 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Attacks on Deep Reinforcement Learning
Jul 24, 2019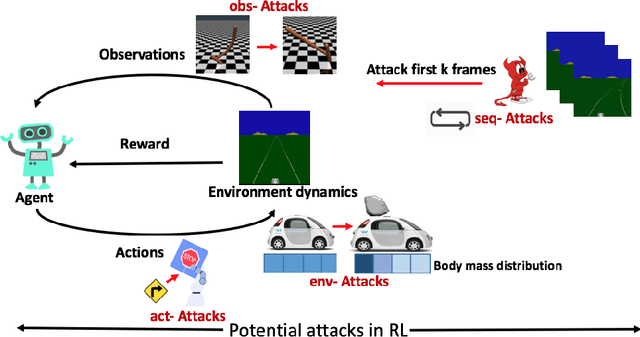
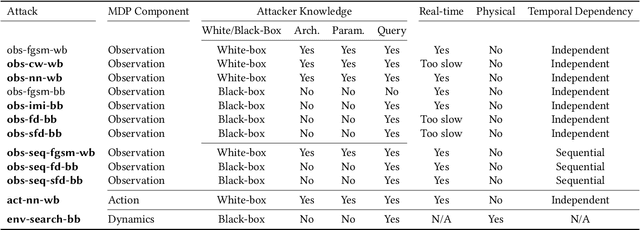
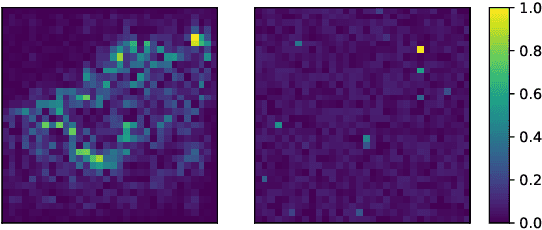

Deep reinforcement learning (DRL) has achieved great success in various applications. However, recent studies show that machine learning models are vulnerable to adversarial attacks. DRL models have been attacked by adding perturbations to observations. While such observation based attack is only one aspect of potential attacks on DRL, other forms of attacks which are more practical require further analysis, such as manipulating environment dynamics. Therefore, we propose to understand the vulnerabilities of DRL from various perspectives and provide a thorough taxonomy of potential attacks. We conduct the first set of experiments on the unexplored parts within the taxonomy. In addition to current observation based attacks against DRL, we propose the first targeted attacks based on action space and environment dynamics. We also introduce the online sequential attacks based on temporal consistency information among frames. To better estimate gradient in black-box setting, we propose a sampling strategy and theoretically prove its efficiency and estimation error bound. We conduct extensive experiments to compare the effectiveness of different attacks with several baselines in various environments, including game playing, robotics control, and autonomous driving.
Learning Belief Representations for Imitation Learning in POMDPs
Jun 22, 2019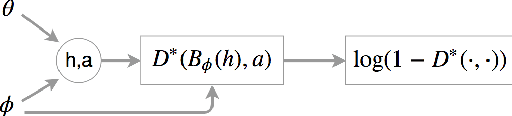
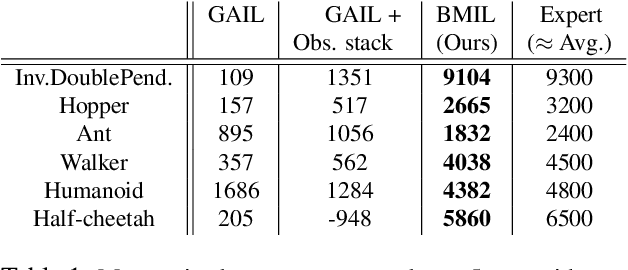
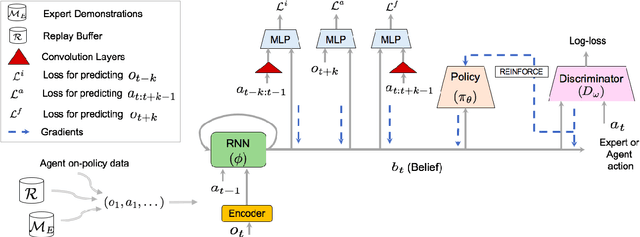
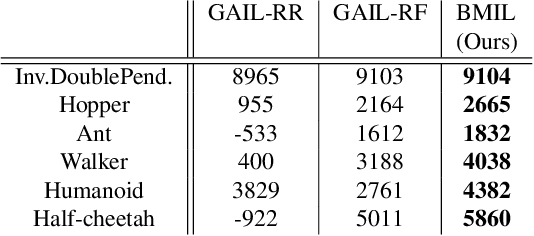
We consider the problem of imitation learning from expert demonstrations in partially observable Markov decision processes (POMDPs). Belief representations, which characterize the distribution over the latent states in a POMDP, have been modeled using recurrent neural networks and probabilistic latent variable models, and shown to be effective for reinforcement learning in POMDPs. In this work, we investigate the belief representation learning problem for generative adversarial imitation learning in POMDPs. Instead of training the