Unlike classical supervised learning and online learning settings, in batch contextual bandit learning, one only has access to a collection of logged feedback from the actions taken by a historical policy, and expect to learn a policy that takes good actions in possibly unseen contexts. Such a batch learning setting is ubiquitous in online and interactive systems, such as ad platforms and recommendation systems. Existing approaches based on inverse propensity weights, such as Inverse Propensity Scoring (IPS) and Policy Optimizer for Exponential Models (POEM), enjoy unbiasedness but often suffer from large mean squared error. In this work, we introduce a new approach named Maximum Likelihood Inverse Propensity Scoring (MLIPS) for batch learning from logged bandit feedback. Instead of using the given historical policy as the proposal in inverse propensity weights, we estimate a maximum likelihood surrogate policy based on the logged action-context pairs, and then use this surrogate policy as the proposal. We prove that MLIPS is asymptotically unbiased, and moreover, has a smaller nonasymptotic mean squared error than IPS. Such an error reduction phenomenon is somewhat surprising as the estimated surrogate policy is less accurate than the given historical policy. Results on multi-label classification problems and a large- scale ad placement dataset demonstrate the empirical effectiveness of MLIPS. Furthermore, the proposed surrogate policy technique is complementary to existing error reduction techniques, and when combined, is able to consistently boost the performance of several widely used approaches.
Large-Margin Classification in Hyperbolic Space
Jun 01, 2018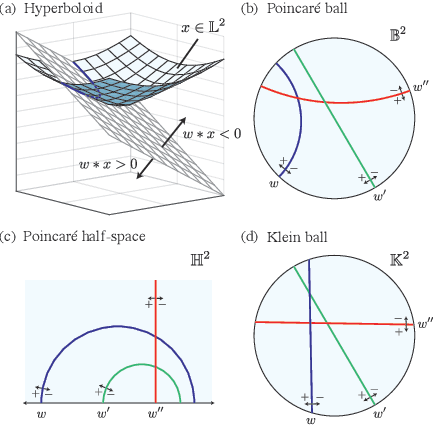
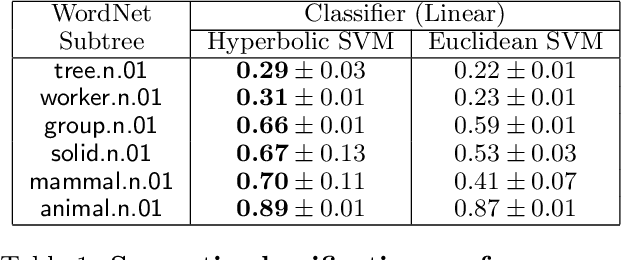
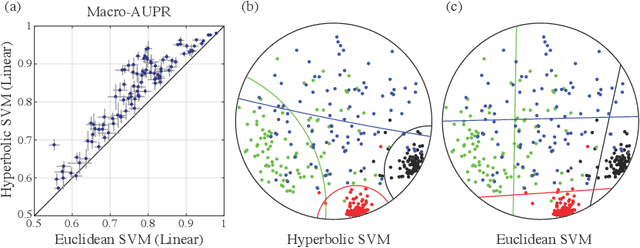
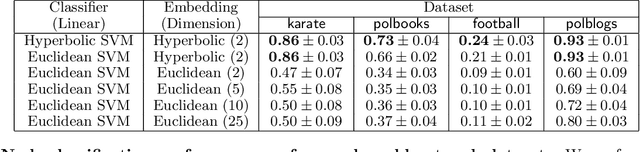
Representing data in hyperbolic space can effectively capture latent hierarchical relationships. With the goal of enabling accurate classification of points in hyperbolic space while respecting their hyperbolic geometry, we introduce hyperbolic SVM, a hyperbolic formulation of support vector machine classifiers, and elucidate through new theoretical work its connection to the Euclidean counterpart. We demonstrate the performance improvement of hyperbolic SVM for multi-class prediction tasks on real-world complex networks as well as simulated datasets. Our work allows analytic pipelines that take the inherent hyperbolic geometry of the data into account in an end-to-end fashion without resorting to ill-fitting tools developed for Euclidean space.
