 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsking for Knowledge: Training RL Agents to Query External Knowledge Using Language
May 12, 2022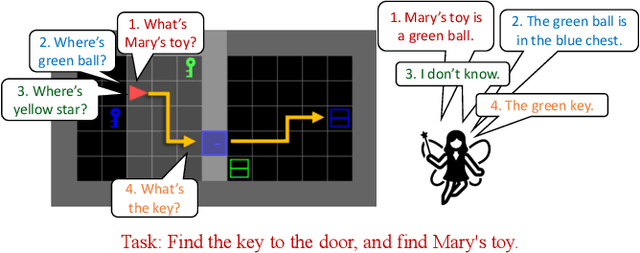
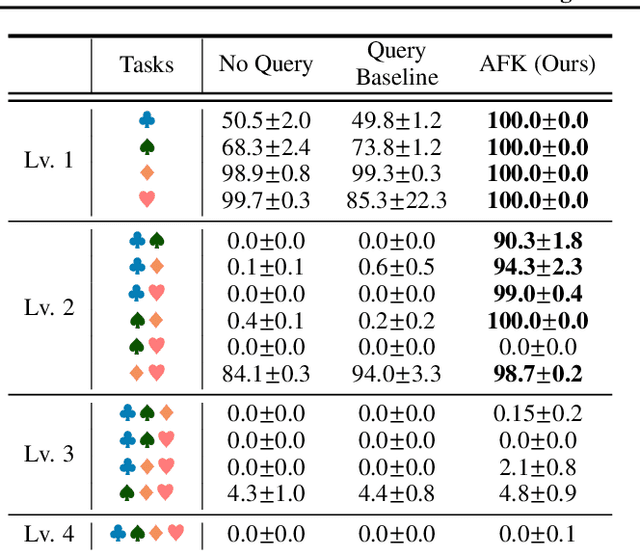


To solve difficult tasks, humans ask questions to acquire knowledge from external sources. In contrast, classical reinforcement learning agents lack such an ability and often resort to exploratory behavior. This is exacerbated as few present-day environments support querying for knowledge. In order to study how agents can be taught to query external knowledge via language, we first introduce two new environments: the grid-world-based Q-BabyAI and the text-based Q-TextWorld. In addition to physical interactions, an agent can query an external knowledge source specialized for these environments to gather information. Second, we propose the "Asking for Knowledge" (AFK) agent, which learns to generate language commands to query for meaningful knowledge that helps solve the tasks. AFK leverages a non-parametric memory, a pointer mechanism and an episodic exploration bonus to tackle (1) a large query language space, (2) irrelevant information, (3) delayed reward for making meaningful queries. Extensive experiments demonstrate that the AFK agent outperforms recent baselines on the challenging Q-BabyAI and Q-TextWorld environments.
Semantic Tracklets: An Object-Centric Representation for Visual Multi-Agent Reinforcement Learning
Aug 06, 2021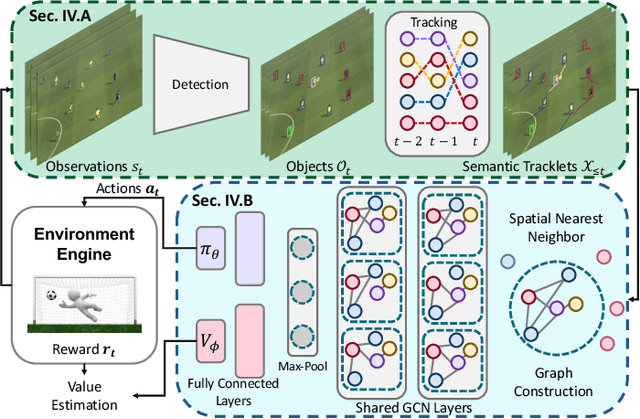
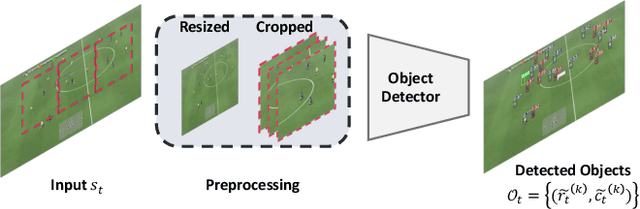


Solving complex real-world tasks, e.g., autonomous fleet control, often involves a coordinated team of multiple agents which learn strategies from visual inputs via reinforcement learning. Many existing multi-agent reinforcement learning (MARL) algorithms however don't scale to environments where agents operate on visual inputs. To address this issue, algorithmically, recent works have focused on non-stationarity and exploration. In contrast, we study whether scalability can also be achieved via a disentangled representation. For this, we explicitly construct an object-centric intermediate representation to characterize the states of an environment, which we refer to as `semantic tracklets.' We evaluate `semantic tracklets' on the visual multi-agent particle environment (VMPE) and on the challenging visual multi-agent GFootball environment. `Semantic tracklets' consistently outperform baselines on VMPE, and achieve a +2.4 higher score difference than baselines on GFootball. Notably, this method is the first to successfully learn a strategy for five players in the GFootball environment using only visual data.
