 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Time is Here for Just-in-Time Systems: Challenges and Opportunities
May 22, 2026Core systems like key-value stores have historically taken years to build, and are designed to be general so as to amortize cost across deployments, paying a significant performance cost. We argue that LLM-based coding agents now make a different approach tractable: Just-in-Time Systems, in which the entire system is synthesized from scratch, specialized to the environment, workload, and required system properties. We present a JIT system synthesis pipeline, Jitskit, and explore its effectiveness in synthesizing key-value stores from spec cards that span different YCSB workloads, deployment constraints (e.g., compute resources), and system properties (e.g., consistency and durability). Jitskit iteratively refines a system implementation to match the specification against an evolving evaluation test suite. The resulting synthesized systems are performant, beating comparable state-of-the-art systems on 18 of 18 specs tried, by up to 4.6x over the best off-the-shelf baseline on the most favorable spec. Naively running Claude Code either reward-hacks or underperforms Jitskit by up to 5.4x. We discuss the challenges we overcame in building Jitskit and our key takeaways.
Inductive Deductive Synthesis: Enabling AI to Generate Formally Verified Systems
May 22, 2026AI agents increasingly excel at generating, testing, and refining code. However, they fall short on tasks requiring formal guarantees of full coverage that testing alone cannot provide. Distributed systems are a prime example: properties such as consistency between reads and writes must hold under every possible interleaving of events. Mechanized formal verification can guarantee such correctness, but typically demands months to years of expert effort. As evidence, even SOTA coding agents (Codex with GPT-5.4 and Claude Code with Opus 4.6) succeed on only 2/7 distributed key-value-store specifications. In this paper, we present the first effective approach to addressing this gap, Inductive Deductive Synthesis (IDS), which jointly and incrementally synthesizes implementation and proof, and learns from failed attempts to systematically try promising strategies. Built as an agentic LLM system, IDS achieves 7/7 in about 6.8 hours and $106 per spec on average, roughly 200x faster than expert effort and 17% cheaper than SOTA agents. IDS further incorporates performance feedback into the same loop, yielding implementations up to 3x faster than published verified systems.
PROMPTEVALS: A Dataset of Assertions and Guardrails for Custom Production Large Language Model Pipelines
Apr 20, 2025Large language models (LLMs) are increasingly deployed in specialized production data processing pipelines across diverse domains -- such as finance, marketing, and e-commerce. However, when running them in production across many inputs, they often fail to follow instructions or meet developer expectations. To improve reliability in these applications, creating assertions or guardrails for LLM outputs to run alongside the pipelines is essential. Yet, determining the right set of assertions that capture developer requirements for a task is challenging. In this paper, we introduce PROMPTEVALS, a dataset of 2087 LLM pipeline prompts with 12623 corresponding assertion criteria, sourced from developers using our open-source LLM pipeline tools. This dataset is 5x larger than previous collections. Using a hold-out test split of PROMPTEVALS as a benchmark, we evaluated closed- and open-source models in generating relevant assertions. Notably, our fine-tuned Mistral and Llama 3 models outperform GPT-4o by 20.93% on average, offering both reduced latency and improved performance. We believe our dataset can spur further research in LLM reliability, alignment, and prompt engineering.
RAG Without the Lag: Interactive Debugging for Retrieval-Augmented Generation Pipelines
Apr 18, 2025Retrieval-augmented generation (RAG) pipelines have become the de-facto approach for building AI assistants with access to external, domain-specific knowledge. Given a user query, RAG pipelines typically first retrieve (R) relevant information from external sources, before invoking a Large Language Model (LLM), augmented (A) with this information, to generate (G) responses. Modern RAG pipelines frequently chain multiple retrieval and generation components, in any order. However, developing effective RAG pipelines is challenging because retrieval and generation components are intertwined, making it hard to identify which component(s) cause errors in the eventual output. The parameters with the greatest impact on output quality often require hours of pre-processing after each change, creating prohibitively slow feedback cycles. To address these challenges, we present RAGGY, a developer tool that combines a Python library of composable RAG primitives with an interactive interface for real-time debugging. We contribute the design and implementation of RAGGY, insights into expert debugging patterns through a qualitative study with 12 engineers, and design implications for future RAG tools that better align with developers' natural workflows.