Learning Self-Imitating Diverse Policies
May 25, 2018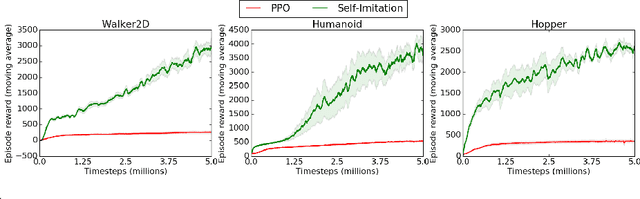
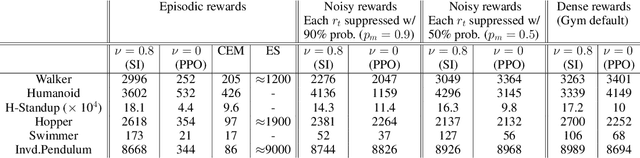

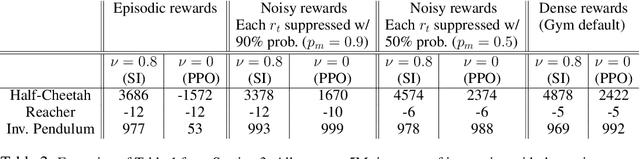
Deep reinforcement learning algorithms, including policy gradient methods and Q-learning, have been widely applied to a variety of decision-making problems. Their success has relied heavily on having very well designed dense reward signals, and therefore, they often perform badly on the sparse or episodic reward settings. Trajectory-based policy optimization methods, such as cross-entropy method and evolution strategies, do not take into consideration the temporal nature of the problem and often suffer from high sample complexity. Scaling up the efficiency of RL algorithms to real-world problems with sparse or episodic rewards is therefore a pressing need. In this work, we present a new perspective of policy optimization and introduce a self-imitation learning algorithm that exploits and explores well in the sparse and episodic reward settings. First, we view each policy as a state-action visitation distribution and formulate policy optimization as a divergence minimization problem. Then, we show that, with Jensen-Shannon divergence, this divergence minimization problem can be reduced into a policy-gradient algorithm with dense reward learned from experience replays. Experimental results indicate that our algorithm works comparable to existing algorithms in the dense reward setting, and significantly better in the sparse and episodic settings. To encourage exploration, we further apply the Stein variational policy gradient descent with the Jensen-Shannon kernel to learn multiple diverse policies and demonstrate its effectiveness on a number of challenging tasks.
Stochastic Variance Reduction for Policy Gradient Estimation
Mar 29, 2018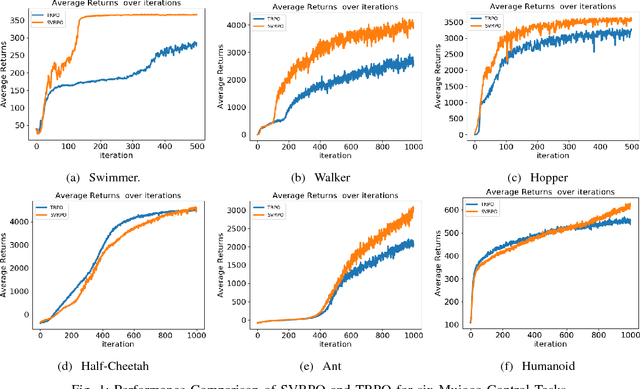