Cooperative Exploration for Multi-Agent Deep Reinforcement Learning
Jul 23, 2021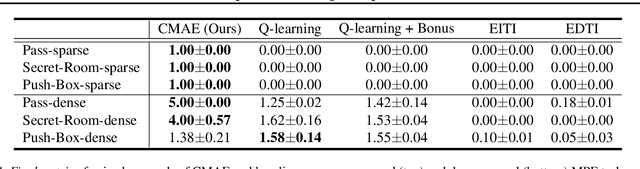
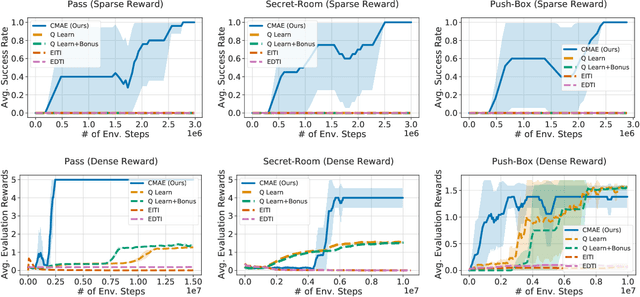
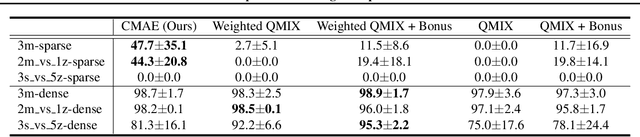
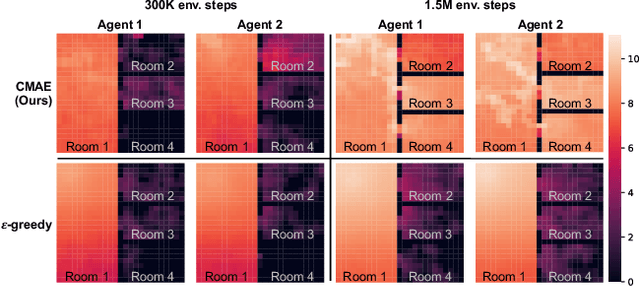
Exploration is critical for good results in deep reinforcement learning and has attracted much attention. However, existing multi-agent deep reinforcement learning algorithms still use mostly noise-based techniques. Very recently, exploration methods that consider cooperation among multiple agents have been developed. However, existing methods suffer from a common challenge: agents struggle to identify states that are worth exploring, and hardly coordinate exploration efforts toward those states. To address this shortcoming, in this paper, we propose cooperative multi-agent exploration (CMAE): agents share a common goal while exploring. The goal is selected from multiple projected state spaces via a normalized entropy-based technique. Then, agents are trained to reach this goal in a coordinated manner. We demonstrate that CMAE consistently outperforms baselines on various tasks, including a sparse-reward version of the multiple-particle environment (MPE) and the Starcraft multi-agent challenge (SMAC).