Why Do Multi-Agent LLM Systems Fail?
Mar 17, 2025Despite growing enthusiasm for Multi-Agent Systems (MAS), where multiple LLM agents collaborate to accomplish tasks, their performance gains across popular benchmarks remain minimal compared to single-agent frameworks. This gap highlights the need to analyze the challenges hindering MAS effectiveness. In this paper, we present the first comprehensive study of MAS challenges. We analyze five popular MAS frameworks across over 150 tasks, involving six expert human annotators. We identify 14 unique failure modes and propose a comprehensive taxonomy applicable to various MAS frameworks. This taxonomy emerges iteratively from agreements among three expert annotators per study, achieving a Cohen's Kappa score of 0.88. These fine-grained failure modes are organized into 3 categories, (i) specification and system design failures, (ii) inter-agent misalignment, and (iii) task verification and termination. To support scalable evaluation, we integrate MASFT with LLM-as-a-Judge. We also explore if identified failures could be easily prevented by proposing two interventions: improved specification of agent roles and enhanced orchestration strategies. Our findings reveal that identified failures require more complex solutions, highlighting a clear roadmap for future research. We open-source our dataset and LLM annotator.
LLM-Powered Proactive Data Systems
Feb 18, 2025With the power of LLMs, we now have the ability to query data that was previously impossible to query, including text, images, and video. However, despite this enormous potential, most present-day data systems that leverage LLMs are reactive, reflecting our community's desire to map LLMs to known abstractions. Most data systems treat LLMs as an opaque black box that operates on user inputs and data as is, optimizing them much like any other approximate, expensive UDFs, in conjunction with other relational operators. Such data systems do as they are told, but fail to understand and leverage what the LLM is being asked to do (i.e. the underlying operations, which may be error-prone), the data the LLM is operating on (e.g., long, complex documents), or what the user really needs. They don't take advantage of the characteristics of the operations and/or the data at hand, or ensure correctness of results when there are imprecisions and ambiguities. We argue that data systems instead need to be proactive: they need to be given more agency -- armed with the power of LLMs -- to understand and rework the user inputs and the data and to make decisions on how the operations and the data should be represented and processed. By allowing the data system to parse, rewrite, and decompose user inputs and data, or to interact with the user in ways that go beyond the standard single-shot query-result paradigm, the data system is able to address user needs more efficiently and effectively. These new capabilities lead to a rich design space where the data system takes more initiative: they are empowered to perform optimization based on the transformation operations, data characteristics, and user intent. We discuss various successful examples of how this framework has been and can be applied in real-world tasks, and present future directions for this ambitious research agenda.
NUDGE: Lightweight Non-Parametric Fine-Tuning of Embeddings for Retrieval
Sep 04, 2024$k$-Nearest Neighbor search on dense vector embeddings ($k$-NN retrieval) from pre-trained embedding models is the predominant retrieval method for text and images, as well as Retrieval-Augmented Generation (RAG) pipelines. In practice, application developers often fine-tune the embeddings to improve their accuracy on the dataset and query workload in hand. Existing approaches either fine-tune the pre-trained model itself or, more efficiently, but at the cost of accuracy, train adaptor models to transform the output of the pre-trained model. We present NUDGE, a family of novel non-parametric embedding fine-tuning approaches that are significantly more accurate and efficient than both sets of existing approaches. NUDGE directly modifies the embeddings of data records to maximize the accuracy of $k$-NN retrieval. We present a thorough theoretical and experimental study of NUDGE's non-parametric approach. We show that even though the underlying problem is NP-Hard, constrained variations can be solved efficiently. These constraints additionally ensure that the changes to the embeddings are modest, avoiding large distortions to the semantics learned during pre-training. In experiments across five pre-trained models and nine standard text and image retrieval datasets, NUDGE runs in minutes and often improves NDCG@10 by more than 10% over existing fine-tuning methods. On average, NUDGE provides 3.3x and 4.3x higher increase in accuracy and runs 200x and 3x faster, respectively, over fine-tuning the pre-trained model and training adaptors.