belief module and the policy separately as suggested in prior work, we learn the belief module jointly with the policy, using a task-aware imitation loss to ensure that the representation is more aligned with the policy's objective. To improve robustness of representation, we introduce several informative belief regularization techniques, including multi-step prediction of dynamics and action-sequences. Evaluated on various partially observable continuous-control locomotion tasks, our belief-module imitation learning approach (BMIL) substantially outperforms several baselines, including the original GAIL algorithm and the task-agnostic belief learning algorithm. Extensive ablation analysis indicates the effectiveness of task-aware belief learning and belief regularization.
A gradual, semi-discrete approach to generative network training via explicit Wasserstein minimization
Jun 11, 2019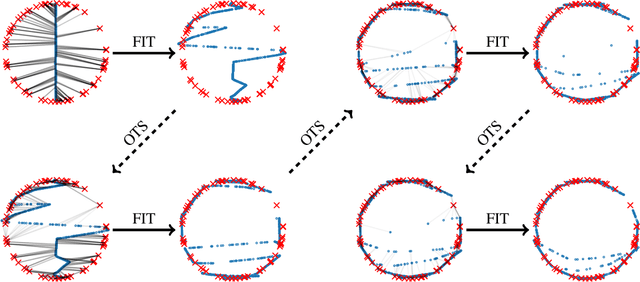
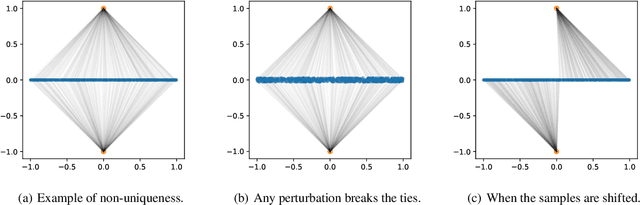
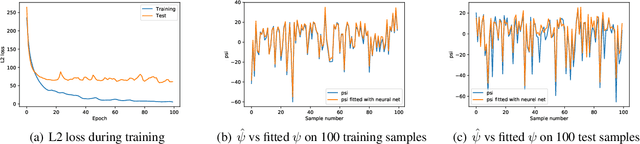
This paper provides a simple procedure to fit generative networks to target distributions, with the goal of a small Wasserstein distance (or other optimal transport costs). The approach is based on two principles: (a) if the source randomness of the network is a continuous distribution (the "semi-discrete" setting), then the Wasserstein distance is realized by a deterministic optimal transport mapping; (b) given an optimal transport mapping between a generator network and a target distribution, the Wasserstein distance may be decreased via a regression between the generated data and the mapped target points. The procedure here therefore alternates these two steps, forming an optimal transport and regressing against it, gradually adjusting the generator network towards the target distribution. Mathematically, this approach is shown to minimize the Wasserstein distance to both the empirical target distribution, and also its underlying population counterpart. Empirically, good performance is demonstrated on the training and testing sets of the MNIST and Thin-8 data. The paper closes with a discussion of the unsuitability of the Wasserstein distance for certain tasks, as has been identified in prior work [Arora et al., 2017, Huang et al., 2017].