GridToPix: Training Embodied Agents with Minimal Supervision
Apr 14, 2021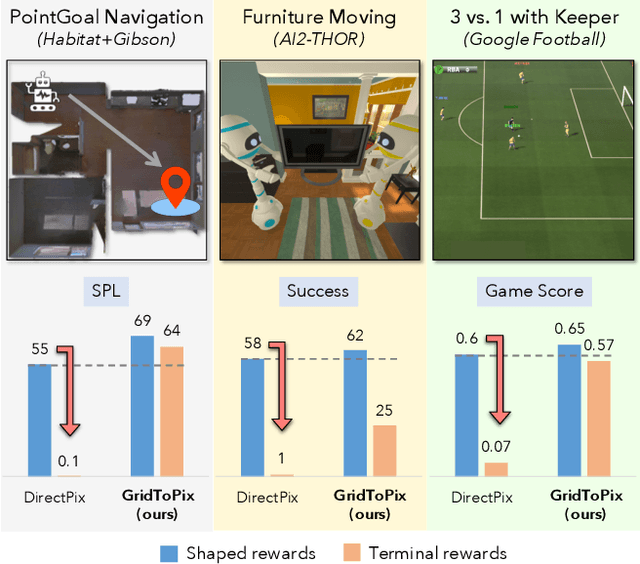

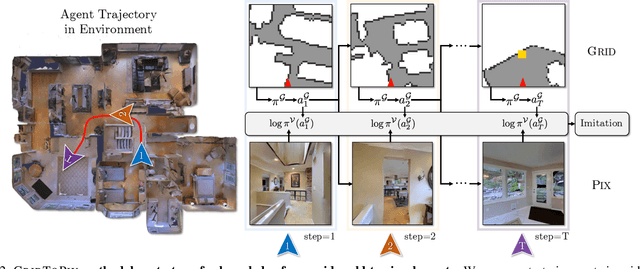

While deep reinforcement learning (RL) promises freedom from hand-labeled data, great successes, especially for Embodied AI, require significant work to create supervision via carefully shaped rewards. Indeed, without shaped rewards, i.e., with only terminal rewards, present-day Embodied AI results degrade significantly across Embodied AI problems from single-agent Habitat-based PointGoal Navigation (SPL drops from 55 to 0) and two-agent AI2-THOR-based Furniture Moving (success drops from 58% to 1%) to three-agent Google Football-based 3 vs. 1 with Keeper (game score drops from 0.6 to 0.1). As training from shaped rewards doesn't scale to more realistic tasks, the community needs to improve the success of training with terminal rewards. For this we propose GridToPix: 1) train agents with terminal rewards in gridworlds that generically mirror Embodied AI environments, i.e., they are independent of the task; 2) distill the learned policy into agents that reside in complex visual worlds. Despite learning from only terminal rewards with identical models and RL algorithms, GridToPix significantly improves results across tasks: from PointGoal Navigation (SPL improves from 0 to 64) and Furniture Moving (success improves from 1% to 25%) to football gameplay (game score improves from 0.1 to 0.6). GridToPix even helps to improve the results of shaped reward training.
High-Throughput Synchronous Deep RL
Dec 17, 2020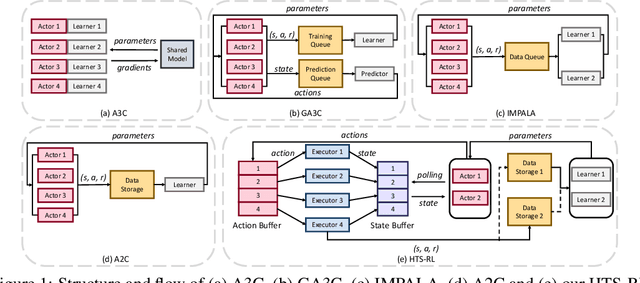
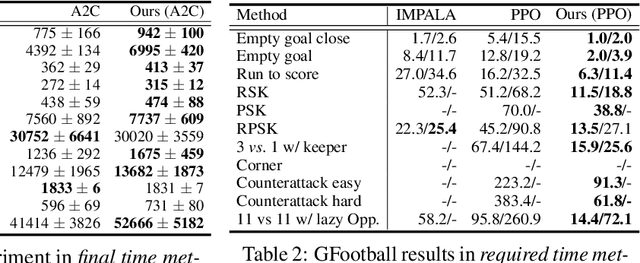

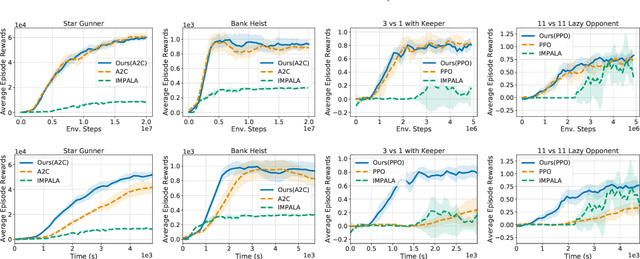