Production Machine Learning Pipelines: Empirical Analysis and Optimization Opportunities
Mar 30, 2021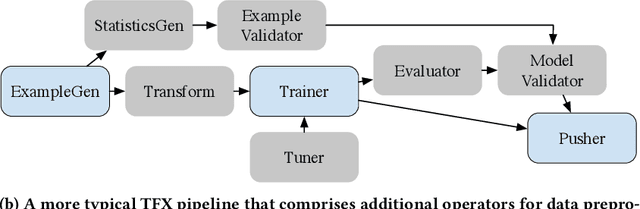
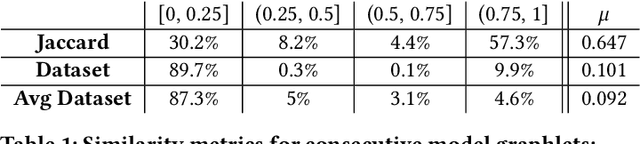
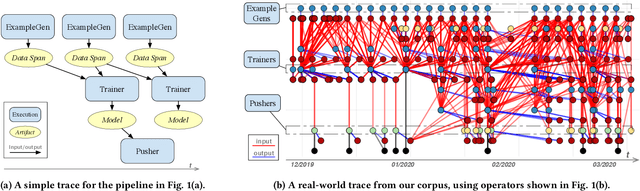
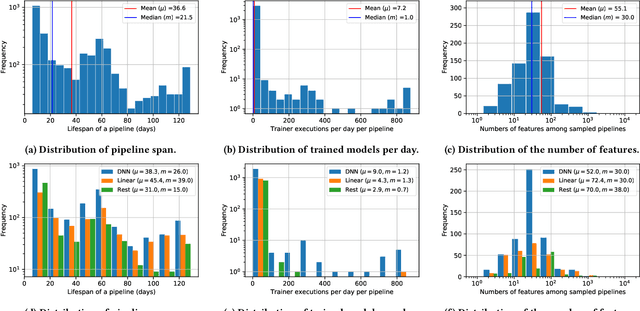
Machine learning (ML) is now commonplace, powering data-driven applications in various organizations. Unlike the traditional perception of ML in research, ML production pipelines are complex, with many interlocking analytical components beyond training, whose sub-parts are often run multiple times on overlapping subsets of data. However, there is a lack of quantitative evidence regarding the lifespan, architecture, frequency, and complexity of these pipelines to understand how data management research can be used to make them more efficient, effective, robust, and reproducible. To that end, we analyze the provenance graphs of 3000 production ML pipelines at Google, comprising over 450,000 models trained, spanning a period of over four months, in an effort to understand the complexity and challenges underlying production ML. Our analysis reveals the characteristics, components, and topologies of typical industry-strength ML pipelines at various granularities. Along the way, we introduce a specialized data model for representing and reasoning about repeatedly run components in these ML pipelines, which we call model graphlets. We identify several rich opportunities for optimization, leveraging traditional data management ideas. We show how targeting even one of these opportunities, i.e., identifying and pruning wasted computation that does not translate to model deployment, can reduce wasted computation cost by 50% without compromising the model deployment cadence.