Exploration via Hindsight Goal Generation
Jun 10, 2019
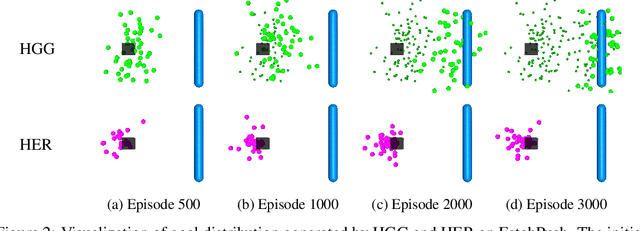
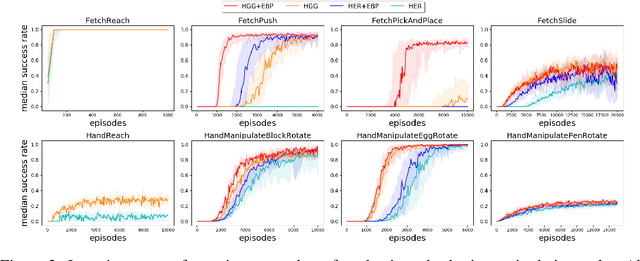
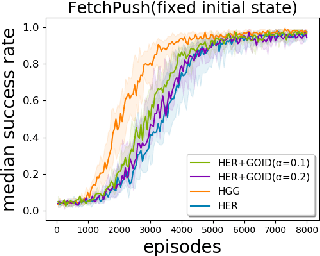
Goal-oriented reinforcement learning has recently been a practical framework for robotic manipulation tasks, in which an agent is required to reach a certain goal defined by a function on the state space. However, the sparsity of such reward definition makes traditional reinforcement learning algorithms very inefficient. Hindsight Experience Replay (HER), a recent advance, has greatly improved sample efficiency and practical applicability for such problems. It exploits previous replays by constructing imaginary goals in a simple heuristic way, acting like an implicit curriculum to alleviate the challenge of sparse reward signal. In this paper, we introduce Hindsight Goal Generation (HGG), a novel algorithmic framework that generates valuable hindsight goals which are easy for an agent to achieve in the short term and are also potential for guiding the agent to reach the actual goal in the long term. We have extensively evaluated our goal generation algorithm on a number of robotic manipulation tasks and demonstrated substantially improvement over the original HER in terms of sample efficiency.
Sequence Modeling of Temporal Credit Assignment for Episodic Reinforcement Learning
May 31, 2019

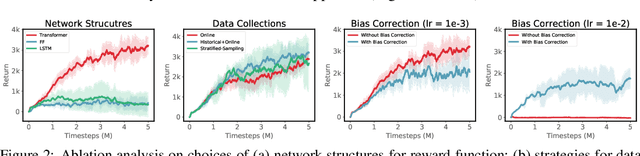
Recent advances in deep reinforcement learning algorithms have shown great potential and success for solving many challenging real-world problems, including Go game and robotic applications. Usually, these algorithms need a carefully designed reward function to guide training in each time step. However, in real world, it is non-trivial to design such a reward function, and the only signal available is usually obtained at the end of a trajectory, also known as the episodic reward or return. In this work, we introduce a new algorithm for temporal credit assignment, which learns to decompose the episodic return back to each time-step in the trajectory using deep neural networks. With this learned reward signal, the learning efficiency can be substantially improved for episodic reinforcement learning. In particular, we find that expressive language models such as the Transformer can be adopted for learning the importance and the dependency of states in the trajectory, therefore providing high-quality and interpretable learned reward signals. We have performed extensive experiments on a set of MuJoCo continuous locomotive control tasks with only episodic returns and demonstrated the effectiveness of our algorithm.