Deep reinforcement learning (RL) is computationally demanding and requires processing of many data points. Synchronous methods enjoy training stability while having lower data throughput. In contrast, asynchronous methods achieve high throughput but suffer from stability issues and lower sample efficiency due to `stale policies.' To combine the advantages of both methods we propose High-Throughput Synchronous Deep Reinforcement Learning (HTS-RL). In HTS-RL, we perform learning and rollouts concurrently, devise a system design which avoids `stale policies' and ensure that actors interact with environment replicas in an asynchronous manner while maintaining full determinism. We evaluate our approach on Atari games and the Google Research Football environment. Compared to synchronous baselines, HTS-RL is 2-6$\times$ faster. Compared to state-of-the-art asynchronous methods, HTS-RL has competitive throughput and consistently achieves higher average episode rewards.
PIC: Permutation Invariant Critic for Multi-Agent Deep Reinforcement Learning
Oct 31, 2019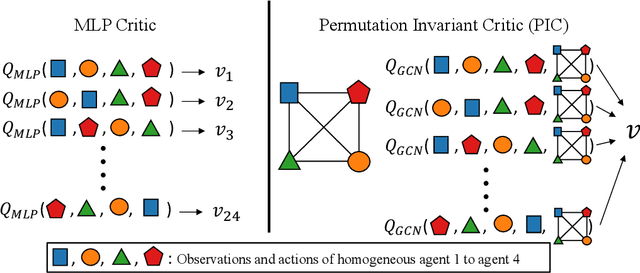
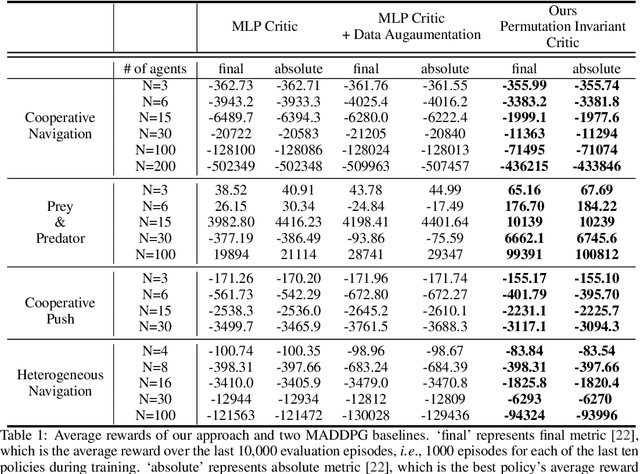
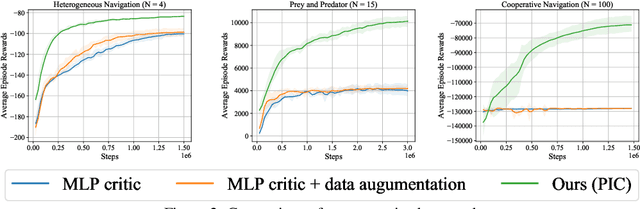
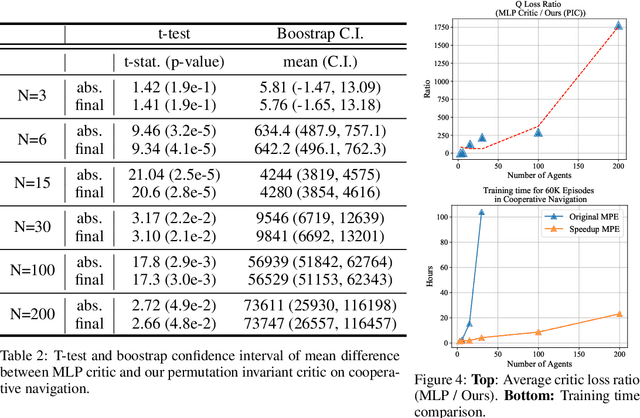
Sample efficiency and scalability to a large number of agents are two important goals for multi-agent reinforcement learning systems. Recent works got us closer to those goals, addressing non-stationarity of the environment from a single agent's perspective by utilizing a deep net critic which depends on all observations and actions. The critic input concatenates agent observations and actions in a user-specified order. However, since deep nets aren't permutation invariant, a permuted input changes the critic output despite the environment remaining identical. To avoid this inefficiency, we propose a 'permutation invariant critic' (PIC), which yields identical output irrespective of the agent permutation. This consistent representation enables our model to scale to 30 times more agents and to achieve improvements of test episode reward between 15% to 50% on the challenging multi-agent particle environment (MPE).