Whither AutoML? Understanding the Role of Automation in Machine Learning Workflows
Jan 13, 2021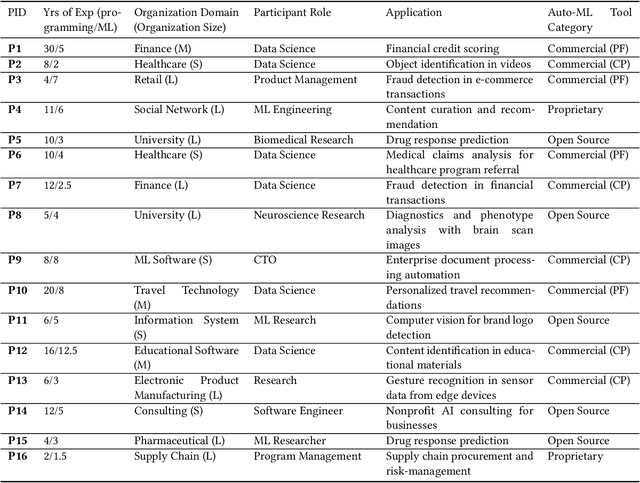
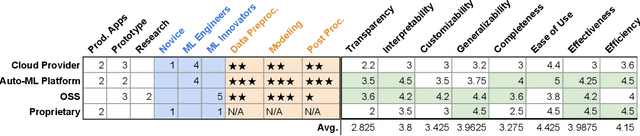
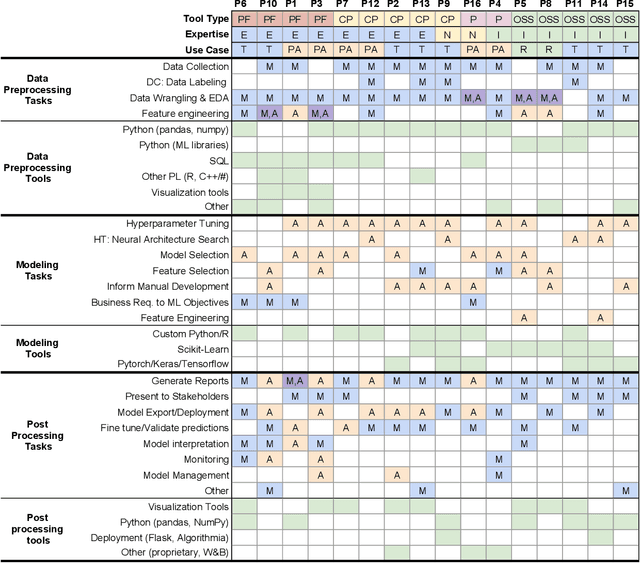
Efforts to make machine learning more widely accessible have led to a rapid increase in Auto-ML tools that aim to automate the process of training and deploying machine learning. To understand how Auto-ML tools are used in practice today, we performed a qualitative study with participants ranging from novice hobbyists to industry researchers who use Auto-ML tools. We present insights into the benefits and deficiencies of existing tools, as well as the respective roles of the human and automation in ML workflows. Finally, we discuss design implications for the future of Auto-ML tool development. We argue that instead of full automation being the ultimate goal of Auto-ML, designers of these tools should focus on supporting a partnership between the user and the Auto-ML tool. This means that a range of Auto-ML tools will need to be developed to support varying user goals such as simplicity, reproducibility, and reliability.
Demystifying a Dark Art: Understanding Real-World Machine Learning Model Development