Thresholding Bandit with Optimal Aggregate Regret
May 27, 2019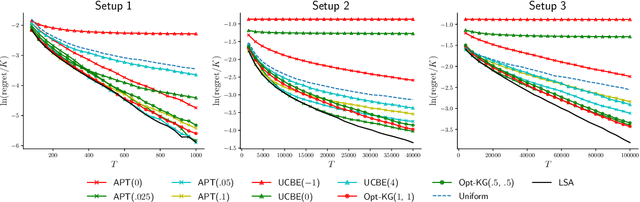
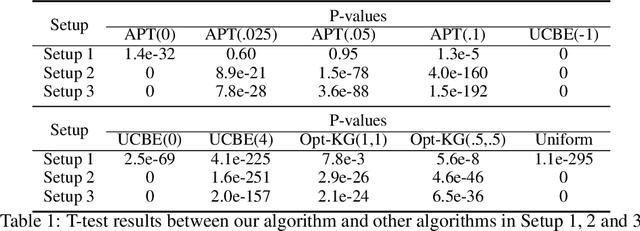
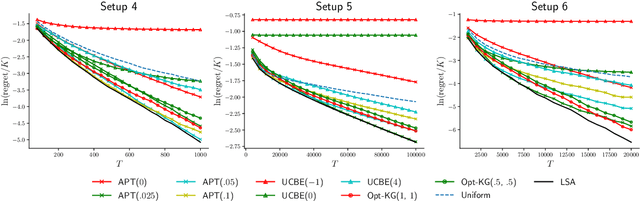
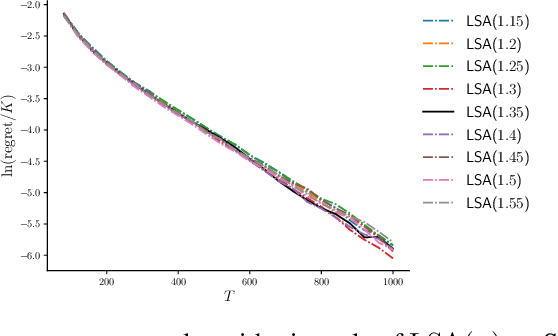
We consider the thresholding bandit problem, whose goal is to find arms of mean rewards above a given threshold $\theta$, with a fixed budget of $T$ trials. We introduce LSA, a new, simple and anytime algorithm that aims to minimize the aggregate regret (or the expected number of mis-classified arms). We prove that our algorithm is instance-wise asymptotically optimal. We also provide comprehensive empirical results to demonstrate the algorithm's superior performance over existing algorithms under a variety of different scenarios.
Stochastic Variance Reduction for Deep Q-learning
May 20, 2019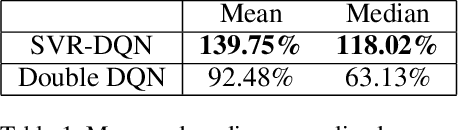
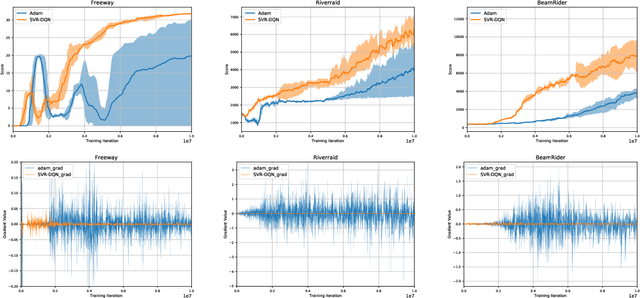
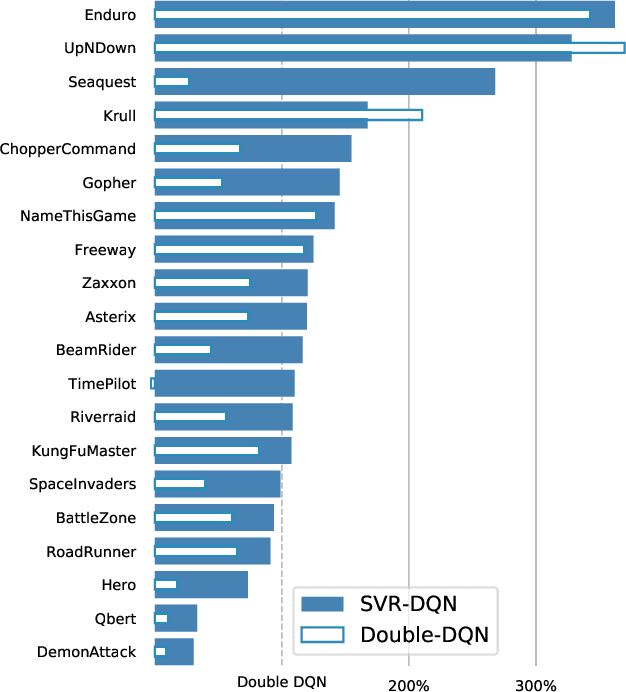
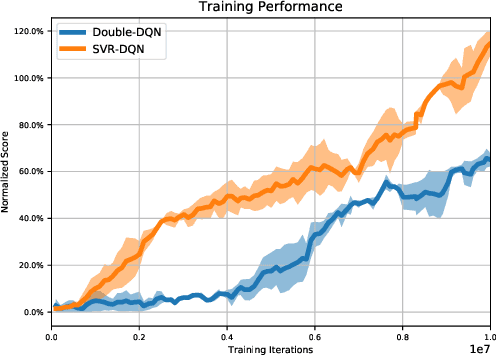
Recent advances in deep reinforcement learning have achieved human-level performance on a variety of real-world applications. However, the current algorithms still suffer from poor gradient estimation with excessive variance, resulting in unstable training and poor sample