Knowledge Flow: Improve Upon Your Teachers
Apr 11, 2019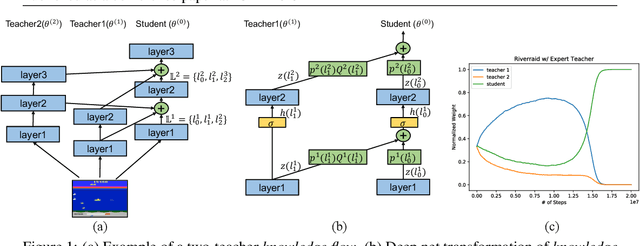
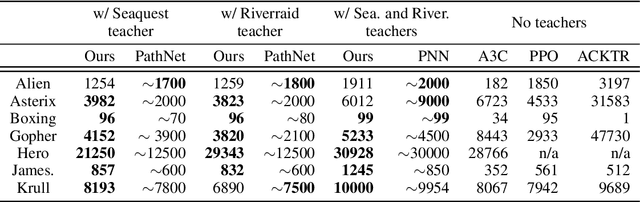
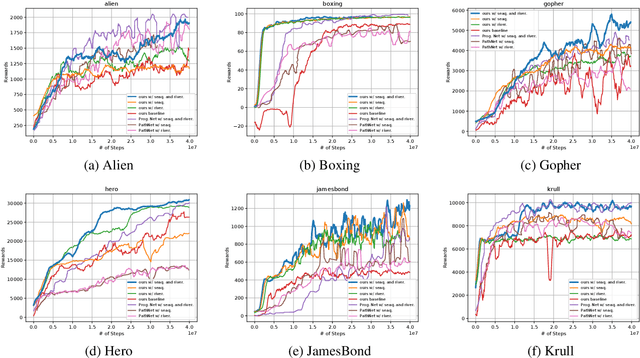
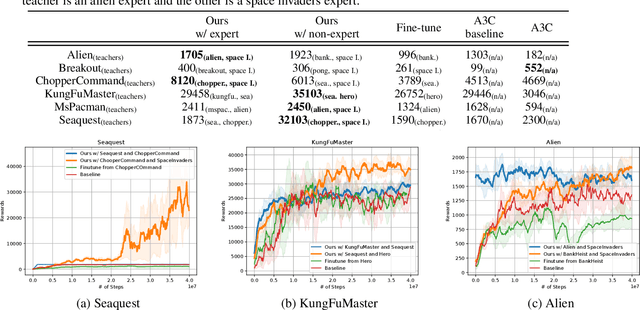
A zoo of deep nets is available these days for almost any given task, and it is increasingly unclear which net to start with when addressing a new task, or which net to use as an initialization for fine-tuning a new model. To address this issue, in this paper, we develop knowledge flow which moves 'knowledge' from multiple deep nets, referred to as teachers, to a new deep net model, called the student. The structure of the teachers and the student can differ arbitrarily and they can be trained on entirely different tasks with different output spaces too. Upon training with knowledge flow the student is independent of the teachers. We demonstrate our approach on a variety of supervised and reinforcement learning tasks, outperforming fine-tuning and other 'knowledge exchange' methods.