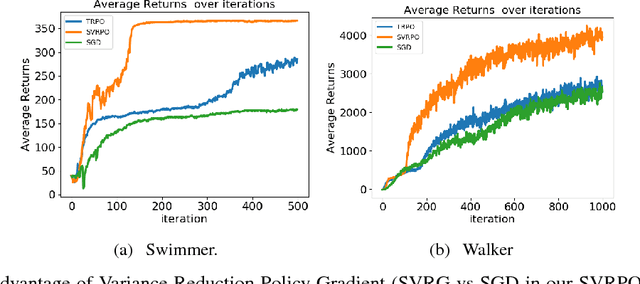
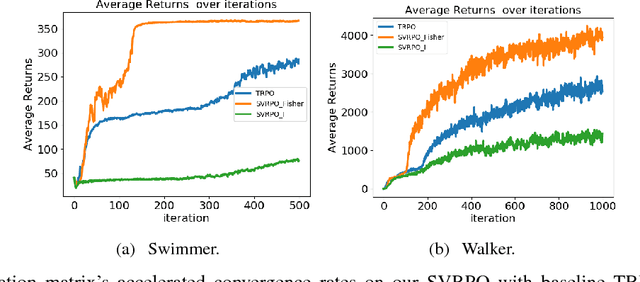

Recent advances in policy gradient methods and deep learning have demonstrated their applicability for complex reinforcement learning problems. However, the variance of the performance gradient estimates obtained from the simulation is often excessive, leading to poor sample efficiency. In this paper, we apply the stochastic variance reduced gradient descent (SVRG) to model-free policy gradient to significantly improve the sample-efficiency. The SVRG estimation is incorporated into a trust-region Newton conjugate gradient framework for the policy optimization. On several Mujoco tasks, our method achieves significantly better performance compared to the state-of-the-art model-free policy gradient methods in robotic continuous control such as trust region policy optimization (TRPO)
Learning to Explore with Meta-Policy Gradient
Mar 26, 2018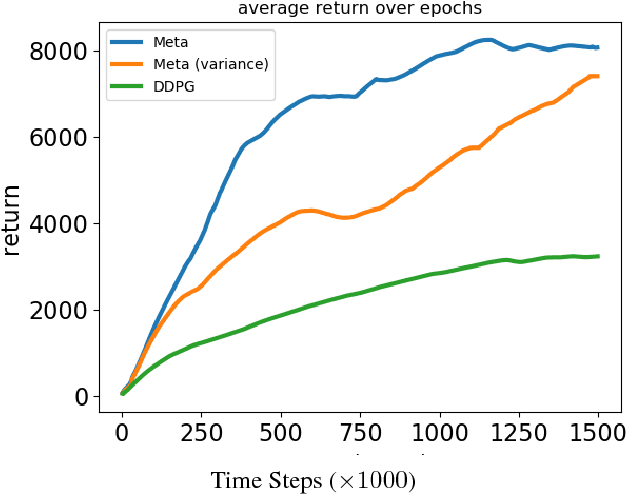

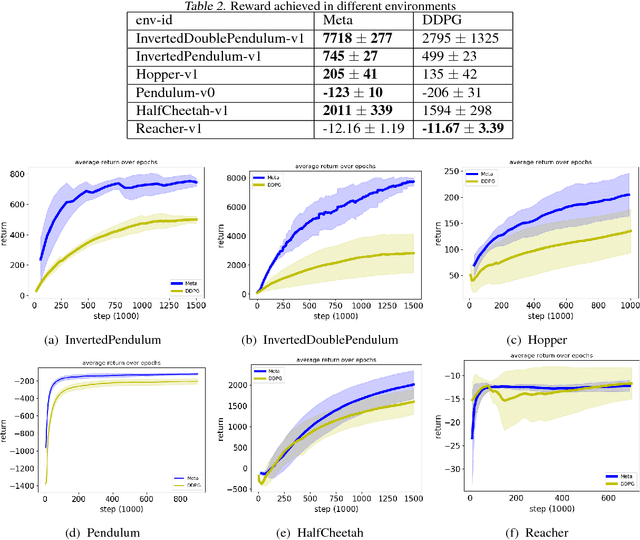
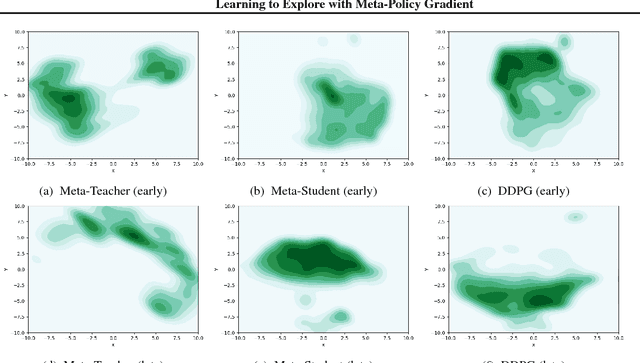
The performance of off-policy learning, including deep Q-learning and deep deterministic policy gradient (DDPG), critically depends on the choice of the exploration policy. Existing exploration methods are mostly based on adding noise to the on-going actor policy and can only explore \emph{local} regions close to what the actor policy dictates. In this work, we develop a simple meta-policy gradient algorithm that allows us to adaptively learn the exploration policy in DDPG. Our algorithm allows us to train flexible exploration behaviors that are independent of the actor policy, yielding a \emph{global exploration} that significantly speeds up the learning process. With an extensive study, we show that our method significantly improves the sample-efficiency of DDPG on a variety of reinforcement learning tasks.