efficiency. In our paper, we proposed an innovative optimization strategy by utilizing stochastic variance reduced gradient (SVRG) techniques. With extensive experiments on Atari domain, our method outperforms the deep q-learning baselines on 18 out of 20 games.
Knowledge Flow: Improve Upon Your Teachers
Apr 11, 2019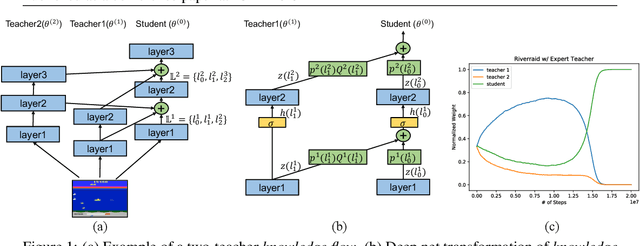
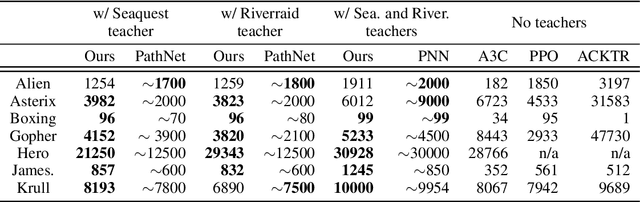
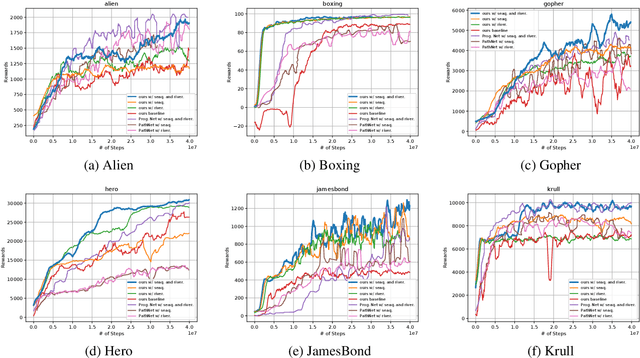
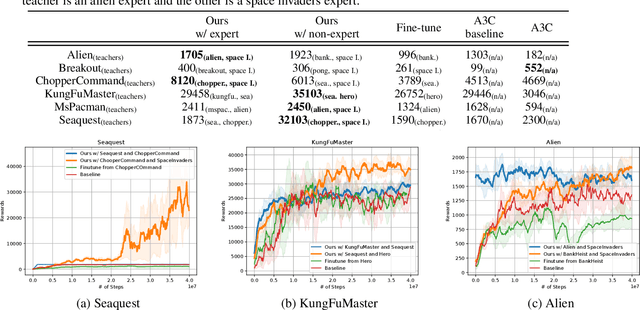
A zoo of deep nets is available these days for almost any given task, and it is increasingly unclear which net to start with when addressing a new task, or which net to use as an initialization for fine-tuning a new model. To address this issue, in this paper, we develop knowledge flow which moves 'knowledge' from multiple deep nets, referred to as teachers, to a new deep net model, called the student. The structure of the teachers and the student can differ arbitrarily and they can be trained on entirely different tasks with different output spaces too. Upon training with knowledge flow the student is independent of the teachers. We demonstrate our approach on a variety of supervised and reinforcement learning tasks, outperforming fine-tuning and other 'knowledge exchange' methods.