May 04, 2020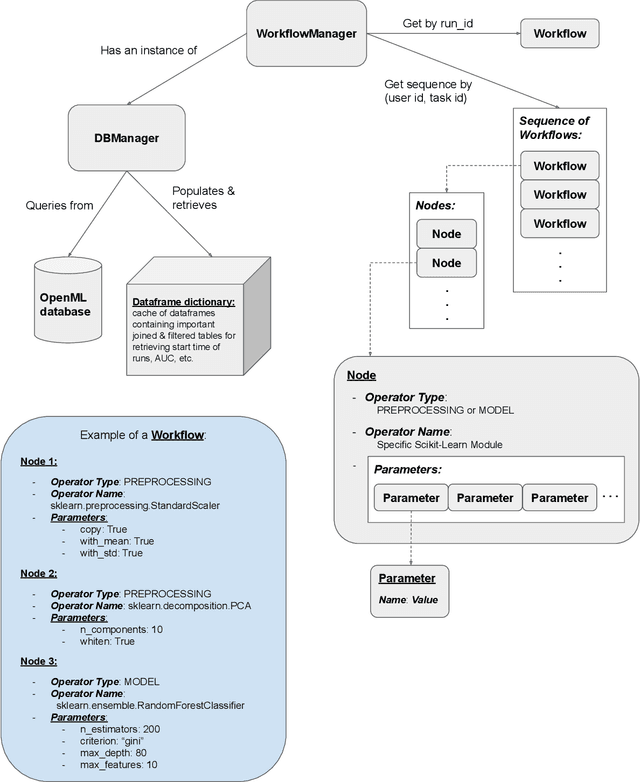
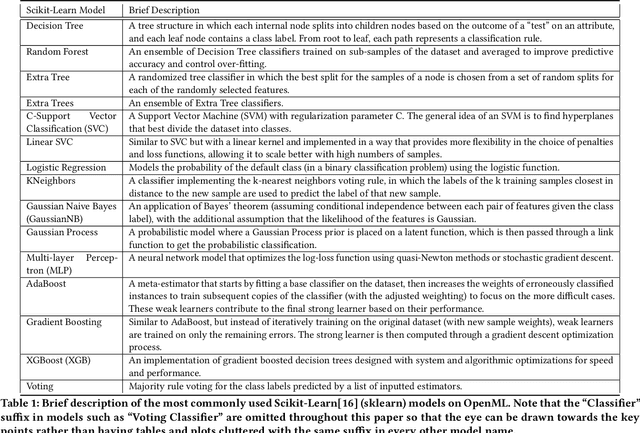
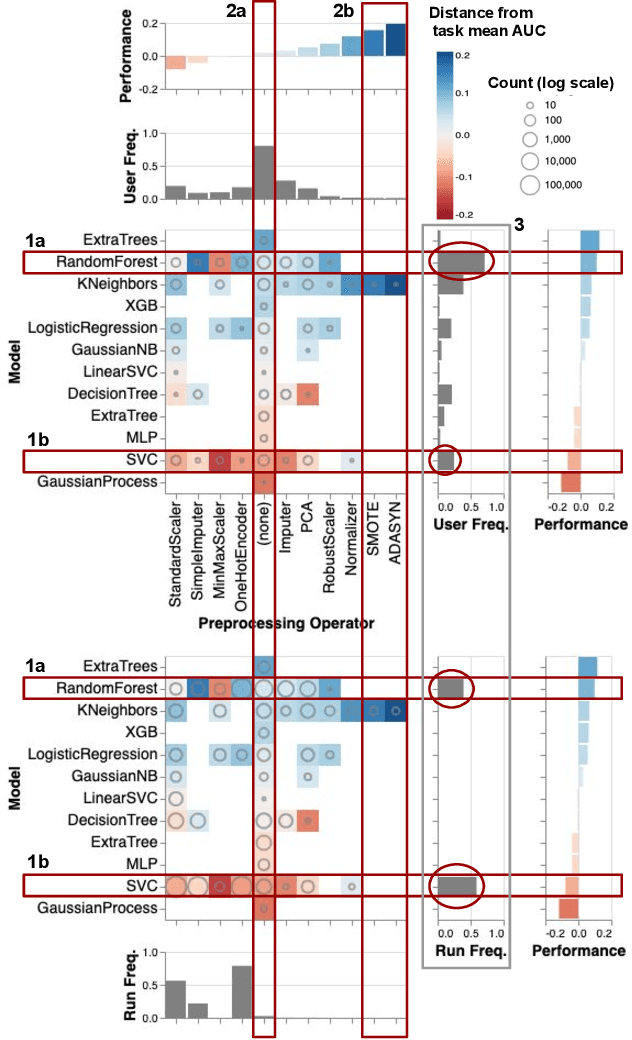
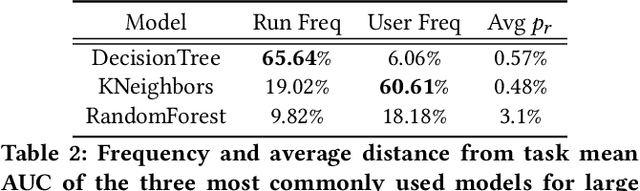
It is well-known that the process of developing machine learning (ML) workflows is a dark-art; even experts struggle to find an optimal workflow leading to a high accuracy model. Users currently rely on empirical trial-and-error to obtain their own set of battle-tested guidelines to inform their modeling decisions. In this study, we aim to demystify this dark art by understanding how people iterate on ML workflows in practice. We analyze over 475k user-generated workflows on OpenML, an open-source platform for tracking and sharing ML workflows. We find that users often adopt a manual, automated, or mixed approach when iterating on their workflows. We observe that manual approaches result in fewer wasted iterations compared to automated approaches. Yet, automated approaches often involve more preprocessing and hyperparameter options explored, resulting in higher performance overall--suggesting potential benefits for a human-in-the-loop ML system that appropriately recommends a clever combination of the two strategies.