Policy Optimization by Genetic Distillation
Mar 12, 2018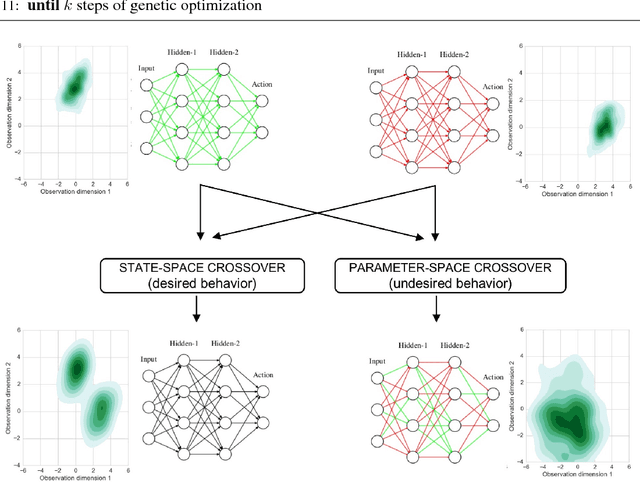
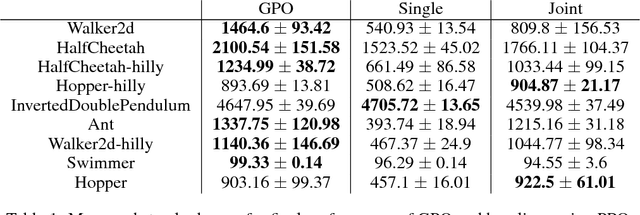
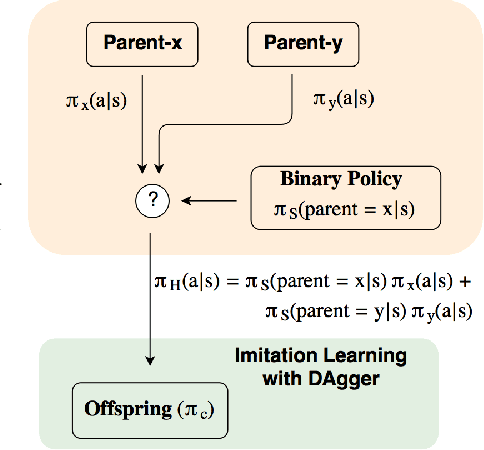
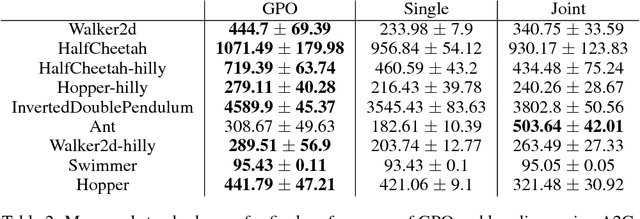
Genetic algorithms have been widely used in many practical optimization problems. Inspired by natural selection, operators, including mutation, crossover and selection, provide effective heuristics for search and black-box optimization. However, they have not been shown useful for deep reinforcement learning, possibly due to the catastrophic consequence of parameter crossovers of neural networks. Here, we present Genetic Policy Optimization (GPO), a new genetic algorithm for sample-efficient deep policy optimization. GPO uses imitation learning for policy crossover in the state space and applies policy gradient methods for mutation. Our experiments on MuJoCo tasks show that GPO as a genetic algorithm is able to provide superior performance over the state-of-the-art policy gradient methods and achieves comparable or higher sample efficiency.