Understanding the Importance of Single Directions via Representative Substitution
Dec 06, 2018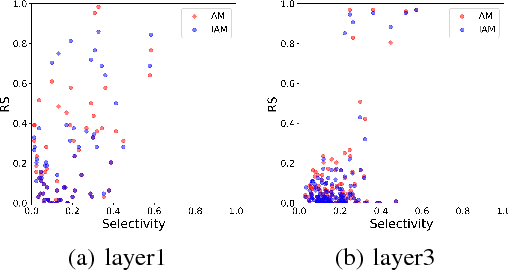
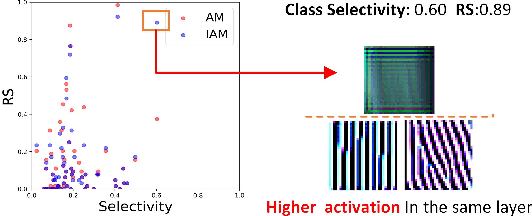
Understanding the internal representations of deep neural networks (DNNs) is crucal to explain their behavior. The interpretation of individual units, which are neurons in MLPs or convolution kernels in convolutional networks, has been paid much attention given their fundamental role. However, recent research (Morcos et al. 2018) presented a counterintuitive phenomenon, which suggests that an individual unit with high class selectivity, called interpretable units, has poor contributions to generalization of DNNs. In this work, we provide a new perspective to understand this counterintuitive phenomenon, which makes sense when we introduce Representative Substitution (RS). Instead of individually selective units with classes, the RS refers to the independence of a unit's representations in the same layer without any annotation. Our experiments demonstrate that interpretable units have high RS which are not critical to network's generalization. The RS provides new insights into the interpretation of DNNs and suggests that we need to focus on the independence and relationship of the representations.
* 4 pages, 6 figures
Overcoming Catastrophic Forgetting by Soft Parameter Pruning
Dec 04, 2018

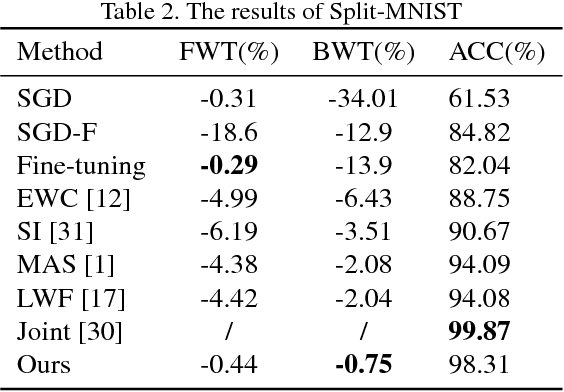
Catastrophic forgetting is a challenge issue in continual learning when a deep neural network forgets the knowledge acquired from the former task after learning on subsequent tasks. However, existing methods try to find the joint distribution of parameters shared with all tasks. This idea can be questionable because this joint distribution may not present when the number of tasks increase. On the other hand, It also leads to "long-term" memory issue when the network capacity is limited since adding tasks will "eat" the network capacity. In this paper, we proposed a Soft Parameters Pruning (SPP) strategy to reach the trade-off between short-term and long-term profit of a learning model by freeing those parameters less contributing to remember former task domain knowledge to learn future tasks, and preserving memories about previous tasks via those parameters effectively encoding knowledge about tasks at the same time. The SPP also measures the importance of parameters by information entropy in a label free manner. The experiments on several tasks shows SPP model achieved the best performance compared with others state-of-the-art methods. Experiment results also indicate that our method is less sensitive to hyper-parameter and better generalization. Our research suggests that a softer strategy, i.e. approximate optimize or sub-optimal solution, will benefit alleviating the dilemma of memory. The source codes are available at https://github.com/lehaifeng/Learning_by_memory.